在上一篇中,我们介绍了了用TensorflowJS构建一个神经网络,然后用该模型来进行手写MINST数据的识别。和之前的基本模型比起来,模型的准确率上升的似乎不是很大。(在我的例子中,验证部分比较简单,只是一个大致的统计)甚至有些情况下,如果参数选择不当,训练效果还会更差。
卷积网络,也叫做卷积神经网络(con-volutional neural network, CNN),是一种专门用来处理具有类似网格结构的数据的神经网络。例如时间序列数据(可以认为是在时间轴上有规律地采样形成的一维网格)和图像数据(可以看作是二维的像素网格)。对于MINST手写数据来说,应用卷积网络会不会是更好的选择呢?
先上图:
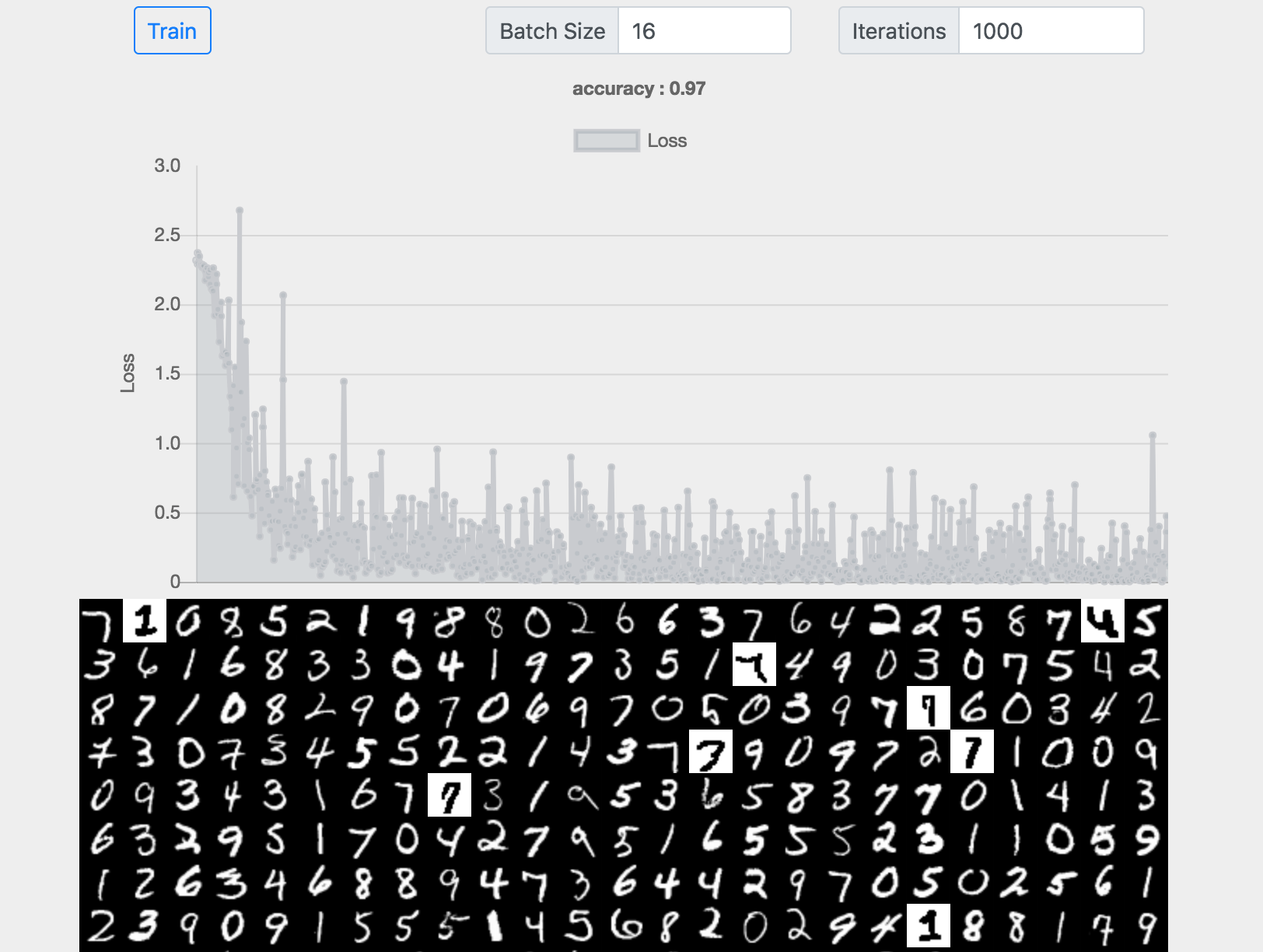
代码见Codepen
该图是我应用CNN对MINST数据进行训练的结果,准确率在97%,可以说和之前的模型来比较,提高显著。要知道,要知道在获得比较高的准确率后,要提高一点都是比较困难的。那我们就简单的看看卷积网络是什么,他为什么对于手写数据的识别做的比其他模型的更好?
CNN的原理实际上是模拟了人类的视觉神经如何识别图像。每个视觉神经只负责处理不同大小的一小块画面,在不同的神经层次处理不同的信息。
卷积和核
大家可能有用过Photoshop的经验,Photoshop提供很多不同类型的滤镜来处理图像,其实那个本质上就是应用不同的核函数对图像进行卷积的结果。
卷积操作如下图所示:
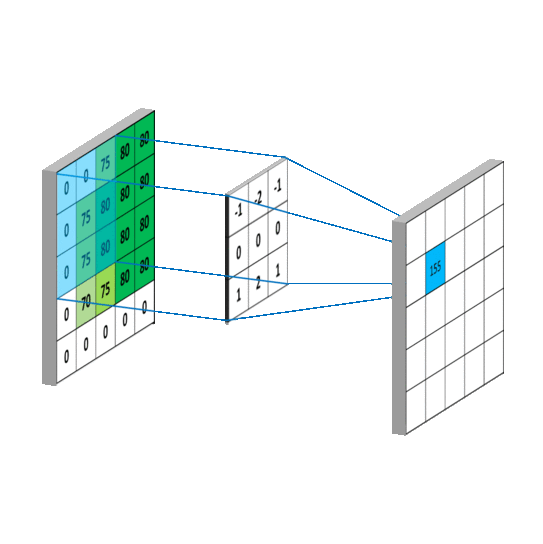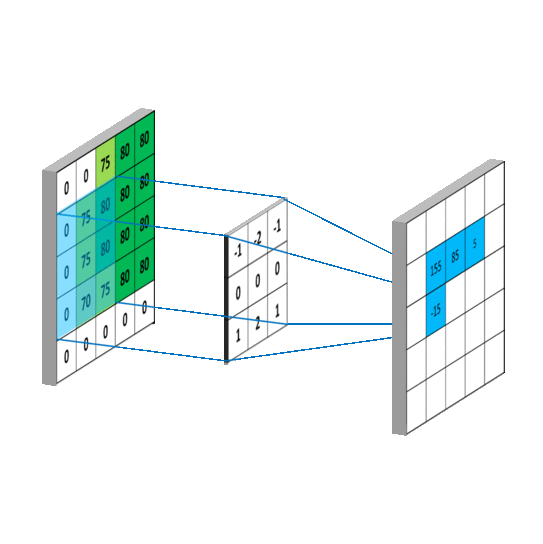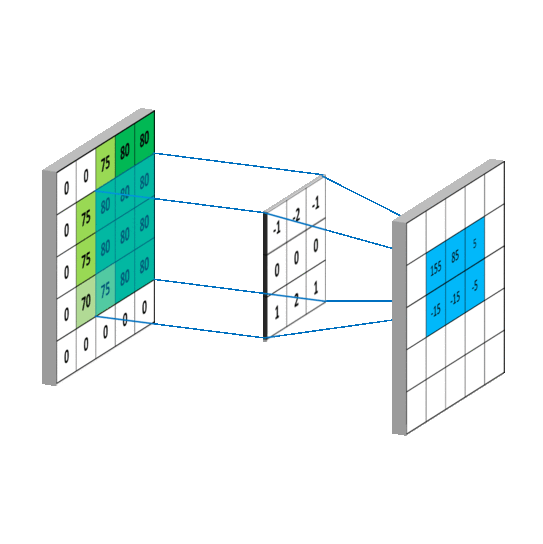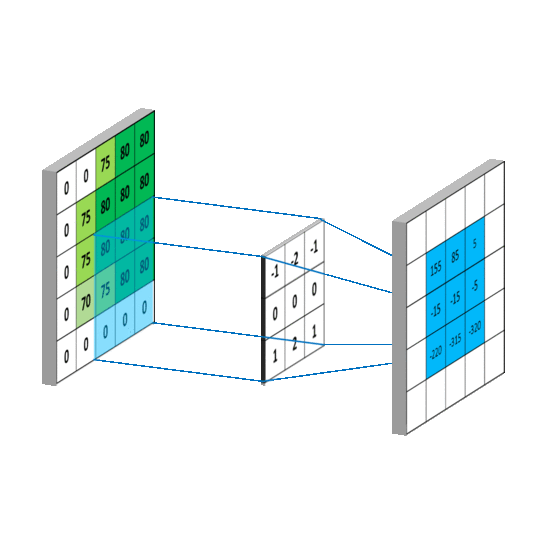
左边的矩形是输入数据,也就是我们要处理的图像的张量表示。中间的矩形是核,而右边的矩形就是卷积的结果。核函数从左至右,从上到下,每次移动一个像素扫描图像,计算出卷积和的结果矩阵。
卷积的计算过程如下图:
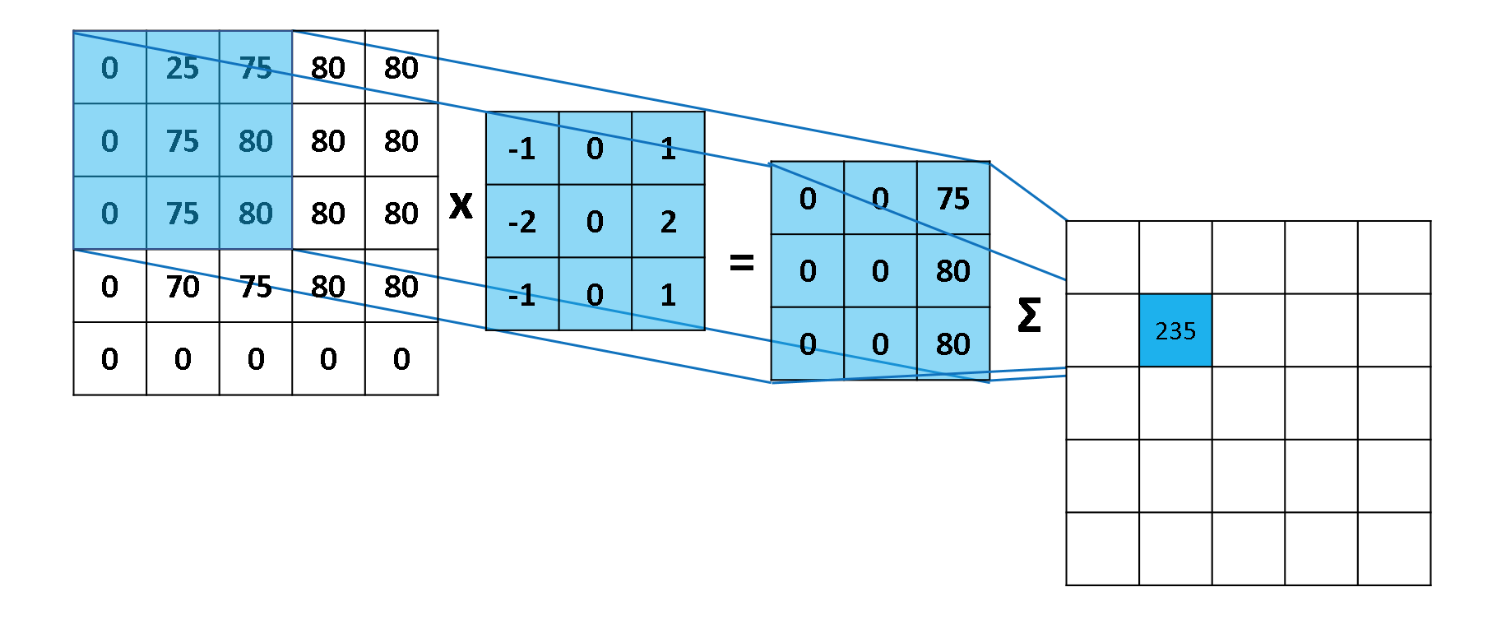
计算就是乘法和加法,但是上图的例子计算有个错误,看你找不找得到。下面这个图计算更简单一点:
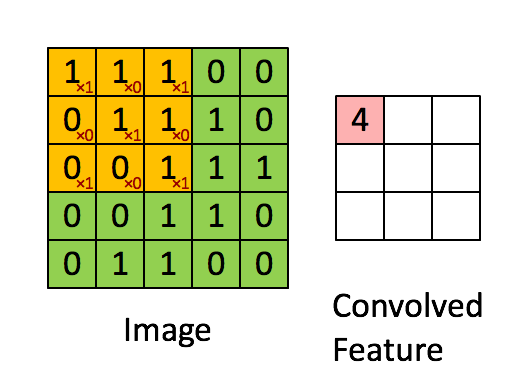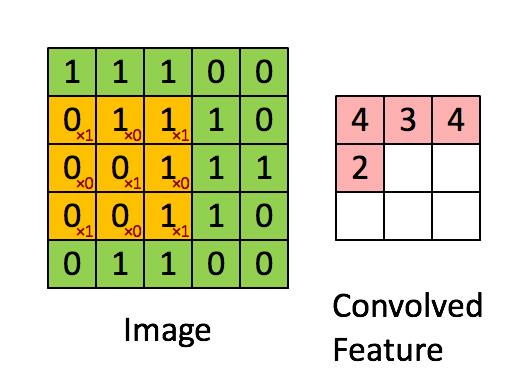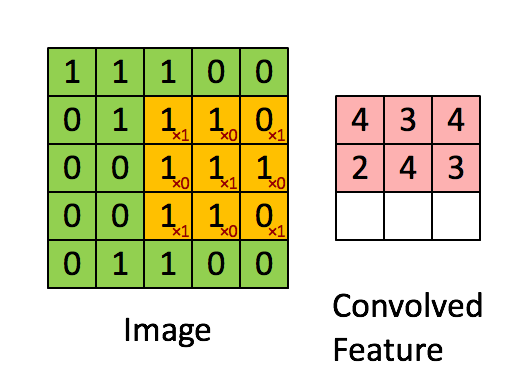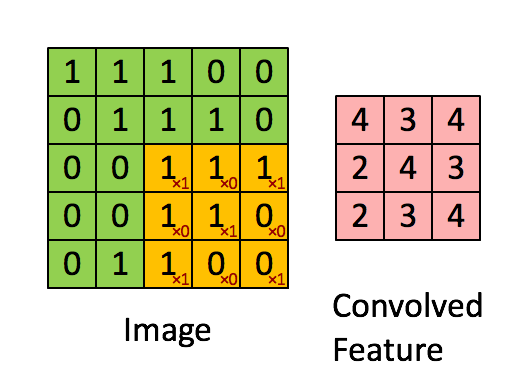
如果你能够理解上图的数学含义你就能理解,核函数其实是一个权重,对于每一个小块的图像,不同的核对不同区域的权重不一样。
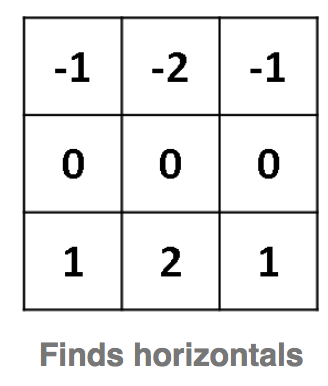
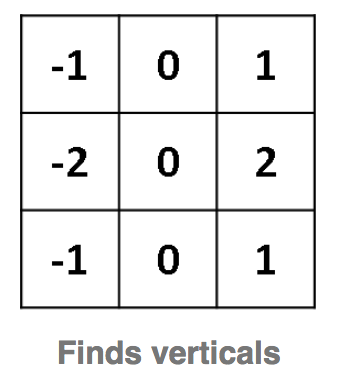
如上图的两个核,左面的对于图像中间的权重为0,上面的是负向加权,而下面的正向加权。可以想像对应于普通图像,数据分布均匀,这个加权计算的结果趋近于零,对应于水平边缘,上面没有数据而下面有数据,这个加权的值就比较大,这样我们就能够检测出水平边缘。同理右边核函数对应垂直边缘。

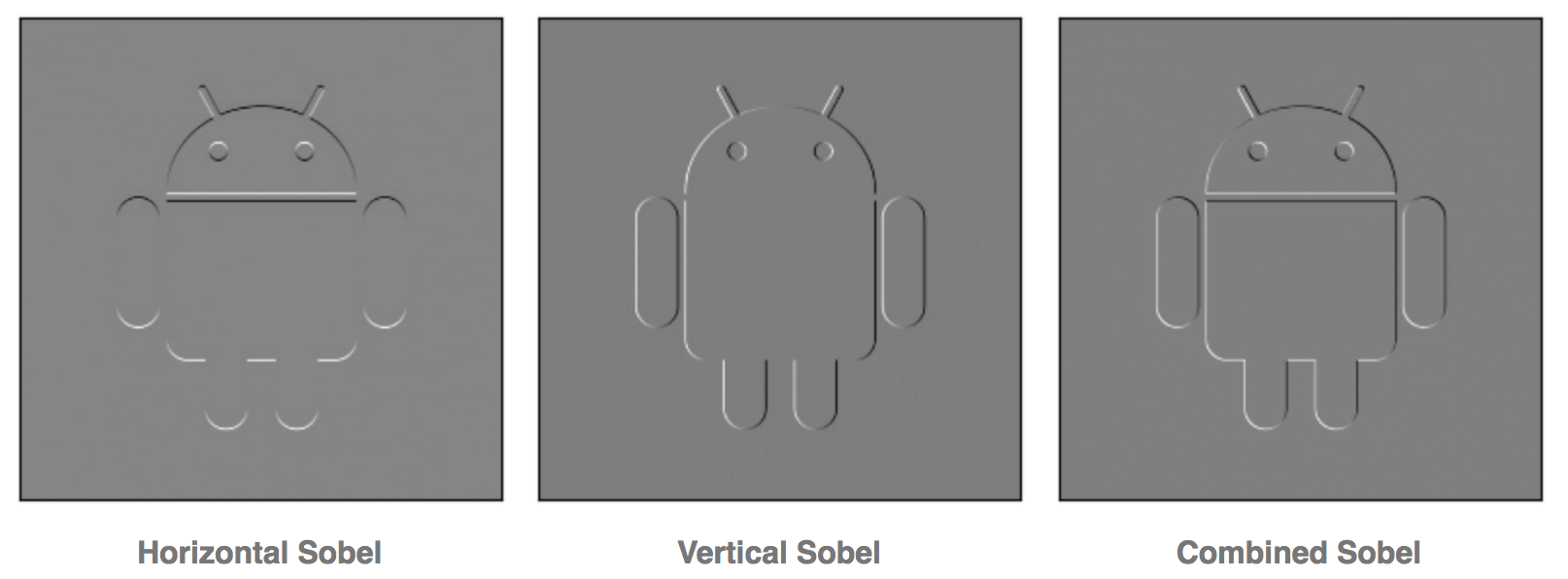
上图就是应用垂直,水平,垂直加水平的核,对安卓小机器人图像卷积的结果。我们可以看出对应的核函数是如何识别出边缘的。
然而在学习的时候要使用什么样的核呢?我们看一下网络结构:
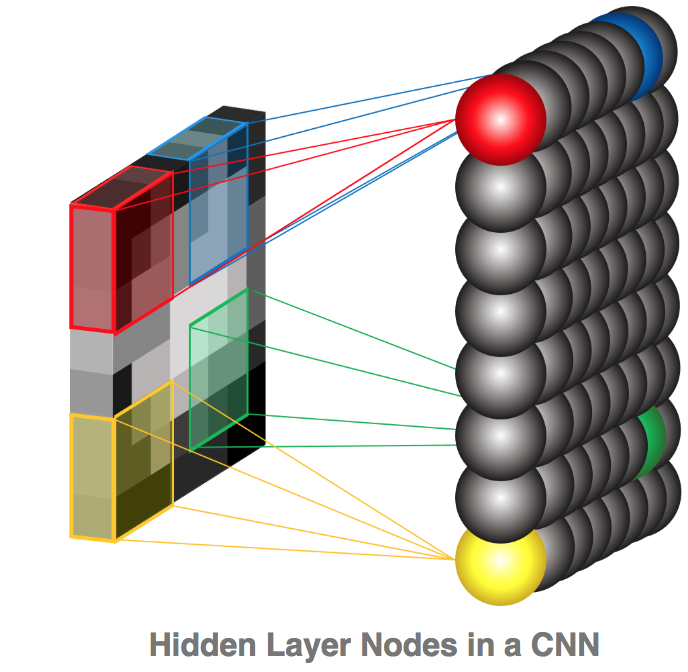
每一个像素都是一个特征,每一个特征是一个输入节点。每一个卷积的结果都输入到下一层的隐藏节点。核的权重就连接了输入层和隐藏层。经过0填充的输入层可以输出不同形状的卷积结果。同时可以调整扫描的步幅(stride)。

上图中,输入为7*7,没有填充,步幅为1,输出为5*5

上图中,输入为5*5,填充1格,步幅为1,输出为5*5
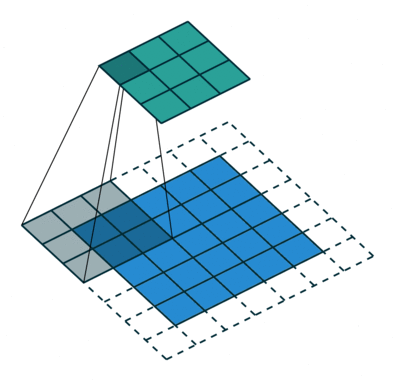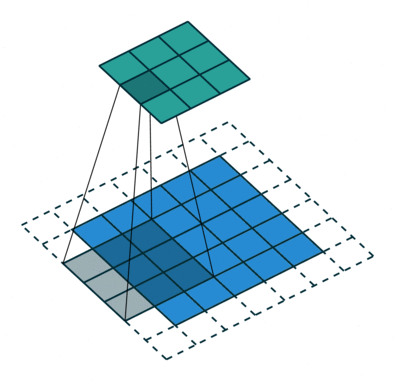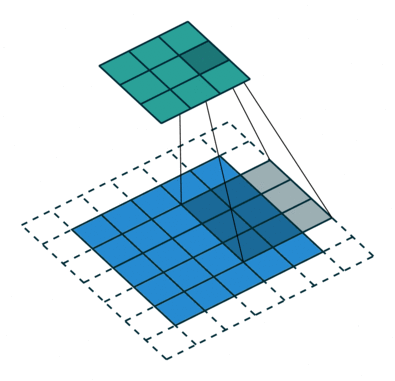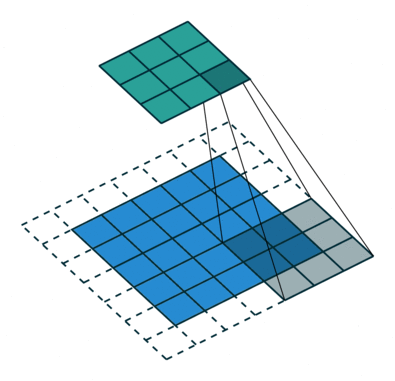
上图中,输入为5*5,填充1格,步幅为2,输出为3*3

上图中,输入为2*2,填充2格,步幅为1,输出为4*4
我们可以看出来,增加填充会导致隐藏层节点数量增加,而增大步幅可以使得隐藏层的节点变少。
通过神经网络的学习,就能够确定核的权重。实际的应用,可能会有多个核,因为有许多的特征要学习。
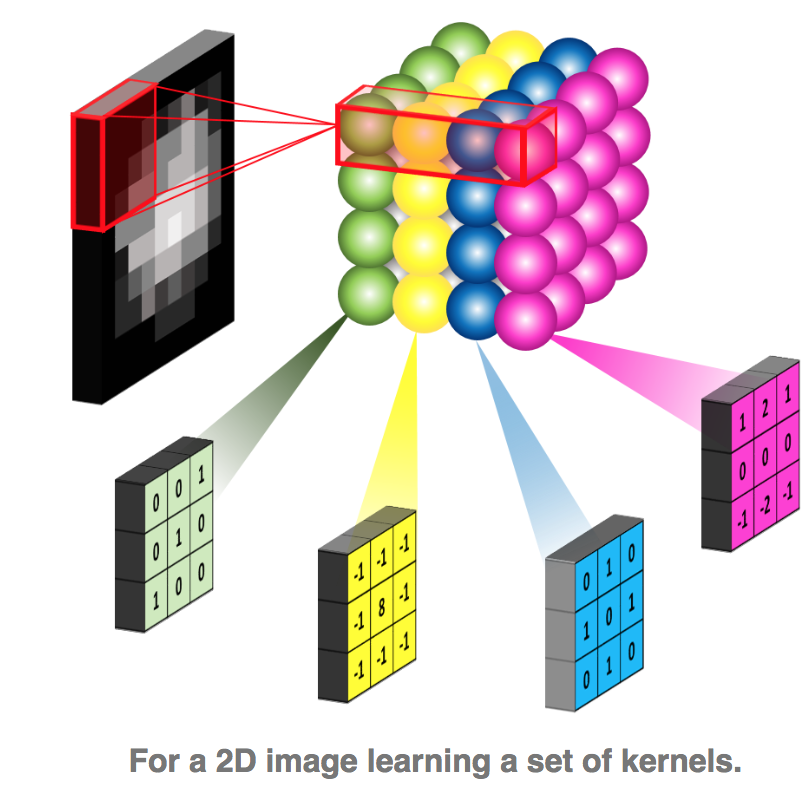
就像我们之前看到如果要学习图像的轮廓,其实是两个不同的核的组合。
池化
池化层通常是紧跟着卷积的一层,通常是做区域的均值或者最大值操作。如下图:
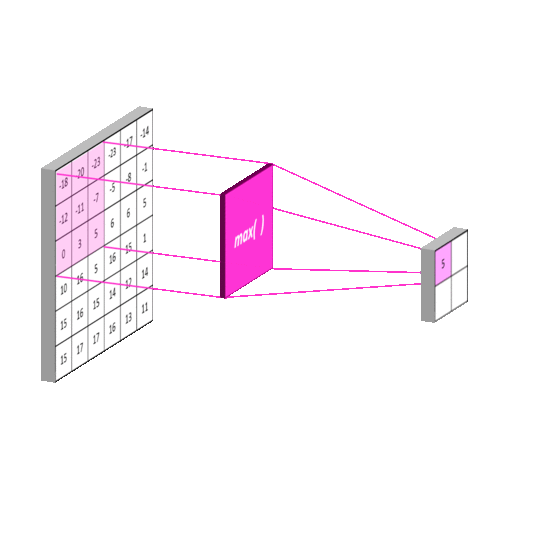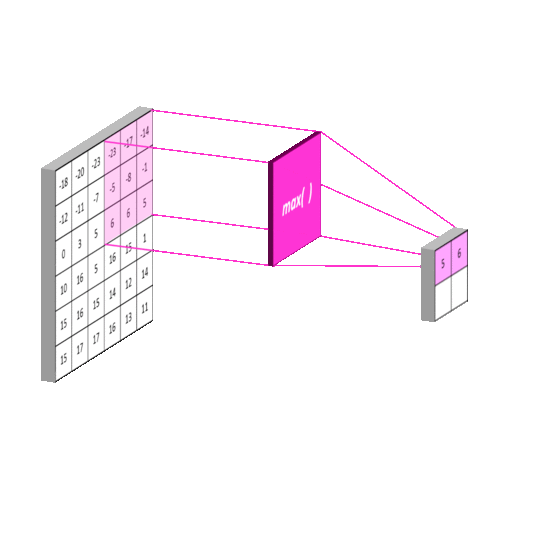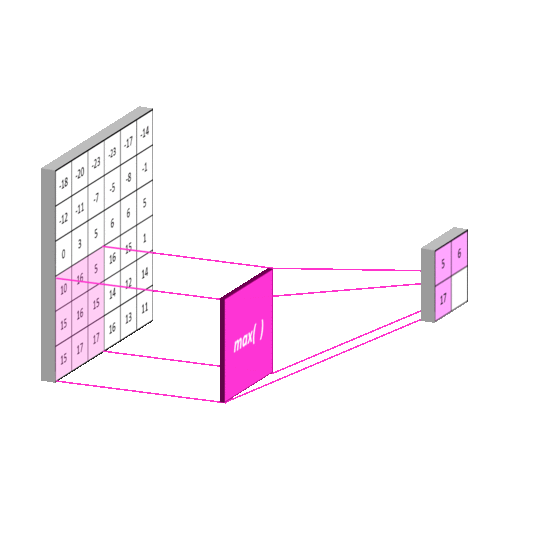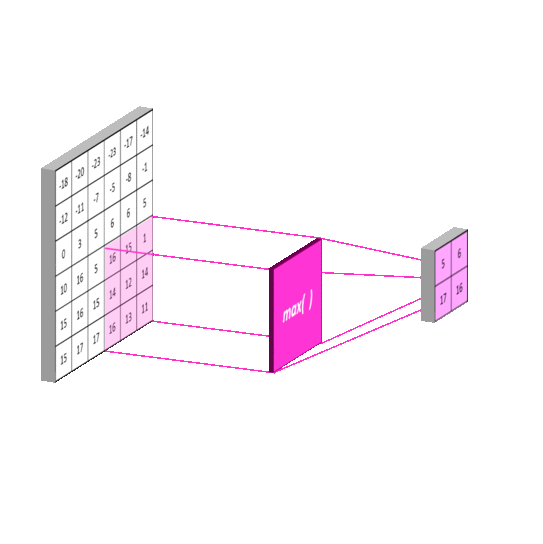
如下图,池化的策略通常是取最大值或者取均值。
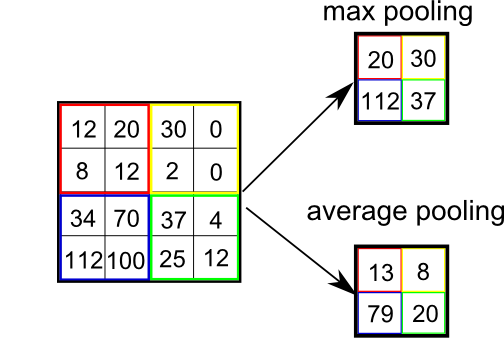
池化的作用类似取样,使得下一层神经网络要处理的数据极大的缩小。减少整个网络的参数,防止出现过拟合。
整体结构
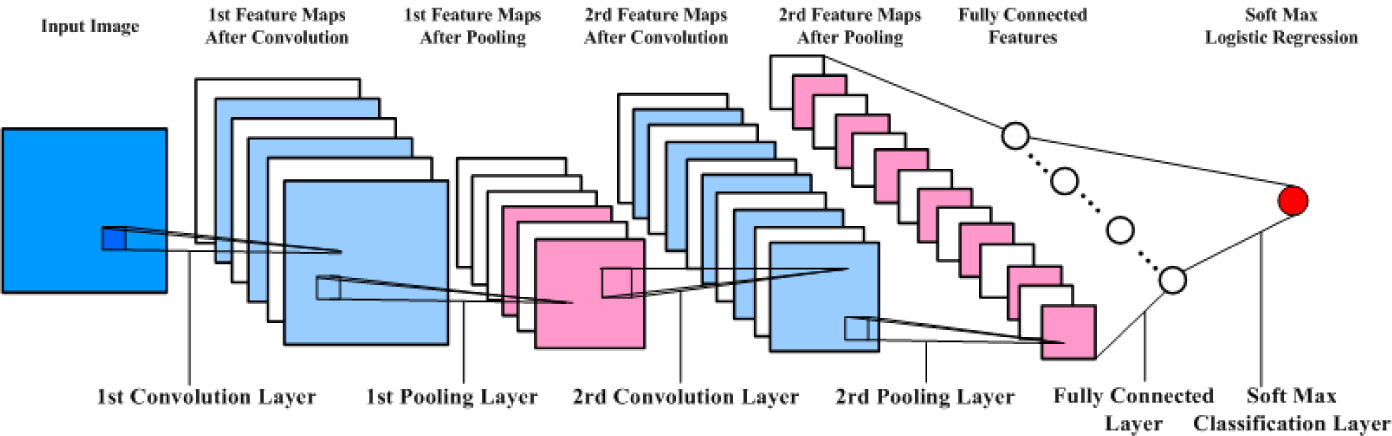
通常,CNN网络的由如上图所示的层次构成:
- 输入层 Input Layer
- 卷积层 Convolution Layer
- 池化层 Pooling Layer
- 全连接层 Fully Connected (Dense) Layer
- 分类层 Softmax Classification Layer
- 输出层 Output Layer
在了解的基本的卷积网络的概念后,我们来看看如何在TensorflowJS中实现一个CNN。
下面是模型的代码:
function cnn() { const model = tf.sequential(); model.add(tf.layers.conv2d({ inputShape: [28, 28, 1], kernelSize: 5, filters: 8, strides: 1, activation: 'relu', kernelInitializer: 'varianceScaling' })); model.add(tf.layers.maxPooling2d({poolSize: [2, 2], strides: [2, 2]})); model.add(tf.layers.conv2d({ kernelSize: 5, filters: 16, strides: 1, activation: 'relu', kernelInitializer: 'varianceScaling' })); model.add(tf.layers.maxPooling2d({poolSize: [2, 2], strides: [2, 2]})); model.add(tf.layers.flatten()); model.add(tf.layers.dense( {units: 10, kernelInitializer: 'varianceScaling', activation: 'softmax'})); return model; }
-
tf.sequential() 创建一个连续的神经网络,自动创建输入层
-
tf.layers.conv2d 是第一层的卷积层,输入28*28*1是图像的长,高,颜色通道。核的大小是5*5,步幅是1。我们先忽略其它参数。
-
tf.layers.maxPooling2d是下一个池化层,就是以2*2的小窗口对卷积结果做池化。
-
接着又是一个卷积和一个池化层。
-
tf.layers.flatten() 是把之前的结果打平。
-
最后是一个softmax分类层 tf.layers.dense
类似这样一个结构
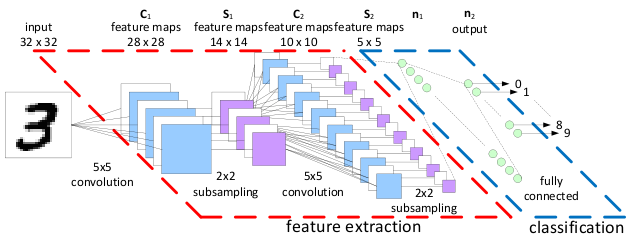
训练的代码如下:
const model = cnn(); const LEARNING_RATE = 0.15; const optimizer = tf.train.sgd(LEARNING_RATE); model.compile({ optimizer: optimizer, loss: 'categoricalCrossentropy', metrics: ['accuracy'], }); async function train() { const BATCH_SIZE = 16; const TRAIN_BATCHES = 1000; const TEST_BATCH_SIZE = 100; const TEST_ITERATION_FREQUENCY = 5; for (let i = 0; i < TRAIN_BATCHES; i++) { const batch = data.nextTrainBatch(BATCH_SIZE); let testBatch; let validationData; // Every few batches test the accuracy of the mode. if (i % TEST_ITERATION_FREQUENCY === 0 && i > 0 ) { testBatch = data.nextTestBatch(TEST_BATCH_SIZE); validationData = [ testBatch.xs.reshape([TEST_BATCH_SIZE, 28, 28, 1]), testBatch.labels ]; } // The entire dataset doesn't fit into memory so we call fit repeatedly // with batches. const history = await model.fit( batch.xs.reshape([BATCH_SIZE, 28, 28, 1]), batch.labels, {batchSize: BATCH_SIZE, validationData, epochs: 1}); const loss = history.history.loss[0]; const accuracy = history.history.acc[0]; batch.xs.dispose(); batch.labels.dispose(); if (testBatch != null) { testBatch.xs.dispose(); testBatch.labels.dispose(); } await tf.nextFrame(); } }
如果和之前的神经网络的训练的代码比较,这里唯一的变化就是输入数据的形状。
// For CNN batch.xs.reshape([BATCH_SIZE, 28, 28, 1]) // For NN batch.xs.reshape([BATCH_SIZE, 784])
这是由两个网络输入层的形状来决定的。
大家在选取模型的时候可以考虑CNN的优缺点。
优点:
- 共享卷积核,对高维数据处理无压力
- 无需手动选取特征,训练好权重,即得特征
- 分类效果好
缺点:
- 需要调参,需要大样本量,训练最好要用GPU
- 物理含义不明确,随着 Convolution 的堆叠,Feature Map 变得越来越抽象,人类已经很难去理解了
CNN是非常流行的深度学习的模型,广泛用于图像相关的有关领域,从阿尔法狗到自动驾驶,到处都有他的身影。如果大家希望进一步了解,可以研习下面的文章。
参考

