我们登陆hive shell 写复杂的长的sql语句不是很方便,没有格式化拷贝粘贴等常用操作,查询结果也不是很直观,时我们可以使用第三方的客户端连接hive进行操作,于是我们使用支持hive的数据库客户端界面工具dbeaver,本文我们使用其连接上面文章搭建好的hive数据仓库服务。
一、环境准备
1.hadoop集群
2.hive元数据存储服务
3.hive数据仓库服务
4.dbeaver客户端工具
二、实践准备
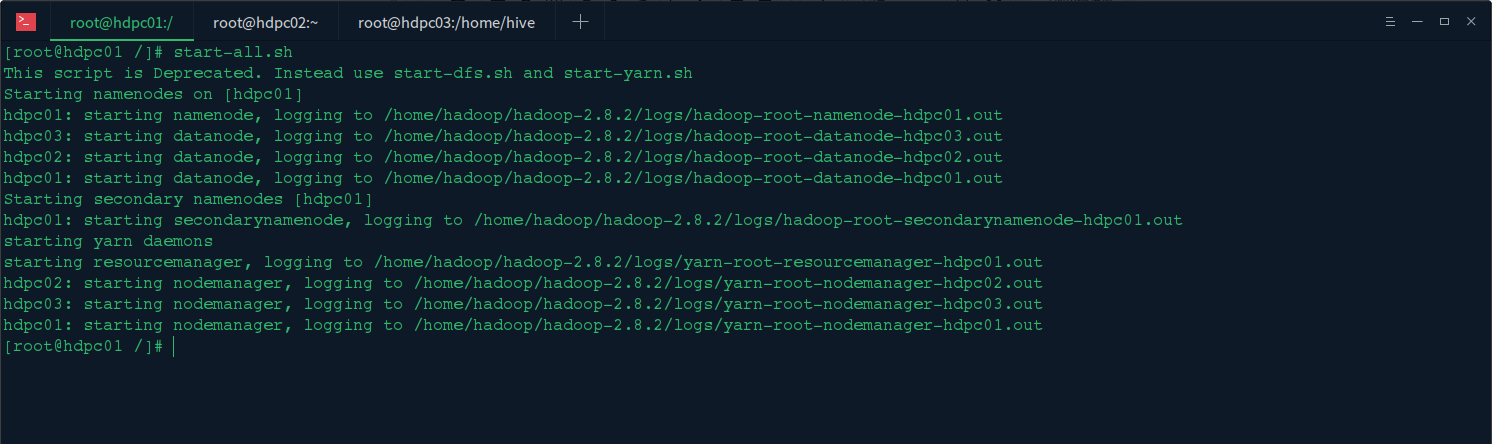
1.启动hadoop集群
在主节点上启动hadoop集群start-all.sh
2.启动元数据库服务
登陆元数据库服务所在主机,启动mysql服务service mysql start
3.启动hiveserver2服务
在hive机器上启动hiveserver服务:hive --service hiveserver2 或者hive --service hiveserver2 &

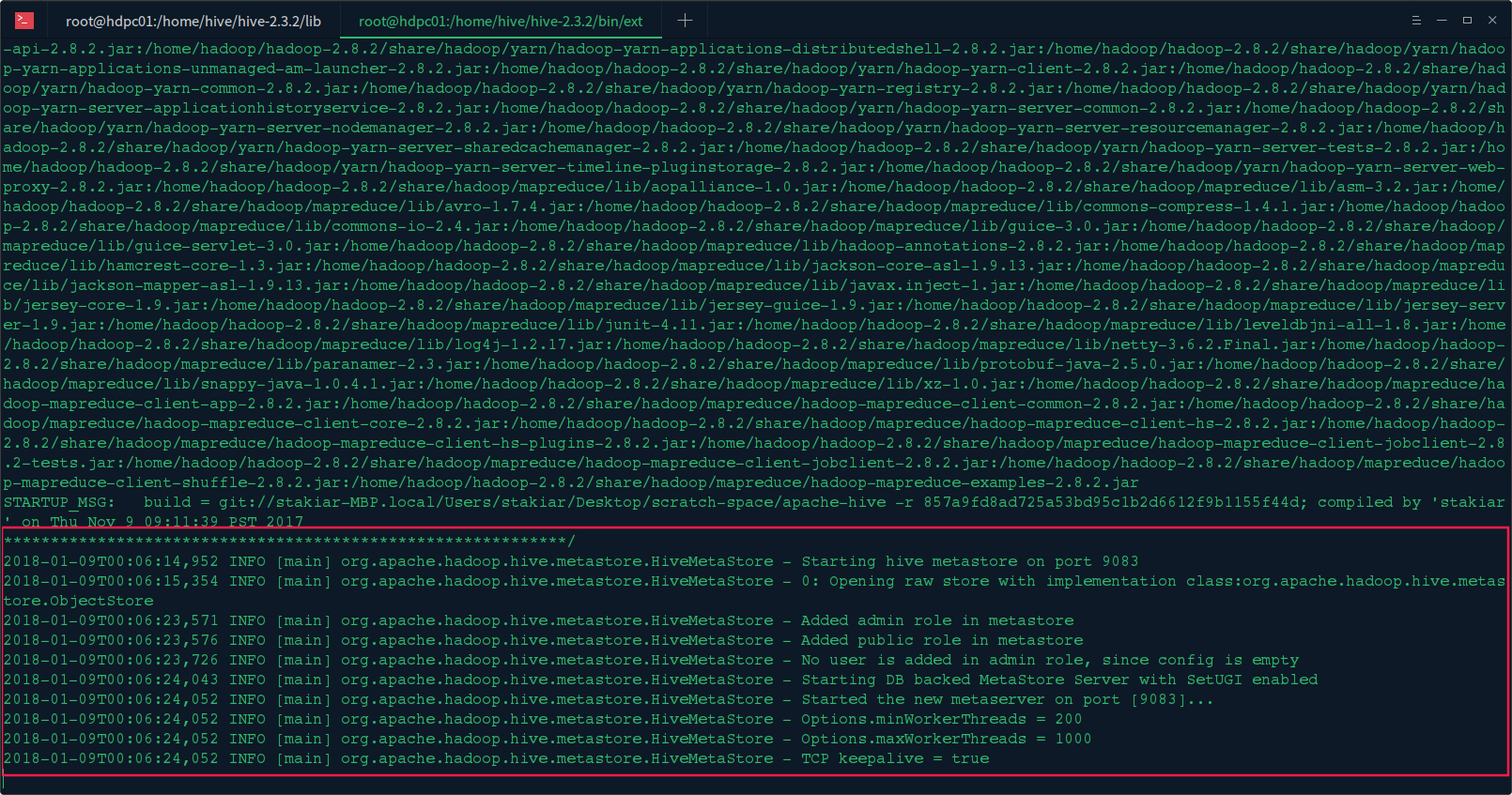
4.启动Hive Metastore服务
在hive机器上启动Hive Metastore服务:hive --service metastore或者hive --service metastore &

看到如下信息,说明启动完成:
5.验证启动
在终端输入jps -ml查看:

可以看到hadoop集群个hive服务启动都正常
三、连接配置
1.新建连接
打开dbeaver工具,点击文件——新建
在新建向导点击选择dbeaver—数据库连接
在数据库连接选择界面,点击选择hadoop—Apache Hive
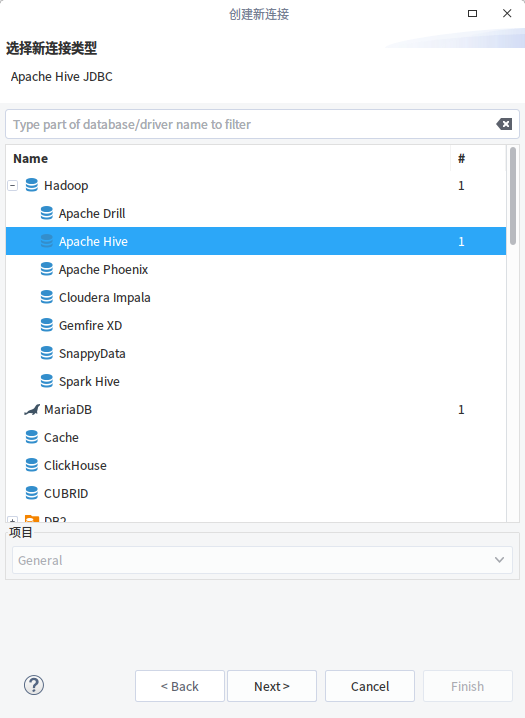
2.配置连接信息
在此处填写连接hive服务的信息,注意端口号是hive服务的10000,不是元数据库3306
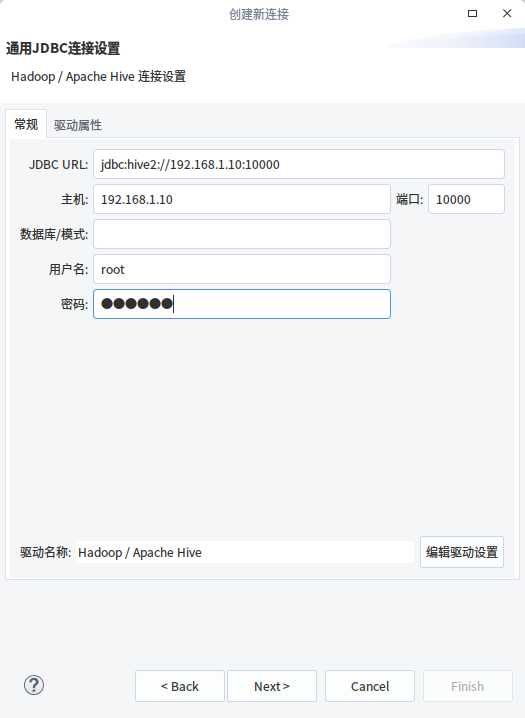
点击下一步,此时会自动下载hive的启动程序
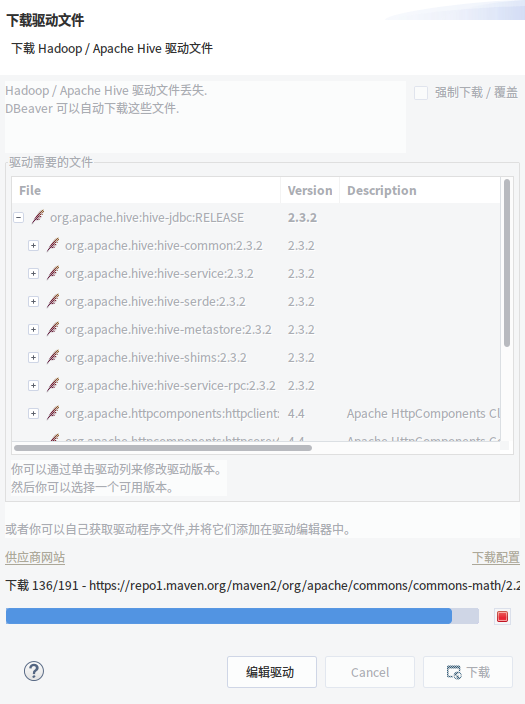
下一步网络配置我们默认就好,直接下一步
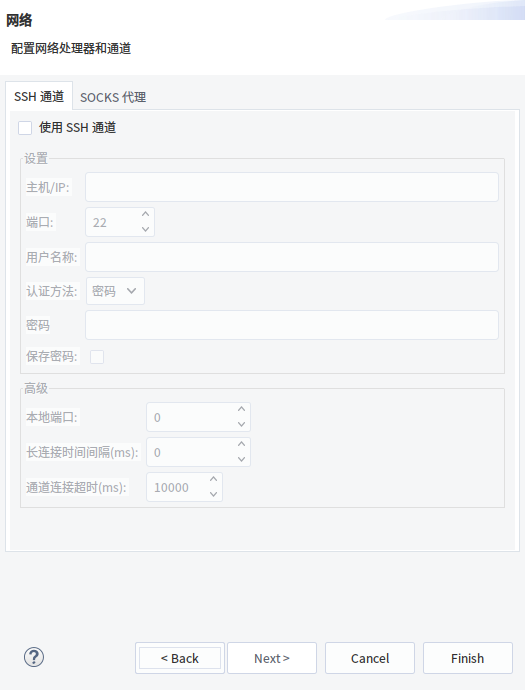
这一步没有特殊需求也默认配置,直接finish就可以了
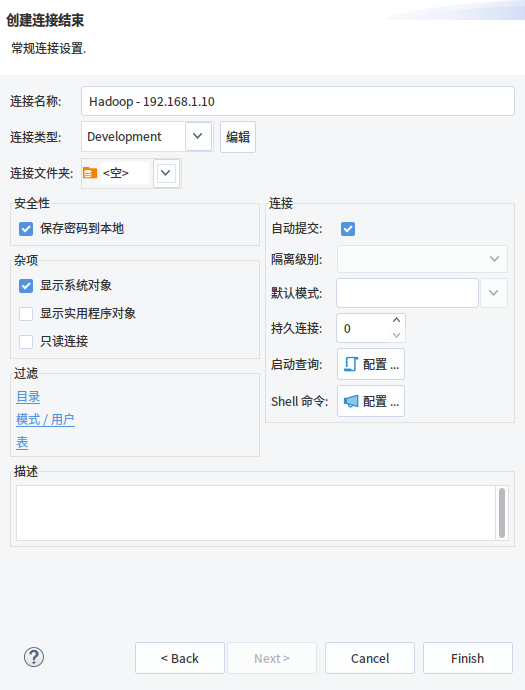
3.完成配置
经过以上的新建连接和配置连接,完成后就成功连接到hive了
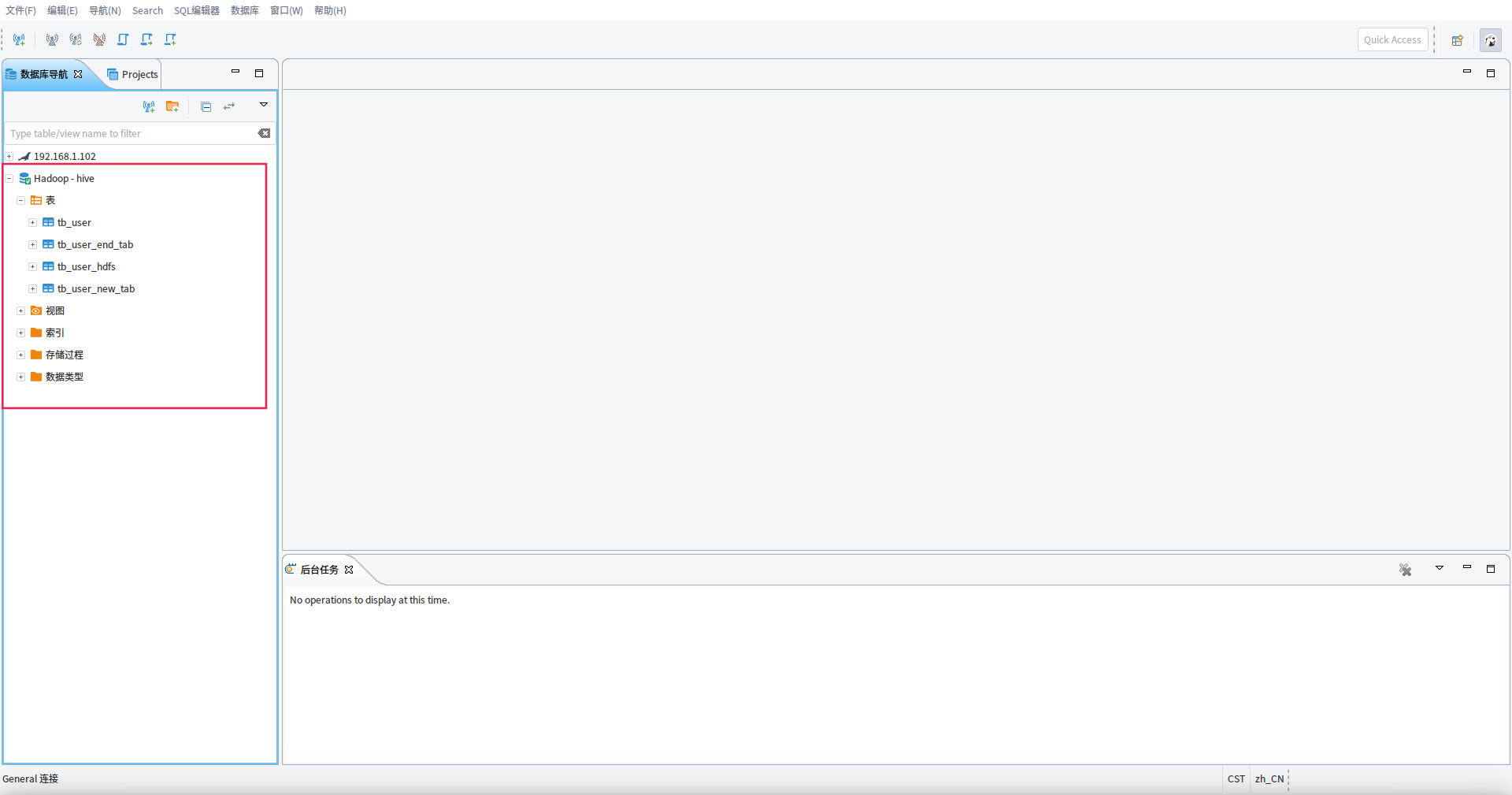
四、简单验证使用
我们使用dbeaver的sql编辑窗口编写sql语句测试几个查询操作
show tables
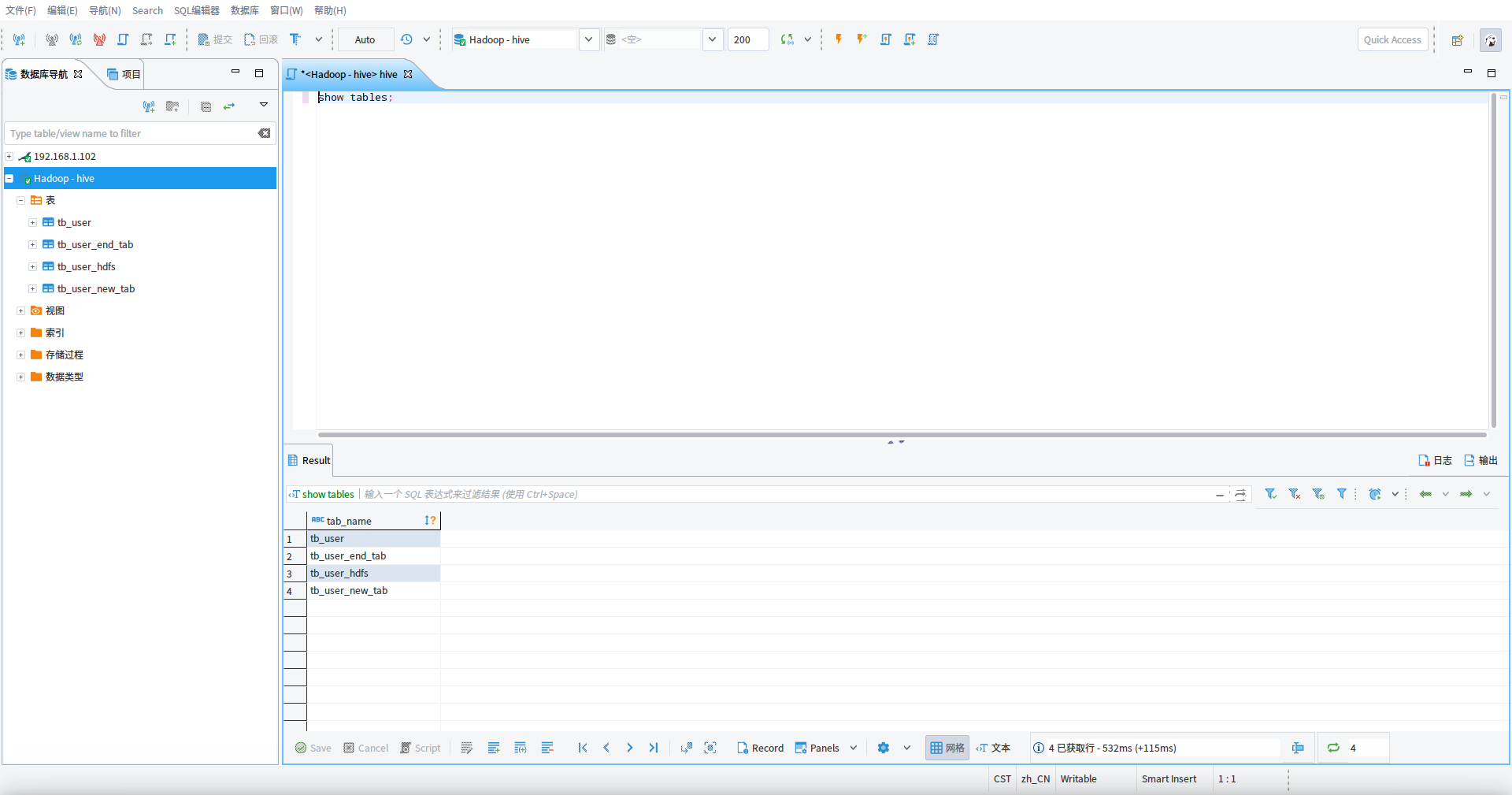
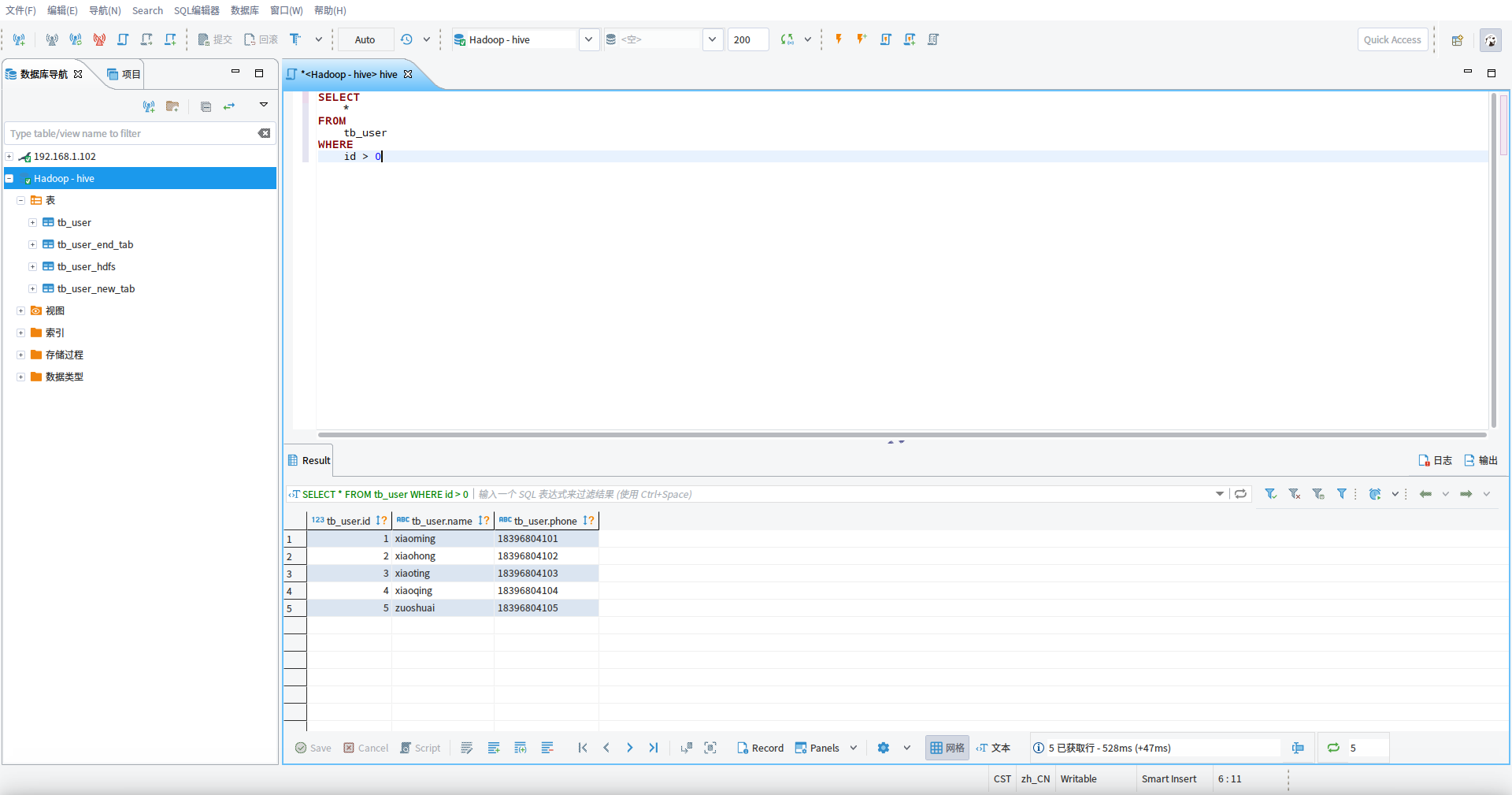
SELECT * FROM tb_user WHERE id > 0
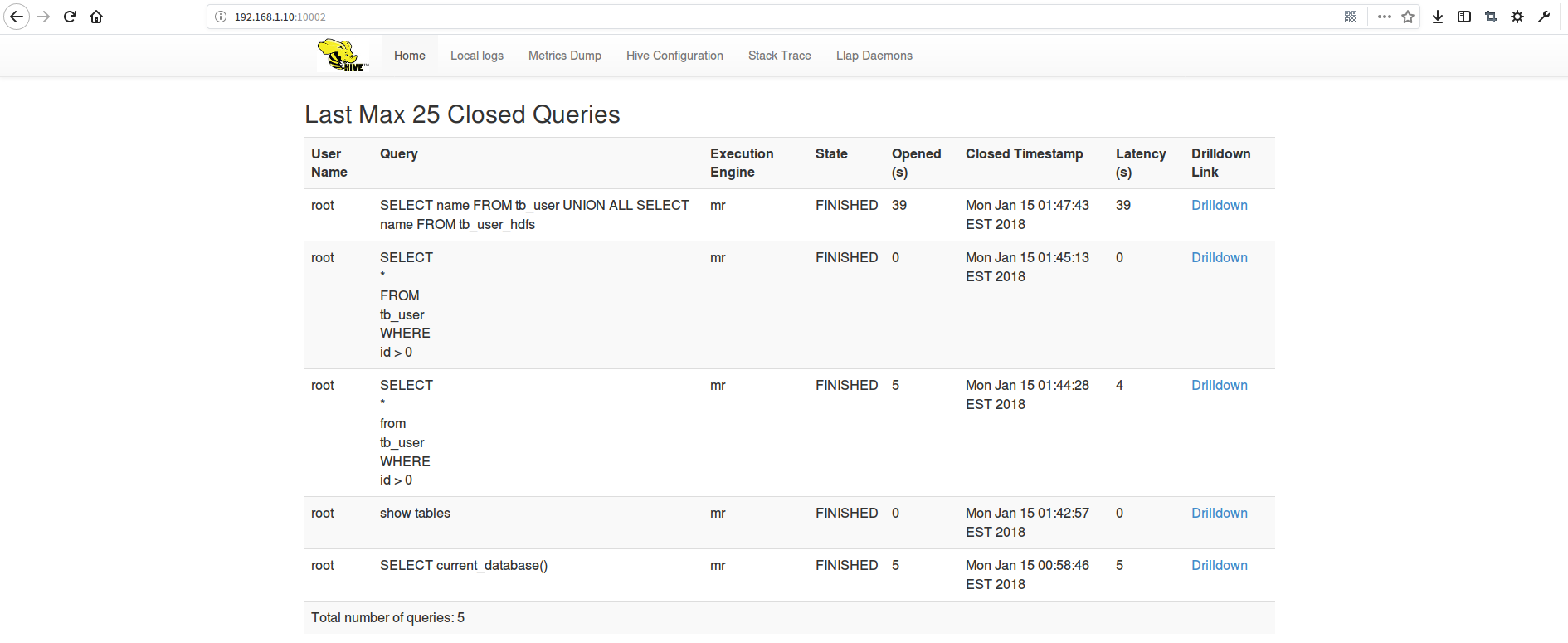
SELECT name FROM tb_user UNION ALL SELECT name FROM tb_user_hdfs
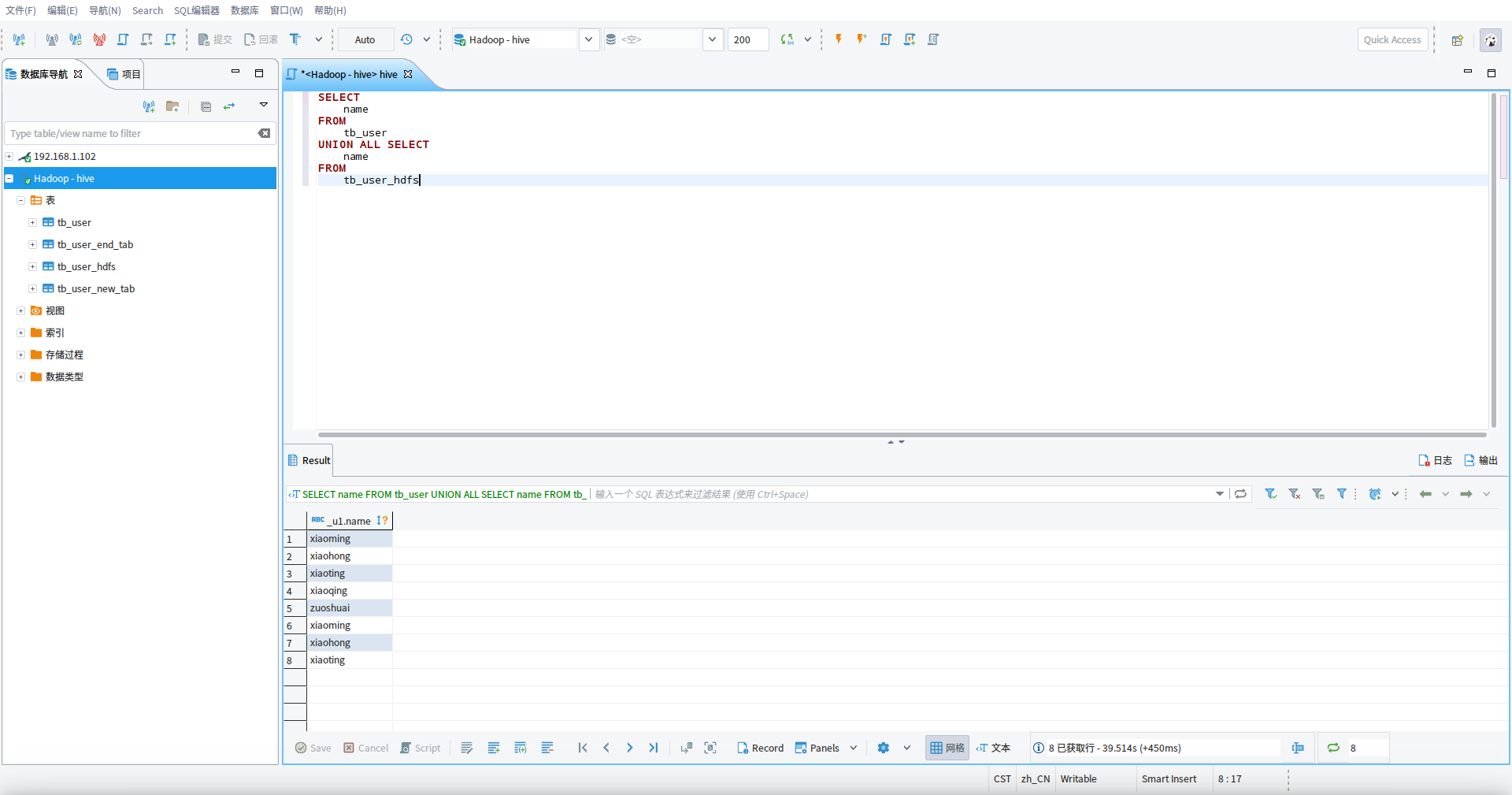
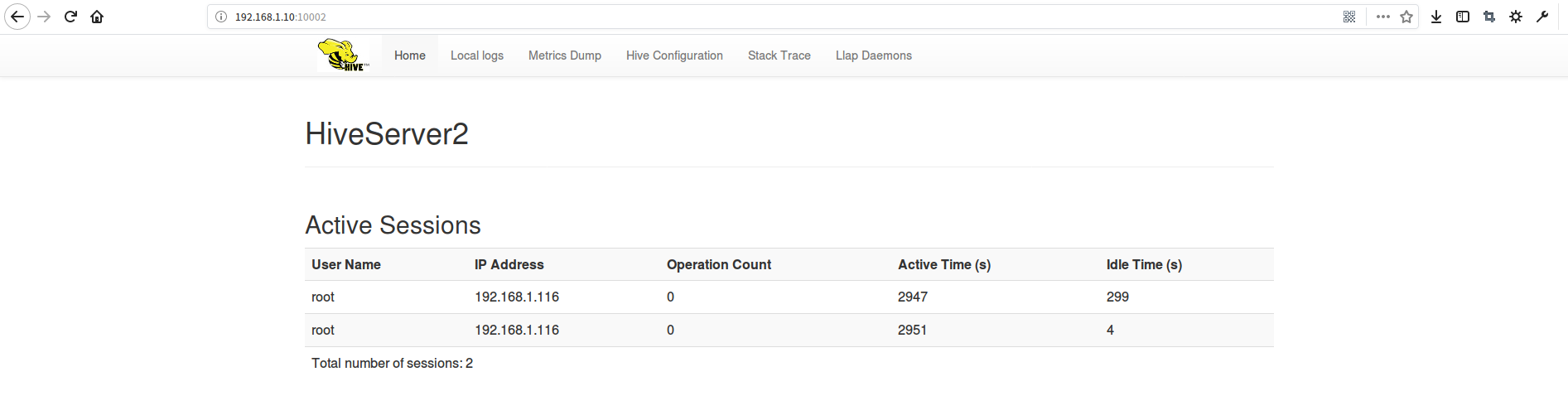
我们这时候打开hive的webui服务,可以看到我们的连接记录、查询操作记录等
五、总结
本文通过配置使用dbeaver连接hive服务,并且使用该工具进行了一些基本的查询 操作,可以看出和我们去操作数据库没什么区别,但是其实底层是不一样的,hive查询底层是转换成mapreduce任务去操作的,在后面的深入文章中我们会详细研究下其原理。

