当我们点开某个网站或某个新闻APP的时候,经常能看到这样的题目:“14亿人都不知道的真相,历史的血泪……”、“删前速看!XXX视频流出”等,可是当我们点进去的时候,往往会发现,都是标题党,文章和内容完全不符合!
如果这时候有一种工具能先替我们阅读新闻,再提炼出关键内容,那么我们肯定不会再受到标题党的影响,这对我们的生活无疑会有非常大的便利。而这需要的就是“文本摘要自动生成”技术!
文本摘要充斥着我们生活的方方面面,往小了说,新闻关键词的提炼是文本摘要;往宽泛看,文本摘要也可以应用在像Google、百度等搜索引擎的结果优化中,真正实现搜索中的“所见即所得”,“Smarter & Faster”。
主流的文本摘要方式
目前主流的文本摘要自动生成有两种方式,一种是抽取式(extractive),另一种是生成式 (abstractive)。
抽取式顾名思义,就是按照一定的权重,从原文中寻找跟中心思想最接近的一条或几条句子。而生成式则是计算机通读原文后,在理解整篇文章意思的基础上,按自己的话生成流畅的翻译。
抽取式的摘要目前已经比较成熟,但是抽取质量及内容流畅度均差强人意。伴随着深度学习的研究,生成式摘要的质量和流畅度都有很大的提升,但目前也受到原文本长度过长、抽取内容不佳等的限制。
文本摘要的发展概况
抽取式摘要是一种比较成熟的方案,其中Text rank排序算法以其简洁、高效的特点被工业界广泛运用。大体思想是先去除文章中的一些停用词,之后对句子的相似度进行度量,计算每一句相对另一句的相似度得分,迭代传播,直到误差小于0.0001。再对上述得到的关键语句进行排序,便能得到想要的摘要。抽取式摘要主要考虑单词词频,并没有过多的语义信息,像“猪八戒”,“孙悟空”这样的词汇都会被独立对待,无法建立文本段落中的完整语义信息。
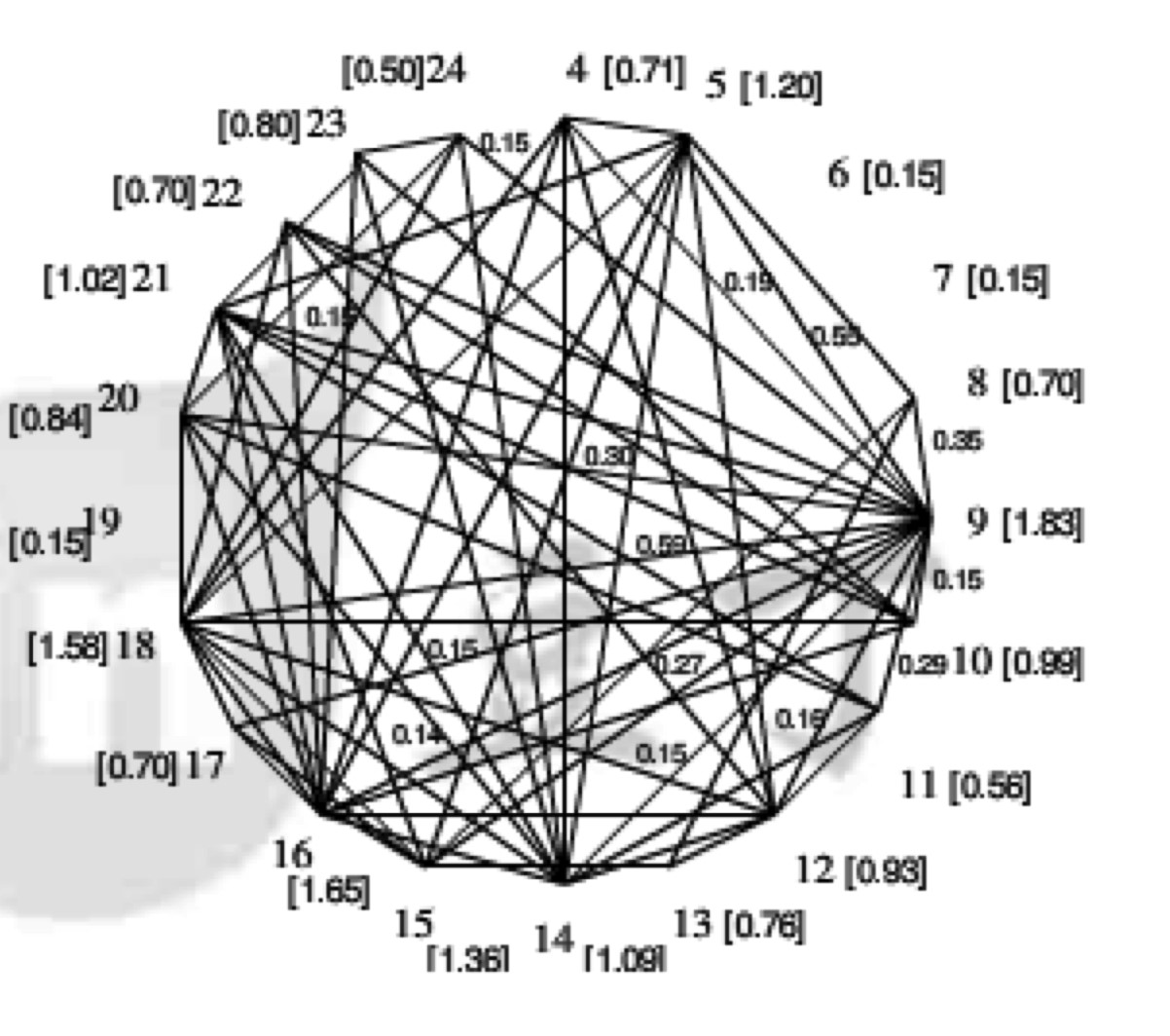
(Text rank原理如上图所示,根据句子的相似性进行排序打分。)
生成式文本摘要主要依靠深度神经网络结构实现,2014年由Google Brain团队提出的Sequence-to-Sequence序列,开启了NLP中端到端网络的火热研究。Sequence-to-Sequence又称为编、解码器(Encoder、Decoder)架构。其中Encoder、Decoder均由数层RNN/LSTM构成,Encoder负责把原文编码为一个向量C;Decoder负责从这个向量C中提取信息,获取语义,生成文本摘要。
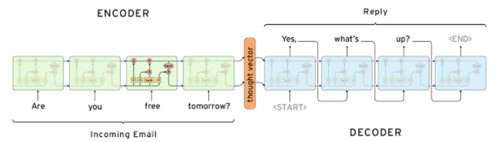
但是由于“长距离依赖”问题的存在,RNN到最后一个时间步输入单词的时候,已经丢失了相当一部分的信息。这时候编码生成的语义向量C同样也丢失了大量信息,就导致生成的摘要不够准确。
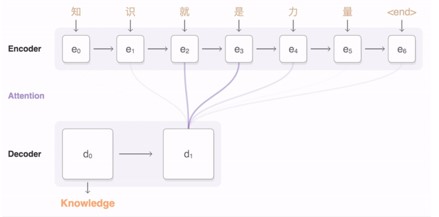
Bahdanau等人在14年发表的论文《Neural Machine Translation by Jointly Learning to Align and Translate》中,第一次将Attention机制应用于NLP中。Attention机制是一种注意力(资源)分配机制,在某个特定时刻,总是重点关注跟它相关的内容,其他内容则进行选择性忽视。就像下图,在翻译“Knowledge”时,只会关注“知识”.这样的对齐能让文本翻译或者摘要生成更具针对性。
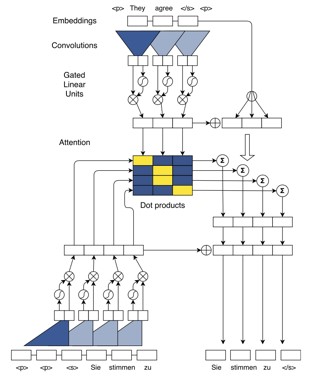
RNN/LSTM单元,由于每个词是按顺序输入网络的,所以会记录文章的序列信息。因此,大部分的NLP任务,都是采用的RNN架构。但是这也限制了网络训练及摘要生成的速度,因为RNN必须一个个输入,一个个生成,无法并行计算。2016年Facebook AI Research(FAIR)发表了《A Convolutional Encoder Model for Neural Machine Translation》,对Encoder部分采用似乎不擅长处理序列信息的卷积网络(CNN)来实现,结果在翻译、摘要任务中,也达到了当年的最高水准;
2017年5月,还是FAIR,发布了《Convolutional Sequence to Sequence Learning》,第一次实现了Encoder、Decoder都采用CNN单元,使得网络在训练阶段,可以并行计算,效率进一步提升。同时引入了Multi-step Attention(多跳注意),相比之前只在最后一层生成翻译时往回看,多跳注意使得Decoder阶段生成每一层的语义向量时都往回看,进一步提升了准确度。同时还有一些其他的Trick:引入单词的位置信息,残差网络,计算Attention时候对高层语义信息和低层细节信息,兼收并取等。最后在生成翻译和摘要时,速度相比之前最快的网络,提升了近9倍。同时在WMT-14英德、英法两项的单模型训练结果中,BLEU得分达到了25.16、40.46,其中英法翻译也是迄今为止的最高得分。
时隔一个月,17年6月,Google团队发布了名为《Attention Is All You Need》的文章,即不用CNN和RNN单元,只用Self-Attention和Encoder-Decoder Attention,就完全实现了端到端的翻译任务。并且在WMT-14英德、英法翻译任务中,BLEU值达到了28.4和41.0的高分。因为同样可以并行计算,模型的训练及生成速度也有所提升。Self-Attention相比于之前的模型更加关注句子的内部结构,也就是word-pairs的信息,附图是论文中Attention可视化的结果,可以发现仅在源文端,模型便学习到了“making more difficult”的word-pairs信息。
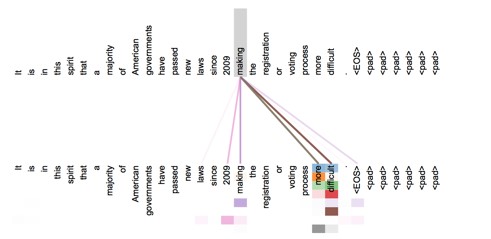
同理对目标端,模型也会单独学习句子的内部结构信息。之后利用Encoder-Decoder Attention建立源文和目标词组、句子的对应关系。相比于FAIR 的卷积模型到很高层才能看到句子的完整信息,Self-Attention在第一层便巧妙地建立了每个词和整个句子的联系,同时位置编码采用三角函数的相对位置法表示,理论上可以泛化到训练中未见过的更长长度句子的翻译中。目前Self-Attention仅用在了翻译任务中,但这样的思想,在文本摘要自动生成的任务中,也是可以参照的。
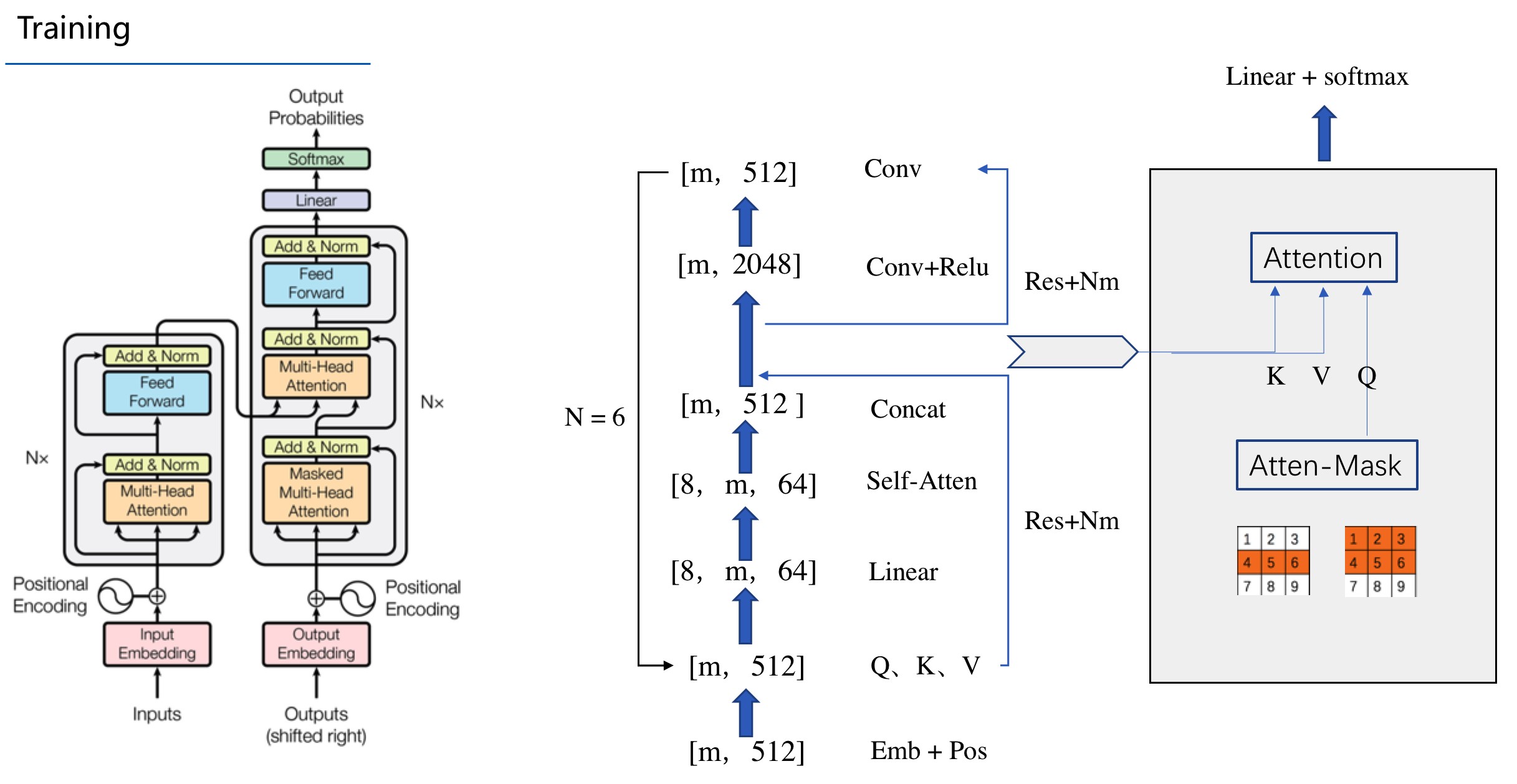
(Google Transformer模型的拆解)
总结:
从传统的Textrank抽取式,到深度学习中采用RNN、CNN单元处理,再引入Attention、Self-Attention、机器生成摘要的方式,这些跟人类思维越来越像,都建立在对整段句子的理解之上。与此同时生成摘要的效果,也常常让我们惊艳。
但文本摘要自动生成依然还有很多难题,比如如果段落太长,那么机器对段落的理解时间就要很长, 而过长的时间会导致机器对段落信息的记忆的损失。而且深度学习非常依赖有标签的样本,标注工作也是一笔非常大的开销。
总的来说,文本摘要自动生成是个非常具有前景但也非常具有挑战性的技术。
联系我们,关注图鸭微信公众号


