一、环境简介
本教程服务器主机都是CentOS 7(Red Hat 7 亦可),集群结点分布情况如下表:
+---------------+-----------+---------------------------------- |IP |HOSTNAME |备注 +---------------+-----------+---------------------------------- |192.168.6.171 |hdpmmaster |ResourceManager 进程所在机器 +---------------+-----------+---------------------------------- |192.168.6.172 |hdpsmaster |SecondaryNameNode 主机的备机 +---------------+-----------+---------------------------------- |198.168.6.67 |hdpslave67 |datanode +---------------+-----------+---------------------------------- |198.168.6.68 |hdpslave68 |datanode +---------------+-----------+---------------------------------- |198.168.6.69 |hdpslave68 |datanode +---------------+-----------+----------------------------------
二、Linux 环境准备
01. 创建hadoop用户
01) 新建用户: adduser hadoop(注: 在创建hadoop用户的同时也创建了hadoop用户组) 02) 给hadoop用户添加登录密码: passwd hadoop 03) 把hadoop用户加入到hadoop用户组: usermod -a -G hadoop hadoop 03) 赋予用户root权限, 向/etc/sudoers中添加"hadoop ALL=(ALL) ALL",如果没有写的权限需要先执行 chmod +w /etc/sudoers 注:以上所有操作都是在root用户下完成,非root用户可以在所有命令前加sudo
02. HOSTNAME 处理
01) 修改服务器的 hostname,使用命令 hostnamectl set-hostname <new_host_name>
192.168.6.171 中: hostnamectl set-hostname hdpmmaster 192.168.6.172 中: hostnamectl set-hostname hdpsmaster 192.168.6.67 中: hostnamectl set-hostname hdpslave67 192.168.6.68 中: hostnamectl set-hostname hdpslave68 192.168.6.69 中: hostnamectl set-hostname hdpslave69
02) 向/etc/hosts文件中添加域名和IP的映射,内容如下
192.168.6.171 hdpmmaster 192.168.6.172 hdpsmaster 192.168.6.67 hdpslave67 192.168.6.68 hdpslave68 192.168.6.69 hdpslave69
注:以上所有操作都是在root用户下完成,非root用户可以在所有命令前加sudo
03. ssh免密码登录
01) ssh安装,使用命令 sudo yum isntall -y openssd
02) ssh dsa算法密钥对生成,分别在5台机器执行以下3条命令
ssh-keygen -t dsa -P '' -f ~/.ssh/id_dsa cat ~/.ssh/id_dsa.pub >> ~/.ssh/authorized_keys chmod 600 ~/.ssh/authorized_keys
03) 复制公钥到集群服务器,使用命令 ssh-copy-id <user>@<host>
示例:复制 hdpslave67(192.168.6.67) 的公钥到 hdpslave68(192.168.6.68)
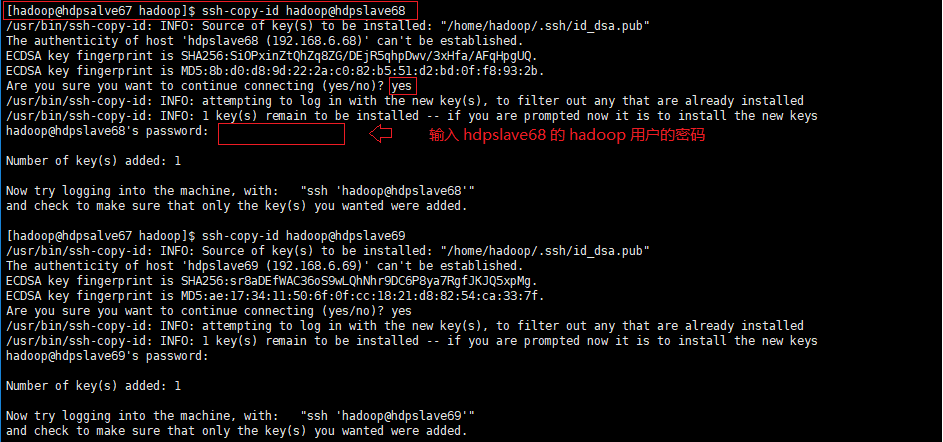
可以执行 ssh hadoop@hdpslave68 命令看是否需要输入登录密码
注:需要保证集群中的机器两两能无密码登录
04. JDK 安装
01) 下载并安装JDK
01) 下载 jdk 的 rpm 安装文件 02) 使用命令 sudo rpm -ivh jdk-8u144-linux-x64.rpm 安装
02) JDK 环境变量配置:sudo vi /etc/profile
export JAVA_HOME=/usr/java/jdk1.8.0_144 export JRE_HOME=${JAVA_HOME}/jre export CLASSPATH=$CLASSPATH:.:${JAVA_HOME}/lib:${JAVA_HOME}/jre/lib export PATH=${JAVA_HOME}/bin:${JAVA_HOME}/jre/bin:$PATH
注:jdk的环境变量配置也可写入 hadoop 用户目录下的 .bashrc 文件,或者 .bash_profile 文件
05. 关闭所有服务器的防火墙
sudo systemctl stop firewalld #停止防火墙服务 sudo systemctl disable firewalld #禁用防火墙服务开机启动
三、HAOOP 安装以及配置
01) 下载并安装 hadoop (版本:3.0.0)
wget http://mirrors.shuosc.org/apache/hadoop/common/hadoop-3.0.0/hadoop-3.0.0.tar.gz tar -xzf hadoop-3.0.0.tar.gz -C /usr/local/ cd /usr/local/ ln -s hadoop-3.0.0/ hadoop #建立软链接, 也可直接使用 mv hadoop-3.0.0 hadoop 命令改名
02) 配置 hadoop 环境变量,向 /home/hadoop/.bashrc 文件添加以下内容
# HADOOP export HADOOP_HOME=/usr/local/hadoop export PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop export HADOOP_INSTALL=$HADOOP_HOME export HADOOP_MAPRED_HOME=$HADOOP_HOME export HADOOP_COMMON_HOME=$HADOOP_HOME export HADOOP_HDFS_HOME=$HADOOP_HOME export HADOOP_YARN_HOME=$HADOOP_HOME export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
03) 配置 hadoop 安装目录(/usr/local/hadoop)下的 etc/hadoop/core-site.xml
<configuration> <property> <name>fs.defaultFS</name> <value>hdfs://hdpmmaster:9000</value> </property> <property> <name>hadoop.tmp.dir</name> <value>file:///usr/local/hadoop/hdptmp</value> <description>Abase for other temporary directories.</description> </property> </configuration>
04) 配置 hadoop 安装目录(/usr/local/hadoop)下的 etc/hadoop/hdfs-site.xml
<configuration> <property> <name>dfs.replication</name> <value>1</value> </property> <property> <name>dfs.namenode.name.dir</name> <value>file:///usr/local/hadoop/hadoop_data/hdfs/namenode</value> </property> <property> <name>dfs.datanode.data.dir</name> <value>file:///usr/local/hadoop/hadoop_data/hdfs/datanode</value> </property> <property> <name>dfs.namenode.secondary.http-address</name> <value>hdpsmaster:9868</value> </property> </configuration>
05) 配置 hadoop 安装目录(/usr/local/hadoop)下的 etc/hadoop/mapred-site.xml
<configuration> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> <property> <name>mapreduce.jobhistory.address</name> <value>hdpmmaster:10020</value> </property> <property> <name>mapreduce.jobhistory.webapp.address</name> <value>hdpmmaster:19888</value> </property> </configuration>
06) 配置 hadoop 安装目录(/usr/local/hadoop)下的 etc/hadoop/yarn-site.xml
<configuration> <!-- Site specific YARN configuration properties --> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <property> <name>yarn.nodemanager.env-whitelist</name> <value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value> </property> <property> <name>yarn.nodemanager.resource.cpu-vcores</name> <value>2</value> </property> <!-- <property> <name>yarn.nodemanager.resource.memory-mb</name> <value>3072</value> </property> <property> <name>yarn.scheduler.maximum-allocation-mb></name> <value>3052</value> </property> --> <property> <name>yarn.resourcemanager.scheduler.address</name> <value>hdpmmaster:8030</value> </property> <property> <name>yarn.resourcemanager.resource-tracker.address</name> <value>hdpmmaster:8031</value> </property> <property> <name>yarn.resourcemanager.address</name> <value>hdpmmaster:8032</value> </property> <property> <name>yarn.resourcemanager.admin.address</name> <value>hdpmmaster:8033</value> </property> <property> <name>yarn.resourcemanager.webapp.address</name> <value>hdpmmaster:8088</value> </property> <property> <name>yarn.nodemanager.vmem-check-enabled</name> <value>false</value> </property> </configuration>
07) 配置 hadoop 安装目录(/usr/local/hadoop)下的 etc/hadoop/workers
hdpsmaster hdpslave67 hdpslave68 hdpslave69
注:该 workers 文件也可以配置为ip,如下
192.168.6.171 192.168.6.67 192.168.6.68 192.168.6.69
08) 配置 hadoop 安装目录(/usr/local/hadoop)下的 etc/hadoop/hadoop-env.sh
export JAVA_HOME=/usr/java/latest #去掉前面的'#', 且写入jdk的安装路径, 这里的写法用latest是为了以后jdk升级不用修改该配置, 当然也可以写jdk安装的绝对路径, 即"/usr/java1.8.0_144"
09) 格式化namenode
hdfs namenode -format
10) 启动集群
start-all.sh
注:启动之后通过 jps 命令查看java后台进程,各个结点的java进程信息如下
+---------------+-----------+-------------------------------------------------- |IP |HOSTNAME |java进程 +---------------+-----------+-------------------------------------------------- |192.168.6.171 |hdpmmaster |ResourceManager, NameNode, Jps +---------------+-----------+-------------------------------------------------- |192.168.6.172 |hdpsmaster |Jps, SecondaryNameNode, NodeManager, DataNode +---------------+-----------+-------------------------------------------------- |198.168.6.67 |hdpslave67 |NodeManager, Jps, DataNode +---------------+-----------+-------------------------------------------------- |198.168.6.68 |hdpslave68 |NodeManager, Jps, DataNode +---------------+-----------+-------------------------------------------------- |198.168.6.69 |hdpslave68 |NodeManager, Jps, DataNode +---------------+-----------+--------------------------------------------------
11) 在有图形界面的pc上访问下面两个地址链接,查看相关信息
http://hdpmmaster:8088/ #NameNode图形界面, 任务分配和任务进度信息的查询 http://hdpmmaster:9870/ #集群结点(Node Of Cluster)图形界面
注:以域名访问需要向该pc的hosts文件中加入 "192.168.6.171 hdpmmaster",Windows 操作系统的hosts文件路径在 "C:\Windows\System32\drivers\etc\hosts",CentOS操作系统的hosts文件路径在"/etc/hosts"。
12) 单词统计示例运行
hadoop fs -mkdir /input hadoop fs -chmod -R 775 /input hadoop fs -put /usr/local/hadoop/LICENSE.txt /input hadoop jar /usr/local/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.0.0.jar wordcount /input /output
注:01. 每次执行上面的 hadoop jar 命令,需要确认集群结点上的 /output 目录是否存在,存在则使用命令 "hadoop fs -rmr -f /output"删除该目录
02. 执行成功之后可以在 http://hdpmmaster:9870/explorer.html 中的"/output"文件夹中找到输出结果,允许下载和预览该结果文件
13) 停止集群
stop-all.sh
四、FAQ
问题描述: 执行任务的时虚拟内存溢出 报错信息: Container [pid=5623,containerID=container_1514514155753_0001_01_000002] is running beyond virtual memory limits. Current usage: 155.1 MB of 1 GB physical memory used; 2.4 GB of 2.1 GB virtual memory used. Killing container. 解决方案: 方案一: 关闭虚拟内存监测, 在yarn-site.xml文件中添加"yarn.nodemanager.vmem-check-enabled"配置, 值为"false"(该方案不建议在正式环境中使用) 方案二: 提高内存配置, 参考 http://blog.chinaunix.net/uid-25691489-id-5587957.html
问题描述: 集群启动正常, 使用jps查看各个结点的java进程也是对的, 但是无法打开http://hdpmmaster:8088, 虽然http://hdpmmaster:9870能访问, 但是查看 DataNode 页面没有看到任何一个结点。 报错信息: 查看任何一个 DataNode 结点的日志文件(HADOOP_HOME/logs/hadoop-hadoop-datanode-hdpsmaster.log)发现以下信息 Retrying connect to server: hdpmmaster/192.168.6.171:9000. Already tried 0 time(s); retry policy is RetryUpToMaximumCountWithFixedSleep(maxRetries=10, sleepTime=1000 MILLISECONDS) 解决方案: 查看 hdpmmaster/192.168.6.171 主机的hosts文件中是否有"127.0.0.1 hdpmmaster", 删除该行, 重新格式化集群(hdfs namenode -format). 问题原因: 因为将hdpmmaster映射在了localhost, 所以DataNode结点无法访问到该NameNode, 同时也无法打开http://hdpmmaster:8088. 可以通过查看格式化集群结点时最后的提示信息来判定是否有出现该问题. 如果是"SHUTDOWN_MSG: Shutting down NameNode at localhost/127.0.0.1", 表示映射错误; 如果是"SHUTDOWN_MSG: Shutting down NameNode at hdpmmaster/192.168.6.171", 表示映射是正确的. 当然这一切都要在所有集群主机能够互相ping通的前提下, 即需要的所有端口都开放, 或者直接关闭防火墙, 该教程为简洁就是直接关闭集群所有主机的防火墙.
问题描述: 在http://hdpmmaster:8088/cluster/nodes的界面出现unhealthy结点 报错信息: yarn.server.nodemanager.DirectoryCollection: Directory /var/lib/hadoop-yarn/cache/yarn/nm-local-dir error, used space above threshold of 90.0%, removing from list of valid directories 解决方案: 加大磁盘容量, 或者清理磁盘空间, 当然也可以提高yarn的监测数值, 即在yarn-site.xml中添加"yarn.nodemanager.disk-health-checker.max-disk-utilization-per-disk-percentage"配置, 值是一个百分比数值, 例如"95.0" 问题原因: 该结点主机的磁盘使用超过90%,

