采用问答的方式对常见的问题进行整理小结
I. Map篇
0. 什么是Map
看到这个有点懵逼,一时还真不知道怎么解释,能让完全没有接触过的人都能听懂
想到生活中一个有意思的场景,和我们使用Map非常像,拿着新华词典查字
我们这里以拼音方式查询字时,一般步骤如下:
- 首先后获取字的拼音
- 通过拼音,查询到字对应的页码
- 在页码中查到对应的字的解释
再转换看一下Map的工作原理(主要是HashMap)
-
通过hash()计算key,得出一个hash值(同字转拼音)
-
通过hash值,获取Node在数组中的索引 (同通过拼音获取页码)
-
获取Node,然后遍历Node#next,查到我们需要的节点(同在页码中找到对应的字)
- 这里获取的Node是一个链表头(jdk8中做过优化,可能为红黑树,为简单起见,以链表说明),如果没有hash碰撞,这个链表就一个节点;若hash碰撞了,则将这些碰撞的节点串成一个链表
1. 常见的map有那些
JDK中实现了一些能够覆盖绝大部分场景的Map容器,罗列一些常见的如下
HashMap: 主要是利用key的hash来定位对应的元素HashTableEnumMap : key为枚举的map,根据枚举的ordinal作为定位对应的元素 (用的比较少,后面不纳入分析范畴)TreeMapLinkedHashMapConcurrentHashMap
2. 根据不同的分类方式,对上面的map进行划分
根据是否线程安全进行分类
| 线程安全 | 非线程安全 |
|---|
HashTable, ConcurrentHashMap | HashMap, TreeMap, LinkedHashMap |
根据Map是否有序进行分类
| 有序 | 无序 |
|---|
TreeMap, LinkedHashMap | HashMap, ConcurrentHashMap, HashTable |
根据key怎么获取对应的元素
| hash定位 | 其他定位 |
|---|
HashTable, ConcurrentHashMap, HashMap, LinkedHashMap | TreeMap |
TreeMap比较有意思,要求指定一个比较器,或者key可自比较,而且如果塞入两个不同的kv对,但是key通过比较器发现相等时,会用后入的kv对中的value替换前面的那个,即定位是根据比较器来的
根据底层数据结构进行分类
| 数组+链表 | 树 |
|---|
HashTable, ConcurrentHashMap, HashMap, LinkedHashMap | TreeMap |
3. HashMap怎么用,如何实现的
>>> 如何使用
最最常见的使用方式,三把斧即可,如下
// 1. 创建一个Map对象 Map<String, String> map = new HashMap<>(); // 2. 塞入kv数据对 map.put("key", "value"); // 3. 取出key对应的数据 String value = map.get("key");
其次就是使用的注意事项
- Map中key和value都可以为null,但是如若不是需求场景中,必须要塞null,否则就不要这么干;因为使用时,如果漏了null判断,非常容易产生npe
- 如果能知道这个Map中大概会存多少数据,就在初始化时,指定容量(避免频繁的扩容,导致的性能开销)
- 非线程安全(如需要线程安全,采用
ConcurrentHashMap,不要用HashTable) - 无序(如需要有序,采用
TreeMap, LinkedHashMap,实际后者用得更多)
此外分享一个实际项目中关于HashMap的一个优化点
一般来说,HashMap的get(key)方法是O(1)时间开销,但是由于获取对应value,会频繁的计算hash值,且不可避免的会产生Hash碰撞,这些都是会有额外的开销(cpu和时间开销)
我们的一个应用中,存在大量的配置开关(用与各种预案,各种场景的切换)存在一个大的HashMap中,导致每次提供服务时,都会去这个Map中多次查询Map中的配置值,我们做的优化是将Map映射到一个配置类,以此减少频繁的hash操作
遗憾的是最后性能提升并不是特别明显,也就1-2毫秒的样子...(如果系统的rt要求特别严格的可以考虑从这个方面出发)
>>> 如何实现的
简单来讲,从两个点出发,一是数据结构,二是如何向其中添加和取数据
底层存储结构如下图:
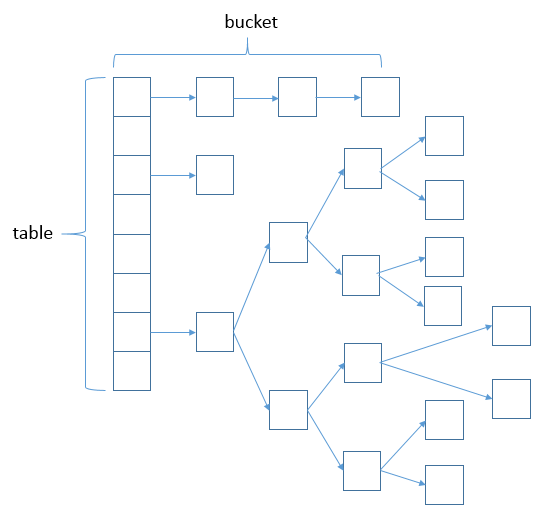
数组+链表(or红黑树),数组的容量,必然为2的n次方
读写数据:
- 通过hash方法获取key对应的hash值
- hash值对数组长度取模,即为kv可能在数组中出现位置
- 获取数组中对应索引的元素Node,判断是否为我们需要的
- 判断规则:hash值相同,key相同,or
equals()判断相等 - 若Node不满足,则判断Node#next对应的Node节点
- 直到找到匹配的值,or压根就木有时,才返回
另外一点就是扩容
- 当塞入一个数据后,Map中元素的个数大于
capacity * loadFactor (一般是容量*0.75),则数组会出现扩容,扩为原来的两倍 - 扩容后,原来的Node节点可能会向后移(新的索引为hash值对新的容量取模)
4. HashTable和ConcurrentHashMap的安全保证是怎样的,有什么区别
两者都是线程安全的,但底层的实现原理确实完全不同
HashTable - 所有方法上加上
synchronized 关键字,实行加锁同步
ConcurrentHashMap - 写使用分段锁机制,把整个哈希表切分成段segment(默认为16段),每段有一个锁,最多可以同时有16个写线程。而读不受限制
5. HashMap是否有序,如何保证有序
HashMap无序,但实际的业务场景中,需要有序的地方还不少,一般来将,常见的顺序要求是根据先后塞入Map容器的顺序来确定,此时可以考虑采用 LinkedHashMap,确保先塞入Map的,在遍历时,优先出来
如果有比较复杂的排序场景,则可以采用TreeMap,使用的时候需要额外注意一些使用事项
6. 几种遍历方式
一般遍历就是下面三中场景了
// 遍历kv for(Map.Entry<String, String> entry: map.entrySet()) { // .... } // 遍历key值 for(Object key : map.keySet()) { // xxx } // 遍历value值 for(Object value: map.values()) { // xxxx }
根据不同的场景选择遍历方式
- 如果需要kv,则遍历EntrySet
- 如果只需要key, 则遍历 KeySet
- 如果只需要value,则遍历 ValueSet
上面的遍历过程中,都是不允许对Map进行增删操作的,否则会抛一个并发修改异常;如果在遍历过程中,需要根据对应的值,做一些处理,采用迭代器方式, 一个demo如下
Map<String, String> map = new HashMap<>(); // .... Iterator<Map.Entry<String, String>> iterator = map.entrySet().iterator(); while (iterator.hasNext()) { Map.Entry<String, String> entry = iterator.next(); iterator.remove(); iterator.next(); }
7. 如何设计一个线程安全的HashMap
蛋疼的问题,真要自己来设计的话,最简单的就是HashTable这种全加锁的机制;但是这种实际是强制使多线程串行工作了,如果需要并发工作呢?
除了ConcurrentHashMap的锁分段机制,感觉可以参考CopyOnWriteArrayList的实现方式,来一个CopyOnWriteHashMap,对写进行加锁,读无锁,具体的实现,有待完善...
Java分享,关注小灰灰Blog