系统:Centos6.5
三台机器
IP 主机名称 192.168.2.101 node1(主) 192.168.2.154 node2(从) 192.168.2.187 node3(从)
修改主机对应Ip (每台机器)
vi /etc/hosts

Java环境:jdk1.8(每台机器)
创建java目录
mkdir /usr/local/java/

解压jdk安装包
tar -zxvf jdk-8u121-linux-x64.tar.gz

复制到java目录下
mv jdk1.8.0_121/ /usr/local/java/

配置环境
vi /etc/profile JAVA_HOME=/usr/local/java/jdk1.8.0_121/ JRE_HOME=/usr/local/java/jdk1.8.0_121/jre PATH=$PATH:$JAVA_HOME/bin:$JRE_HOME/bin CLASSPATH=:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar:$JRE_HOME/lib export JAVA_HOME JRE_HOME PATH CLASSPATH
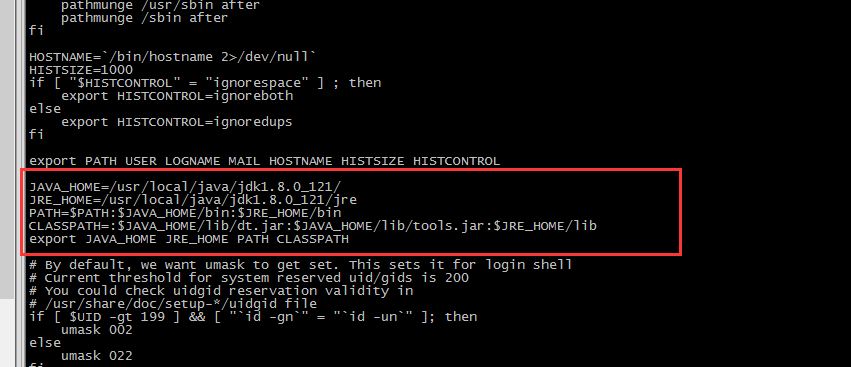
配置生效
source /etc/profile
配置ssh免密码登陆
进入cd /root/.ssh/目录下
每台机器执行:ssh-keygen -t rsa 一路回车
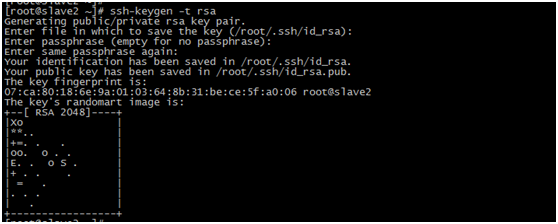
生成两个文件,一个私钥,一个公钥,在master1中执行:cp id_rsa.pub authorized_keys

设置本机无密码登陆
chmod 644 authorized_keys
重启sshd服务 service sshd restart
登陆测试:ssh node1

设置其他节点无密码登陆
scp authorized_keys node2:/root/.ssh/
scp authorized_keys node3:/root/.ssh/

接下来是hadoop安装配置
Hadoop2.8.1版本
下载位置:链接:http://pan.baidu.com/s/1eRBREdc 密码:h3wf
解压 tar –zxvf hadoop-2.8.1.tar.gz
拷贝到/usr/local/ 目录下
修改名称cp hadoop-2.8.1 hadoop
Hadoop配置文件配置
cd /usr/local/hadoop/etc/hadoop/

vi core-site.xml
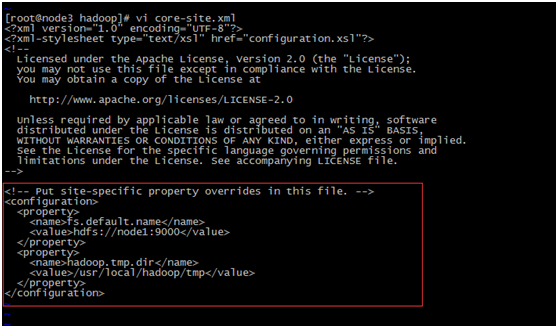
fs.default.name - 这是一个描述集群中NameNode结点的URI(包括协议、主机名称、端口号),集群里面的每一台机器都需要知道NameNode的地址。DataNode结点会先在NameNode上注册,这样它们的数据才可以被使用。独立的客户端程序通过这个URI跟DataNode交互,以取得文件的块列表
hadoop.tmp.dir 是hadoop文件系统依赖的基础配置,很多路径都依赖它。如果hdfs-site.xml中不配 置namenode和datanode的存放位置,默认就放在这个路径中
<configuration> <property> <name>fs.default.name</name> <value>hdfs://node1:9000</value> </property> <property> <name>hadoop.tmp.dir</name> <value>/usr/local/hadoop/tmp</value> </property> </configuration>
vi hdfs-site.xml

dfs.replication -它决定着 系统里面的文件块的数据备份个数。对于一个实际的应用,它 应该被设为3(这个 数字并没有上限,但更多的备份可能并没有作用,而且会占用更多的空间)。少于三个的备份,可能会影响到数据的 可靠性(系统故障时,也许会造成数据丢失)
<property> <name>dfs.replication</name> <value>1</value> </property> <property> <name>dfs.webhdfs.enabled</name> <value>true</value> </property> <property> <name>dfs.permissions</name> <value>false</value> </property>
vi mapred-site.xml.template

<configuration> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> <property> <name>mapreduce.jobhistory.address</name> <value>Master:10020</value> </property> <property> <name>mapreduce.jobhistory.webapp.address</name> <value>Master:19888</value> </property> </configuration>
vi slaves 加入节点名称
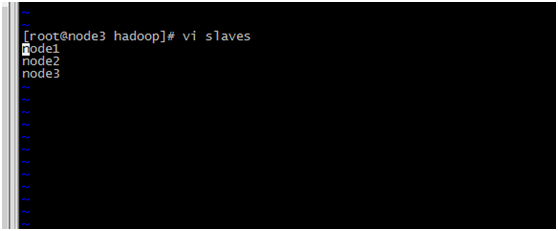
node1 node2 node3
vi yarn-site.xml

<configuration> <!-- Site specific YARN configuration properties --> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <property> <name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name> <value>org.apache.hadoop.mapred.ShuffleHandler</value> </property> <property> <name>yarn.resourcemanager.address</name> <value>node1:8032</value> </property> <property> <name>yarn.resourcemanager.scheduler.address</name> <value>node1:8030</value> </property> <property> <name>yarn.resourcemanager.resource-tracker.address</name> <value>node1:8031</value> </property> <property> <name>yarn.resourcemanager.admin.address</name> <value>node1:8033</value> </property> <property> <name>yarn.resourcemanager.webapp.address</name> <value>node1:8088</value> </property> </configuration>
将hadoop目录 拷贝到每台机器上面
scp -r /usr/local/hadoop/ node2:/usr/local/ scp -r /usr/local/hadoop/ node3:/usr/local/

在每台机器上 格式化生效
在hadoop目录下 :bin/hdfs namenode –format

进入cd /usr/local/hadoop/sbin/目录下启动hadoop
./start-dfs.sh

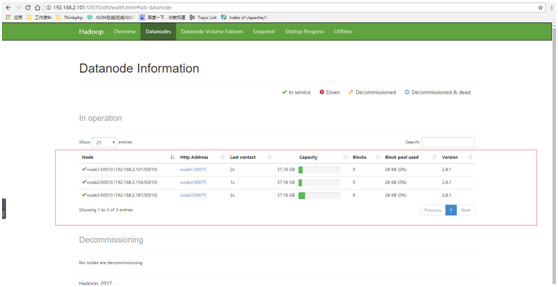
启动成功页面