自从2012年AlexNet网络在ImageNet挑战赛上取得巨大成功之后,计算机视觉和深度学习等领域再一次迎来研究热潮。计算机视觉,从字面意义上理解就是让计算机等机器也具备人类视觉,研究让机器进行图像分类、目标检测等。在这近十年里,该领域取得的成就让人大吃一惊,有些研究已经超越了人类的表现水平。
对于想入门或者从事深度学习领域的工作者而言,一般是从计算机视觉入手,网上有很多资料去介绍理论方面的知识,进行相应的实践也必不可少。本文总结一些在计算机视觉和深度学习领域的一些实践项目,供读者针对自己的感兴趣点挑选并实践。
如果不熟悉上述术语,可以从下面的文章中了解更多的相关信息:
下面进行正文介绍:
1.使用OpenCV进行手部动作跟踪
项目地址:akshaybahadur21/HandMovementTracking
为了执行视频跟踪,算法分析连续视频帧并输出帧之间的目标移动。针对这类问题,有各种各样的算法,每种算法都有各自的优缺点。在选择使用哪种算法时,针对实际应用场景考虑是很重要的。视觉跟踪系统有两个主要组成部分:目标表示和局部化,以及过滤和数据关联。
视频跟踪是使用相机随时间定位移动物体(或多个物体)的过程。它有多种用途,比如:人机交互、安全和监控、视频通信和压缩、增强现实、交通控制、医学成像和视频编辑等。

项目代码如下:
import numpy as np
import cv2
import argparse
from collections import deque
cap=cv2.VideoCapture(0)
pts = deque(maxlen=64)
Lower_green = np.array([110,50,50])
Upper_green = np.array([130,255,255])
while True:
ret, img=cap.read()
hsv=cv2.cvtColor(img,cv2.COLOR_BGR2HSV)
kernel=np.ones((5,5),np.uint8)
mask=cv2.inRange(hsv,Lower_green,Upper_green)
mask = cv2.erode(mask, kernel, iterations=2)
mask=cv2.morphologyEx(mask,cv2.MORPH_OPEN,kernel)
#mask=cv2.morphologyEx(mask,cv2.MORPH_CLOSE,kernel)
mask = cv2.dilate(mask, kernel, iterations=1)
res=cv2.bitwise_and(img,img,mask=mask)
cnts,heir=cv2.findContours(mask.copy(),cv2.RETR_EXTERNAL,cv2.CHAIN_APPROX_SIMPLE)[-2:]
center = None
if len(cnts) > 0:
c = max(cnts, key=cv2.contourArea)
((x, y), radius) = cv2.minEnclosingCircle(c)
M = cv2.moments(c)
center = (int(M["m10"] / M["m00"]), int(M["m01"] / M["m00"]))
if radius > 5:
cv2.circle(img, (int(x), int(y)), int(radius),(0, 255, 255), 2)
cv2.circle(img, center, 5, (0, 0, 255), -1)
pts.appendleft(center)
for i in xrange (1,len(pts)):
if pts[i-1]is None or pts[i] is None:
continue
thick = int(np.sqrt(len(pts) / float(i + 1)) * 2.5)
cv2.line(img, pts[i-1],pts[i],(0,0,225),thick)
cv2.imshow("Frame", img)
cv2.imshow("mask",mask)
cv2.imshow("res",res)
k=cv2.waitKey(30) & 0xFF
if k==32:
break
# cleanup the camera and close any open windows
cap.release()
cv2.destroyAllWindows()
54行代码即可解决这个问题,很简单吧!该项目依赖Opencv包,需要在计算机中安装OpenCV才能执行这个项目,下面是针对Mac系统、Ubuntu系统以及Windows系统的安装方法:
-
Mac系统:
-
Ubuntu系统:
-
Windows系统:
2.使用OpenCV进行睡意检测
项目地址:akshaybahadur21/Drowsiness_Detection
睡意检测对于长时间驾驶、工厂生产等场景很重要,由于长时间开车时,容易产生睡意,进而可能导致事故。当用户昏昏欲睡时,此代码可以通过检测眼睛来发出警报。
依赖包
CV2
immutils
DLIB
SciPy
实现算法
每只眼睛用6个(x,y)坐标表示,从眼睛的左角开始,然后顺时针绕眼睛工作:

条件
它检查20个连续帧,如果眼睛纵横比低于0.25,则生成警报。
关系
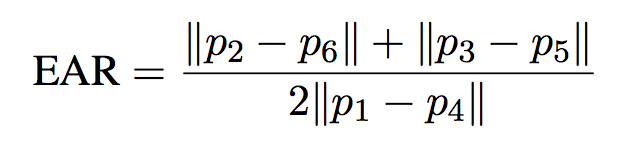
实现

https://cdn-images-1.medium.com/max/800/1*rA3cxL2429vOi4jsuscPug.gif
3.使用Softmax回归进行数字手写体识别
项目地址:akshaybahadur21/Digit-Recognizer
此代码使用softmax回归对不同的数字进行分类,依赖的包有点多,可以安装下Conda,它包含了机器学习所需要的所有依赖包。
描述
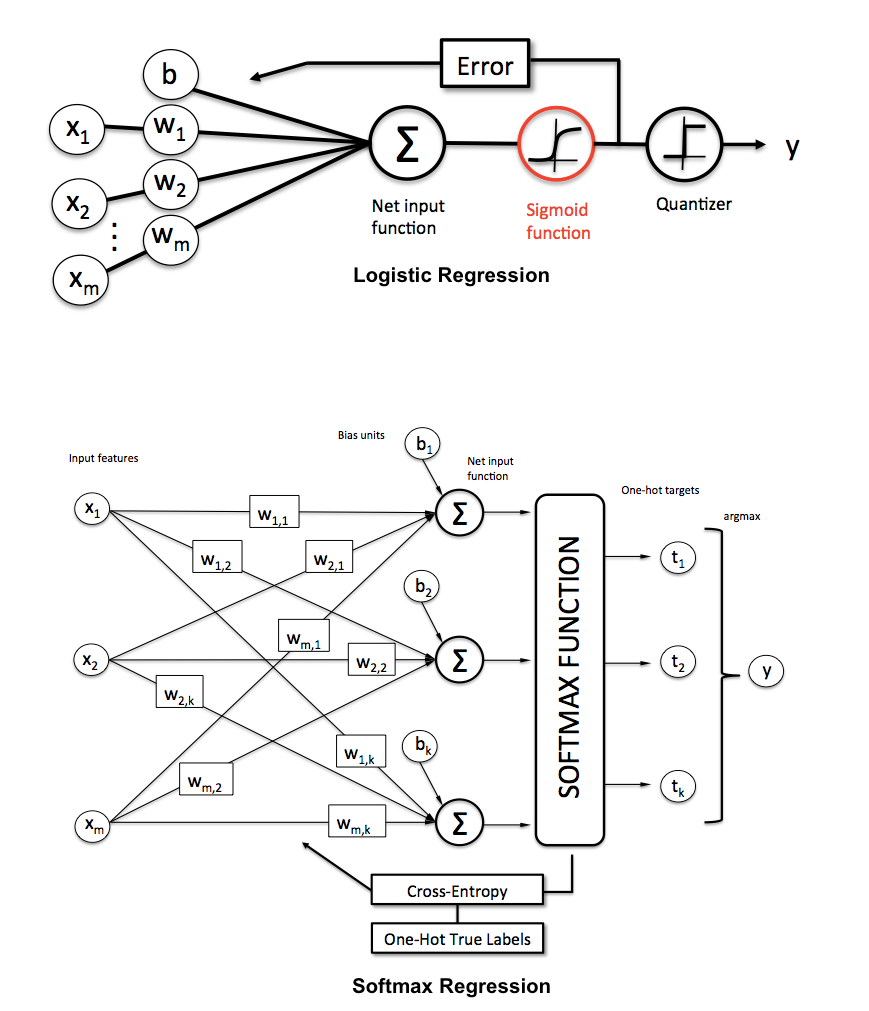
Softmax回归(同义词:多项Logistic、最大熵分类器、多类Logistic回归)是逻辑回归的推广,可以将其用于多类分类(假设类间是互斥的)。相反,在二分类任务中使用(标准)Logistic回归模型。
Python实现
使用的是MNIST数字手写体数据集,每张图像大小为28×28,这里尝试使用三种方法对0到9的数字进行分类,分别是Logistic回归、浅层神经网络和深度神经网络。
import numpy as np
import matplotlib.pyplot as plt
def softmax(z):
z -= np.max(z)
sm = (np.exp(z).T / np.sum(np.exp(z), axis=1))
return sm
def initialize(dim1, dim2):
"""
:param dim: size of vector w initilazied with zeros
:return:
"""
w = np.zeros(shape=(dim1, dim2))
b = np.zeros(shape=(10, 1))
return w, b
def propagate(w, b, X, Y):
"""
:param w: weights for w
:param b: bias
:param X: size of data(no of features, no of examples)
:param Y: true label
:return:
"""
m = X.shape[1] # getting no of rows
# Forward Prop
A = softmax((np.dot(w.T, X) + b).T)
cost = (-1 / m) * np.sum(Y * np.log(A))
# backwar prop
dw = (1 / m) * np.dot(X, (A - Y).T)
db = (1 / m) * np.sum(A - Y)
cost = np.squeeze(cost)
grads = {"dw": dw,
"db": db}
return grads, cost
def optimize(w, b, X, Y, num_iters, alpha, print_cost=False):
"""
:param w: weights for w
:param b: bias
:param X: size of data(no of features, no of examples)
:param Y: true label
:param num_iters: number of iterations for gradient
:param alpha:
:return:
"""
costs = []
for i in range(num_iters):
grads, cost = propagate(w, b, X, Y)
dw = grads["dw"]
db = grads["db"]
w = w - alpha * dw
b = b - alpha * db
# Record the costs
if i % 50 == 0:
costs.append(cost)
# Print the cost every 100 training examples
if print_cost and i % 50 == 0:
print("Cost after iteration %i: %f" % (i, cost))
params = {"w": w,
"b": b}
grads = {"dw": dw,
"db": db}
return params, grads, costs
def predict(w, b, X):
"""
:param w:
:param b:
:param X:
:return:
"""
# m = X.shape[1]
# y_pred = np.zeros(shape=(1, m))
# w = w.reshape(X.shape[0], 1)
y_pred = np.argmax(softmax((np.dot(w.T, X) + b).T), axis=0)
return y_pred
def model(X_train, Y_train, Y,X_test,Y_test, num_iters, alpha, print_cost):
"""
:param X_train:
:param Y_train:
:param X_test:
:param Y_test:
:param num_iterations:
:param learning_rate:
:param print_cost:
:return:
"""
w, b = initialize(X_train.shape[0], Y_train.shape[0])
parameters, grads, costs = optimize(w, b, X_train, Y_train, num_iters, alpha, print_cost)
w = parameters["w"]
b = parameters["b"]
y_prediction_train = predict(w, b, X_train)
y_prediction_test = predict(w, b, X_test)
print("Train accuracy: {} %", sum(y_prediction_train == Y) / (float(len(Y))) * 100)
print("Test accuracy: {} %", sum(y_prediction_test == Y_test) / (float(len(Y_test))) * 100)
d = {"costs": costs,
"Y_prediction_test": y_prediction_test,
"Y_prediction_train": y_prediction_train,
"w": w,
"b": b,
"learning_rate": alpha,
"num_iterations": num_iters}
# Plot learning curve (with costs)
#costs = np.squeeze(d['costs'])
#plt.plot(costs)
#plt.ylabel('cost')
#plt.xlabel('iterations (per hundreds)')
#plt.title("Learning rate =" + str(d["learning_rate"]))
#plt.plot()
#plt.show()
#plt.close()
#pri(X_test.T, y_prediction_test)
return d
def pri(X_test, y_prediction_test):
example = X_test[2, :]
print("Prediction for the example is ", y_prediction_test[2])
plt.imshow(np.reshape(example, [28, 28]))
plt.plot()
plt.show()
import numpy as np
import matplotlib.pyplot as plt
def softmax(z):
z -= np.max(z)
sm = (np.exp(z).T / np.sum(np.exp(z),axis=1))
return sm
def layers(X, Y):
"""
:param X:
:param Y:
:return:
"""
n_x = X.shape[0]
n_y = Y.shape[0]
return n_x, n_y
def initialize_nn(n_x, n_h, n_y):
"""
:param n_x:
:param n_h:
:param n_y:
:return:
"""
np.random.seed(2)
W1 = np.random.randn(n_h, n_x) * 0.01
b1 = np.random.rand(n_h, 1)
W2 = np.random.rand(n_y, n_h)
b2 = np.random.rand(n_y, 1)
parameters = {"W1": W1,
"b1": b1,
"W2": W2,
"b2": b2}
return parameters
def forward_prop(X, parameters):
W1 = parameters['W1']
b1 = parameters['b1']
W2 = parameters['W2']
b2 = parameters['b2']
Z1 = np.dot(W1, X) + b1
A1 = np.tanh(Z1)
Z2 = np.dot(W2, A1) + b2
A2 = softmax(Z2.T)
cache = {"Z1": Z1,
"A1": A1,
"Z2": Z2,
"A2": A2}
return A2, cache
def compute_cost(A2, Y, parameters):
m = Y.shape[1]
W1 = parameters['W1']
W2 = parameters['W2']
logprobs = np.multiply(np.log(A2), Y)
cost = - np.sum(logprobs) / m
cost = np.squeeze(cost)
return cost
def back_prop(parameters, cache, X, Y):
m = Y.shape[1]
W1 = parameters['W1']
W2 = parameters['W2']
A1 = cache['A1']
A2 = cache['A2']
dZ2 = A2 - Y
dW2 = (1 / m) * np.dot(dZ2, A1.T)
db2 = (1 / m) * np.sum(dZ2, axis=1, keepdims=True)
dZ1 = np.multiply(np.dot(W2.T, dZ2), 1 - np.square(A1))
dW1 = (1 / m) * np.dot(dZ1, X.T)
db1 = (1 / m) * np.sum(dZ1, axis=1, keepdims=True)
grads = {"dW1": dW1,
"db1": db1,
"dW2": dW2,
"db2": db2}
return grads
def update_params(parameters, grads, alpha):
W1 = parameters['W1']
b1 = parameters['b1']
W2 = parameters['W2']
b2 = parameters['b2']
dW1 = grads['dW1']
db1 = grads['db1']
dW2 = grads['dW2']
db2 = grads['db2']
W1 = W1 - alpha * dW1
b1 = b1 - alpha * db1
W2 = W2 - alpha * dW2
b2 = b2 - alpha * db2
parameters = {"W1": W1,
"b1": b1,
"W2": W2,
"b2": b2}
return parameters
def model_nn(X, Y,Y_real,test_x,test_y, n_h, num_iters, alpha, print_cost):
np.random.seed(3)
n_x,n_y = layers(X, Y)
parameters = initialize_nn(n_x, n_h, n_y)
W1 = parameters['W1']
b1 = parameters['b1']
W2 = parameters['W2']
b2 = parameters['b2']
costs = []
for i in range(0, num_iters):
A2, cache = forward_prop(X, parameters)
cost = compute_cost(A2, Y, parameters)
grads = back_prop(parameters, cache, X, Y)
if (i > 1500):
alpha1 = 0.95*alpha
parameters = update_params(parameters, grads, alpha1)
else:
parameters = update_params(parameters, grads, alpha)
if i % 100 == 0:
costs.append(cost)
if print_cost and i % 100 == 0:
print("Cost after iteration for %i: %f" % (i, cost))
predictions = predict_nn(parameters, X)
print("Train accuracy: {} %", sum(predictions == Y_real) / (float(len(Y_real))) * 100)
predictions=predict_nn(parameters,test_x)
print("Train accuracy: {} %", sum(predictions == test_y) / (float(len(test_y))) * 100)
#plt.plot(costs)
#plt.ylabel('cost')
#plt.xlabel('iterations (per hundreds)')
#plt.title("Learning rate =" + str(alpha))
#plt.show()
return parameters
def predict_nn(parameters, X):
A2, cache = forward_prop(X, parameters)
predictions = np.argmax(A2, axis=0)
return predictions
import numpy as np
import matplotlib.pyplot as plt
def softmax(z):
cache = z
z -= np.max(z)
sm = (np.exp(z).T / np.sum(np.exp(z), axis=1))
return sm, cache
def relu(z):
"""
:param z:
:return:
"""
s = np.maximum(0, z)
cache = z
return s, cache
def softmax_backward(dA, cache):
"""
:param dA:
:param activation_cache:
:return:
"""
z = cache
z -= np.max(z)
s = (np.exp(z).T / np.sum(np.exp(z), axis=1))
dZ = dA * s * (1 - s)
return dZ
def relu_backward(dA, cache):
"""
:param dA:
:param activation_cache:
:return:
"""
Z = cache
dZ = np.array(dA, copy=True) # just converting dz to a correct object.
dZ[Z <= 0] = 0
return dZ
def initialize_parameters_deep(dims):
"""
:param dims:
:return:
"""
np.random.seed(3)
params = {}
L = len(dims)
for l in range(1, L):
params['W' + str(l)] = np.random.randn(dims[l], dims[l - 1]) * 0.01
params['b' + str(l)] = np.zeros((dims[l], 1))
return params
def linear_forward(A, W, b):
"""
:param A:
:param W:
:param b:
:return:
"""
Z = np.dot(W, A) + b
cache = (A, W, b)
return Z, cache
def linear_activation_forward(A_prev, W, b, activation):
"""
:param A_prev:
:param W:
:param b:
:param activation:
:return:
"""
if activation == "softmax":
Z, linear_cache = linear_forward(A_prev, W, b)
A, activation_cache = softmax(Z.T)
elif activation == "relu":
Z, linear_cache = linear_forward(A_prev, W, b)
A, activation_cache = relu(Z)
cache = (linear_cache, activation_cache)
return A, cache
def L_model_forward(X, params):
"""
:param X:
:param params:
:return:
"""
caches = []
A = X
L = len(params) // 2 # number of layers in the neural network
# Implement [LINEAR -> RELU]*(L-1). Add "cache" to the "caches" list.
for l in range(1, L):
A_prev = A
A, cache = linear_activation_forward(A_prev,
params["W" + str(l)],
params["b" + str(l)],
activation='relu')
caches.append(cache)
A_last, cache = linear_activation_forward(A,
params["W" + str(L)],
params["b" + str(L)],
activation='softmax')
caches.append(cache)
return A_last, caches
def compute_cost(A_last, Y):
"""
:param A_last:
:param Y:
:return:
"""
m = Y.shape[1]
cost = (-1 / m) * np.sum(Y * np.log(A_last))
cost = np.squeeze(cost) # To make sure your cost's shape is what we expect (e.g. this turns [[17]] into 17).
return cost
def linear_backward(dZ, cache):
"""
:param dZ:
:param cache:
:return:
"""
A_prev, W, b = cache
m = A_prev.shape[1]
dW = (1. / m) * np.dot(dZ, cache[0].T)
db = (1. / m) * np.sum(dZ, axis=1, keepdims=True)
dA_prev = np.dot(cache[1].T, dZ)
return dA_prev, dW, db
def linear_activation_backward(dA, cache, activation):
"""
:param dA:
:param cache:
:param activation:
:return:
"""
linear_cache, activation_cache = cache
if activation == "relu":
dZ = relu_backward(dA, activation_cache)
dA_prev, dW, db = linear_backward(dZ, linear_cache)
elif activation == "softmax":
dZ = softmax_backward(dA, activation_cache)
dA_prev, dW, db = linear_backward(dZ, linear_cache)
return dA_prev, dW, db
def L_model_backward(A_last, Y, caches):
"""
:param A_last:
:param Y:
:param caches:
:return:
"""
grads = {}
L = len(caches) # the number of layers
m = A_last.shape[1]
Y = Y.reshape(A_last.shape) # after this line, Y is the same shape as A_last
dA_last = - (np.divide(Y, A_last) - np.divide(1 - Y, 1 - A_last))
current_cache = caches[-1]
grads["dA" + str(L)], grads["dW" + str(L)], grads["db" + str(L)] = linear_activation_backward(dA_last,
current_cache,
activation="softmax")
for l in reversed(range(L - 1)):
current_cache = caches[l]
dA_prev_temp, dW_temp, db_temp = linear_activation_backward(grads["dA" + str(l + 2)], current_cache,
activation="relu")
grads["dA" + str(l + 1)] = dA_prev_temp
grads["dW" + str(l + 1)] = dW_temp
grads["db" + str(l + 1)] = db_temp
return grads
def update_params(params, grads, alpha):
"""
:param params:
:param grads:
:param alpha:
:return:
"""
L = len(params) // 2 # number of layers in the neural network
for l in range(L):
params["W" + str(l + 1)] = params["W" + str(l + 1)] - alpha * grads["dW" + str(l + 1)]
params["b" + str(l + 1)] = params["b" + str(l + 1)] - alpha * grads["db" + str(l + 1)]
return params
def model_DL( X, Y, Y_real, test_x, test_y, layers_dims, alpha, num_iterations, print_cost): # lr was 0.009
"""
Implements a L-layer neural network: [LINEAR->RELU]*(L-1)->LINEAR->SIGMOID.
Arguments:
X -- data, numpy array of shape (number of examples, num_px * num_px * 3)
Y -- true "label" vector (containing 0 if cat, 1 if non-cat), of shape (1, number of examples)
layers_dims -- list containing the input size and each layer size, of length (number of layers + 1).
alpha -- learning rate of the gradient descent update rule
num_iterations -- number of iterations of the optimization loop
print_cost -- if True, it prints the cost every 100 steps
Returns:
params -- params learnt by the model. They can then be used to predict.
"""
np.random.seed(1)
costs = [] # keep track of cost
params = initialize_parameters_deep(layers_dims)
for i in range(0, num_iterations):
A_last, caches = L_model_forward(X, params)
cost = compute_cost(A_last, Y)
grads = L_model_backward(A_last, Y, caches)
if (i > 800 and i<1700):
alpha1 = 0.80 * alpha
params = update_params(params, grads, alpha1)
elif(i>=1700):
alpha1 = 0.50 * alpha
params = update_params(params, grads, alpha1)
else:
params = update_params(params, grads, alpha)
if print_cost and i % 100 == 0:
print("Cost after iteration %i: %f" % (i, cost))
if print_cost and i % 100 == 0:
costs.append(cost)
predictions = predict(params, X)
print("Train accuracy: {} %", sum(predictions == Y_real) / (float(len(Y_real))) * 100)
predictions = predict(params, test_x)
print("Test accuracy: {} %", sum(predictions == test_y) / (float(len(test_y))) * 100)
#plt.plot(np.squeeze(costs))
#plt.ylabel('cost')
#plt.xlabel('iterations (per tens)')
#plt.title("Learning rate =" + str(alpha))
#plt.show()
return params
def predict(parameters, X):
A_last, cache = L_model_forward(X, parameters)
predictions = np.argmax(A_last, axis=0)
return predictions
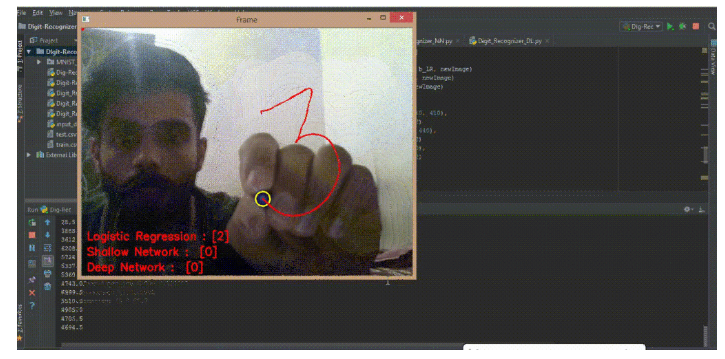
通过网络摄像头执行写入
运行代码
python Dig-Rec.py
https://cdn-images-1.medium.com/max/800/1*WTV3DSu0HUnoN2HI6c5wbw.gif
通过网络摄像头显示图像
运行代码
python Digit-Recognizer.py

https://cdn-images-1.medium.com/max/800/1*f_XcMY2RSBGDlhElBwRqnA.gif
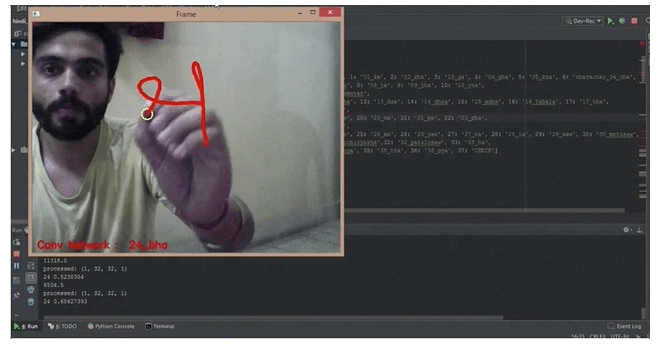
梵文字母识别
项目地址:akshaybahadur21/Devanagiri-Recognizer
此代码可帮助您使用CNN对不同梵文字母进行分类。
使用技术
使用了卷积神经网络,使用Tensorflow作为框架和Keras API来提供高级抽象。
网络结构
CONV2D→MAXPOOL→CONV2D→MAXPOOL→FC→Softmax→Classification
额外的要点
1.可以尝试不同的网络结构;
2.添加正则化以防止过拟合;
3.可以向训练集添加其他图像以提高准确性;
Python实现
使用Dataset-DHCD(Devnagari Character Dataset)数据集,每张图大小为32 X 32,详细代码请参考项目地址。
运行代码
python Dev-Rec.py
https://cdn-images-1.medium.com/max/800/1*VKAL2X-Up49EklMvm-h6qg.gif
4.使用FaceNet进行面部识别
项目地址:akshaybahadur21/Face-Recoinion
此代码使用facenet进行面部识别。facenet的概念最初是在一篇研究论文中提出的,主要思想是谈到三重损失函数来比较不同人的图像。为了提供稳定性和更好的检测,额外添加了自己的几个功能。
本项目依赖的包如下:
numpy
matplotlib
cv2
keras
dlib
h5py
scipy
描述
面部识别系统是能够从数字图像或来自视频源的视频帧识别或验证人的技术。面部识别系统有多种方法,但一般来说,它们都是通过将给定图像中的选定面部特征与数据库中的面部进行比较来工作。
功能增加
1.仅在眼睛睁开时检测脸部(安全措施);
2.使用dlib中的面部对齐功能在实时流式传输时有效预测;
Python实现
1.网络使用 - Inception Network;
2.原始论文 - Google的Facenet;
程序
1.如果想训练网络,运行Train-inception.py,但是不需要这样做,因为已经训练了模型并将其保存为face-rec_Google.h5,在运行时只需加载这个文件即可;
2.现在需要在数据库中放置一些图像。检查/images文件夹,可以将图片粘贴到此,也可以使用网络摄像头拍摄;
3.运行rec-feat.py以运行该应用程序;
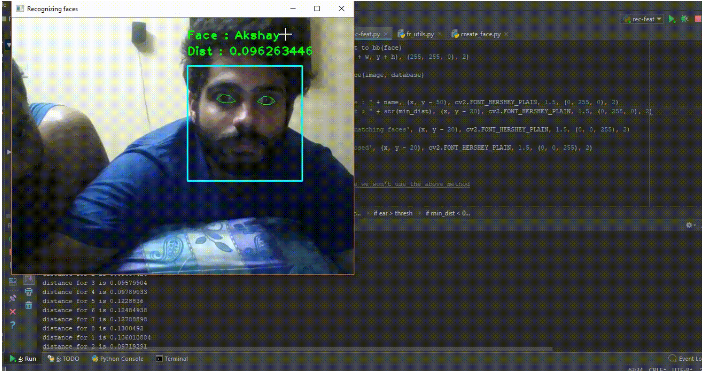
https://cdn-images-1.medium.com/max/800/1*sNLiysO0eCj49kg3ZR3m_Q.gif
5.表情识别器
项目地址akshaybahadur21/Emojinator
此项目可识别和分类不同的表情符号。但是目前为止,只支持手势表达的情绪。
代码依赖包
numpy
matplotlib
cv2
keras
dlib
h5py
scipy
描述
表情符号是电子信息和网页中使用的表意文字和表情的符号。表情符号存在于各种类型中,包括面部表情、常见物体、地点和天气以及动物等。
功能
1.用于检测手的过滤器;
2.CNN用于训练模型;
Python实现
1.网络使用 - 卷积神经网络
程序
1.首先,创建一个手势数据库。为此,运行CreateGest.py。尝试在框架内稍微移动一下手,以确保模型在训练时不会发生过拟合;
2.对所需的所有功能重复此操作;
3.运行CreateCSV.py将图像转换为CSV文件;
4.训练模型,运行TrainEmojinator.py;
5.运行Emojinator.py通过网络摄像头测试模型;
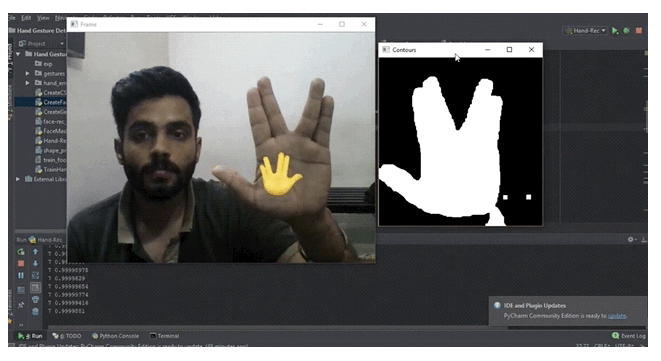
https://cdn-images-1.medium.com/max/800/1*S__r_PVF7Q1Egvl3iWts8g.gif
总结
这些项目都令人印象深刻,所有这些项目都可以在计算机上运行。如果你不想安装任何东西,可以更轻松地在Deep Cognition平台上运行,并且可以在线运行。
感谢网络上各种开源项目的贡献。尝试一下各种感兴趣的项目,运行它们并获得灵感。上述这些这只是深度学习和计算机视觉可以做的事情中的一小部分,还有很多事情可以尝试,并且可以将其转变为帮助世界变得更美好的事情,code change world!
此外,每个人都应该对许多不同的事情感兴趣。我认为这样可以改善世界、改善生活、改善工作方式,思考和解决问题的方式,如果我们依据现在所掌握的资源,使这些知识领域共同发挥作用,我们就可以在世界和生活中产生巨大的积极影响。
作者:【方向】
原文链接
本文为云栖社区原创内容,未经允许不得转载。

