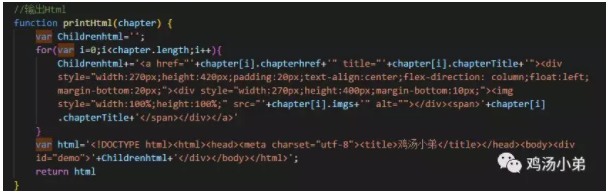
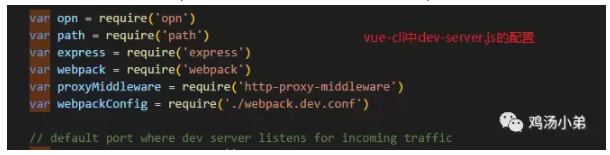
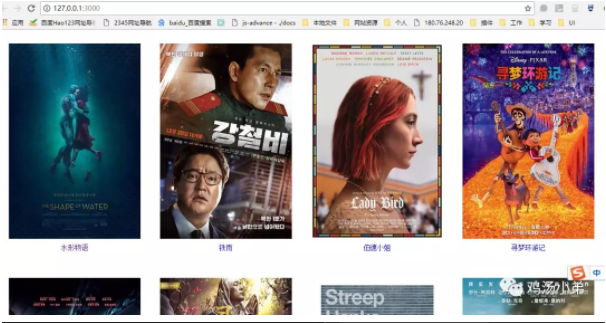
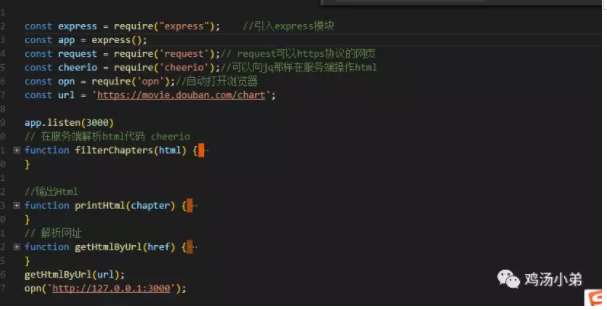


死磕 java集合之ConcurrentSkipListSet源码分析——Set大汇总
Flink中的多source+event watermark测试
避坑!MotionGo就是一款诈骗软件!千万不要用ChatPPT,浪费时间!
宝塔面板使用WWW用户执行计划任务命令 解决laravel日志权限问题 宝塔设置计划任务执行用户
手机微信一键制作透明底文字表情 教你如何让微信表情包背景为透明 自制微信表情包动图 文字表情在线制作
ssh目录权限配置指南 .ssh文件夹及rsa_id.pub等文件正确权限规则
Mac连接亚马逊AWS EC2 远程连接登录不上去 有pem私钥文件依然要输密码 默认密码 教程
PHP工程师必知必会 - Linux系统常用命令 - Linux中的网络管理命令(下)
