简介
POLARDB数据库是阿里云自研的下一代关系型云数据库,100%兼容MySQL,性能最高是MySQL的6倍,但是随着数据量不断增大,面临着单条SQL无法分析出结果的现状。X-Pack Spark为数据库提供分析引擎,旨在打造数据库闭环,借助X-Pack Spark可以将POLARDB数据归档至列式存储Parquet文件,一条SQL完成复杂数据分析,并将分析结果回流到业务库提供查询。本文主要介绍如何使用X-Pack Spark数据工作台对POLARDB数据归档。
业务架构
业务需要对多张表出不同纬度,按天、按月的报表并对外提供查询服务;最大表当前500G,数据量还在不断的增加。尝试过spark直接通过jdbc去分析POLARDB,一方面比较慢,另外一方面每次扫全量的POLARDB数据,对在线业务有影响。基于以下几点考虑选择POLARDB+Spark的架构:
- 选择POLARDB按天增量归档到spark列存,每天增量数据量比较少,选择业务低峰期归档,对在线查询无影响
- 选择Spark作为报表分析引擎,因为Spark很适合做ETL,且内置支持数据回流到POLARDB、MongoDB等多种在线库
- 选择Spark离线数仓作为数据的中转站,对于分析的结果数据回流到在线库提供查询,能够一条Spark SQL完成分析,不需要按维度值拆分多条分析SQL

前置条件
1. 设置Spark访问POLARDB白名单
Spark集群和POLARDB需在同一个VPC下才能访问,目前X-Pack Spark上还不支持一键关联POLARDB数据库,需要将Spark集群的IP加到POLARDB白名单中。后续将会开放一键关联POLARDB的功能。
在“HBase控制台”->“集群列表”中找到分析Spark实例,在“数据库连接”栏中找到“VSwitch ID”交换机ID,如下图:
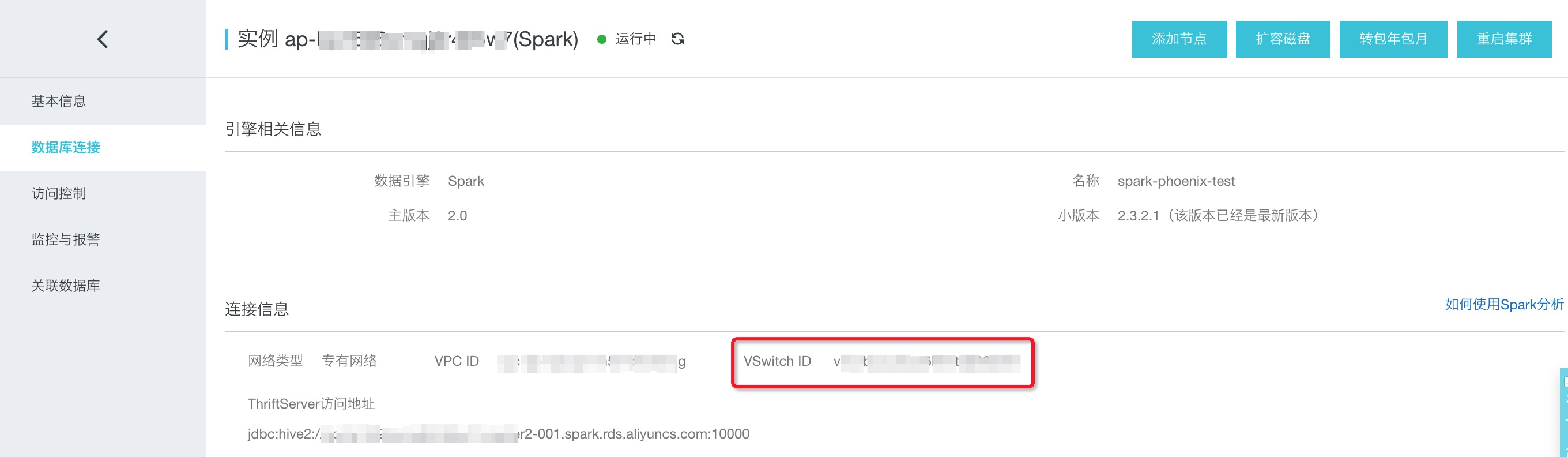
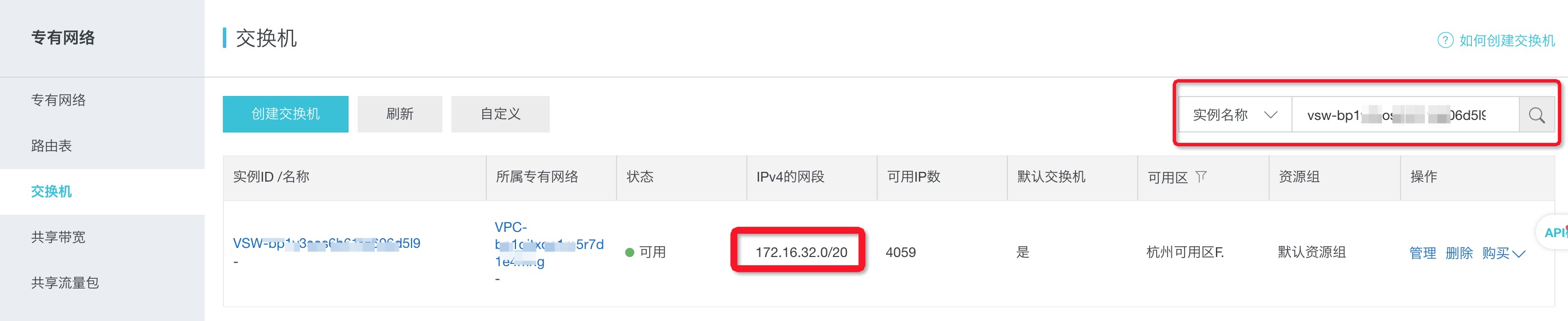
然后在“专有网络VPC控制台”->"交换机"搜索交换机实例ID,查询到IPV4网段。
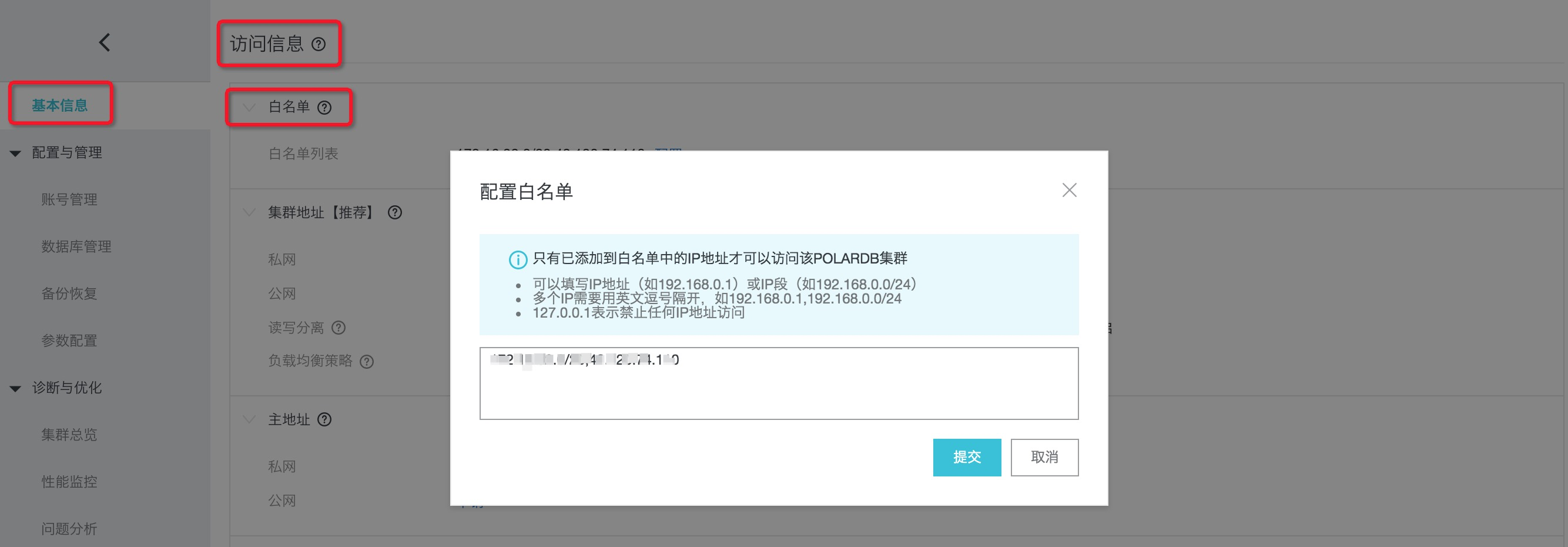
将Spark集群网络加入到POLARDB白名单,进入“控制台”->“集群列表”找到所要关联的POLARDB实例,然后在“基本信息”->“访问信息”->“白名单”加入Spark集群所属网段。
2. 创建测试表
POLARDB中已经存在测试表,如果没有可登录POLARDB数据库创建测试表,下文也以该测试表为例。
CREATE TABLE IF NOT EXISTS test.us_population (
state CHAR(2) NOT NULL PRIMARY KEY,
city VARCHAR(10),
population INTEGER,
dt TIMESTAMP );
INSERT INTO test.us_population VALUES('NY','New York',8143197, CURRENT_DATE );
INSERT INTO test.us_population VALUES('CA','Los Angeles',3844829, CURRENT_DATE);
INSERT INTO test.us_population VALUES('IL','Chicago',2842518, '2019-04-13');
INSERT INTO test.us_population VALUES('TX','Houston',2016582, '2019-04-14');
INSERT INTO test.us_population VALUES('PA','Philadelphia',1463281, '2019-04-13');
INSERT INTO test.us_population VALUES('AZ','Phoenix',1461575, '2019-04-15');
INSERT INTO test.us_population VALUES('SA','San Antonio',1256509, CURRENT_DATE);
INSERT INTO test.us_population VALUES('SD','San Diego',1255540, CURRENT_DATE);
INSERT INTO test.us_population VALUES('DL','Dallas',1213825, '2019-04-15');
INSERT INTO test.us_population VALUES('SJ','San Jose',912332,'2019-04-15');
一、使用交互式工作台归档数据(调试、测试)
创建Spark运行会话
在"HBase控制台"->"会话管理"创建会话,指定会话名称和执行集群,如图:
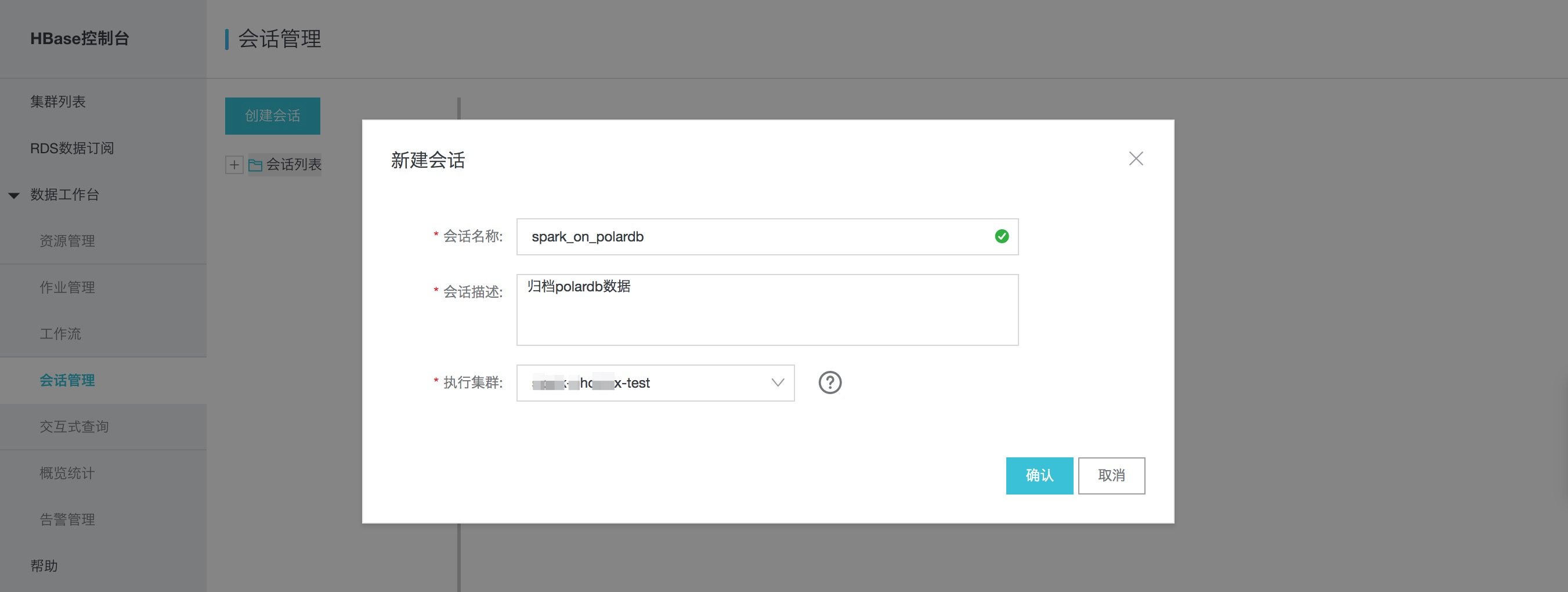
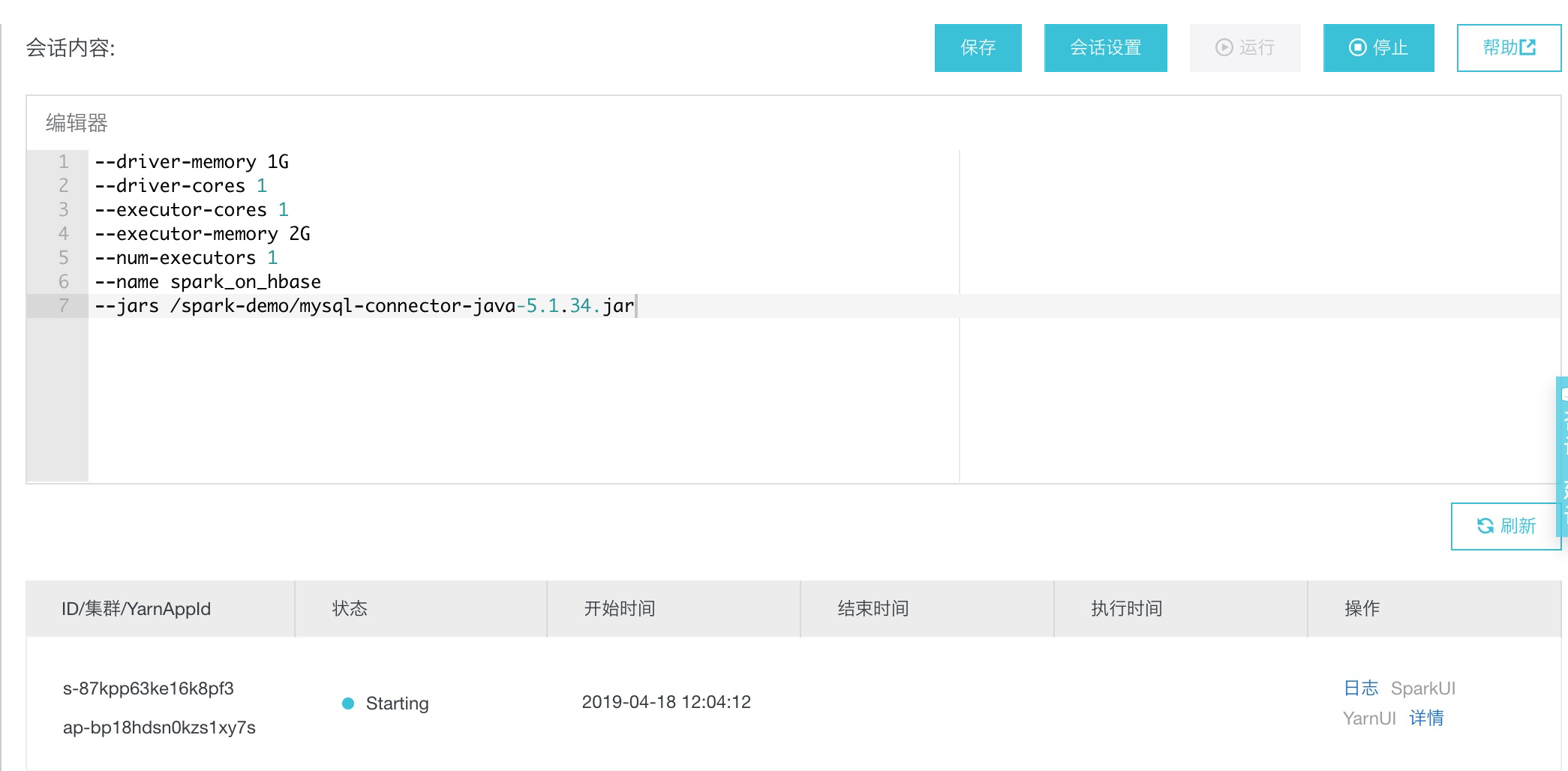
在编辑器中输入Spark启动参数,并运行会话,以便在交互式查询中使用。
--driver-memory 1G
--driver-cores 1
--executor-cores 1
--executor-memory 2G
--num-executors 1
--name spark_on_polardb
--jars /spark-demo/mysql-connector-java-5.1.34.jar
参数说明:
| 参数 |
说明 |
| driver-memory |
spark运行driver内存大小 |
| driver-cores |
spark运行driver核数 |
| executor-cores |
spark作业执行器executor核数 |
| executor-memory |
执行器内存 |
| jars |
spark作业依赖第三方包,地址可在资源管理中复制 |
注:上述参数在测试环境中给定偏小,大数据量时根据实际集群规格和数据量进行配置
会话运行成功后如下图所示:
交互式查询归档数据
创建Spark映射POLARDB表
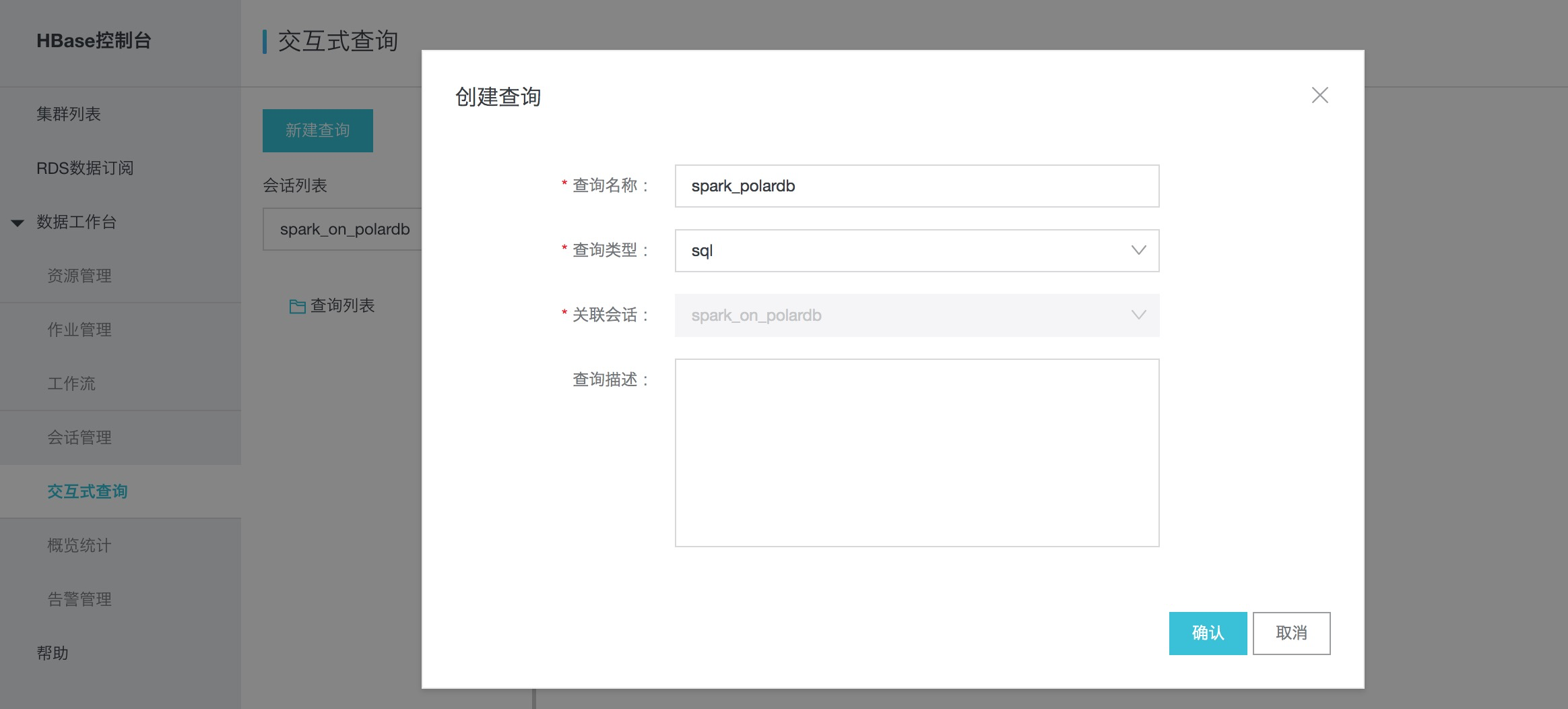
进入"HBase控制台"->"交互式查询",在会话列表中选择上一步创建会话“spark_on_polardb”,然后新建查询,指定查询名称,选择查询类型为“SQL”类型,如图:
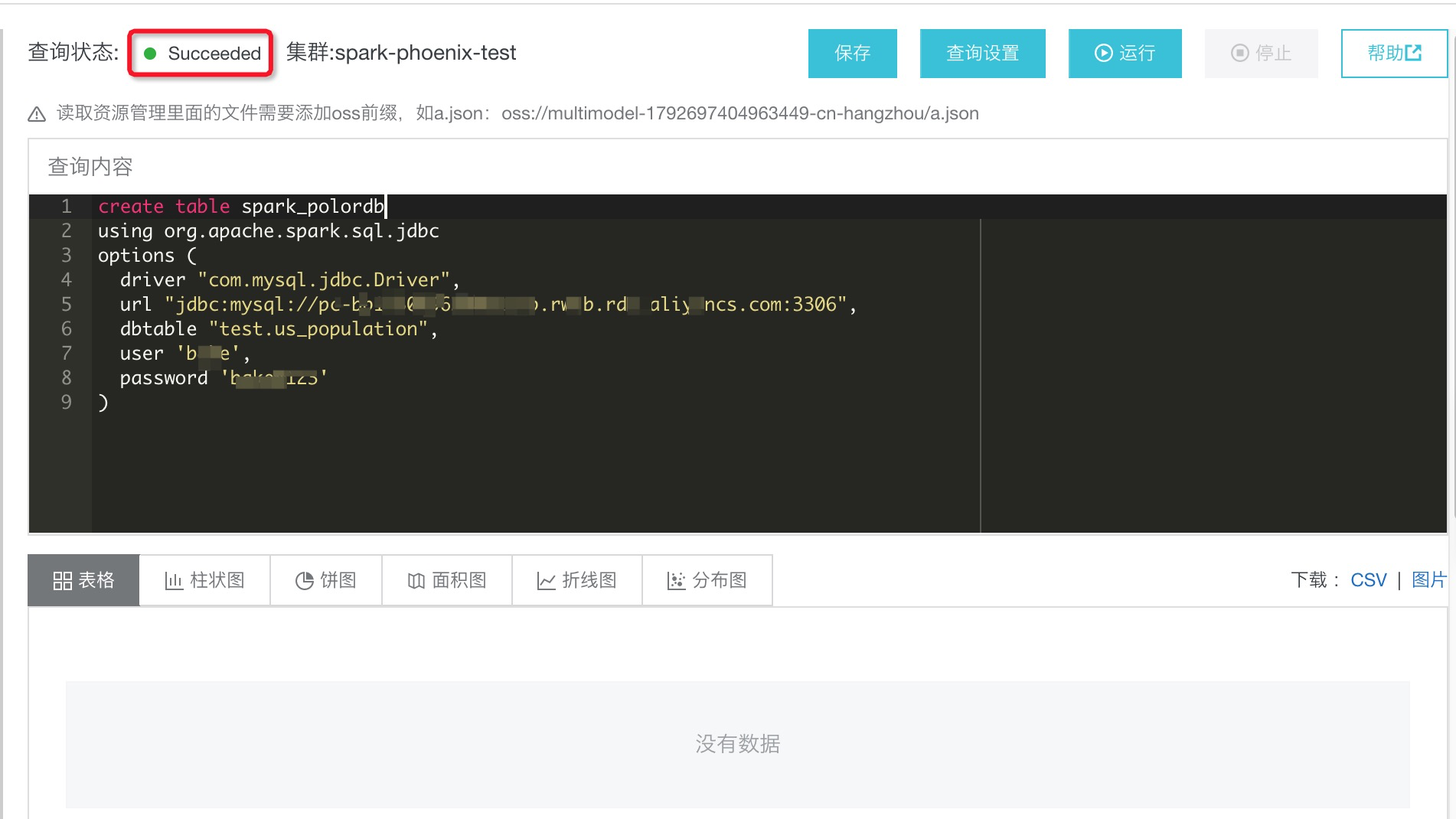
在查询输入框中输入Spark建表语句,与POLARDB表进行关联,建表语句为:
create table spark_polordb
using org.apache.spark.sql.jdbc
options (
driver "com.mysql.jdbc.Driver",
url "jdbc:mysql://pc-xxx.rwlb.rds.aliyuncs.com:3306",
dbtable "test.us_population",
user 'xxx',
password 'xxxxxx'
)
参数说明:
| 参数 |
说明 |
| spark_polordb |
spark中表名 |
| driver |
polardb驱动类名 |
| url |
polardb的数据库连接地址 |
| dbtable |
对应polardb表名,格式为database.tablename |
| user |
polardb用户名 |
| password |
连接密码 |
点击运行,查询状态为“success”时表明创建成功。
查询测试
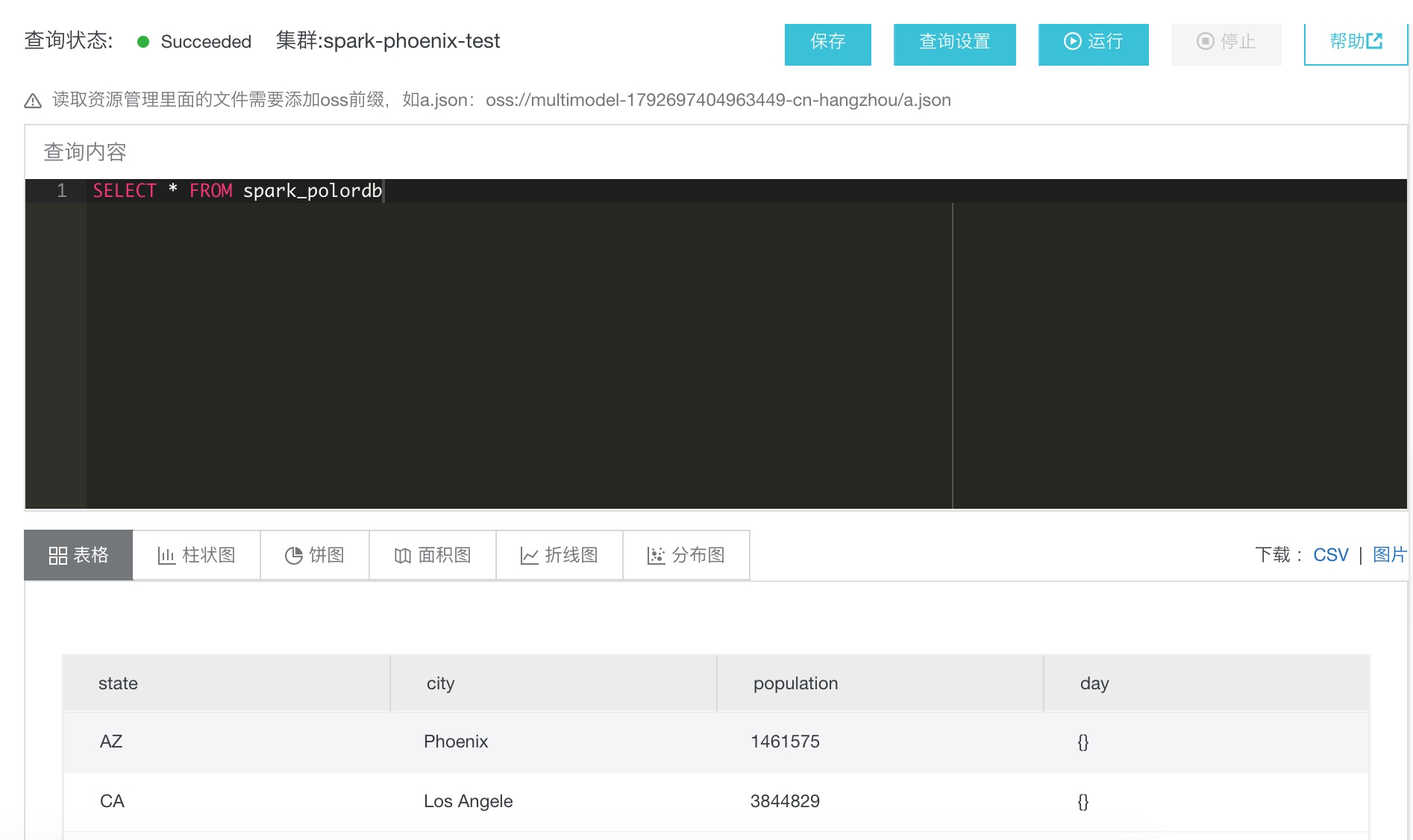
在上步创建查询编辑器中输入查询语句,然后运行:
SELECT * FROM spark_polordb
查询成功后返回结果如图:
创建归档表
X-Pack Spark将POLARDB数据归档至Parquet列式存储格式中,一方面能够获取更优的压缩空间,另一方面后续分析任务中具有更高的效率。
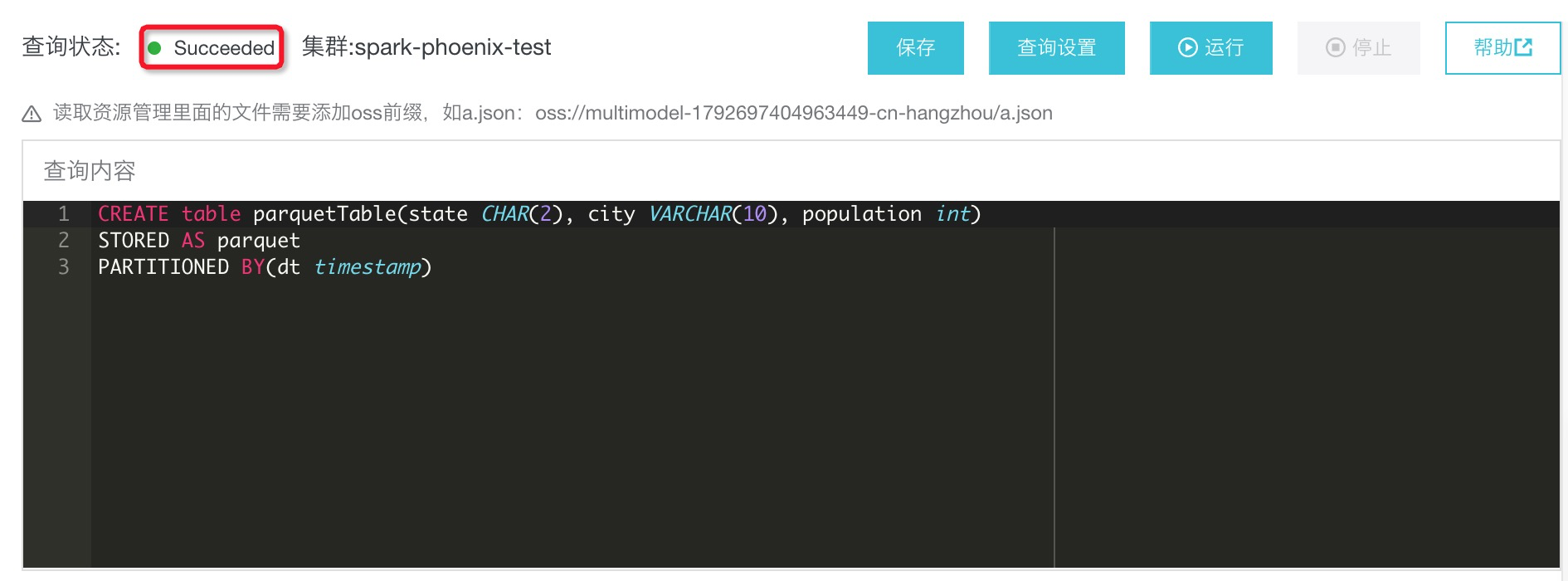
Spark创建parquet分区表语句如下,同样在第一步中交互式查询编辑中输入:
CREATE table parquetTable(state CHAR(2), city VARCHAR(10), population int)
USING parquet
PARTITIONED BY(dt timestamp)
参数说明:
| 参数 |
说明 |
| parquetTable |
spark中归档表名 |
| USING parquet |
数据存储格式为parquet |
| PARTITIONED BY |
按照字段分区,类型为timestamp,也可以指定为date |
建表成功后,可以将POLARDB数据写入至Parquet表。
归档数据
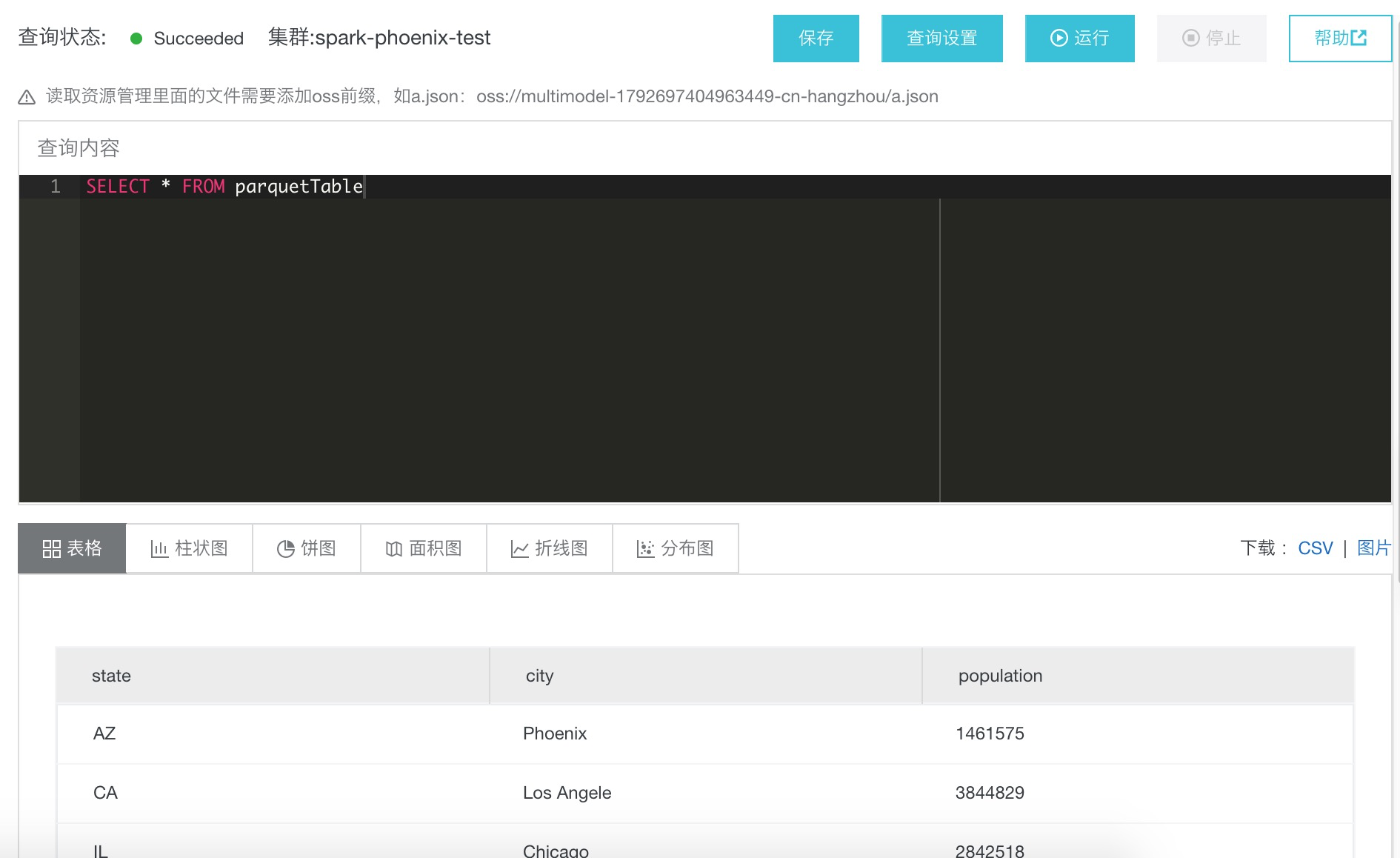
将POLARDB数据查询出写入parquet表即可完成数据归档,操作语句为:
INSERT INTO parquetTable partition(dt) SELECT state, city, population, dt FROM spark_polordb
运行成功后数据归档完成。查询parquet表数据:
二、工作流调度周期归档(生产T+1归档)
交互式查询主要用来测试调试,归档一般需要做t+1的操作,每天定期把当前的数据做归档,这就需要使用工作流的周期调度,下面具体介绍如何使用工作流的周期调度实现t+1的归档。
归档代码编写
使用工作流之前需要创建对应的Spark作业,Spark归档POLARDB可以实现一个完整作业,包括以下流程:
- 在Spark中创建POLARDB表映射表(前提POLARDB中表已经存在)
- 创建Spark分区归档表
- 将数据写入归档表
云Spark提供了Spark归档POLARDB的代码DEMO,请参考github:SparkArchivePolarDB
具体归档代码需结合实际场景,归档不同表,设置特定分区和归档条件等。
上传Spark归档作业资源
将打成jar包的spark归档demo代码通过资源管理上传至资源列表,jar包下载地址:Spark归档工具DEMO下载
自己编写的Spark作业同样需要打成jar包后上传至资源列表,后面作业需要运行jar包中归档作业。
创建Spark作业
进入“HBase控制台”->"数据工作台"->“作业管理”->“创建作业”, 如图

编辑作业内容
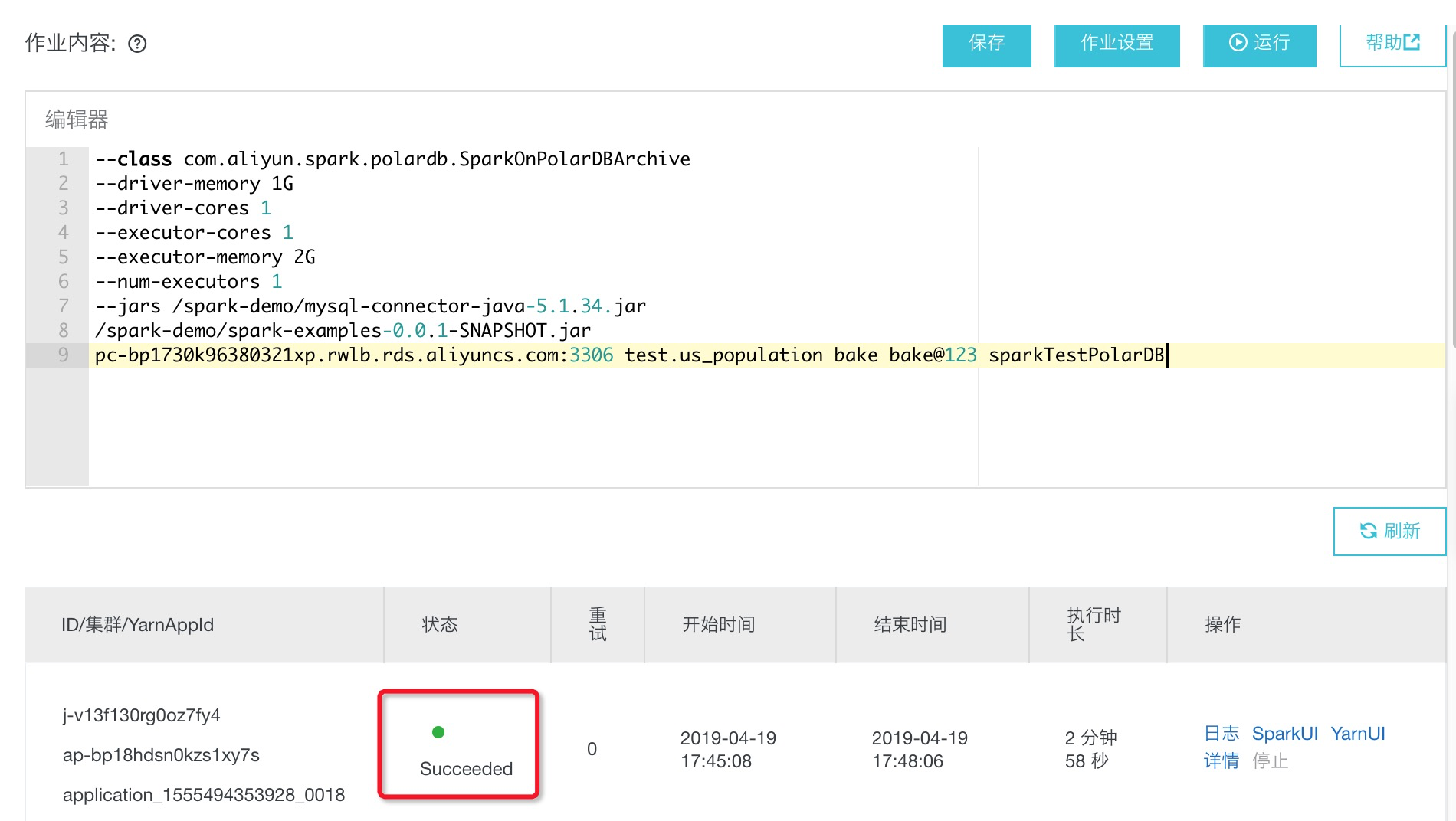
作业内容中主要指定了Spark作业运行参数,以及具体的归档作业编码类和传入参数等,以SparkArchivePolarDB demo为例:
--class com.aliyun.spark.polardb.SparkOnPolarDBArchive
--driver-memory 1G
--driver-cores 1
--executor-cores 1
--executor-memory 2G
--num-executors 1
--jars /spark-demo/mysql-connector-java-5.1.34.jar
/spark-demo/spark-examples-0.0.1-SNAPSHOT.jar
pc-xxx.rwlb.rds.aliyuncs.com:3306 test.us_population username passwd sparkTestPolarDB
参数说明:
| 参数 |
说明 |
| class |
指定spark作业运行主类 |
| /spark-demo/spark-examples-0.0.1-SNAPSHOT.jar |
spark作业所属包 |
| pc-xxx.rwlb.rds.aliyuncs.com:3306 |
polardb的连接串 |
| test.us_population |
归档polardb表 |
| username |
polardb用户名 |
| passwd |
polardb连接密码 |
| sparkTestPolarDB |
spark归档表名 |
其余参数可参见上述章节介绍
作业配置如图:

运行作业并查看结果
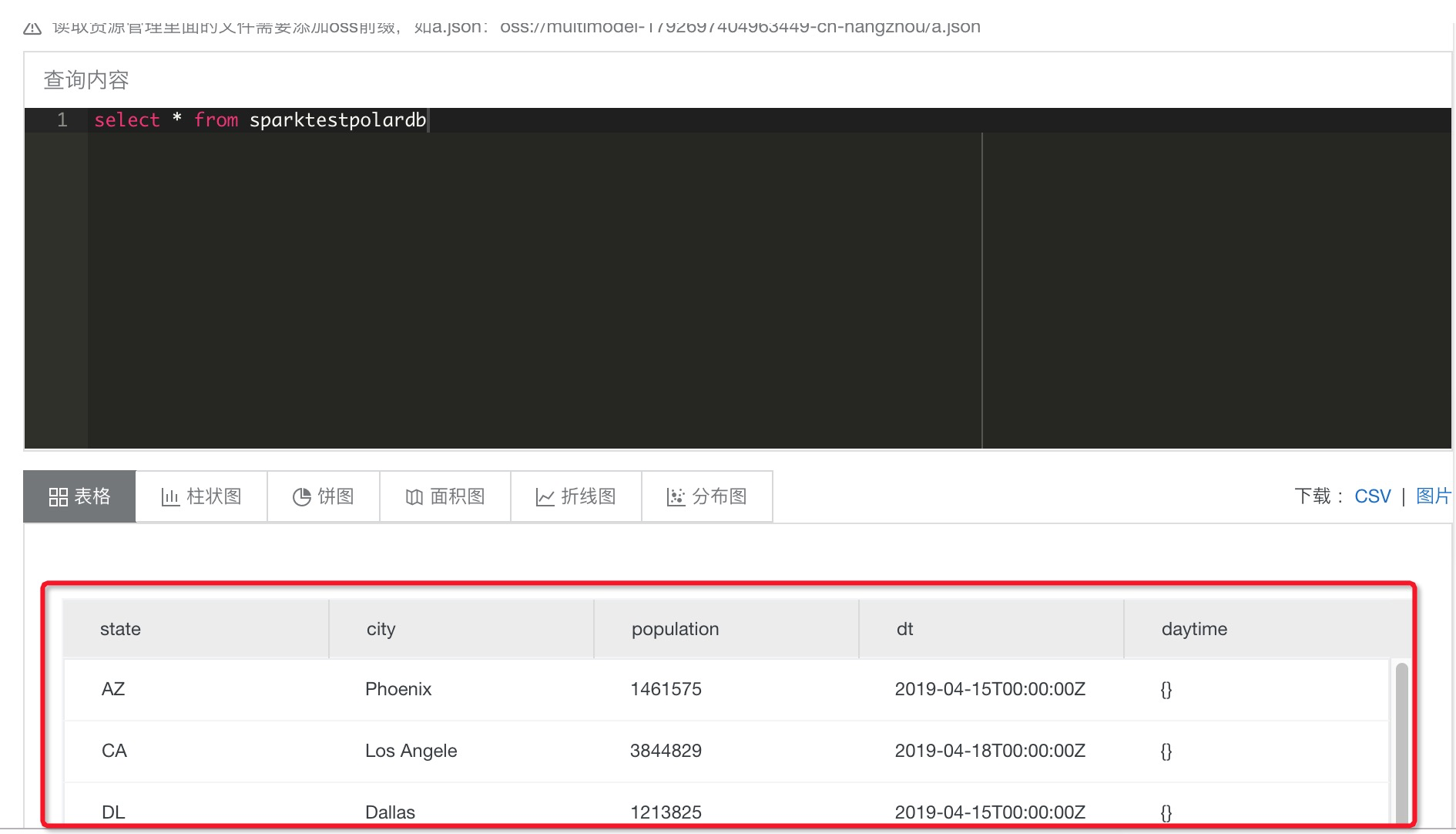
作业运行后一段时间可以查看到运行状态,成功后可在交互式查询中查看归档表数据。
进入交互式工作台,使用可参考上述介绍,查看归档表数据:
配置工作流
进入“HBase控制台”->“数据工作台”->“工作流”,选择新建工作流,指定工作流名称、描述和执行集群,
然后进入工作流设计工作台,拖动Spark作业并进行配置,选择上一步配置作业并连线:

选择"工作流配置"->"调度属性",开启调度状态并设置其实时间和调度周期,工作流即将进行周期性调度,如图:

三、归档方式(产出表的形式)
全量归档
全量归档方式主要用来对原库中历史数据进行归档或者针对数据量比较小的表,归档步骤如下:
- 使用Spark的jdbc datasource创建POLARDB的映射表;
- 在Spark中创建相同表结构的归档表,归档表使用Parquet列式存储,能够最大化节约存储空间,并加速分析性能;
- 通过映射表读取POLARDB数据并写入Spark归档表,注意写入时保证字段顺序一致。
创建归档表时如果表数据量较大,可以创建分区表。分区策略一般分为时间分区和业务分区:
- 时间分区易于使用,即将相同时间的数据归档到同一个目录,比如选择按年或者按天进行时间分区,在分析时限定数据分区即可过滤掉与分析任务无关的数据。
- 业务分区字段需要具有有限的类别,比如性别、年龄、部门等。业务分区需要结合具体业务进行考虑,分区个数不宜过多,spark默认最大分区数为1000。
- 分区方式可以选择静态分区和动态分区,默认使用静态分区,即写入数据时必须指定写入哪个分区,动态分区需要将hive.exec.dynamic.partition.mode设置为nonstrict,写入时根据具体分区字段值动态创建分区,相同partition key值写入同一个分区。
使用示例可参考:SparkOnPolarDBArchivedemo
增量归档
业务数据仅增量
在业务表中数据不存在更新和删除的操作,仅仅是向数据表中增量写入,这种情况下只需要在数据表中记录数据入库时间或者其他标记记录新增数据,在Spark中使用工作流周期调度,传入增量数据条件,定期将新增数据归档只Spark中即可。
业务数据更新
针对业务数据存在更新的数据,如果原表中无法辨别更新的数据,目前只能通过全量归档的方式每次对全量数据进行一次归档,将原归档表数据进行overwrite;如果存在更新数据标记,如update_time字段,由于Spark目前不支持ACID,无法使用merge..into功能直接更新已有数据,增量更新归档步骤如下:
- 设置更新增量数据选择条件(归档表全量归档时已创建),如update_time大于某个日期;
- 抽取增量更新的数据写入spark临时表;
- 将历史数据归档表与增量更新数据表进行left out join并过滤出增量表字段为空的数据,表示历史数据中未参与增量更新的数据,然后与增量更新的数据进行union合并,写入Spark临时表;
- 将临时表数据覆盖写入到归档表中作为新的归档数据参与后续业务分析。
Spark更新增量归档目前只能使用join关联方式遍历所有数据完成数据更新,但好处是尽量避免影响在线库POLARDB的数据访问,每次只读取更新和增量的部分数据,将计算工作放在廉价的Spark集群中。
使用示例可参考:SparkOnPolarDBIncrement
另一种方式:如果在业务侧需要保留多个版本更新的数据,可以直接将更新和增量的数据追加到归档表中,然后在业务侧通过最新时间判断出有效的数据,可以避免每次更新时复杂计算过程。
业务数据更新删除
业务表中如果存在delete,目前Spark没有较好的办法进行支持,需要在业务库记录删除的关键字段信息,与归档表进行join,过滤掉join到的数据然后覆写到归档表中,达到delete的效果。
总结
在进行实际数据开发中,往往需要多个Spark作业配合完成数据归档以及分析工作,单个工作流中支持配置多个作业并按序执行,同时配合交互式工作台进行数据验证,减少很多开发中不便。目前工作台仍在不断优化中,在使用中遇到不便之处可随时提出建议,便于简化您的数据开发工作。
后续X-Pack Spark将提供一键归档功能,敬请期待。
产品链接
X-Pack Spark宣传页:
https://promotion.aliyun.com/ntms/act/hbasespark.html
使用X-Pack Spark帮助文档:
https://help.aliyun.com/document_detail/93899.html?spm=a2c4g.11186623.6.558.762c429dRDeERw
POLARDB产品入口:
https://www.aliyun.com/product/polardb
作者:巴客
原文链接
本文为云栖社区原创内容,未经允许不得转载。

