前言
推荐算法有很多,最基础的就是协同过滤,前段时间对KTV数据比较感兴趣,大家去唱歌也只是唱熟悉的歌,那是不是有办法给大家一些建议拓展一下唱歌的宽度呢。KTV推荐可能要考虑很多因素,比如唱歌者的音域,年龄,地区,喜好,等等。第一版算法暂时只从item base的角度出发去给用户推荐。由于是个人兴趣,所以没有模型反馈迭代的过程,有兴趣的可以自己实现。
协同过滤算法
协同过滤又叫行为相似召回,其实就是基于共现的一种相似度计算。 Item Base的协同过滤算法有几个关键概念:
相似度计算
相似度计算有很多种:共现相似度,欧几里得距离,皮尔逊相关系数,等等这里使用的是共现相似度,公式如下:
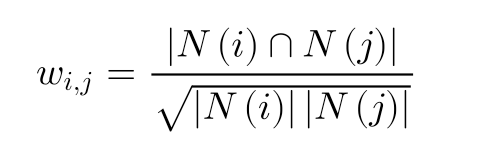
其中N(i)为喜欢i歌曲的用户数,同样N(j)为喜欢j歌曲的用户数,分子为同时喜欢i,j的用户数。该公式为改良公式,分子中加入了N(j)对相似度进行惩罚。这里不细讲。
ItemBase和UserBase
UserBase
寻找兴趣相似的用户,然后将偏好相同的用户的歌曲推荐给被推荐用户,表中发现A和C用户都喜欢i和k歌曲所以两个用户相似,所以将C用户的歌曲l推荐给A用户。如果用共现的方式去表述就是。这里细节计算的时候会涉及到用户打分和相似用户数据排序汇总。我这里都是概述。
| 用户/歌曲 |
歌曲i |
歌曲j |
歌曲k |
歌曲l |
| 用户A |
1 |
|
1 |
推荐 |
| 用户B |
|
1 |
|
|
| 用户C |
1 |
|
1 |
1 |
ItemBase
与UserBase类似,计算相似的时候使用的是歌曲矩阵找到相似的歌曲,然后根据用户历史数据进行推荐,大概原理如下表。表中发现i,k歌曲同事被A,B两个用户喜欢,所以i,k相似,如果C用户喜欢i歌曲那么他应该也喜欢相似的k歌曲.
| 用户/歌曲 |
歌曲i |
歌曲j |
歌曲k |
| 用户A |
1 |
|
1 |
| 用户B |
1 |
1 |
1 |
| 用户C |
1 |
|
推荐 |
这里使用的是ItemBase
算法实现
得到用户对歌曲的one hot矩阵
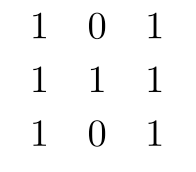
计算得到歌曲对歌曲的共现度矩阵
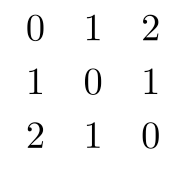
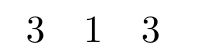

推荐
如果用户喜欢i歌曲则

得到推荐歌曲为k歌曲
代码实现
获取数据
import elasticsearch
import elasticsearch.helpers
import re
import numpy as np
import operator
def trim_song_name(song_name):
"""
处理歌名,过滤掉无用内容和空白
"""
song_name = song_name.strip()
song_name = re.sub("-?【.*?】", "", song_name)
song_name = re.sub("-?(.*?)", "", song_name)
song_name = re.sub("-?(.*?)", "", song_name)
return song_name
def get_data(size=0):
"""
获取uid=>作品名list的字典
"""
cur_size=0
ret = {}
es_client = elasticsearch.Elasticsearch()
search_result = elasticsearch.helpers.scan(
es_client,
index="ktv_works",
doc_type="ktv_works",
scroll="10m",
query={}
)
all_songs_list = []
all_songs_set = set()
for hit_item in search_result:
cur_size += 1
if size>0 and cur_size>size:
break
item = hit_item['_source']
work_list = item['item_list']
ret[item['uid']] = [trim_song_name(item['songname']) for item in work_list]
return ret
def get_uniq_song_sort_list(song_dict):
"""
合并重复歌曲并按歌曲名排序
"""
return sorted(list(set(np.concatenate(list(song_dict.values())).tolist())))
相似度计算
import math
# 共现数矩阵
col_show_count_matrix = np.zeros((song_count, song_count))
one_trik_matrix = np.zeros(song_count)
for i in range(song_count):
for j in range(song_count):
if i>j: # 对角矩阵只计算一半的矩阵
one_trik_matrix = np.zeros(song_count)
one_trik_matrix[i] = 1
one_trik_matrix[j] = 1
ret_m = user_song_one_hot_matrix.dot(one_trik_matrix.T)
col_show_value = len([ix for ix in ret_m if ix==2])
col_show_count_matrix[i,j] = col_show_value
col_show_count_matrix[j,i] = col_show_value
# 相似度矩阵
col_show_rate_matrix = np.zeros((song_count, song_count))
# 歌曲count N(i)矩阵
song_count_matrix = np.zeros(song_count)
for i in range(song_count):
song_col = user_song_one_hot_matrix[:,i]
song_count_matrix[i] = len([ix for ix in song_col if ix>=1])
# 相似度矩阵计算
for i in range(song_count):
for j in range(song_count):
if i>j: # 对角矩阵只计算一半的矩阵
# 相似度计算 N(i)nN(j)/sqart(N(i)*N(j))
rate_value = col_show_count_matrix[i,j]/math.sqrt(song_count_matrix[i]*song_count_matrix[j])
col_show_rate_matrix[i,j] = rate_value
col_show_rate_matrix[j,i] = rate_value
推荐
import operator
def get_songs_from_recommand(col_recommand_matrix):
return [(int_to_song[k],r_value) for k,r_value in enumerate(col_recommand_matrix) if r_value>0]
input_song = "十年"
# 构造被推荐矩阵
one_trik_matrix = np.zeros(song_count)
one_trik_matrix[song_to_int[input_song]] = 1
col_recommand_matrix = col_show_rate_matrix.dot(one_trik_matrix.T)
recommand_array = get_songs_from_recommand(col_recommand_matrix)
sorted_x = sorted(recommand_array, key=lambda k:k[1], reverse=True)
# 获取推荐结果
print(sorted_x)
结果
[('三生三世', 0.5773502691896258), ('下个路口见', 0.5773502691896258), ('不分手的恋爱', 0.5773502691896258),...]

