mapreduce框架内部核心工作流程图
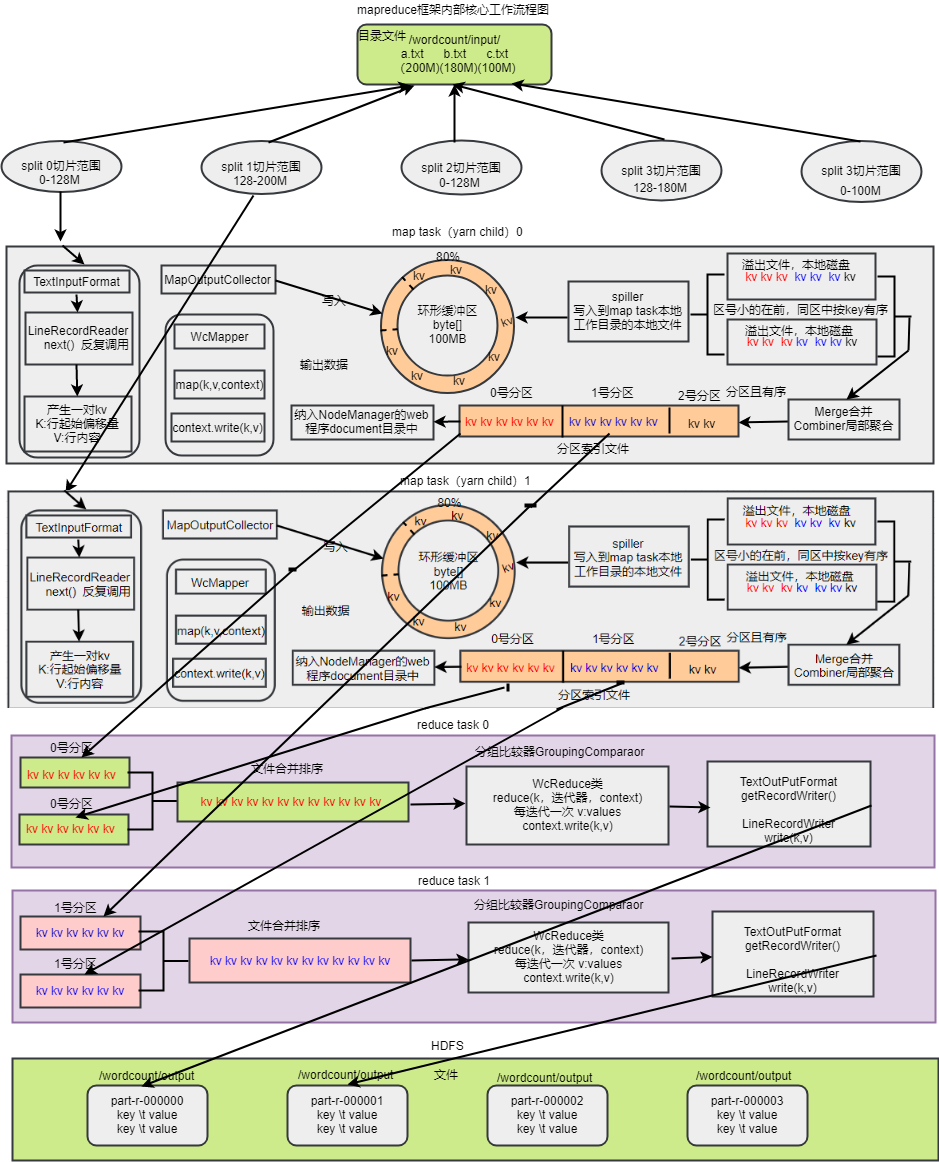
流程
1、mapTask调用InputFormat再调用RecourReader的read()方法来读取数据,获得key、value,mapreduce通过InputFormat来解耦
2、read()方法依靠一次读取一行的逻辑来读取原始文件的数据,返回key、value,mapTask会将其交给自定义的Mapper
3、map方法我们会调用context.write方法来输出数据到OutPutCollector类,OutPutCollector会将数据放到(内存中存放 默认MR.SORT.MB:100MB可以自己配置,一般不会放满默认80%,这里面还要留有空间排序默认20%)环形缓冲区(其实就是一个bite()数组,如果写满了,那么就会一边写一边将开始的数据回收,然后继续写到回收后的位置上,形成了环形缓冲区)
4、环形缓冲区的溢出的数据溢出之前会通过Hashpartioner进行分区、排序(默认是快速排序法key.compareTO),会通过spiller写入到mapTask工作目录的本地文件(所有溢写文件分区且区内有序)
5、所有溢出的文件会做归并排序形成mapTask的最终结果文件,一个mapTask对应一个最终结果文件,形成几个分区就会有对应几个reduceTask。reduceTask的个数由配置文件或者参数设置,只要不设置自定义partitioner,那么这里的分区会动态适配reduceTask个数。如果设置了自定义partitioner,那么就需要提前设置对应的reduceTask的个数
6、每个reduceTask都会到每一个mapTask的节点去下载分区文件到reduceTask的本地磁盘工作目录
7、为了保证最后的结果有序,reduceTask任务A需要再次从所有mapTask下载到的对应文件重新进行归并排序
8、reduceTask的内部逻辑写在reducer的reduce(key,values)方法,通过调用GroupingComparaor(key,netxtk)或者自定义GroupingComparaor来判断哪些key是一组,形成key和values。
9、reducer的reduce方法最后通过context.writer(key,v)写到输出文件(所有reduceTask的输出文件都有序),输出路径由提交任务时的参数决定,默认文件名part-r-00000
10、如果设置了combiner,那么溢写排序文件会调用,归并排序时也会combiner,将加快shluffer的效率,但是一般情况下不建议使用,如果符合条件下一定要使用,也可以直接指定reducer为combiner,没必要重复写代码
两个核心点:
map reduce编程模型:把数据运算流程分为2个阶段
阶段1:读取原始数据,形成key-value数据(map方法)
阶段2:将阶段1的key-value数据按照相同的key分组聚合(reduce方法)
mapreduce编程模型的具体实现(软件):Hadoop中的mapreduce框架;spark
hadoop中的mapreduce框架:
对编程模型阶段1的实现就是:map task
map task:
读数据:InputFormat-->TextInputFormat:读文本文件
-->SequenceFileInputFormat:读Sequence文件
-->DBInputFormat:读数据库
处理数据:map task通过调用Mapper类的map()方法实现对数据处理
分区:将map阶段产生的key-value数据,分发给若干个reduce task来分担负载,map task调用Partitionner类的 getPartition()方法来决定如何划分数据给不同的reduce task
对编程模型阶段2的实现就是:reduce task
对key-value数据排序:调用key.compareTo()方法来实现对key-value数据排序
reduce task:
读数据:通过HTTP方式从maptask产生的数据文件中下载属于自己的“区”的数据到本地磁盘,然后将多个同区文件(做 合 并,归并排序)
处理数据:通过调用GroupingComparator的compare()方法来判断文件中的哪些key-value属于同一组,然后将这一组 数据传给Reducer类的reduce()方法聚合一次
输出结果:调用OutPutFormat组件将结果key-value数据写出去
OutputFormat-->TextOutputFormat:写文本文件(一对key-value写一行。分隔符号\t)
-->SequenceFileOutputFormat:写Sequence文件(直接将key-value对象序列化到文件中)
-->DBOutputFormat
版权@须臾之余https://my.oschina.net/u/3995125

