背景
Jdk给我们提供了大量的map来供我们研发使用。通常情况下我们使用HashMap
需要插入顺序或者访问我们可以使用LinkedHashMap 需要排序我们可以使用TreeMap
并发场景下我们可以使用ConcurrentSkipListMap
介绍
跳表这种数据结构相对来说大家都比较陌生,大学里面基本也没有相关的数据结构老师教过。
对于常见的数据结构 大家最熟悉的就是数组和链表 基本上增删改查不在话下
而对于其他的数据结构 比如二叉树 平衡树 红黑树 2-3树 等等可能就没那么容易了

相比较其他数据结构的难度 跳表这种就相对十分容易实现了。讲真话其他的数据结构一般业务程序员不用搜索引擎不翻书基本都会翻车。
初次接触该数据结构是在使用redis中后期在LevelDB的使用中也接触到了该数据结构。
SkipList顾名思义还是和List有关
一个简单的链表是这样的

那么跳表大概是长这样的

其抽象出来的模型应该如图

跳表具有如下性质:
(1) 由很多层结构组成
(2) 每一层都是一个有序的链表
(3) 最底层(Level 1)的链表包含所有元素
(4) 如果一个元素出现在 Level i 的链表中,则它在 Level i 之下的链表也都会出现。
(5) 每个节点包含两个指针,一个指向同一链表中的下一个元素,一个指向下面一层的元素。
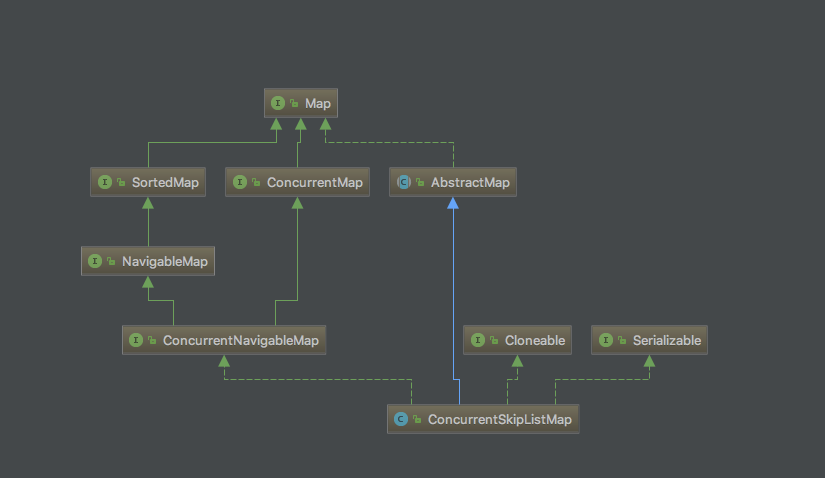
源码
惯例先上类图
类图
/* * This class implements a tree-like two-dimensionally linked skip * list in which the index levels are represented in separate * nodes from the base nodes holding data. There are two reasons * for taking this approach instead of the usual array-based * structure: 1) Array based implementations seem to encounter * more complexity and overhead 2) We can use cheaper algorithms * for the heavily-traversed index lists than can be used for the * base lists. Here's a picture of some of the basics for a * possible list with 2 levels of index: * * Head nodes Index nodes * +-+ right +-+ +-+ * |2|---------------->| |--------------------->| |->null * +-+ +-+ +-+ * | down | | * v v v * +-+ +-+ +-+ +-+ +-+ +-+ * |1|----------->| |->| |------>| |----------->| |------>| |->null * +-+ +-+ +-+ +-+ +-+ +-+ * v | | | | | * Nodes next v v v v v * +-+ +-+ +-+ +-+ +-+ +-+ +-+ +-+ +-+ +-+ +-+ +-+ * | |->|A|->|B|->|C|->|D|->|E|->|F|->|G|->|H|->|I|->|J|->|K|->null * +-+ +-+ +-+ +-+ +-+ +-+ +-+ +-+ +-+ +-+ +-+ +-+ * * The base lists use a variant of the HM linked ordered set * algorithm. See Tim Harris, "A pragmatic implementation of * non-blocking linked lists" * http://www.cl.cam.ac.uk/~tlh20/publications.html and Maged * Michael "High Performance Dynamic Lock-Free Hash Tables and * List-Based Sets" * http://www.research.ibm.com/people/m/michael/pubs.htm. The * basic idea in these lists is to mark the "next" pointers of * deleted nodes when deleting to avoid conflicts with concurrent * insertions, and when traversing to keep track of triples * (predecessor, node, successor) in order to detect when and how * to unlink these deleted nodes. * * Rather than using mark-bits to mark list deletions (which can * be slow and space-intensive using AtomicMarkedReference), nodes * use direct CAS'able next pointers. On deletion, instead of * marking a pointer, they splice in another node that can be * thought of as standing for a marked pointer (indicating this by * using otherwise impossible field values). Using plain nodes * acts roughly like "boxed" implementations of marked pointers, * but uses new nodes only when nodes are deleted, not for every * link. This requires less space and supports faster * traversal. Even if marked references were better supported by * JVMs, traversal using this technique might still be faster * because any search need only read ahead one more node than * otherwise required (to check for trailing marker) rather than * unmasking mark bits or whatever on each read. * * This approach maintains the essential property needed in the HM * algorithm of changing the next-pointer of a deleted node so * that any other CAS of it will fail, but implements the idea by * changing the pointer to point to a different node, not by * marking it. While it would be possible to further squeeze * space by defining marker nodes not to have key/value fields, it * isn't worth the extra type-testing overhead. The deletion * markers are rarely encountered during traversal and are * normally quickly garbage collected. (Note that this technique * would not work well in systems without garbage collection.) * * In addition to using deletion markers, the lists also use * nullness of value fields to indicate deletion, in a style * similar to typical lazy-deletion schemes. If a node's value is * null, then it is considered logically deleted and ignored even * though it is still reachable. This maintains proper control of * concurrent replace vs delete operations -- an attempted replace * must fail if a delete beat it by nulling field, and a delete * must return the last non-null value held in the field. (Note: * Null, rather than some special marker, is used for value fields * here because it just so happens to mesh with the Map API * requirement that method get returns null if there is no * mapping, which allows nodes to remain concurrently readable * even when deleted. Using any other marker value here would be * messy at best.) * * Here's the sequence of events for a deletion of node n with * predecessor b and successor f, initially: * * +------+ +------+ +------+ * ... | b |------>| n |----->| f | ... * +------+ +------+ +------+ * * 1. CAS n's value field from non-null to null. * From this point on, no public operations encountering * the node consider this mapping to exist. However, other * ongoing insertions and deletions might still modify * n's next pointer. * * 2. CAS n's next pointer to point to a new marker node. * From this point on, no other nodes can be appended to n. * which avoids deletion errors in CAS-based linked lists. * * +------+ +------+ +------+ +------+ * ... | b |------>| n |----->|marker|------>| f | ... * +------+ +------+ +------+ +------+ * * 3. CAS b's next pointer over both n and its marker. * From this point on, no new traversals will encounter n, * and it can eventually be GCed. * +------+ +------+ * ... | b |----------------------------------->| f | ... * +------+ +------+ * * A failure at step 1 leads to simple retry due to a lost race * with another operation. Steps 2-3 can fail because some other * thread noticed during a traversal a node with null value and * helped out by marking and/or unlinking. This helping-out * ensures that no thread can become stuck waiting for progress of * the deleting thread. The use of marker nodes slightly * complicates helping-out code because traversals must track * consistent reads of up to four nodes (b, n, marker, f), not * just (b, n, f), although the next field of a marker is * immutable, and once a next field is CAS'ed to point to a * marker, it never again changes, so this requires less care. * * Skip lists add indexing to this scheme, so that the base-level * traversals start close to the locations being found, inserted * or deleted -- usually base level traversals only traverse a few * nodes. This doesn't change the basic algorithm except for the * need to make sure base traversals start at predecessors (here, * b) that are not (structurally) deleted, otherwise retrying * after processing the deletion. * * Index levels are maintained as lists with volatile next fields, * using CAS to link and unlink. Races are allowed in index-list * operations that can (rarely) fail to link in a new index node * or delete one. (We can't do this of course for data nodes.) * However, even when this happens, the index lists remain sorted, * so correctly serve as indices. This can impact performance, * but since skip lists are probabilistic anyway, the net result * is that under contention, the effective "p" value may be lower * than its nominal value. And race windows are kept small enough * that in practice these failures are rare, even under a lot of * contention. * * The fact that retries (for both base and index lists) are * relatively cheap due to indexing allows some minor * simplifications of retry logic. Traversal restarts are * performed after most "helping-out" CASes. This isn't always * strictly necessary, but the implicit backoffs tend to help * reduce other downstream failed CAS's enough to outweigh restart * cost. This worsens the worst case, but seems to improve even * highly contended cases. * * Unlike most skip-list implementations, index insertion and * deletion here require a separate traversal pass occuring after * the base-level action, to add or remove index nodes. This adds * to single-threaded overhead, but improves contended * multithreaded performance by narrowing interference windows, * and allows deletion to ensure that all index nodes will be made * unreachable upon return from a public remove operation, thus * avoiding unwanted garbage retention. This is more important * here than in some other data structures because we cannot null * out node fields referencing user keys since they might still be * read by other ongoing traversals. * * Indexing uses skip list parameters that maintain good search * performance while using sparser-than-usual indices: The * hardwired parameters k=1, p=0.5 (see method randomLevel) mean * that about one-quarter of the nodes have indices. Of those that * do, half have one level, a quarter have two, and so on (see * Pugh's Skip List Cookbook, sec 3.4). The expected total space * requirement for a map is slightly less than for the current * implementation of java.util.TreeMap. * * Changing the level of the index (i.e, the height of the * tree-like structure) also uses CAS. The head index has initial * level/height of one. Creation of an index with height greater * than the current level adds a level to the head index by * CAS'ing on a new top-most head. To maintain good performance * after a lot of removals, deletion methods heuristically try to * reduce the height if the topmost levels appear to be empty. * This may encounter races in which it possible (but rare) to * reduce and "lose" a level just as it is about to contain an * index (that will then never be encountered). This does no * structural harm, and in practice appears to be a better option * than allowing unrestrained growth of levels. * * The code for all this is more verbose than you'd like. Most * operations entail locating an element (or position to insert an * element). The code to do this can't be nicely factored out * because subsequent uses require a snapshot of predecessor * and/or successor and/or value fields which can't be returned * all at once, at least not without creating yet another object * to hold them -- creating such little objects is an especially * bad idea for basic internal search operations because it adds * to GC overhead. (This is one of the few times I've wished Java * had macros.) Instead, some traversal code is interleaved within * insertion and removal operations. The control logic to handle * all the retry conditions is sometimes twisty. Most search is * broken into 2 parts. findPredecessor() searches index nodes * only, returning a base-level predecessor of the key. findNode() * finishes out the base-level search. Even with this factoring, * there is a fair amount of near-duplication of code to handle * variants. * * For explanation of algorithms sharing at least a couple of * features with this one, see Mikhail Fomitchev's thesis * (http://www.cs.yorku.ca/~mikhail/), Keir Fraser's thesis * (http://www.cl.cam.ac.uk/users/kaf24/), and Hakan Sundell's * thesis (http://www.cs.chalmers.se/~phs/). * * Given the use of tree-like index nodes, you might wonder why * this doesn't use some kind of search tree instead, which would * support somewhat faster search operations. The reason is that * there are no known efficient lock-free insertion and deletion * algorithms for search trees. The immutability of the "down" * links of index nodes (as opposed to mutable "left" fields in * true trees) makes this tractable using only CAS operations. * * Notation guide for local variables * Node: b, n, f for predecessor, node, successor * Index: q, r, d for index node, right, down. * t for another index node * Head: h * Levels: j * Keys: k, key * Values: v, value * Comparisons: c */
一段很有意思的注释详细说明了skipList的原理
构造函数
/** * Constructs a new, empty map, sorted according to the * {@linkplain Comparable natural ordering} of the keys. */ public ConcurrentSkipListMap() { this.comparator = null; initialize(); } /** * Constructs a new, empty map, sorted according to the specified * comparator. * * @param comparator the comparator that will be used to order this map. * If <tt>null</tt>, the {@linkplain Comparable natural * ordering} of the keys will be used. */ public ConcurrentSkipListMap(Comparator<? super K> comparator) { this.comparator = comparator; initialize(); } /** * Constructs a new map containing the same mappings as the given map, * sorted according to the {@linkplain Comparable natural ordering} of * the keys. * * @param m the map whose mappings are to be placed in this map * @throws ClassCastException if the keys in <tt>m</tt> are not * {@link Comparable}, or are not mutually comparable * @throws NullPointerException if the specified map or any of its keys * or values are null */ public ConcurrentSkipListMap(Map<? extends K, ? extends V> m) { this.comparator = null; initialize(); putAll(m); } /** * Constructs a new map containing the same mappings and using the * same ordering as the specified sorted map. * * @param m the sorted map whose mappings are to be placed in this * map, and whose comparator is to be used to sort this map * @throws NullPointerException if the specified sorted map or any of * its keys or values are null */ public ConcurrentSkipListMap(SortedMap<K, ? extends V> m) { this.comparator = m.comparator(); initialize(); buildFromSorted(m); }
事实上都会执行initialize来进行初始化
/** * Initializes or resets state. Needed by constructors, clone, * clear, readObject. and ConcurrentSkipListSet.clone. * (Note that comparator must be separately initialized.) */ final void initialize() { keySet = null; entrySet = null; values = null; descendingMap = null; randomSeed = seedGenerator.nextInt() | 0x0100; // ensure nonzero head = new HeadIndex<K,V>(new Node<K,V>(null, BASE_HEADER, null), null, null, 1); }
初始化了头结点
/** * The topmost head index of the skiplist. */ private transient volatile HeadIndex<K,V> head;
需要注意的是都是用了volatile关键字【happen-before】这边涉及到Java内存模型可以后再详细描述(只需要记得该关键字修饰的变量在任何线程修改完之后其他线程都能like读到最新的值并且禁止了指令重排序)
首先需要介绍三个内部类
Node
/** * Nodes hold keys and values, and are singly linked in sorted * order, possibly with some intervening marker nodes. The list is * headed by a dummy node accessible as head.node. The value field * is declared only as Object because it takes special non-V * values for marker and header nodes. */ static final class Node<K,V> { final K key; volatile Object value; volatile Node<K,V> next; /** * Creates a new regular node. */ Node(K key, Object value, Node<K,V> next) { this.key = key; this.value = value; this.next = next; } /** * Creates a new marker node. A marker is distinguished by * having its value field point to itself. Marker nodes also * have null keys, a fact that is exploited in a few places, * but this doesn't distinguish markers from the base-level * header node (head.node), which also has a null key. */ Node(Node<K,V> next) { this.key = null; this.value = this; this.next = next; } /** * compareAndSet value field */ boolean casValue(Object cmp, Object val) { return UNSAFE.compareAndSwapObject(this, valueOffset, cmp, val); } /** * compareAndSet next field */ boolean casNext(Node<K,V> cmp, Node<K,V> val) { return UNSAFE.compareAndSwapObject(this, nextOffset, cmp, val); } /** * Returns true if this node is a marker. This method isn't * actually called in any current code checking for markers * because callers will have already read value field and need * to use that read (not another done here) and so directly * test if value points to node. * @param n a possibly null reference to a node * @return true if this node is a marker node */ boolean isMarker() { return value == this; } /** * Returns true if this node is the header of base-level list. * @return true if this node is header node */ boolean isBaseHeader() { return value == BASE_HEADER; } /** * Tries to append a deletion marker to this node. * @param f the assumed current successor of this node * @return true if successful */ boolean appendMarker(Node<K,V> f) { return casNext(f, new Node<K,V>(f)); } /** * Helps out a deletion by appending marker or unlinking from * predecessor. This is called during traversals when value * field seen to be null. * @param b predecessor * @param f successor */ void helpDelete(Node<K,V> b, Node<K,V> f) { /* * Rechecking links and then doing only one of the * help-out stages per call tends to minimize CAS * interference among helping threads. */ if (f == next && this == b.next) { if (f == null || f.value != f) // not already marked appendMarker(f); else b.casNext(this, f.next); } } /** * Returns value if this node contains a valid key-value pair, * else null. * @return this node's value if it isn't a marker or header or * is deleted, else null. */ V getValidValue() { Object v = value; if (v == this || v == BASE_HEADER) return null; return (V)v; } /** * Creates and returns a new SimpleImmutableEntry holding current * mapping if this node holds a valid value, else null. * @return new entry or null */ AbstractMap.SimpleImmutableEntry<K,V> createSnapshot() { V v = getValidValue(); if (v == null) return null; return new AbstractMap.SimpleImmutableEntry<K,V>(key, v); } // UNSAFE mechanics private static final sun.misc.Unsafe UNSAFE; private static final long valueOffset; private static final long nextOffset; static { try { UNSAFE = sun.misc.Unsafe.getUnsafe(); Class k = Node.class; valueOffset = UNSAFE.objectFieldOffset (k.getDeclaredField("value")); nextOffset = UNSAFE.objectFieldOffset (k.getDeclaredField("next")); } catch (Exception e) { throw new Error(e); } } }
用来存储KV同时提供了无锁化的cas设置对应域的方法
Index
/* ---------------- Indexing -------------- */ /** * Index nodes represent the levels of the skip list. Note that * even though both Nodes and Indexes have forward-pointing * fields, they have different types and are handled in different * ways, that can't nicely be captured by placing field in a * shared abstract class. */ static class Index<K,V> { final Node<K,V> node; final Index<K,V> down; volatile Index<K,V> right; /** * Creates index node with given values. */ Index(Node<K,V> node, Index<K,V> down, Index<K,V> right) { this.node = node; this.down = down; this.right = right; } /** * compareAndSet right field */ final boolean casRight(Index<K,V> cmp, Index<K,V> val) { return UNSAFE.compareAndSwapObject(this, rightOffset, cmp, val); } /** * Returns true if the node this indexes has been deleted. * @return true if indexed node is known to be deleted */ final boolean indexesDeletedNode() { return node.value == null; } /** * Tries to CAS newSucc as successor. To minimize races with * unlink that may lose this index node, if the node being * indexed is known to be deleted, it doesn't try to link in. * @param succ the expected current successor * @param newSucc the new successor * @return true if successful */ final boolean link(Index<K,V> succ, Index<K,V> newSucc) { Node<K,V> n = node; newSucc.right = succ; return n.value != null && casRight(succ, newSucc); } /** * Tries to CAS right field to skip over apparent successor * succ. Fails (forcing a retraversal by caller) if this node * is known to be deleted. * @param succ the expected current successor * @return true if successful */ final boolean unlink(Index<K,V> succ) { return !indexesDeletedNode() && casRight(succ, succ.right); } // Unsafe mechanics private static final sun.misc.Unsafe UNSAFE; private static final long rightOffset; static { try { UNSAFE = sun.misc.Unsafe.getUnsafe(); Class k = Index.class; rightOffset = UNSAFE.objectFieldOffset (k.getDeclaredField("right")); } catch (Exception e) { throw new Error(e); } } }
Index提供了右和下的索引 当然其包含了对应的Node节点
其中有两个方法需要特别说明
link
在当前节点右边连接新的索引通过cas方法将当前节点的右索引连接到新索引的右索引【理解成带锁的插入即可】
unLink
将当前的节点有右连接cas换成右连接的有链接【如果当前节点的右连接不为空】【理解成带锁的删除即可】
HeadIndex
/* ---------------- Head nodes -------------- */ /** * Nodes heading each level keep track of their level. */ static final class HeadIndex<K,V> extends Index<K,V> { final int level; HeadIndex(Node<K,V> node, Index<K,V> down, Index<K,V> right, int level) { super(node, down, right); this.level = level; } }
HeadIndex除了右和下连接还提供了level域这个表明当前层级
put
/** * Associates the specified value with the specified key in this map. * If the map previously contained a mapping for the key, the old * value is replaced. * * @param key key with which the specified value is to be associated * @param value value to be associated with the specified key * @return the previous value associated with the specified key, or * <tt>null</tt> if there was no mapping for the key * @throws ClassCastException if the specified key cannot be compared * with the keys currently in the map * @throws NullPointerException if the specified key or value is null */ public V put(K key, V value) { if (value == null) throw new NullPointerException(); return doPut(key, value, false); } /** * Main insertion method. Adds element if not present, or * replaces value if present and onlyIfAbsent is false. * @param kkey the key * @param value the value that must be associated with key * @param onlyIfAbsent if should not insert if already present * @return the old value, or null if newly inserted */ private V doPut(K kkey, V value, boolean onlyIfAbsent) { Comparable<? super K> key = comparable(kkey); for (;;) { Node<K,V> b = findPredecessor(key); Node<K,V> n = b.next; for (;;) { if (n != null) { Node<K,V> f = n.next; if (n != b.next) // inconsistent read break; Object v = n.value; if (v == null) { // n is deleted n.helpDelete(b, f); break; } if (v == n || b.value == null) // b is deleted break; int c = key.compareTo(n.key); if (c > 0) { b = n; n = f; continue; } if (c == 0) { if (onlyIfAbsent || n.casValue(v, value)) return (V)v; else break; // restart if lost race to replace value } // else c < 0; fall through } Node<K,V> z = new Node<K,V>(kkey, value, n); if (!b.casNext(n, z)) break; // restart if lost race to append to b int level = randomLevel(); if (level > 0) insertIndex(z, level); return null; } } } /** * If using comparator, return a ComparableUsingComparator, else * cast key as Comparable, which may cause ClassCastException, * which is propagated back to caller. */ private Comparable<? super K> comparable(Object key) throws ClassCastException { if (key == null) throw new NullPointerException(); if (comparator != null) return new ComparableUsingComparator<K>((K)key, comparator); else return (Comparable<? super K>)key; }
从上述代码来看 对应kv均不支持空
我们来看找到对应前辈节点的代码
/** * Returns a base-level node with key strictly less than given key, * or the base-level header if there is no such node. Also * unlinks indexes to deleted nodes found along the way. Callers * rely on this side-effect of clearing indices to deleted nodes. * @param key the key * @return a predecessor of key */ private Node<K,V> findPredecessor(Comparable<? super K> key) { if (key == null) throw new NullPointerException(); // don't postpone errors for (;;) { Index<K,V> q = head; Index<K,V> r = q.right; for (;;) { if (r != null) { Node<K,V> n = r.node; K k = n.key; if (n.value == null) { if (!q.unlink(r)) break; // restart r = q.right; // reread r continue; } if (key.compareTo(k) > 0) { q = r; r = r.right; continue; } } Index<K,V> d = q.down; if (d != null) { q = d; r = d.right; } else return q.node; } } }
首先查询都是从head节点开始
由于节点都是有序的 那么插入节点时有如下规律 右边节点一定比左边节点大
因此给定一个key只要出现当右边的节点大于当前节点则在前一个节点获取向下的索引
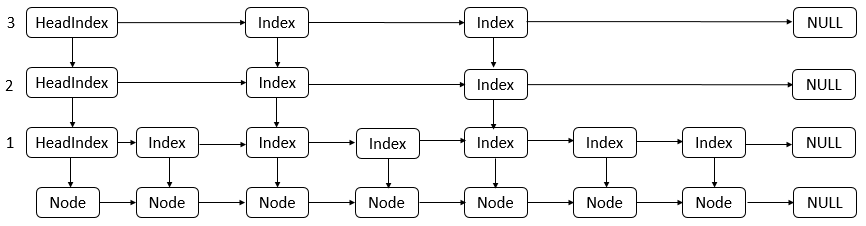
通过该方法我们可以找到前置节点
/* ---------------- Insertion -------------- */ /** * Main insertion method. Adds element if not present, or * replaces value if present and onlyIfAbsent is false. * @param kkey the key * @param value the value that must be associated with key * @param onlyIfAbsent if should not insert if already present * @return the old value, or null if newly inserted */ private V doPut(K kkey, V value, boolean onlyIfAbsent) { Comparable<? super K> key = comparable(kkey); for (;;) { Node<K,V> b = findPredecessor(key); Node<K,V> n = b.next; for (;;) { if (n != null) { Node<K,V> f = n.next; if (n != b.next) // inconsistent read break; Object v = n.value; if (v == null) { // n is deleted n.helpDelete(b, f); break; } if (v == n || b.value == null) // b is deleted break; int c = key.compareTo(n.key); if (c > 0) { b = n; n = f; continue; } if (c == 0) { if (onlyIfAbsent || n.casValue(v, value)) return (V)v; else break; // restart if lost race to replace value } // else c < 0; fall through } Node<K,V> z = new Node<K,V>(kkey, value, n); if (!b.casNext(n, z)) break; // restart if lost race to append to b int level = randomLevel(); if (level > 0) insertIndex(z, level); return null; } } }
从最简单情况开始分析 假设第一次只有headIndex节点 那么新的节点进来要插入到headIndex节点之后
此时BaseNode为找到的前置节点。那么其next为空
那么新建新的node节点
通过cas方法设置next域【处处可见UNSAFE】为对应的节点
当然如果设置失败则需要继续循环直到成功为止
要给对应的节点产生level这个就是链接中所说的抛硬币方法(随机)
/** * Returns a random level for inserting a new node. * Hardwired to k=1, p=0.5, max 31 (see above and * Pugh's "Skip List Cookbook", sec 3.4). * * This uses the simplest of the generators described in George * Marsaglia's "Xorshift RNGs" paper. This is not a high-quality * generator but is acceptable here. */ private int randomLevel() { int x = randomSeed; x ^= x << 13; x ^= x >>> 17; randomSeed = x ^= x << 5; if ((x & 0x80000001) != 0) // test highest and lowest bits return 0; int level = 1; while (((x >>>= 1) & 1) != 0) ++level; return level; }
大家可以看到randomSeed每次都会被重新赋值 同样的道理 仍然是通过volatile来进行保证线程可见性的么?看来不是!
/** * Seed for simple random number generator. Not volatile since it * doesn't matter too much if different threads don't see updates. */ private transient int randomSeed;
对于seed的要求是不能初始为0否则所有的randomSeed左右移就一直为0了
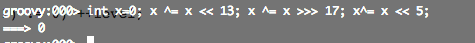
从上面来看level的层次应该为对应x的末尾1的个数【最多是32层】
此时需要执行真正的插入节点的操作了
/** * Creates and adds index nodes for the given node. * @param z the node * @param level the level of the index */ private void insertIndex(Node<K,V> z, int level) { HeadIndex<K,V> h = head; int max = h.level; if (level <= max) { Index<K,V> idx = null; for (int i = 1; i <= level; ++i) idx = new Index<K,V>(z, idx, null); addIndex(idx, h, level); } else { // Add a new level /* * To reduce interference by other threads checking for * empty levels in tryReduceLevel, new levels are added * with initialized right pointers. Which in turn requires * keeping levels in an array to access them while * creating new head index nodes from the opposite * direction. */ level = max + 1; Index<K,V>[] idxs = (Index<K,V>[])new Index[level+1]; Index<K,V> idx = null; for (int i = 1; i <= level; ++i) idxs[i] = idx = new Index<K,V>(z, idx, null); HeadIndex<K,V> oldh; int k; for (;;) { oldh = head; int oldLevel = oldh.level; if (level <= oldLevel) { // lost race to add level k = level; break; } HeadIndex<K,V> newh = oldh; Node<K,V> oldbase = oldh.node; for (int j = oldLevel+1; j <= level; ++j) newh = new HeadIndex<K,V>(oldbase, newh, idxs[j], j); if (casHead(oldh, newh)) { k = oldLevel; break; } } addIndex(idxs[k], oldh, k); } } /** * Adds given index nodes from given level down to 1. * @param idx the topmost index node being inserted * @param h the value of head to use to insert. This must be * snapshotted by callers to provide correct insertion level * @param indexLevel the level of the index */ private void addIndex(Index<K,V> idx, HeadIndex<K,V> h, int indexLevel) { // Track next level to insert in case of retries int insertionLevel = indexLevel; Comparable<? super K> key = comparable(idx.node.key); if (key == null) throw new NullPointerException(); // Similar to findPredecessor, but adding index nodes along // path to key. for (;;) { int j = h.level; Index<K,V> q = h; Index<K,V> r = q.right; Index<K,V> t = idx; for (;;) { if (r != null) { Node<K,V> n = r.node; // compare before deletion check avoids needing recheck int c = key.compareTo(n.key); if (n.value == null) { if (!q.unlink(r)) break; r = q.right; continue; } if (c > 0) { q = r; r = r.right; continue; } } if (j == insertionLevel) { // Don't insert index if node already deleted if (t.indexesDeletedNode()) { findNode(key); // cleans up return; } if (!q.link(r, t)) break; // restart if (--insertionLevel == 0) { // need final deletion check before return if (t.indexesDeletedNode()) findNode(key); return; } } if (--j >= insertionLevel && j < indexLevel) t = t.down; q = q.down; r = q.right; } } }
如果当前头结点的level比上述生成的level小 说明要生成的新的level了 并且不可能跨级生产level【比如第一个节点插入生成的节点level需要设置为10 此时只有一层那么会将该level重新设置为1 即headIndex.level+1】
正如注释所说 无锁化编程的难度比较大一个正确无误的高性能无锁化并发库 是jdk提供的免费性能午餐。不过这边仍然可以看到JDK开发者是怎么思考和解决的。
由于加了新的Level 新的节点在这一层
如果不考虑并发此时应该
那么需要该节点包装和层级数量相同多的Index 其中每一个Index的down链接指向前一个Index
并且新建新的Head的右链接指向最后一个Index 其下链接指向老的HeadIndex
这边有个疑问
for (int i = 1; i <= level; ++i) idxs[i] = idx = new Index<K,V>(z, idx, null);
idexs[0] 并没有赋值为null 应该只是为了和level保持一致 而不需要对应数组下标-1 使用了idxs[j] 和idxs[k]
HeadIndex<K,V> oldh; int k; for (;;) { oldh = head; int oldLevel = oldh.level; if (level <= oldLevel) { // lost race to add level k = level; break; } HeadIndex<K,V> newh = oldh; Node<K,V> oldbase = oldh.node; for (int j = oldLevel+1; j <= level; ++j) newh = new HeadIndex<K,V>(oldbase, newh, idxs[j], j); if (casHead(oldh, newh)) { k = oldLevel; break; } } addIndex(idxs[k], oldh, k);
插入index和之前找前辈节点类似
get
/** * Gets value for key using findNode. * @param okey the key * @return the value, or null if absent */ private V doGet(Object okey) { Comparable<? super K> key = comparable(okey); /* * Loop needed here and elsewhere in case value field goes * null just as it is about to be returned, in which case we * lost a race with a deletion, so must retry. */ for (;;) { Node<K,V> n = findNode(key); if (n == null) return null; Object v = n.value; if (v != null) return (V)v; } } /** * Returns node holding key or null if no such, clearing out any * deleted nodes seen along the way. Repeatedly traverses at * base-level looking for key starting at predecessor returned * from findPredecessor, processing base-level deletions as * encountered. Some callers rely on this side-effect of clearing * deleted nodes. * * Restarts occur, at traversal step centered on node n, if: * * (1) After reading n's next field, n is no longer assumed * predecessor b's current successor, which means that * we don't have a consistent 3-node snapshot and so cannot * unlink any subsequent deleted nodes encountered. * * (2) n's value field is null, indicating n is deleted, in * which case we help out an ongoing structural deletion * before retrying. Even though there are cases where such * unlinking doesn't require restart, they aren't sorted out * here because doing so would not usually outweigh cost of * restarting. * * (3) n is a marker or n's predecessor's value field is null, * indicating (among other possibilities) that * findPredecessor returned a deleted node. We can't unlink * the node because we don't know its predecessor, so rely * on another call to findPredecessor to notice and return * some earlier predecessor, which it will do. This check is * only strictly needed at beginning of loop, (and the * b.value check isn't strictly needed at all) but is done * each iteration to help avoid contention with other * threads by callers that will fail to be able to change * links, and so will retry anyway. * * The traversal loops in doPut, doRemove, and findNear all * include the same three kinds of checks. And specialized * versions appear in findFirst, and findLast and their * variants. They can't easily share code because each uses the * reads of fields held in locals occurring in the orders they * were performed. * * @param key the key * @return node holding key, or null if no such */ private Node<K,V> findNode(Comparable<? super K> key) { for (;;) { Node<K,V> b = findPredecessor(key); Node<K,V> n = b.next; for (;;) { if (n == null) return null; Node<K,V> f = n.next; if (n != b.next) // inconsistent read break; Object v = n.value; if (v == null) { // n is deleted n.helpDelete(b, f); break; } if (v == n || b.value == null) // b is deleted break; int c = key.compareTo(n.key); if (c == 0) return n; if (c < 0) return null; b = n; n = f; } } }
依旧是使用findPredecessor找到前置节点 使用compare 如果为0则返回否则表示为空
由于并发 当返回为1的时候表示该节点大于找到的前置节点的下一个节点的值大于查找的key
此时可能由于并发导致找到的前置节点已经并非最新的结果 因此再次循环查找
remove
/** * Removes the mapping for the specified key from this map if present. * * @param key key for which mapping should be removed * @return the previous value associated with the specified key, or * <tt>null</tt> if there was no mapping for the key * @throws ClassCastException if the specified key cannot be compared * with the keys currently in the map * @throws NullPointerException if the specified key is null */ public V remove(Object key) { return doRemove(key, null); } /* ---------------- Deletion -------------- */ /** * Main deletion method. Locates node, nulls value, appends a * deletion marker, unlinks predecessor, removes associated index * nodes, and possibly reduces head index level. * * Index nodes are cleared out simply by calling findPredecessor. * which unlinks indexes to deleted nodes found along path to key, * which will include the indexes to this node. This is done * unconditionally. We can't check beforehand whether there are * index nodes because it might be the case that some or all * indexes hadn't been inserted yet for this node during initial * search for it, and we'd like to ensure lack of garbage * retention, so must call to be sure. * * @param okey the key * @param value if non-null, the value that must be * associated with key * @return the node, or null if not found */ final V doRemove(Object okey, Object value) { Comparable<? super K> key = comparable(okey); for (;;) { Node<K,V> b = findPredecessor(key); Node<K,V> n = b.next; for (;;) { if (n == null) return null; Node<K,V> f = n.next; if (n != b.next) // inconsistent read break; Object v = n.value; if (v == null) { // n is deleted n.helpDelete(b, f); break; } if (v == n || b.value == null) // b is deleted break; int c = key.compareTo(n.key); if (c < 0) return null; if (c > 0) { b = n; n = f; continue; } if (value != null && !value.equals(v)) return null; if (!n.casValue(v, null)) break; if (!n.appendMarker(f) || !b.casNext(n, f)) findNode(key); // Retry via findNode else { findPredecessor(key); // Clean index if (head.right == null) tryReduceLevel(); } return (V)v; } } } /** * Possibly reduce head level if it has no nodes. This method can * (rarely) make mistakes, in which case levels can disappear even * though they are about to contain index nodes. This impacts * performance, not correctness. To minimize mistakes as well as * to reduce hysteresis, the level is reduced by one only if the * topmost three levels look empty. Also, if the removed level * looks non-empty after CAS, we try to change it back quick * before anyone notices our mistake! (This trick works pretty * well because this method will practically never make mistakes * unless current thread stalls immediately before first CAS, in * which case it is very unlikely to stall again immediately * afterwards, so will recover.) * * We put up with all this rather than just let levels grow * because otherwise, even a small map that has undergone a large * number of insertions and removals will have a lot of levels, * slowing down access more than would an occasional unwanted * reduction. */ private void tryReduceLevel() { HeadIndex<K,V> h = head; HeadIndex<K,V> d; HeadIndex<K,V> e; if (h.level > 3 && (d = (HeadIndex<K,V>)h.down) != null && (e = (HeadIndex<K,V>)d.down) != null && e.right == null && d.right == null && h.right == null && casHead(h, d) && // try to set h.right != null) // recheck casHead(d, h); // try to backout }
当执行remove的时候依然实现找到前置节点
根据该节点的right节点来判断执行compare是否相同
如果删除key小于right节点的值那么可以返回null 说明该节点不存在
如果删除的key等于right节点的值说明需要删除
如果删除的key大于right节点的值说明前置节点需要更新已被修改
这边删除很有意思 通过marker来标记 而marker节点仍然是Node
/** * Tries to append a deletion marker to this node. * @param f the assumed current successor of this node * @return true if successful */ boolean appendMarker(Node<K,V> f) { return casNext(f, new Node<K,V>(f)); } /** * Creates a new marker node. A marker is distinguished by * having its value field point to itself. Marker nodes also * have null keys, a fact that is exploited in a few places, * but this doesn't distinguish markers from the base-level * header node (head.node), which also has a null key. */ Node(Node<K,V> next) { this.key = null; this.value = this; this.next = next; }
使用Marker其key为自身 同时一旦创建marker节点成功此时执行b.casNext(n, f) 也就完成了节点的替换【即后继节点的删除】
每次删除完毕后需要check头节点的右链接为空的话需要删除一层 即调用tryReduceLevel
tryReduceLevel这段注释写的也很有趣【必须超过三层才会进行层数的减少】
这边更多的还是多线程之前的竞态条件等
如果出现head节点需要再次check 并再次头结点cas交换
不考虑并发的情况下跳表的实现还是相对红黑树等等是比较容易实现的
参考链接
跳表SkipList

