时序数据库连载系列:时序数据库那些事
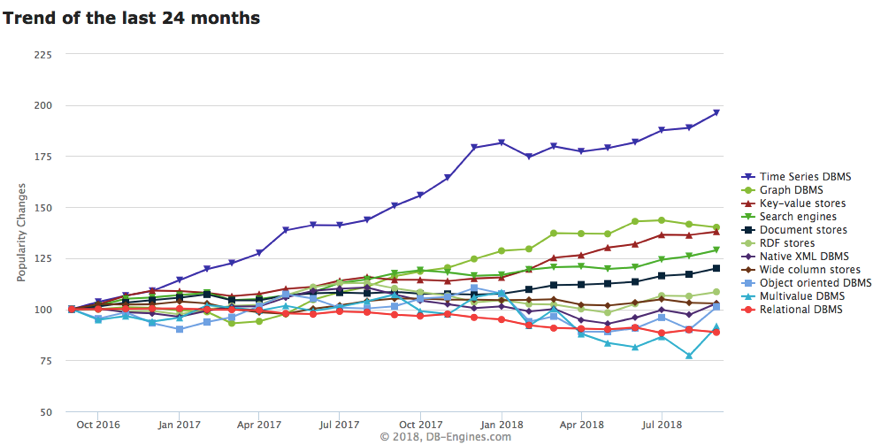
正如《银翼杀手》中那句在影史流传经典的台词:“I've seen things you people wouldn't believe... All those ... moments will be lost in time, like tears...in rain.” 时间浩瀚的人类历史长河中总是一个耀眼的词汇,当科技的年轮划到数据时代,时间与数据库碰到一起,把数据库内建时间属性后,产生了时序数据库。时序数据库是一种带有时间戳业务属性的垂直型数据库。自从2014年开始,数据库热度排名网站DB-Engines就把时间序列数据库作为了独立的目录来分类统计,而且最近几年的增长率在全部数据库分类里排名第一(见下图)。
时序数据库
A time series database (TSDB) is a software system that is optimized for handling time series data, arrays of numbers indexed by time (a datetime or a datetime range)
以上是维基百科对于时序数据库的定义。可以把它拆解成3个方面来看:时序特性,数据特性,数据库特性。
-
时序特性:
-
数据特性:
- 数据顺序追加
- 数据可多维关联
- 通常高频访问热数据
- 冷数据需要降维归档
- 数据主要覆盖数值,状态,事件
-
数据库特性(CRUD)
- 写入速率稳定并且远远大于读取
- 按照时间窗口访问数据
- 极少更新,存在一定窗口期的覆盖写
- 批量删除
- 具备通用数据库要求的高可用,高可靠,可伸缩特性
- 通常不需要具备事务的能力
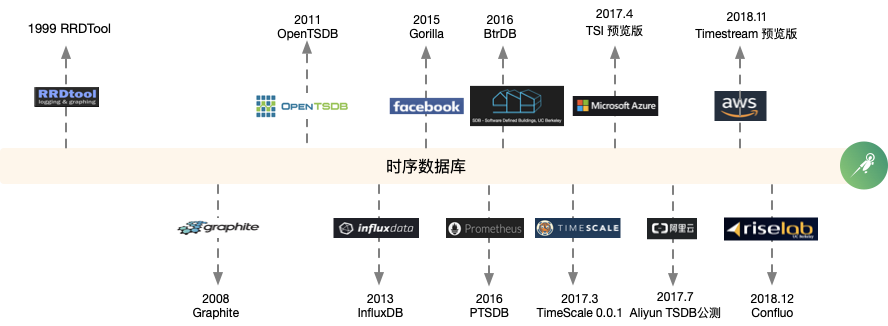
时序数据库发展简史
第一代时序数据存储系统
虽然通用关系数据库可以存储时序数据,但是由于缺乏针对时间的特殊优化,比如按时间间隔存储和检索数据等等,因此在处理这些数据时效率相对不高。
第一代时序数据典型来源于监控领域,直接基于平板文件的简单存储工具成为这类数据的首先存储方式。
以RRDTool,Wishper为代表,通常这类系统处理的数据模型比较单一,单机容量受限,并且内嵌于监控告警方案。
基于通用存储的时序数据库
伴随着大数据和Hadoop的发展,时序数据量开始迅速增长,系统业务对于处理时序数据的扩展性等方面提出更多的要求。
基于通用存储而专门构建的时间序列数据库开始出现,它可以按时间间隔高效地存储和处理这些数据。像OpenTSDB,KairosDB等等。
这类时序数据库在继承通用存储优势的基础上,利用时序的特性规避部分通用存储的劣势,并且在数据模型,聚合分析方面做了贴合时序的大量创新。
比如OpenTSDB继承了HBase的宽表属性结合时序设计了偏移量的存储模型,利用salt缓解热点问题等等。
然而它也有诸多不足之处,比如低效的全局UID机制,聚合数据的加载不可控,无法处理高基数标签查询等等。
垂直型时序数据库的出现
随着docker,kubernetes, 微服务等技术的发展,以及对于IoT的发展预期越来越强烈。
在数据随着时间而增长的过程中,时间序列数据成为增长最快的数据类型之一。
高性能,低成本的垂直型时序数据库开始诞生,以InfluxDB为代表的具有时序特征的数据存储引擎逐步引领市场。
它们通常具备更加高级的数据处理能力,高效的压缩算法和符合时序特征的存储引擎。
比如InfluxDB的基于时间的TSMT存储,Gorilla压缩,面向时序的窗口计算函数p99,rate,自动rollup等等。
同时由于索引分离的架构,在膨胀型时间线,乱序等场景下依然面临着很大的挑战。
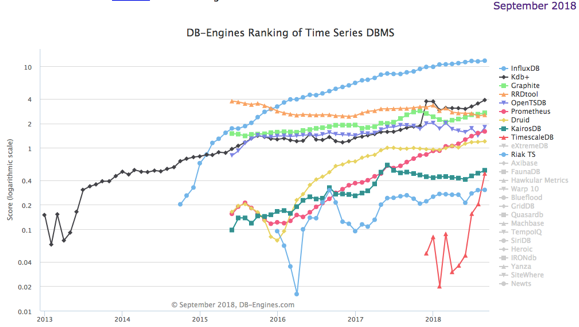
时序数据库发展现状
目前,DB-Engines把时间序列数据库作为独立的目录来分类统计,下图就是2018年业内流行的时序数据库的关注度排名和最近5年的变化趋势。
业界典型时序数据库解析
近2年来时序数据库正处于高速发展的阶段。国内外云市场各大主流厂商已经从整个时序生态的不同角度切入,形成各自特色的解决方案完成布局,开始抢占流量。
而以Facebook Gorilla为代表的优秀的时序数据库则是脱胎于满足自身业务发展的需要。学术上,在时序领域里面更是涌现了一大批黑科技,把时序数据的技术深度推向更高的台阶。
阿里巴巴的TSDB团队自2016年第一版时序数据库落地后,逐步服务于DBPaaS,Sunfire等等集团业务,在2017年中旬公测后,于2018年3月底正式商业化。
在此过程中,TSDB在技术方面不断吸纳时序领域各家之长,开启了自研的时序数据库发展之路。
这个系列文章带领读者一起欣赏下当前时序领域的技术风景。
作者: 焦先
原文链接
本文为云栖社区原创内容,未经允许不得转载。

