Flow Based Programing 是由J. Paul Rodker Morrison在很早以前提出的一种编程范式。
维基百科对FBP的定义如下:
In computer programming, flow-based programming (FBP) is a programming paradigm that defines applications as networks of "black box" processes, which exchange data across predefined connections by message passing, where the connections are specified externally to the processes. These black box processes can be reconnected endlessly to form different applications without having to be changed internally. FBP is thus naturally component-oriented.
在github的这个https://github.com/samuell/awesome-fbp项目内列举了很多不同语言对该范式的实现以及一些资料,大家可以参考。
很多年前我用Python开发了一个基于流概念的数据处理工具。当时主要是想解决让不懂编程的数据工程师能够通过构建图形化的数据流来达到数据获取,变形和抽取的功能。这么多年过去了,我整理了一下代码,丰富了一下基本功能,构建了简单的运行UI,算是有个初步的雏型,看看能不能分享给社区做些贡献。
项目在这里:
其实利用Flow的概念在软件项目中很常见。例如:
我么下面来看看这个项目的基本概念和如何使用吧。
Flow的基本概念
Flow的基本概念很简单,就是一个有向无环图(DAG),数据在节点间流动。

- 节点 Node
节点是组成流的主要单元,负责对流入节点的数据进行处理,并输出到后续节点进行进一步的处理。 - 端口 Port
每个节点拥有输入和输出端口,输入端口负责数据流入节点,输出端口负责数据流出节点。每个节点都可能拥有一个或者多个输入和输出端口。 - 连接 Link
一个节点的输出端口连接到另一个节点的输入端口,节点处理好的数据通过连接流入其后的节点。
Flow的实现
Pyflow对Flow的实现基本思路就是用一个Python的函数function实现一个节点,输入端口映射为函数的输入参数。输出端口映射为函数的返回值。

流中有一个节点被设置为终点节点(End Node),通过节点间的连接关系,以终点节点开始通过连接搜索所有的依赖关系(树形查找),得到一个节点运行的栈。例如上图,我们就可以得到一个 [node1,node2, node3] 这样的栈。按顺序出栈的方式执行每一个节点的功能就可以运行整个流。(注意,这是一个简单版本的Flow的实现,仍然是一个批处理,不是streaming)
需要假定每一个节点的功能是无状态的,这样就可以利用输入输出端口对计算结果进行缓存,但输入值是已经运算过的值的时候,不需要运算,直接返回已经计算过的值。
Pyflow的功能
节点
我们先介绍一下Pyflow的节点管理功能呢。Pyflow支持动态的创建和修改节点。如下图:
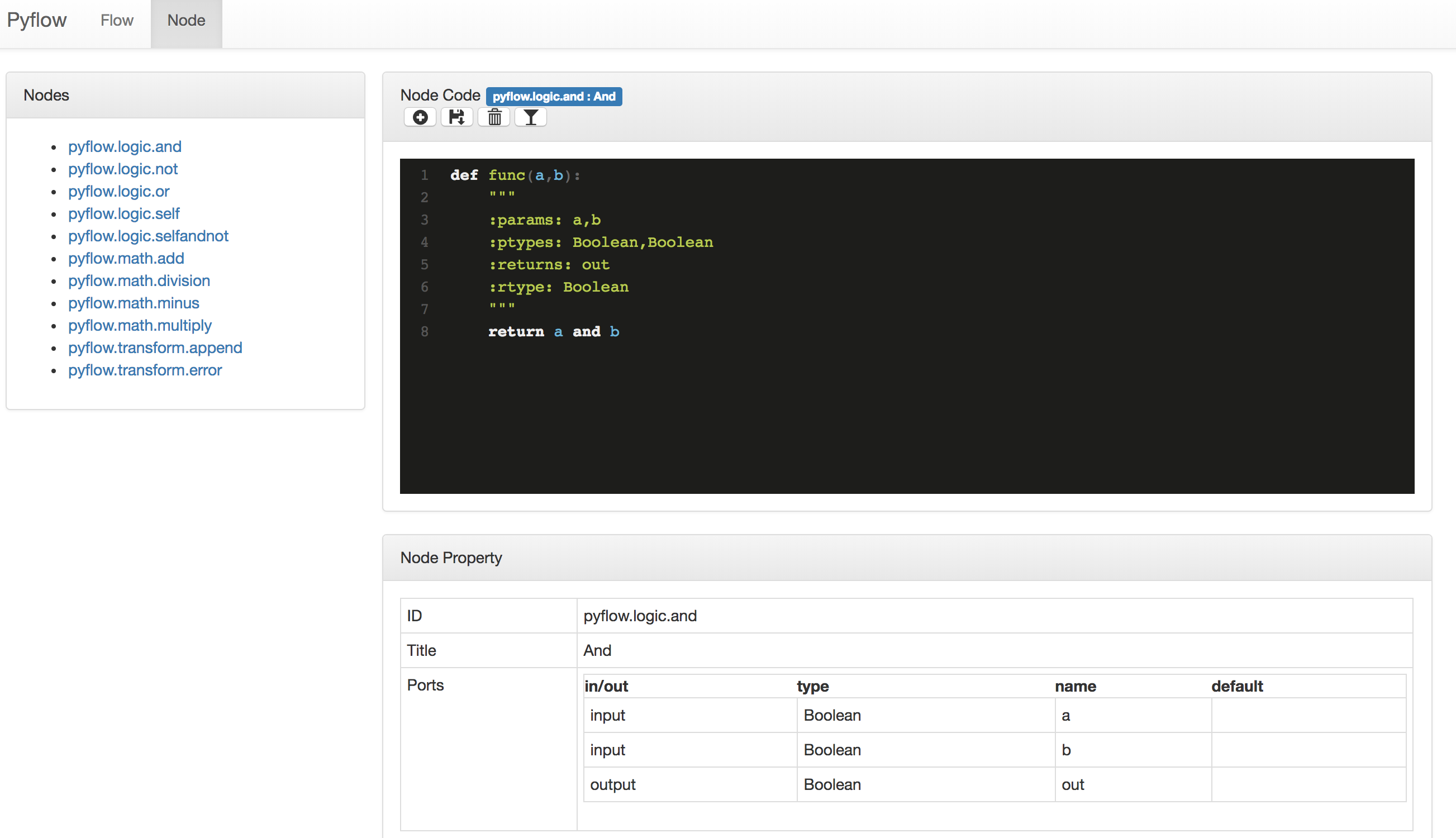
左边的节点列表列举出当前所有已经定义的节点。
右边包含一个节点的代码编辑面板和一个节点属性面板。
节点属性列出选中节点的ID,Title,Port等属性内容。
节点编辑面板提供对节点功能和代码的编辑。代码是节点对应的Python函数。利用函数的注释生成对应的元数据,也就是端口的属性。
上图是一个节点定义了逻辑操作And,输入端口是a和b两个布尔值,输出是a and b

上图的按钮分别对应以下功能:
- 增加一个新的节点
- 存储当前的节点
- 删除当前的节点
- 对当前的节点进行测试
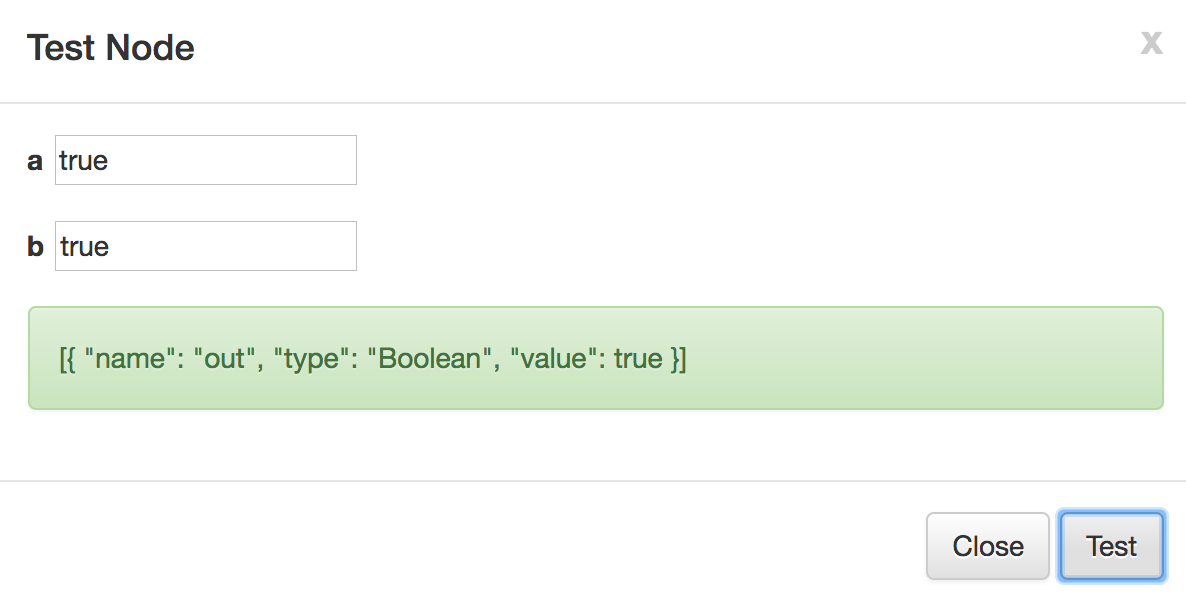
例如之前And的例子,我们修改代码后,点击 对该节点的功能进行测试。
对该节点的功能进行测试。
流
定义好节点后,我们就可以在流管理的界面创建和运行数据流。
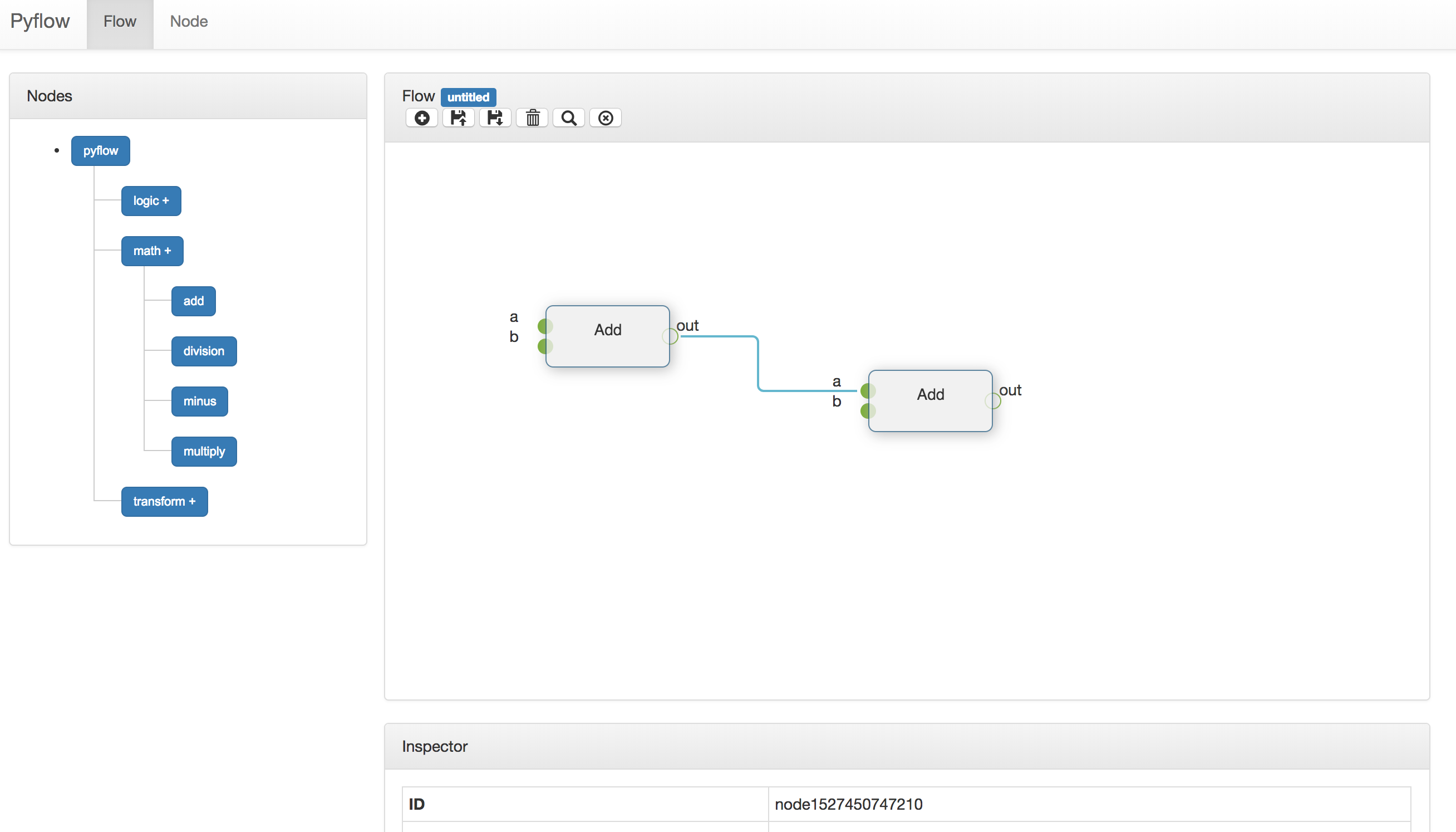
左边的面板是所有应定义好的节点,用户可以通过拖拽的方式把节点拖到右边的FLow面板来构建一个数据流。
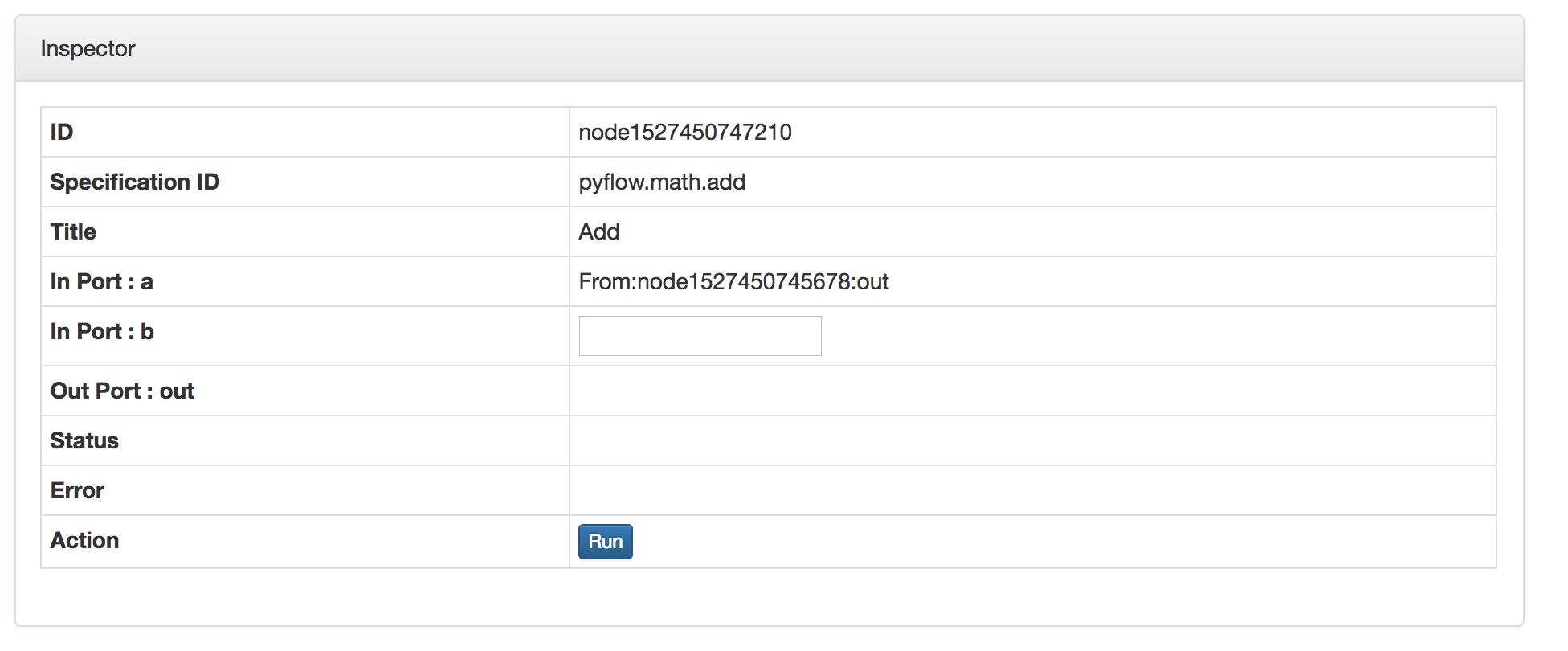
当选中一个节点的时候,对应的Inspector面板会显示当前选中节点的属性,包含
- ID
流中该节点的唯一标志 - Specification ID
该节点对应的Spec的ID,Spec可以理解为该节点的类,而该节点在流中是该类的一个实例。 - Title
节点的名字 - Input Port
输入端口的信息,用户可以对没有连接的端口给出输入值。对于已经连接的端口,会给出连接信心。 - Output Port
输出端口的信息。同样对于有连接的给出连接信息 - Status
当前节点运行的状态 - Error
运行的出错信息 - Action
点击 按钮,会把当前节点设置为终点节点,并运行当前的数据流。
按钮,会把当前节点设置为终点节点,并运行当前的数据流。

上面的按钮分别定义了:
- 创建新的数据流
- 加载已经保存的数据流
- 保存当前的数据流
- 显示当前数据流的JSON表示
- 删除选中的节点
仓库
Pyflow内置一个基于Sqlite的数据仓库,用于保存所有的节点Sepc定义和数据流。用户可以使用action菜单的Dump和Load功能来加载或者导出。
Pyflow的几个例子
Pyflow给出了几个数据流的例子。
数学运算
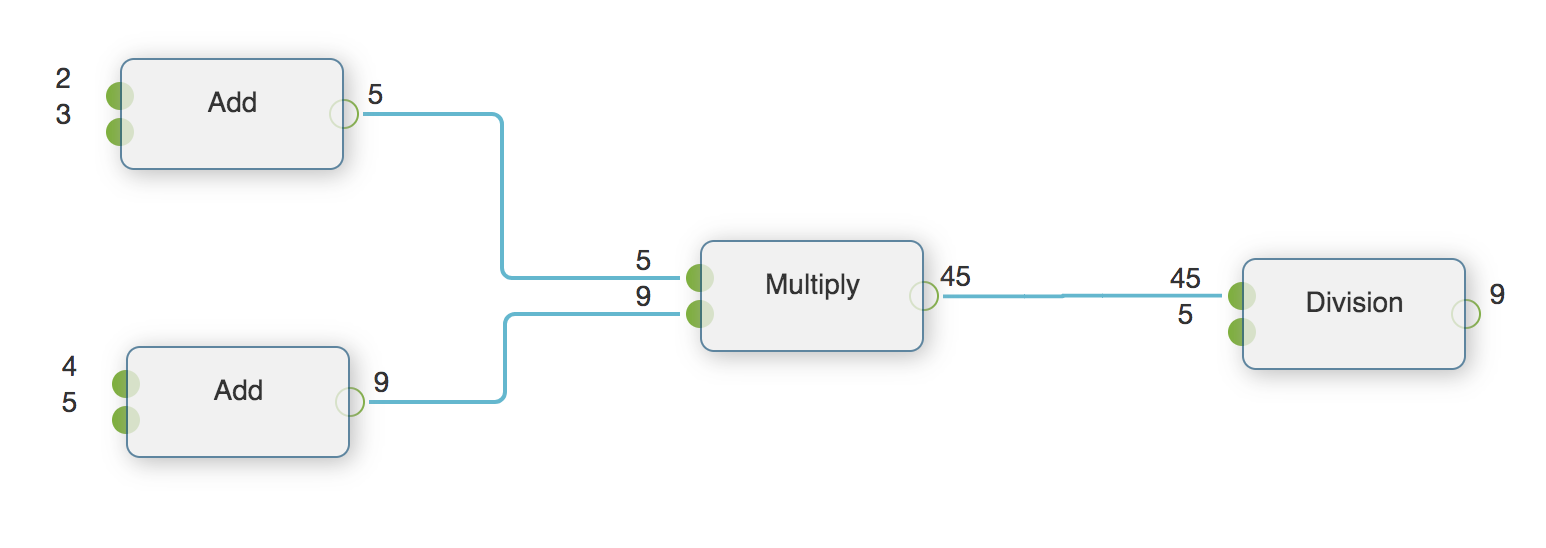
pyflow.sample.math:Math是一个数学运算的例子。
这个例子运算 (2+3)X(4+5)/ 5
逻辑运算
pyflow.sample.xor:Xor是利用基本的逻辑操作实现异或(XOR)。数据流如下:
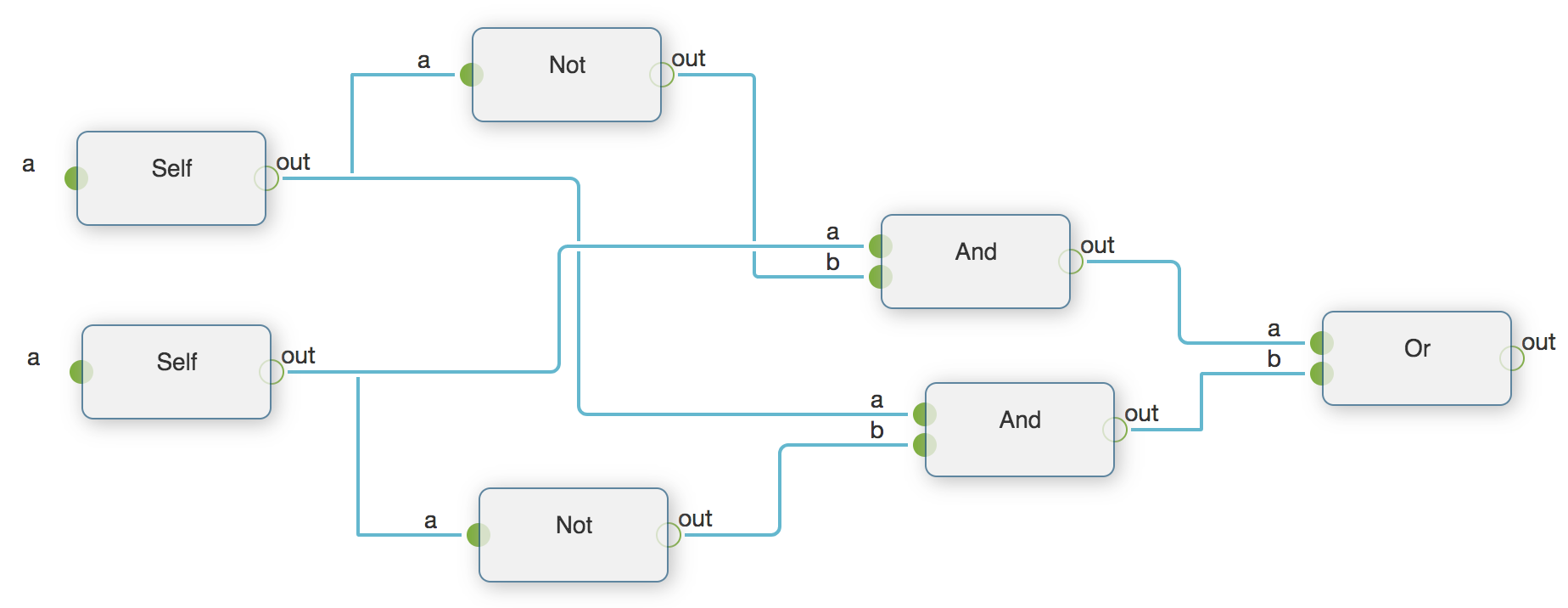
异或只有在两个输入不同的时候才输出真值。
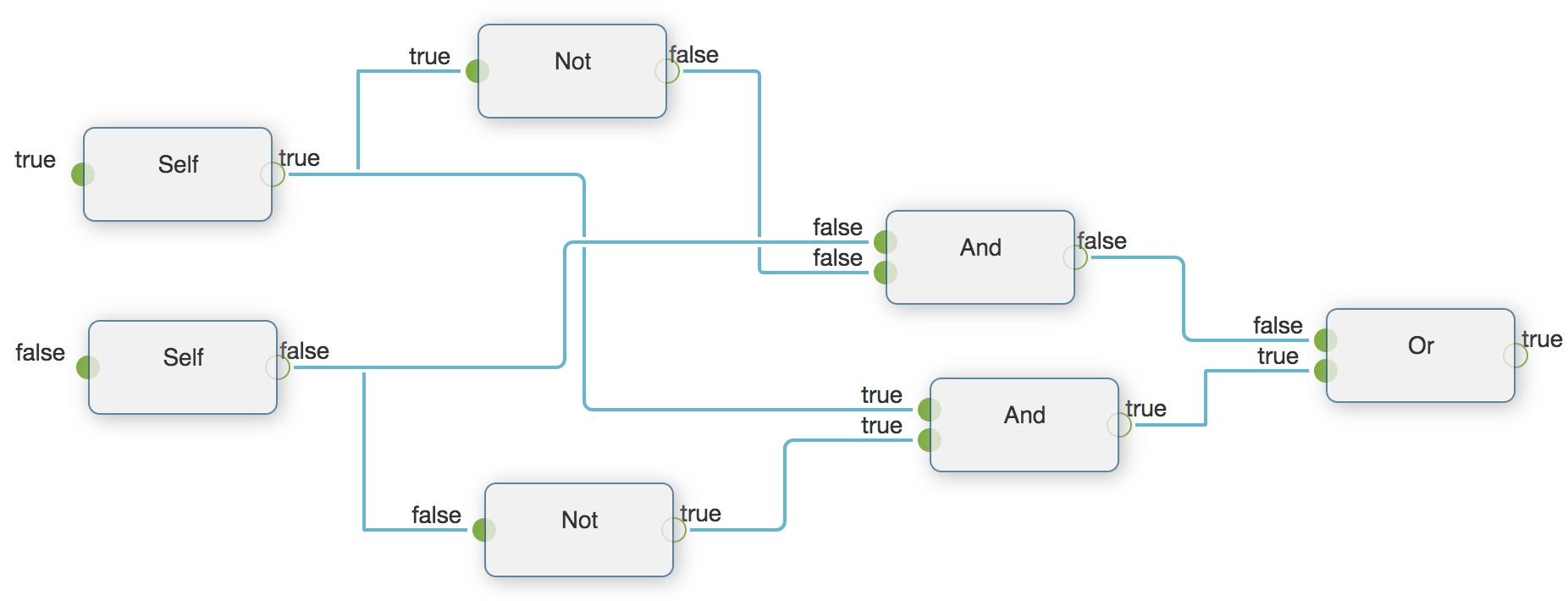
Pyflow给出数据流运行的每一步的结果,让我们可以直观的理解整个数据流的处理过程。
利用多输出,我们可以得到一个简化版本的异或。
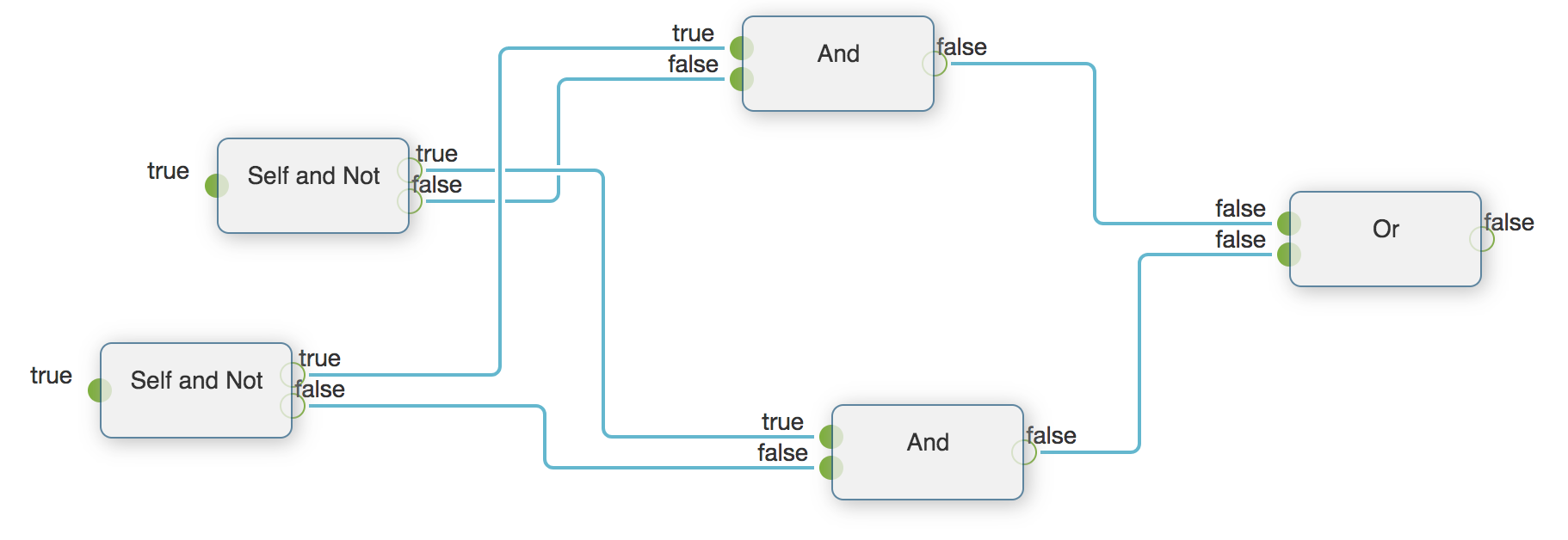
这里Self and Not节点的输出端口有两个,同时输出输入值和输入的非值。整个数据流变得更简洁。
错误处理
pyflow.sample.error:Error是一个对出错处理的演示。
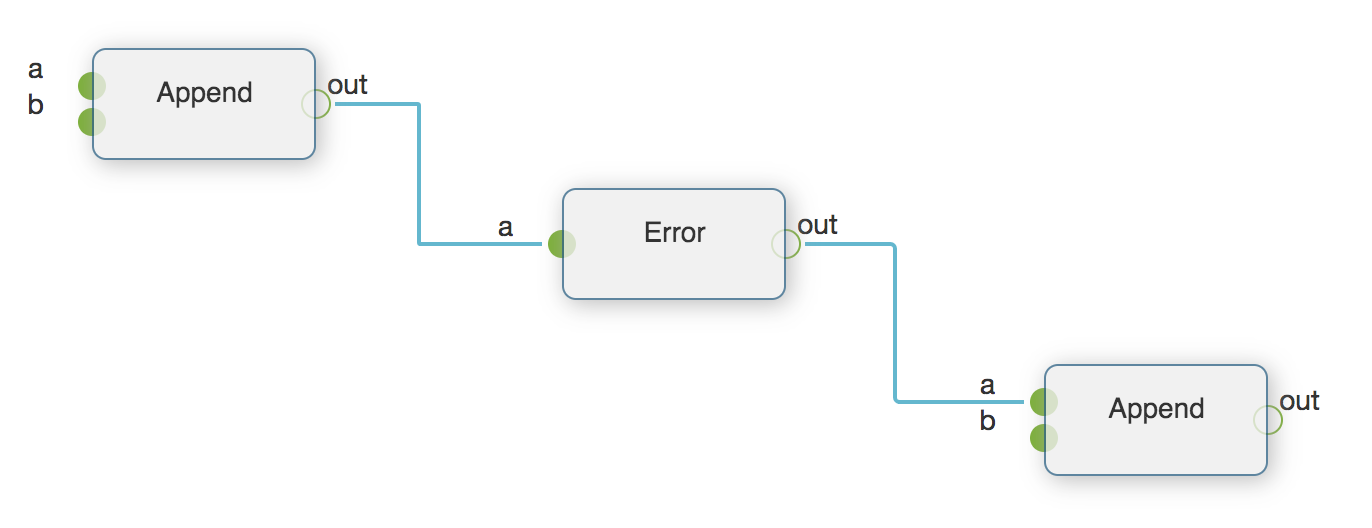
该数据流演示了如果数据流中一个节点出错的情形。
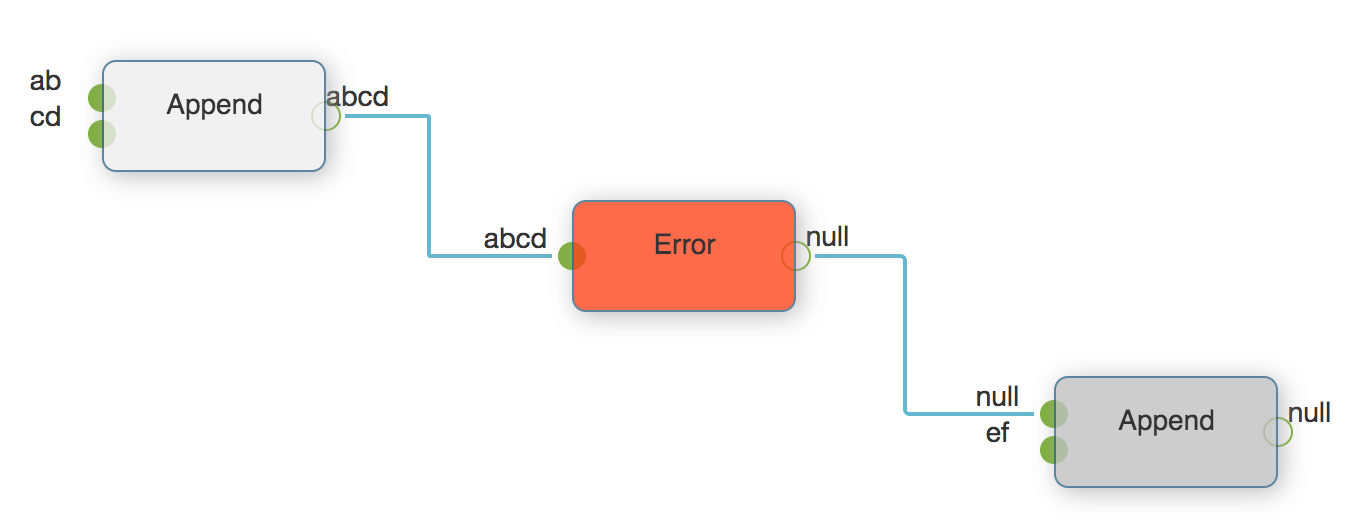
由于数据流中的一个节点出错,该数据流无法正常完成,流运行的结果给出每一步的结果,出错节点之后对出错节点有依赖的节点处于Skip状态,没有运行。当出错被恢复后,已经运行成功的节点可以直接从缓存中获取之前运行成功的值。
Flow的优缺点
Flow的优点:
Flow的缺点或局限:
- 节点的定义很困难,如果单个节点很大,负责很多东西,则可重用性变差;如果单个节点和简单,则flow会变的很复杂。
- 并非所有的功能都能映射为无状态的节点,例如取当前时间,产生随机数。
- 不支持反馈,这个是当前实现的限制,由于要构建运行栈,不支持Flow中有环路。
总结
利用Flow的概念在编程中不是什么新鲜概念,我希望我的工具能给大家带来一些帮助。如果大家喜欢也可以和我一起来完善这个工具,这里有几个想法:
- 当前的运行核心不支持stream运算,想要支持,对核心改动比较大,但也不是做不到。
- 当前的节点是运行在一个独立的进程中,更好的做法是和容器结合,让每一个节点成为一个容器,这样更安全,也有更多的实用性。
- 我的代码sucks,请大家多多批评。我不是一个前端工程师,前端要实现这么多功能太累了。
- Python 2 升级到 3,想想头就疼
项目已经发布到dockerhub了,大家只要运行:
docker run -P naughtytao/pyflow:latest
然后在你的浏览器中访问就好了,欢迎各种反馈!

