Author: xidianwangtao@gmail.com, Based Kubernetes 1.12
摘要:在Kubernetes中,Pod是调度的基本单元,也是所有内置Workload管理的基本单元,无论是Deployment还是StatefulSet,它们在对管理的应用进行更新时,都是以Pod为单位,Pod作为Immutable Unit。然而,在部署业务时,Pod中除了业务容器,经常会有一个甚至多个SideCar Container,如何在不影响业务Container的情况下,完成对SideCar Container的原地升级呢,这正是本文需要探讨的技术实现。
为什么需要容器的原地升级
在Docker的世界,容器镜像作为不可变基础设施,解决了环境依赖的难题,而Kubernetes将这提升到了Pod的高度,希望每次应用的更新都通过ReCreate Pod的方式完成,这个理念是非常好的,这样每次ReCreate都是全新的、干净的应用环境。对于微服务的部署,这种方式并没有带来多大的负担,而对于传统应用的部署,一个Pod中可能包含了主业务容器,还有不可剥离的依赖业务容器,以及SideCar组件容器等,这时的Pod就显得很臃肿了,如果因为要更新其中一个SideCar Container而继续按照ReCreate Pod的方式进行整个Pod的重建,那负担还是很大的,体现在:
- Pod的优雅终止时间(默认30s);
- Pod重新调度后可能存在的多个容器镜像的重新下载耗费时间较长;
- 应用启动时间;
因此,因为要更新一个轻量的SideCar却导致了分钟级的单个Pod的重建过程,如果应用副本数高达成百上千,那么整体耗费时间可想而知,如果是使用StatefulSet OrderedReady PodManagementPolicy进行更新的,那代价就是难于接受的。
因此,我们迫切希望能实现,只升级Pod中的某个Container,而不用重建整个Pod,这就是我们说的容器原地升级能力。
Kubernetes是否已经支持Container原地升级
答案是:支持!其实早在两年都前的Kubernetes v1.5版本就有了对应的代码逻辑,本文以Kubernetes 1.12版本的代码进行解读。
很多同学肯定会觉得可疑,Kubernetes中连真正的ReStart都没有,都是ReCreate Pod,怎么会只更新Container呢?没错,在内置的众多Workload的Controller的逻辑中,确实如此。Kubernetes把容器原地升级的能力只做在Kubelet这一层,并没有暴露在Deployment、StatefulSet等Controller中直接提供给用户,原因很简单,还是建议大家把Pod作为完整的部署单元。
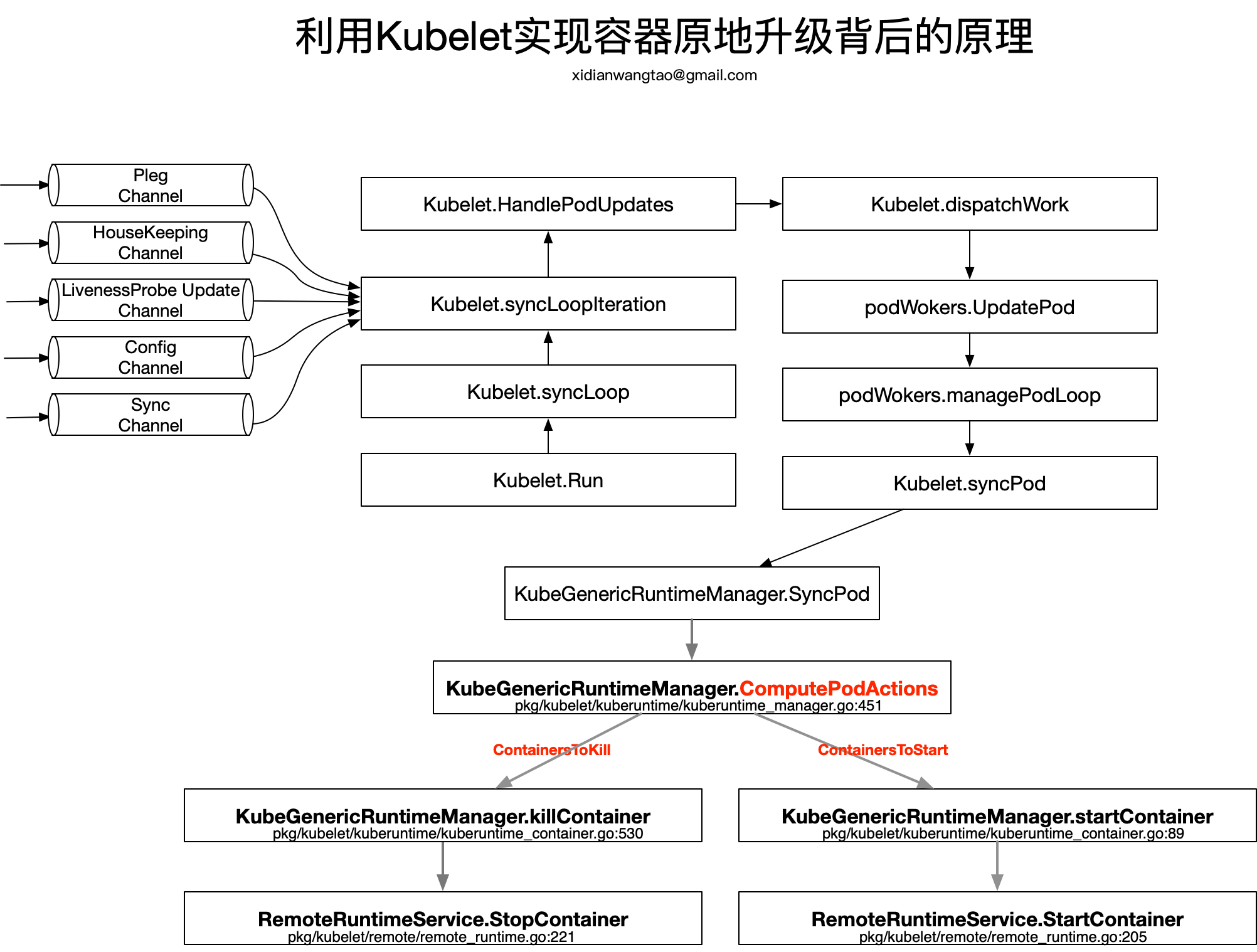
Kubelet启动后通过syncLoop进入到主循环处理Node上Pod Changes事件,监听来自file,apiserver,http三类的事件并汇聚到kubetypes.PodUpdate Channel(Config Channel)中,由syncLoopIteration不断从kubetypes.PodUpdate Channel中消费。
- 为了实现容器原地升级,我们更改Pod.Spec中对应容器的Image,就会生成kubetypes.UPDATE类型的事件,在syncLoopIteration中调用HandlePodUpdates进行处理。
pkg/kubelet/kubelet.go:1870
func (kl *Kubelet) syncLoopIteration(configCh <-chan kubetypes.PodUpdate, handler SyncHandler,
syncCh <-chan time.Time, housekeepingCh <-chan time.Time, plegCh <-chan *pleg.PodLifecycleEvent) bool {
select {
case u, open := <-configCh:
...
switch u.Op {
...
case kubetypes.UPDATE:
glog.V(2).Infof("SyncLoop (UPDATE, %q): %q", u.Source, format.PodsWithDeletionTimestamps(u.Pods))
handler.HandlePodUpdates(u.Pods)
...
...
}
...
}
-
HandlePodUpdates通过dispatchWork分发任务,交给podWorker.UpdatePod进行Pod的更新处理,每个Pod都会per-pod goroutines进行Pod的管理工作,也就是podWorker.managePodLoop。在managePodLoop中调用Kubelet.syncPod进行Pod的sync处理。
-
Kubelet.syncPod中会根据需求进行Pod的Kill、Cgroup的设置、为Static Pod创建Mirror Pod、为Pod创建data directories、等待Volume挂载等工作,最重要的还会调用KubeGenericRuntimeManager.SyncPod进行Pod的状态维护和干预操作。
-
KubeGenericRuntimeManager.SyncPod确保Running Pod处于期望状态,主要执行以下操作。容器原地升级背后的核心原理就从这里开始。
- Compute sandbox and container changes.
- Kill pod sandbox if necessary.
- Kill any containers that should not be running.
- Create sandbox if necessary.
- Create init containers.
- Create normal containers.
-
KubeGenericRuntimeManager.SyncPod中首先调用kubeGenericRuntimeManager.computePodActions检查Pod Spec是否发生变更,并且返回PodActions,记录为了达到期望状态需要执行的变更内容。
pkg/kubelet/kuberuntime/kuberuntime_manager.go:451
// computePodActions checks whether the pod spec has changed and returns the changes if true.
func (m *kubeGenericRuntimeManager) computePodActions(pod *v1.Pod, podStatus *kubecontainer.PodStatus) podActions {
glog.V(5).Infof("Syncing Pod %q: %+v", format.Pod(pod), pod)
createPodSandbox, attempt, sandboxID := m.podSandboxChanged(pod, podStatus)
changes := podActions{
KillPod: createPodSandbox,
CreateSandbox: createPodSandbox,
SandboxID: sandboxID,
Attempt: attempt,
ContainersToStart: []int{},
ContainersToKill: make(map[kubecontainer.ContainerID]containerToKillInfo),
}
// If we need to (re-)create the pod sandbox, everything will need to be
// killed and recreated, and init containers should be purged.
if createPodSandbox {
if !shouldRestartOnFailure(pod) && attempt != 0 {
// Should not restart the pod, just return.
return changes
}
if len(pod.Spec.InitContainers) != 0 {
// Pod has init containers, return the first one.
changes.NextInitContainerToStart = &pod.Spec.InitContainers[0]
return changes
}
// Start all containers by default but exclude the ones that succeeded if
// RestartPolicy is OnFailure.
for idx, c := range pod.Spec.Containers {
if containerSucceeded(&c, podStatus) && pod.Spec.RestartPolicy == v1.RestartPolicyOnFailure {
continue
}
changes.ContainersToStart = append(changes.ContainersToStart, idx)
}
return changes
}
// Check initialization progress.
initLastStatus, next, done := findNextInitContainerToRun(pod, podStatus)
if !done {
if next != nil {
initFailed := initLastStatus != nil && isContainerFailed(initLastStatus)
if initFailed && !shouldRestartOnFailure(pod) {
changes.KillPod = true
} else {
changes.NextInitContainerToStart = next
}
}
// Initialization failed or still in progress. Skip inspecting non-init
// containers.
return changes
}
// Number of running containers to keep.
keepCount := 0
// check the status of containers.
for idx, container := range pod.Spec.Containers {
containerStatus := podStatus.FindContainerStatusByName(container.Name)
// Call internal container post-stop lifecycle hook for any non-running container so that any
// allocated cpus are released immediately. If the container is restarted, cpus will be re-allocated
// to it.
if containerStatus != nil && containerStatus.State != kubecontainer.ContainerStateRunning {
if err := m.internalLifecycle.PostStopContainer(containerStatus.ID.ID); err != nil {
glog.Errorf("internal container post-stop lifecycle hook failed for container %v in pod %v with error %v",
container.Name, pod.Name, err)
}
}
// If container does not exist, or is not running, check whether we
// need to restart it.
if containerStatus == nil || containerStatus.State != kubecontainer.ContainerStateRunning {
if kubecontainer.ShouldContainerBeRestarted(&container, pod, podStatus) {
message := fmt.Sprintf("Container %+v is dead, but RestartPolicy says that we should restart it.", container)
glog.V(3).Infof(message)
changes.ContainersToStart = append(changes.ContainersToStart, idx)
}
continue
}
// The container is running, but kill the container if any of the following condition is met.
reason := ""
restart := shouldRestartOnFailure(pod)
if expectedHash, actualHash, changed := containerChanged(&container, containerStatus); changed {
reason = fmt.Sprintf("Container spec hash changed (%d vs %d).", actualHash, expectedHash)
// Restart regardless of the restart policy because the container
// spec changed.
restart = true
} else if liveness, found := m.livenessManager.Get(containerStatus.ID); found && liveness == proberesults.Failure {
// If the container failed the liveness probe, we should kill it.
reason = "Container failed liveness probe."
} else {
// Keep the container.
keepCount += 1
continue
}
// We need to kill the container, but if we also want to restart the
// container afterwards, make the intent clear in the message. Also do
// not kill the entire pod since we expect container to be running eventually.
message := reason
if restart {
message = fmt.Sprintf("%s. Container will be killed and recreated.", message)
changes.ContainersToStart = append(changes.ContainersToStart, idx)
}
changes.ContainersToKill[containerStatus.ID] = containerToKillInfo{
name: containerStatus.Name,
container: &pod.Spec.Containers[idx],
message: message,
}
glog.V(2).Infof("Container %q (%q) of pod %s: %s", container.Name, containerStatus.ID, format.Pod(pod), message)
}
if keepCount == 0 && len(changes.ContainersToStart) == 0 {
changes.KillPod = true
}
return changes
}
PodActions表示要对Pod进行的操作信息:
pkg/kubelet/kuberuntime/kuberuntime_manager.go:369
// podActions keeps information what to do for a pod.
type podActions struct {
// Stop all running (regular and init) containers and the sandbox for the pod.
KillPod bool
// Whether need to create a new sandbox. If needed to kill pod and create a
// a new pod sandbox, all init containers need to be purged (i.e., removed).
CreateSandbox bool
// The id of existing sandbox. It is used for starting containers in ContainersToStart.
SandboxID string
// The attempt number of creating sandboxes for the pod.
Attempt uint32
// The next init container to start.
NextInitContainerToStart *v1.Container
// ContainersToStart keeps a list of indexes for the containers to start,
// where the index is the index of the specific container in the pod spec (
// pod.Spec.Containers.
ContainersToStart []int
// ContainersToKill keeps a map of containers that need to be killed, note that
// the key is the container ID of the container, while
// the value contains necessary information to kill a container.
ContainersToKill map[kubecontainer.ContainerID]containerToKillInfo
}
因此,computePodActions的关键是的计算出了待启动的和待Kill的容器列表。接下来,KubeGenericRuntimeManager.SyncPod就会在分别调用KubeGenericRuntimeManager.killContainer和startContainer去杀死和启动容器。
func (m *kubeGenericRuntimeManager) SyncPod(pod *v1.Pod, _ v1.PodStatus, podStatus *kubecontainer.PodStatus, pullSecrets []v1.Secret, backOff *flowcontrol.Backoff) (result kubecontainer.PodSyncResult) {
// Step 1: Compute sandbox and container changes.
podContainerChanges := m.computePodActions(pod, podStatus)
...
// Step 2: Kill the pod if the sandbox has changed.
if podContainerChanges.KillPod {
...
} else {
// Step 3: kill any running containers in this pod which are not to keep.
for containerID, containerInfo := range podContainerChanges.ContainersToKill {
glog.V(3).Infof("Killing unwanted container %q(id=%q) for pod %q", containerInfo.name, containerID, format.Pod(pod))
killContainerResult := kubecontainer.NewSyncResult(kubecontainer.KillContainer, containerInfo.name)
result.AddSyncResult(killContainerResult)
if err := m.killContainer(pod, containerID, containerInfo.name, containerInfo.message, nil); err != nil {
killContainerResult.Fail(kubecontainer.ErrKillContainer, err.Error())
glog.Errorf("killContainer %q(id=%q) for pod %q failed: %v", containerInfo.name, containerID, format.Pod(pod), err)
return
}
}
}
...
// Step 4: Create a sandbox for the pod if necessary.
podSandboxID := podContainerChanges.SandboxID
if podContainerChanges.CreateSandbox {
...
}
...
// Step 5: start the init container.
if container := podContainerChanges.NextInitContainerToStart; container != nil {
...
}
// Step 6: start containers in podContainerChanges.ContainersToStart.
for _, idx := range podContainerChanges.ContainersToStart {
container := &pod.Spec.Containers[idx]
startContainerResult := kubecontainer.NewSyncResult(kubecontainer.StartContainer, container.Name)
result.AddSyncResult(startContainerResult)
isInBackOff, msg, err := m.doBackOff(pod, container, podStatus, backOff)
if isInBackOff {
startContainerResult.Fail(err, msg)
glog.V(4).Infof("Backing Off restarting container %+v in pod %v", container, format.Pod(pod))
continue
}
glog.V(4).Infof("Creating container %+v in pod %v", container, format.Pod(pod))
if msg, err := m.startContainer(podSandboxID, podSandboxConfig, container, pod, podStatus, pullSecrets, podIP, kubecontainer.ContainerTypeRegular); err != nil {
startContainerResult.Fail(err, msg)
// known errors that are logged in other places are logged at higher levels here to avoid
// repetitive log spam
switch {
case err == images.ErrImagePullBackOff:
glog.V(3).Infof("container start failed: %v: %s", err, msg)
default:
utilruntime.HandleError(fmt.Errorf("container start failed: %v: %s", err, msg))
}
continue
}
}
return
}
我们只关注整个流程中与容器原地升级原理相关的代码逻辑,对应的流程图如下:
验证
使用StatefulSet部署一个Demo,然后修改某个Pod的Spec中nginx容器的镜像版本,通过kubelet日志可以发现的确如此。
kubelet[1121]: I0412 16:34:28.356083 1121 kubelet.go:1868] SyncLoop (UPDATE, "api"): "web-2_default(2813f459-59cc-11e9-a1f7-525400e7b58a)"
kubelet[1121]: I0412 16:34:28.657836 1121 kuberuntime_manager.go:549] Container "nginx" ({"docker" "8d16517eb4b7b5b84755434eb25c7ab83667bca44318cbbcd89cf8abd232973f"}) of pod web-2_default(2813f459-59cc-11e9-a1f7-525400e7b58a): Container spec hash changed (3176550502 vs 1676109989).. Container will be killed and recreated.
kubelet[1121]: I0412 16:34:28.658529 1121 kuberuntime_container.go:548] Killing container "docker://8d16517eb4b7b5b84755434eb25c7ab83667bca44318cbbcd89cf8abd232973f" with 10 second grace period
kubelet[1121]: I0412 16:34:28.814944 1121 kuberuntime_manager.go:757] checking backoff for container "nginx" in pod "web-2_default(2813f459-59cc-11e9-a1f7-525400e7b58a)"
kubelet[1121]: I0412 16:34:29.179953 1121 kubelet.go:1906] SyncLoop (PLEG): "web-2_default(2813f459-59cc-11e9-a1f7-525400e7b58a)", event: &pleg.PodLifecycleEvent{ID:"2813f459-59cc-11e9-a1f7-525400e7b58a", Type:"ContainerDied", Data:"8d16517eb4b7b5b84755434eb25c7ab83667bca44318cbbcd89cf8abd232973f"}
kubelet[1121]: I0412 16:34:29.182257 1121 kubelet.go:1906] SyncLoop (PLEG): "web-2_default(2813f459-59cc-11e9-a1f7-525400e7b58a)", event: &pleg.PodLifecycleEvent{ID:"2813f459-59cc-11e9-a1f7-525400e7b58a", Type:"ContainerStarted", Data:"52e30b1aa621a20ae2eae5accf98c451c1be3aed781609d5635a79e48eb98222"}
从本地docker ps -a命令也能得到验证:老的容器被终止了,新的容器起来了,而且watch Pod发现Pod没有重建。

总结
总结一下,当用户修改了Pod Spec中某个Container的Image信息后,在KubeGenericRuntimeManager.computePodActions中发现该Container Spec Hash发生改变,调用KubeGenericRuntimeManager.killContainer将容器优雅终止。旧的容器被杀死之后,computePodActions中会发现Pod Spec中定义的Container没有启动,就会调用KubeGenericRuntimeManager.startContainer启动新的容器,如此即完成Pod不重建的前提下实现容器的原地升级。了解技术原理后,我们可以开发一个CRD/Operator,在Operator的逻辑中,实现业务负载层面的灰度的或者滚动的容器原地升级的能力,这样就能解决臃肿Pod中只更新某个镜像而不影响其他容器的问题了。

