推荐系统是机器学习的一个常见应用场景,它用于预测用户对物品的“评分”或“偏好”。通常推荐系统产生推荐列表的方式通常有两种:
- 协同过滤以及基于内容推荐,或者基于个性化推荐。协同过滤方法根据用户历史行为(例如其购买的、选择的、评价过的物品等)结合其他用户的相似决策建立模型。这种模型可用于预测用户对哪些物品可能感兴趣(或用户对物品的感兴趣程度)。
- 基于内容推荐利用一些列有关物品的离散特征,推荐出具有类似性质的相似物品。

如上图所示,简单的说,协同过滤就是给类似的用户推荐类似的东西,因为用户老王和老李比较像,而老李喜欢玩炉石传说,所以我们给老王也推荐炉石传说。而基于内容的推荐就是因为老王喜欢玩王者荣耀,而撸啊撸是和王者荣耀类似的游戏,所以我们给老王推荐撸啊撸。
好了,那么我们就来利用TensorflowJS构建一个电影推荐系统。
数据源
第一步是数据源,要推荐电影,网上有很多的相关网站。例如IMDB。这里我们使用另一大家可能不太熟悉的数据源movielens ,数据分享在grouplens。
这里我们主要使用其中的两张表,电影数据movies.csv和用户评分数据ratings.csv
id,title,tags
1,Toy Story (1995),Adventure|Animation|Children|Comedy|Fantasy
2,Jumanji (1995),Adventure|Children|Fantasy
3,Grumpier Old Men (1995),Comedy|Romance
4,Waiting to Exhale (1995),Comedy|Drama|Romance
5,Father of the Bride Part II (1995),Comedy
6,Heat (1995),Action|Crime|Thriller
电影数据有三个字段,id,title和tags
user,movie,rating,timestamp
1,1,4.0,964982703
1,3,4.0,964981247
1,6,4.0,964982224
1,47,5.0,964983815
1,50,5.0,964982931
而用户评分包含用户的id,电影id,评分(0-5),和时间戳。
在js中,我们可以使用d3提供的csv方法来加载数据:
async function loadData(path) {
return await d3.csv(path);
}
const moviesData = await loadData(
"https://cdn.jsdelivr.net/gh/gangtao/datasets@master/csv/movies.csv"
);
const ratingsData = await loadData(
"https://cdn.jsdelivr.net/gh/gangtao/datasets@master/csv/ratings.csv"
);
加载好后,我们做一点简单的处理,把tag变成数组存储。
const movies = {};
const tags = [];
moviesData.forEach(movie => {
const { id, title, tags: movieTags } = movie;
const tagsSplit = movieTags.split("|");
tagsSplit.forEach(tag => {
if (tags.indexOf(tag) === -1) {
tags.push(tag);
}
});
movies[id] = {
id,
title,
tags: tagsSplit
};
});
const rawData = { tags, movies, ratingsData };
准备数据
数据加载好了,但是这样的数据还不能直接用来训练模型,为了训练,我们要对数据做一定的预处理。
function prepareData(rawData) {
const movieProfile = {};
const userProfile = {};
const trainingData = {xs: [], ys: []};
const moviesCount = Object.keys(rawData.movies).length;
const increment = 1 / moviesCount;
for (let movie of Object.values(rawData.movies)) {
const tagsArr = [];
const { id, title } = movie;
rawData.tags.forEach(tag => {
tagsArr.push(movie.tags.indexOf(tag) !== -1 ? 1 : 0);
});
movieProfile[movie.id] = { id, title, profile: tagsArr };
}
for (let rating of Object.values(rawData.ratingsData)) {
const { user: userIdx, movie: movieIdx, rating: ratingStr } = rating;
const ratingVal = parseFloat(ratingStr);
const ratingNormalized = ratingVal / 5;
rating.rating = ratingVal;
rating.ratingNormalized = ratingNormalized;
let user = userProfile[userIdx];
if (!user) {
user = {
stats: [ 1, 0 ],
tagsData: rawData.tags.map( () => 0 ),
ratingData: d3.range(10).map( () => 0 )
}
userProfile[userIdx] = user;
}
if (user.stats[0] > ratingNormalized) user.stats[0] = ratingNormalized;
if (user.stats[1] < ratingNormalized) user.stats[1] = ratingNormalized;
const movie = rawData.movies[movieIdx];
if (movie) {
const { tags } = movie;
tags.forEach( tag => {
user.tagsData[rawData.tags.indexOf(tag)] += increment;
});
user.ratingData[ Math.floor(ratingVal * 2) - 1 ] += increment;
}
}
for (let rating of Object.values(rawData.ratingsData)) {
const { user: userIdx, movie: movieIdx, ratingNormalized } = rating;
const user = userProfile[userIdx];
const movie = movieProfile[movieIdx];
if (movie) {
const { stats, tagsData, ratingData } = user;
trainingData.xs.push([].concat(stats).concat(tagsData).concat(ratingData).concat(movie.profile));
trainingData.ys.push(ratingNormalized)
}
}
return {
movieProfile,
userProfile,
trainingData,
features: trainingData.xs[0].length,
trainedModel: false,
moviesCount: Object.keys(movieProfile).length
}
}
数据的预处理主要包含以下几个步骤:
对于每一个电影记录,构建一profile字段,该字段是一个数组,表明了该电影包含的tag的类型,例如 Toy Story (1995) 的 profile对应为[1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],表示该电影的标签包含Adventure|Animation|Children|Comedy|Fantasy五个类型。
对于每一个用户,构建三个字段,ratingData,stats,tagsData
首先对于每一个评分,我们都计算一个标准化的评分,因为所有的评分都在0到5之间,所以标准化之后的评分就是 rates/5, 在0到1之间。
stats是一个包含两个数据的数组,分别是该用户的标准化之后的最低和最高评分。
假设总共有10000部电影,这里取一个计算单位1/10000,用于计算ratingData和tagsData。
ratingData记录了该用户对于电影的评价的分布。我们把它设定为0-9十个阶梯。用 rate*2 - 1 来计算用户评分落在哪一个区间。每当有一个评价,就把对应的阶梯加一个单位。用户1的评分记录如下:
[0, 0.00010264832683227263, 0, 0.0005132416341613632, 0, 0.0026688564976390886, 0, 0.007801272839252714, 0, 0.012728392527201836]
分别对应0-5分评价的是个阶梯的总评分。
tagsData记录了用户对于每一种类型的电影的评分统计。类似的:
[0.008725107780743174, 0.002976801478135906, 0.004311229726955449, 0.008519811127078628,...]
记录了该用户对各个类型的电影的总评价的和。这个统计也是标准化的,假设有一个用户看过所有的电影,对每一个电影都打五分, 而这个电影又是全类型覆盖的恐怖爱情动作侦探卡通喜剧电影,那么这里的值就是1。 当然并没有这样的用户和这样的电影。
同这这样的数据处理,我们得到了电影数据的标准化结果,表明电影属于哪一种类型。同样获得了用户评分数据的标准化结果,包含用户评分的喜好和对于每一种类型的评分的统计。
我们把所有的特征综合在一起,就可以构建一个训练数据集了。
训练的目标是用户评价的标准化评分 ratingNormalized
对于每一个评分,我们获得的所有的特征包含:stats/tagsData/ratingData/movie.profile
构建模型和训练
这里模型非常简单,只有一层的8个单元的relu,因为目标是要预测评分,这里损失函数是mse,其实是构建了一个回归模型, 使用用户对电影的口味和喜好(tagsData)加上用户的打分习惯(ratingData,stats),以及电影本身的属性(movie.profile), 来预测标准化后的评分。
function buildModel(data) {
const model = tf.sequential();
const count = data.trainingData.xs.length;
const xsLength = data.features;
model.add(
tf.layers.dense({ units: 8, inputShape: [xsLength], activation: "relu6" })
);
model.add(tf.layers.dense({ units: 1 }));
model.compile({
optimizer: "sgd",
loss: "meanSquaredError",
metrics: ["accuracy"]
});
return model;
}
所谓的协同过滤指的就是这里的我们把用户喜好建模作为模型的输入特征,协同内容本身,也就是电影的自身属性一起作为输入特征来构建模型。
训练过程很简单:
async function trainBatch(data) {
console.log("training start!");
model = buildModel(data);
const batchIndex = 0;
const batchSize = config.datasize;
const epochs = config.epochs;
const results = [];
const xsLength = data.features;
const from = batchIndex * batchSize;
const to = from + batchSize;
const xs = tf.tensor2d(data.trainingData.xs.slice(from, to), [
batchSize,
xsLength
]);
const ys = tf.tensor2d(data.trainingData.ys.slice(from, to), [batchSize, 1]);
const history = await model.fit(xs, ys, {
epochs,
validationSplit: 0.2
});
console.log("training complete!");
return history;
}
推荐搜索
模型建好后,还不能单独利用模型来做推荐,因为我们的模型基于用户和电影的profile能预测一个评分,所以对于摸一个用户而言,我们需要对所有的电影预测该用户的评分,然后给出评分最高的电影,这个搜索过程比较耗时,取决于电影的数量。
async function recommend(profile, rawData, data) {
$("#reStats").empty();
$("#reResults").empty();
const { tags, movies } = rawData;
const statesOutput = d3.select("#reStats");
const resultOutput = d3.select("#reResults");
let results = [];
for (let movie of Object.values(movies)) {
const { stats, tagsData, ratingData } = profile;
const movieProfile = data.movieProfile[movie.id].profile;
const input = []
.concat(stats)
.concat(tagsData)
.concat(ratingData)
.concat(movieProfile);
const rateResult = await model.predict(tf.tensor([input])).data();
statesOutput.text(`searching ${movie.id} ${movie.title}`);
results.push({ "title": movie.title, "rate" : rateResult[0]});
}
statesOutput.text("searching complete, here list the recommendations");
const recommendResult = results.sort(function(a, b) {
return a.rate - b.rate;
}).slice(-maxNum);
recommendResult.forEach( r => {
resultOutput.append("li").text(`${r.title} ${r.rate}`);
})
}
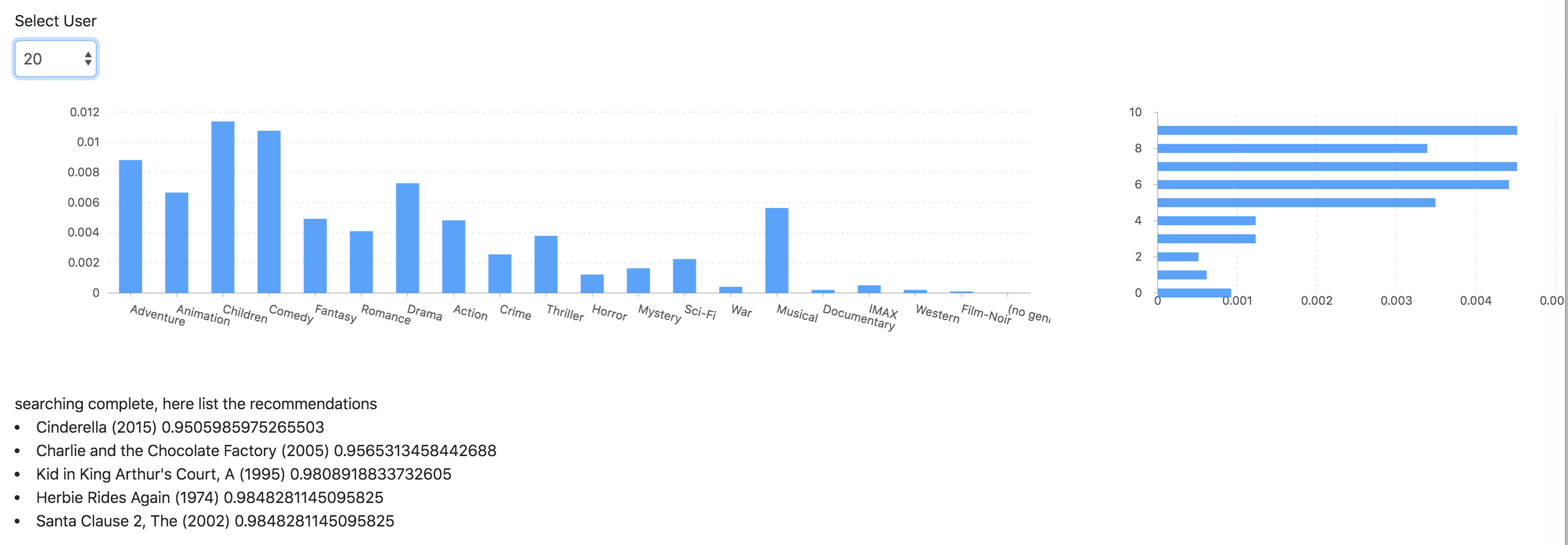
如上图所示,最后我们为20号用户推荐了五部电影。两个柱状图分别表示用户的标签分布和评分分布。
完整代码请见codepen
总结
无论是那种推荐算法,推荐系统的核心都是寻找相似度。其实机器学习的算法有一些是提供相似度检查的,例如KNN。另外SVD也常常被用于推荐系统的构建。本质上来说,我们就是把特征变成向量,在几何空间中寻找距离最接近的数据。认为它们是相似的。
最后给大家推荐两个用于做推荐系统的开源库:
参考

