在本系列上一篇文章中,介绍了故障和恢复,下面是本系列剩下的文章将要讨论的主题:
- Ignite持久化的事务处理(WAL、检查点及其他)
- 第三方持久化的事务处理
在本文中,会聚焦于Ignite持久化的事务处理。
将Apache Ignite作为内存数据网格(IMDG)的都知道,如果整个集群瘫痪,仅仅将数据保存在内存中问题是很严重的,其他的IMDG以及缓存技术也会面临同样的问题。解决这个问题的方案之一就是,将Ignite与第三方的持久化存储集成,然后提供通读和通写能力,如图1所示: 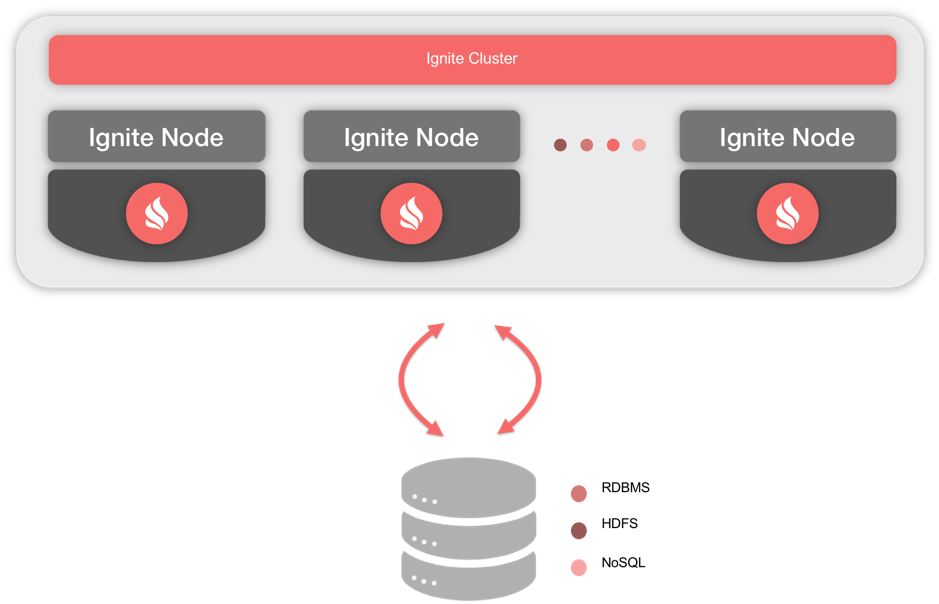
但是,这个方法有一些缺陷,在本系列的下一篇文章中会说明。
作为第三方持久化的替代方案,Ignite开发了一个固化内存架构,如图2所示,该架构可以同时在内存和磁盘上进行数据和索引的存储和处理,该特性使用非常简单,使得Ignite集群在数据落盘的前提下,获得内存级的性能: 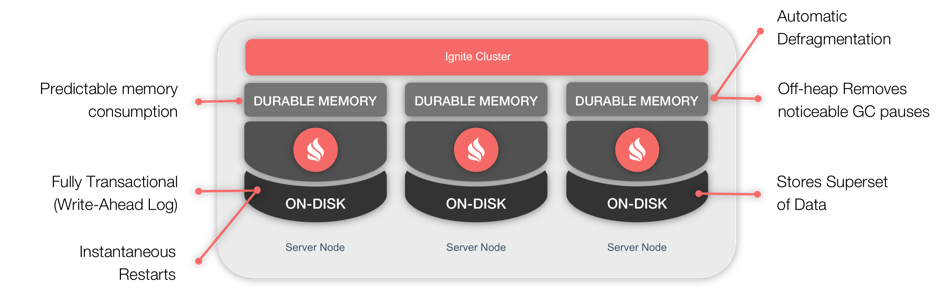
固化内存的工作方式类似于现代操作系统中常见的虚拟内存,但是关键的不同点在于,如果开启了Ignite持久化,固化内存会将所有的数据集和索引保存在磁盘上,而虚拟内存只是将磁盘用于交换。
在图2中还可以看到固化内存架构的若干功能亮点,在内存部分,优势包括【1】:
- 堆外:所有的数据和索引都存储于Java堆外,这有助于处理大量的集群数据;
- 消除了明显的垃圾回收导致的暂停:通过将所有的数据和索引保存在堆外,只有应用代码才能因为垃圾回收而导致暂停;
- 可预测的内存使用:内存使用量完全可配置以满足特定应用的需求;
- 内存碎片自动整理:Ignite通过执行碎片整理过程来避免内存碎片,这个过程是和数据的访问同步进行的;
- 内存占用和性能的优化:Ignite在内存和磁盘上,对数据和索引使用同样的格式,避免了不必要的数据格式转换;
而对于原生的持久化,优势包括:
- 可选的持久化:数据存储易于配置(内存,内存+磁盘),或者内存作为磁盘的缓存层;
- 数据恢复:原生持久化保存了完整的数据集,不用担心集群的崩溃以及重启,不会丢失任何数据,并且仍然提供了强事务一致性;
- 在内存中缓存热数据:固化内存可以在内存中保存热数据,并在内存空间减少时自动清除内存中的冷数据;
- 在数据中执行SQL:Ignite可以作为一个全功能的分布式SQL数据库;
- 快速集群重启:如果集群故障,Ignite可以重启然后快速进入工作状态;
此外,持久化存储兼容ACID,可以将数据和索引存储在闪存、SSD、Intel 3D XPoint以及其他的非易失性存储中,不管是否使用持久化,每个节点都只会管理整体数据的一个子集。
Ignite通过两个机制来管理持久化以及提供事务和一致性保证,下面会分别介绍这两个机制:预写日志(WAL)和检查点,先从WAL开始。
预写日志(WAL)
开启Ignite持久化之后,对于节点上的每个分区,Ignite会维护一个专用的分区文件。当内存中的数据更新之后,更新不是直接写入对应的分区文件的,而是附加到预写日志(WAL)的末尾。使用WAL与直接更新相比,会有一个显著地性能提升,此外,WAL在集群或者节点故障时,还提供了一个恢复机制。
WAL被拆分为若干个文件,叫做段。这些段是按照顺序填充的。默认会创建10个段,但是这个数值是可配置的。这些段文件的使用方式是,当第一个段满了之后,它会被复制到WAL归档文件,该文件会保持一段可配置的时间,在数据从第一个段复制到归档文件的过程中,第二个段就会处于激活状态,对于每个段文件,这个过程会循环执行。
WAL根据不同的一致性保证会有不同的操作模式,范围从没有数据丢失的强一致性到没有一致性,可能存在潜在的数据丢失都有。
就像之前提到过的,每个更新首先都会被添加到WAL,每个更新都会通过缓存ID和条目键唯一标识,因此,当故障或者重启时,集群总是能恢复到最近的成功提交的事务或者原子更新。
WAL同时存放了逻辑和物理记录,逻辑记录描述了事务的行为,结构如下:
- 操作描述(DataRecord):存储了操作类型信息(创建、更新、删除)以及(键、值、版本);
- 事务记录(TxRecord):存储了事务信息(开始准备、准备完毕、提交、回滚);
- 检查点记录(CheckpointRecord):存储了检查点开始信息;
数据记录的结构,如图3所示: 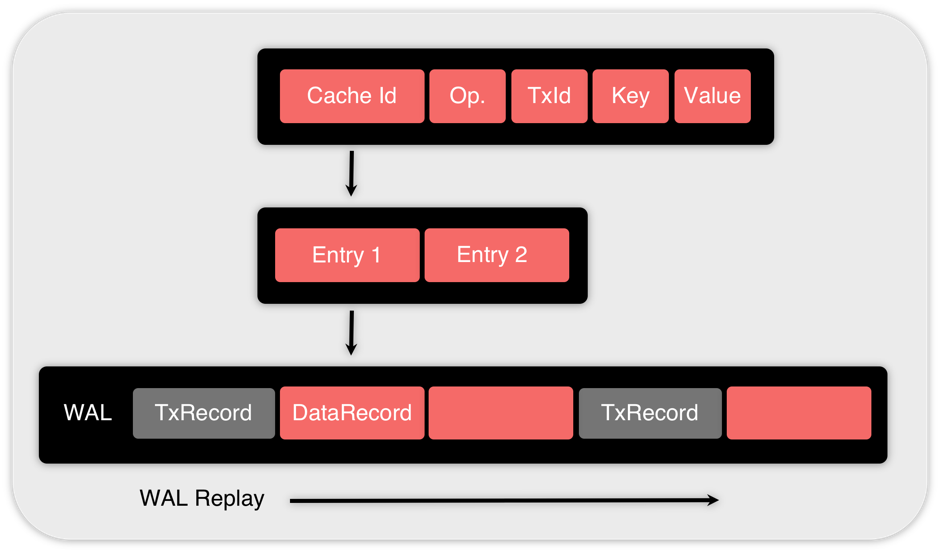
从图3可以看出,数据记录由一组操作条目组成(即Entry 1, Entry 2),每个条目都包括:
操作类型可以是下面中的一个:
- 创建:第一次添加到缓存,包括(键、值);
- 更新:更新已有的数据,包括(键、值);
- 删除:删除数据,包括(键);
如果在一个事务中同一个键更新了若干次,那么这些更新会用最新的值合并成一个更新。
检查点
集群故障时,恢复时间可能很长,因为WAL可能很大。为了解决这个问题,Ignite引入了检查点技术,如果所有的数据无法装入内存必须写入磁盘时,检查点也是必需的,这样所有的数据才是可用的。
记得更新操作追加到WAL的过程吧,但是内存中的已更新(脏)页面仍然需要复制到对应的分区文件,将这些页面从内存复制到分区文件的过程叫做检查点。检查点的好处在于,磁盘上的页面保持是最新的,这样当旧的段被删除时,WAL归档文件就可以压缩了。
图4中,可以看到检查点的工作过程: 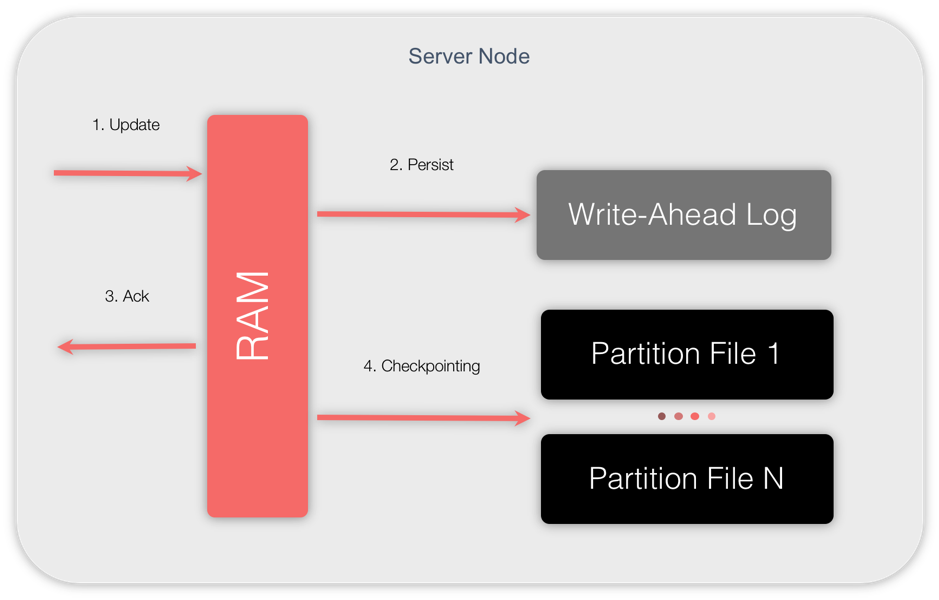
消息流如下:
- 节点收到更新请求(1. Update),该节点会查找要插入或者更新的数据所属的内存数据页面,然后页面被更新并且标记为脏页面;
- 更新被附加到WAL的末尾(2. Persist);
- 节点向更新发起方发送一个确认消息,确认操作成功(3. Ack);
- 检查点周期性地触发(4. Checkpointing),检查点过程的频率是可配置的的。脏页面会从内存复制到磁盘并且传递到特定的分区文件。
如果考虑到事务和检查点,Ignite会使用一个checkpointLock来提供如下的保证:
- 1:开始检查点以及0更新正在执行;
- 0:开始检查点以及N更新正在执行。
检查点的开始不会等待事务结束。这意味着事务可以在检查点之前启动,但是会在检查点过程执行过程中以及结束后提交。
快照
有助于数据恢复的另外一个机制是快照,但是这个特性是GridGain在旗舰版中提供的,它等同于数据库系统中的备份。
总结
Ignite保证了持久化数据管理方面的健壮性。WAL机制保证了在节点或者集群故障时数据恢复的高性能,检查点使得脏页面可以被刷新到磁盘并且使WAL处于可控状态,总之,持久化存储与内存存储保持了同等的事务一致性。

