1、Spark简介
Apache Spark 是专为大规模数据处理而设计的快速通用的计算引擎。Spark是UC Berkeley AMP lab (加州大学伯克利分校的AMP实验室)所开源的类Hadoop MapReduce的通用并行框架,Spark,拥有Hadoop MapReduce所具有的优点;但不同于MapReduce的是——Job中间输出结果可以保存在内存中,从而不再需要读写HDFS,因此Spark能更好地适用于数据挖掘与机器学习等需要迭代的MapReduce的算法。
Spark 是一种与 Hadoop 相似的开源集群计算环境,但是两者之间还存在一些不同之处,这些有用的不同之处使 Spark 在某些工作负载方面表现得更加优越,换句话说,Spark 启用了内存分布数据集,除了能够提供交互式查询外,它还可以优化迭代工作负载。
Spark 是在 Scala 语言中实现的,它将 Scala 用作其应用程序框架。与 Hadoop 不同,Spark 和 Scala 能够紧密集成,其中的 Scala 可以像操作本地集合对象一样轻松地操作分布式数据集。
尽管创建 Spark 是为了支持分布式数据集上的迭代作业,但是实际上它是对 Hadoop 的补充,可以在 Hadoop 文件系统中并行运行。通过名为 Mesos 的第三方集群框架可以支持此行为。Spark 由加州大学伯克利分校 AMP 实验室 (Algorithms, Machines, and People Lab) 开发,可用来构建大型的、低延迟的数据分析应用程序。
2、部署准备
2.1、安装包准备
2.2、节点配置信息
| IP地址 | 主机名 |
| 192.168.23.1 | risen01 |
| 192.168.23.2 | risen02 |
| 192.168.23.3 | risen03 |
2.3、节点资源配置信息
| IP地址 | 角色 |
| 192.168.23.1 | master,worker |
| 192.168.23.2 | HA-Master,worker |
| 192.168.23.3 | worker |
3、集群配置与启动
3.1、安装包上传与解压
操作节点:risen01
操作用户:root
1. 上传安装包spark-2.2.0-bin-hadoop2.6.tgz,scala-2.11.0.tgz,jdk-8u161-linux-x64.tar.gz(如果已经存在则不需要此步骤)到 risen01节点下的~/packages目录下,结果如图所示:
2. 解压JDK安装包,Spark安装包Scala安装包和到/usr/local下
操作节点:risen01
操作用户:root
解压JDK命令:
tar -zxvf ~/packeages/jdk-8u161-linux-x64.tar.gz -C /usr/local
解压spark命令:
tar -zxvf ~/packages/spark-2.2.0-bin-hadoop2.6.tgz -C /usr/local
解压Scala命令:
tar -zxvf ~/packages/scala-2.11.0.tgz -C /usr/local
3.2、启动前准备
操作节点:risen01,risen02,risen03
操作用户:root
1. 在/data目录下新建立spark/work目录用来存放spark的任务处理日志
2. 在/log目录下新建立spark目录用来存放spark的启动日志等
3.3、修改配置文件
3.3.1、编辑spark-env.sh文件
操作节点:risen01
操作用户:root
说明:请根据实际集群的规模和硬件条件来配置每一项参数
进入到/usr/local/spark-2.2.0-bin-hadoop2.6/conf目录下执行命令:
cp spark-env.sh.template spark-env.sh
编辑spark-env.sh文件,添加以下内容:
#设置spark的web访问端口 SPARK_MASTER_WEBUI_PORT=18080 #设置spark的任务处理日志存放目录 SPARK_WORKER_DIR=/data/spark/work #设置spark每个worker上面的核数 SPARK_WORKER_CORES=2 #设置spark每个worker的内存 SPARK_WORKER_MEMORY=1g #设置spark的启动日志等目录 SPARK_LOG_DIR=/log/spark #指定spark需要的JDK目录 export JAVA_HOME=/usr/local/jdk1.8.0_161 #指定spark需要的Scala目录 export SCALA_HOME=/usr/local/scala-2.11.0 #指定Hadoop的安装目录 export HADOOP_HOME=/opt/cloudera/parcels/CDH/lib/hadoop #指定Hadoop的配置目录 export HADOOP_CONF_DIR=/opt/cloudera/parcels/CDH/lib/hadoop/etc/hadoop/ #实现spark-standlone HA(因为我们HA实现的是risen01和risen02之间的切换不涉及risen03,所以这段配置risen03可有可无) export SPARK_DAEMON_JAVA_OPTS="-Dspark.deploy.recoveryMode=ZOOKEEPER -Dspark.deploy.zookeeper.url=risen01:2181,risen02:2181,risen03:2181 -Dspark.deploy.zookeeper.dir=/data/spark"
3.3.2、 编辑spark-defaults.conf文件
操作节点:risen01
操作用户:root
说明:请根据实际集群的规模和硬件条件来配置每一项参数
进入到/usr/local/spark-2.2.0-bin-hadoop2.6/conf目录下执行命令:
cp spark-defaults.conf.template spark-defaults.conf
编辑spark-defaults.conf文件,添加以下内容:
#设置spark的主节点 spark.master spark://risen01:7077 #开启eventLog spark.eventLog.enabled true #设置eventLog存储目录 spark.eventLog.dir /log/spark/eventLog #设置spark序列化方式 spark.serializer org.apache.spark.serializer.KryoSerializer #设置spark的driver内存 spark.driver.memory 1g #设置spark的心跳检测时间间隔 spark.executor.heartbeatInterval 20s #默认并行数 spark.default.parallelism 20 #最大网络延时 spark.network.timeout 3000s
3.3.3、 编辑slaves文件
操作节点:risen01
操作用户:root
说明:请根据实际集群的规模和硬件条件来配置每一项参数
进入到/usr/local/spark-2.2.0-bin-hadoop2.6/conf目录下执行命令:
cp slaves.templete slaves
编辑slaves文件,修改localhost为:
risen01 risen02 risen03
3.4、分发其他节点
1. 执行scp命令:
操作节点:risen01
操作用户:root
scp -r /usr/local/spark-2.2.0-bin-hadoop2.6 root@risen02:/usr/local scp -r /usr/local/scala-2.11.0 root@risen02:/usr/local scp -r /usr/local/jdk1.8.0_161 root@risen02:/usr/local scp -r /usr/local/spark-2.2.0-bin-hadoop2.6 root@risen03:/usr/local scp -r /usr/local/scala-2.11.0 root@risen03:/usr/local scp -r /usr/local/jdk1.8.0_161 root@risen03:/usr/local
2. 需要提前创建好bigdata用户并实现免密(这里不再赘述,此步骤如果做过可不做)
3. 权限修改
操作节点:risen01,risen02,risen03
操作用户:root
修改/log/spark权限命令:
chown -R bigdata.bigdata /log/spark
修改/data/spark权限命令:
chown -R bigdata.bigdata /data/spark
修改spark的安装目录命令:
chown -R bigdata.bigdata /usr/local/spark-2.2.0-bin-hadoop2.6
修改Scala的安装目录命令:
chown -R bigdata.bigdata /usr/local/scala-2.11.0
修改JDK1.8的安装目录命令:(此步骤如果做过可不做)
chown -R bigdata.bigdata /usr/local/jdk1.8.0_161
结果如图下所示:
3.5、启动集群
操作节点:risen01,risen02
操作用户:bigdata
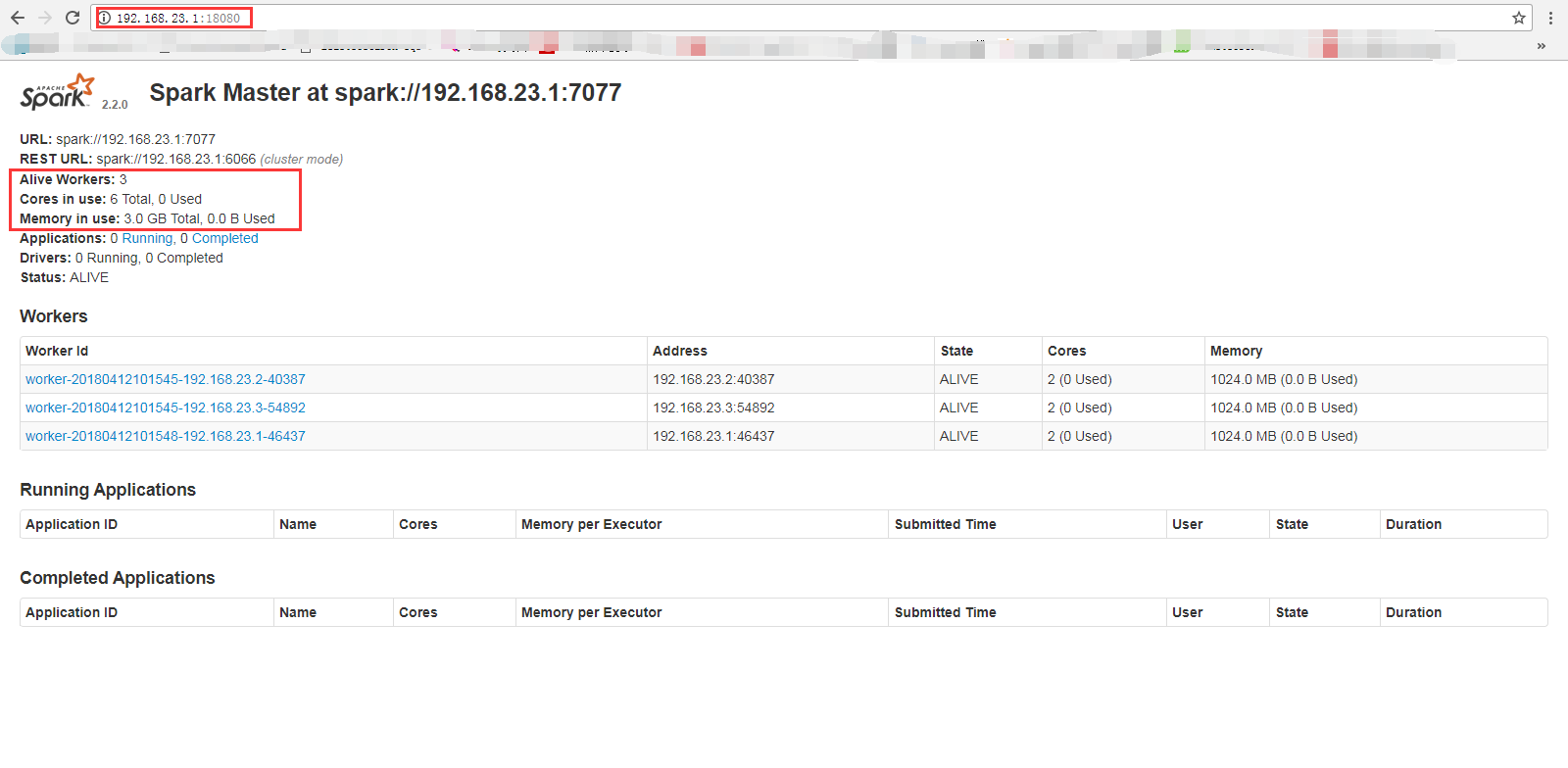
(1) 进入到/usr/local/spark-2.2.0-bin-hadoop2.6/sbin目录下执行./start-all.sh,查看web界面如下图所示:
然后在进入到risen02机器的spark安装目录下/usr/local/spark-2.2.0-bin-hadoop2.6/sbin执行命令./start-master.sh启动spark集群的备用主节点。(记得一定要启动备用主节点的进程,这里我们只用risen02做备用主节点,risen03虽然也配置了有资格,但是暂时我们不需要)
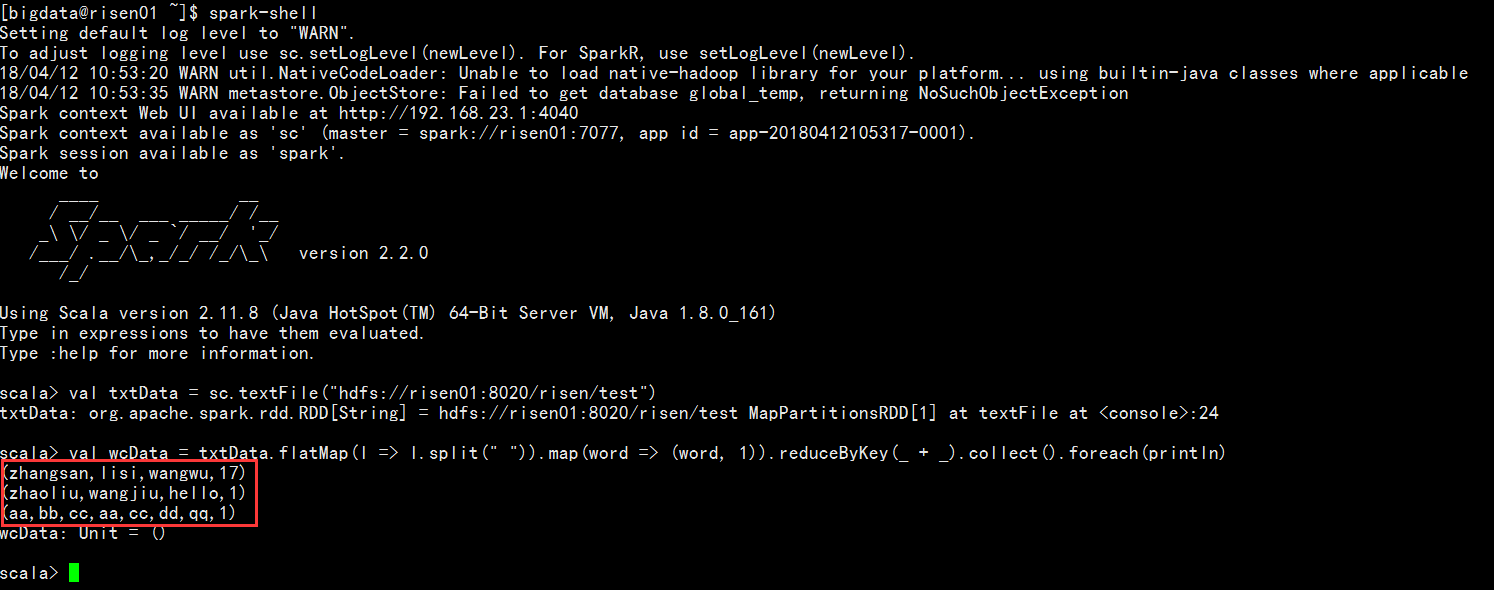
(2) 进入到/usr/local/spark-2.2.0-bin-hadoop2.6/bin目录下执行spark-shell,并测试统计词频的测试,结果如下图所示:
截止到此,spark-standlone模式便安装成功了!

