Java.util.concurrent 包是专为 Java并发编程而设计的包,它下有很多编写好的工具,使用这些更高等的同步工具来编写代码,让我们的程序可以不费力气就得到优化。
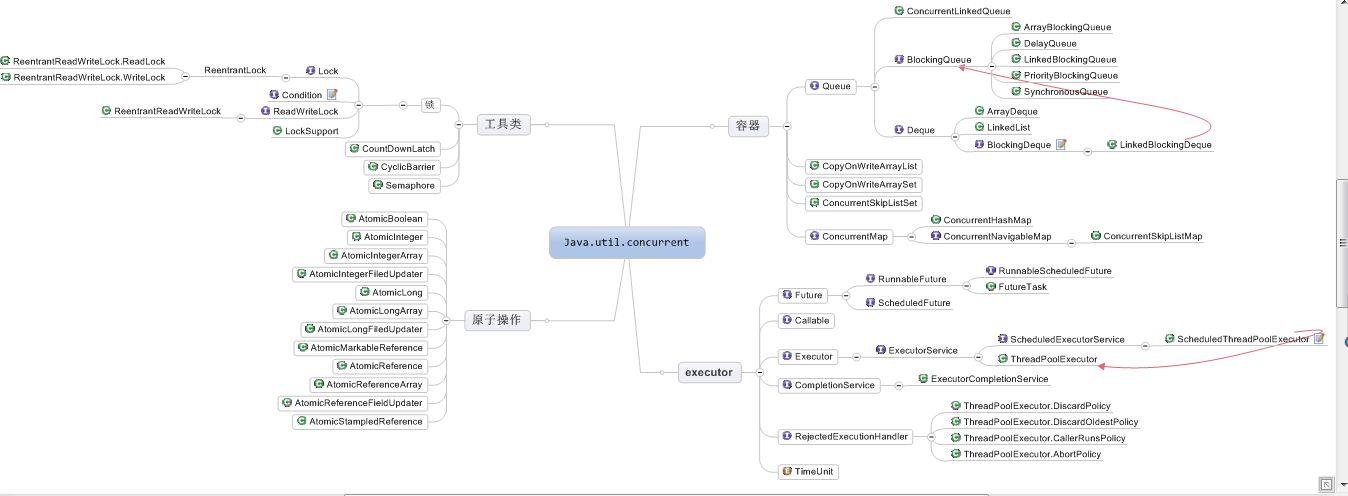
脑图地址,感谢深入浅出 Java Concurrency ,此脑图在这篇基础上修改而来。在这里我们看容器部分:
1.ConcurrentHashMap
2.CopyOnWrite容器
3.并发Queue
1.ConcurrentHashMap
先来说说HashTable(线程安全的HashMap),他们内部采用横向数组,纵向链表的结构来储存数据。横向数组的下标为key的hash值,纵向链表为hash值相同的元素组成的链表:
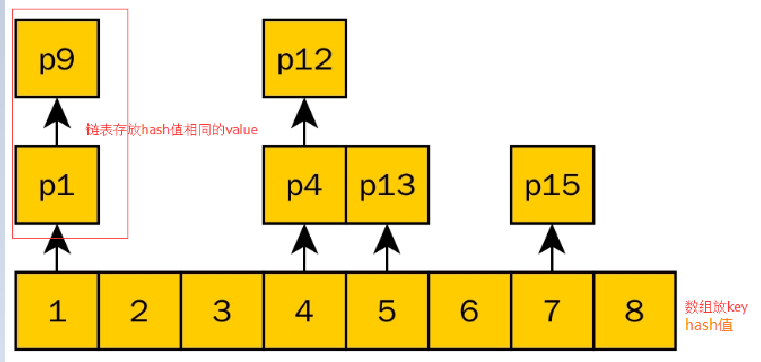
Hashtable容器在竞争激烈的并发情况下,所有访问HashTable的线程都必须使用同一把锁,导致效率低下。假如容器有多把锁,每一把锁用于容器的一部分数据,多线程访问不同数据段时,线程间就不存在锁竞争。这就是ConcurrentHashMap的锁分段技术,它既是线程安全的又支持高并发的HashMap,每一个段就像是一个小的HashTable,它们都有自己的锁。
按默认16个Segment(段)来讲,理论上就允许16个线程并发执行,只要多个修改操作发生在不同的段上,就可以并发进行:
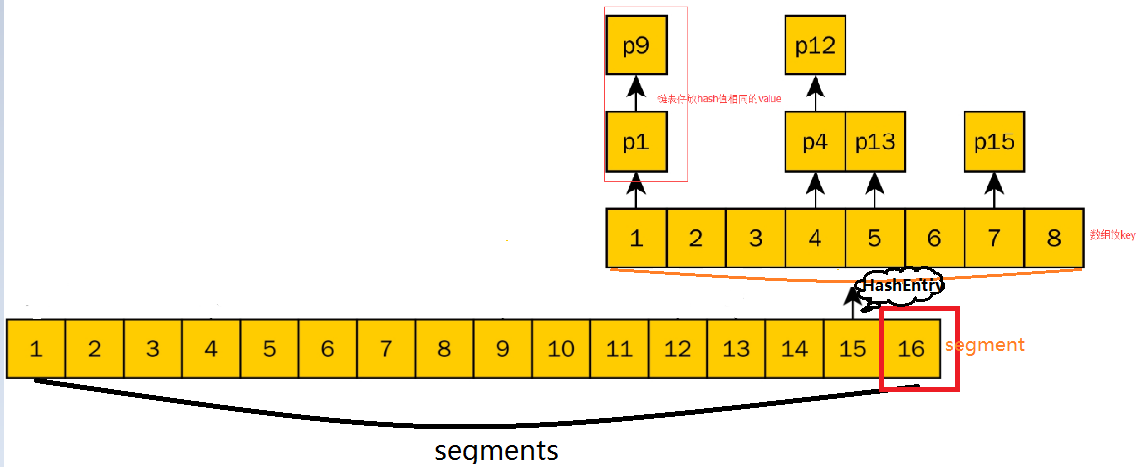
一个ConcurrentHashMap包含了一个Segments数组,每一个Segment和HashTable类似,是一种数组的链表,即每一个Segment维护一个HashEntry数组,每一个HashEntry是一个链表结构。
ConcurrentHashMap的使用方式与HashMap一样:
public static void main(String[] args) { ConcurrentHashMap<String, Object> chm = new ConcurrentHashMap<String, Object>(); chm.put("k1", "v1"); chm.put("k2", "v2"); chm.put("k3", "v3"); chm.putIfAbsent("k3", "vvvv"); System.out.println(chm.get("k2")); System.out.println(chm.size()); for(Map.Entry<String, Object> me : chm.entrySet()){ System.out.println("key:" + me.getKey() + ",value:" + me.getValue()); } }
ConcurrentHashMap的get操作不需要加锁,是经过一次再散列,然后使用这个散列值通过散列运算定位到Segment,再通过散列算法定位到元素。
和get操作一样,先通过key进行两次hash确定应该去哪个Segment中取数据,锁定这个Segment。第一步先判断是否需要对Segment里的HashEntry数组进行扩容。第二步如果需要扩容,则定位到添加元素的位置,放在HashEntry数组里。在扩容的时候,首先会创建一个容量是原来两倍的数组,然后将原数组里的元素进行再散列插入到新的数组里。这样的设计令哈希表即便是在扩容期间,也能保证无锁的读。为了高效,ConcurrentHashMap只会对需要扩容的Segment扩容。
ConcurrentHashMap统计size时会比HashMap麻烦的多,因为使用了分段技术,为了高效,ConcurrentHashMap先会尝试两次不锁住全部Segment的方式统计大小。如果统计过程中容器的count大小发生了变化,再采用加锁的方式统计所有的Segment大小。
2.CopyOnWrite容器
从CopyOnWrite字面意思理解是在写时复制。当我们向容器里添加元素时,不直接往当前容器里添加,而是先将当前容器复制出一个新的容器,然后往新的容器里添加元素。添加完元素后,再将原容器的引用指向新的容器,这样做的好处是可以对容器进行并发的读,而不需要加锁。
CopyOnWrite容器是一种读写分离的思想。jdk里的CopyOnWrite容器有两种:CopyOnWriteArrayList和CopyOnWriteArraySet,它们适用于读多写少的场景中。我先看看CopyOnWriteArrayList源码:
public boolean add(E e) { //加锁 final ReentrantLock lock = this.lock; lock.lock(); try { Object[] elements = getArray(); int len = elements.length; //复制一个新数组 Object[] newElements = Arrays.copyOf(elements, len + 1); //将新元素添加到新数组里 newElements[len] = e; //把原数组的指针指向新数组 setArray(newElements); return true; } finally { //释放锁 lock.unlock(); } }
可以发现在添加的时候是需要加锁的,否则多线程写的时候会Copy出N个副本出来,导致最终的数组数据不是我们期望的。CopyOnWriteArraySet内部构造函数中又调用了CopyOnWriteArrayList,它仅仅是不允许重复的Object数组。
private final CopyOnWriteArrayList<E> al; public CopyOnWriteArraySet() { al = new CopyOnWriteArrayList<E>(); }
CopyOnWriteArrayList和CopyOnWriteArraySet与ArrayList和HashSet用法一样,就不在这里做介绍了。
3.并发Queue
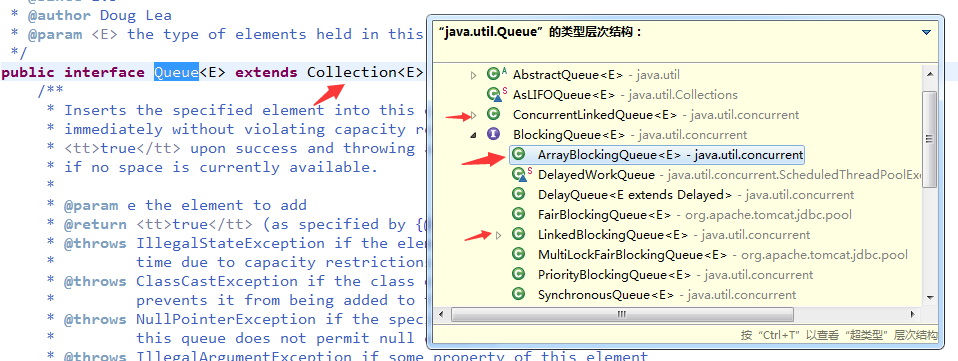
生产者-消费者是一个经典的多线程设计模式,它通常由两类线程组成:生产者线程负责生产数据,消费者线程负责具体拿到数据处理数据。如果生产者直接给消费者提供数据,则耦合度过高。聪明的程序员想了一个办法,把数据存在第三方容器那里,大家都去那里存取数据。这个过程官方的说法就是生产者和消费者之间通过共享内存缓冲区进行通信。并发包下的Queue接口,有很多基于内存缓冲区的队列,层次结构如下:
3.1 高性能队列ConcurrentLinkedQueue
ConcurrentLinkedQueue是高并发场景下,应用很广泛的一种队列。它是一个基于链接节点的无界安全队列,遵循元素先进先出的原则,且元素不允许为null。它有两个重要的方法:
- 加入元素的方法:add()和offer()(在ConcurrentLinkedQueue中这俩方法没有区别),他俩都是Queue接口add和offer方法的实现.因为其他队列有不同的实现.其他队列请看下文。
- 取出元素的方法:poll()取出并删除头元素和peek()取出元素。
//高性能无阻塞无界队列:ConcurrentLinkedQueue ConcurrentLinkedQueue<String> qlq = new ConcurrentLinkedQueue<String>(); qlq.offer("a"); qlq.offer("b"); qlq.offer("c"); qlq.offer("d"); qlq.add("e"); System.out.println(qlq.poll()); //a 从头部取出元素,并从队列里删除 System.out.println(qlq.size()); //4 System.out.println(qlq.peek()); //b System.out.println(qlq.size()); //4
3.2 阻塞队列BlockingQueue接口
使用上文的非阻塞队列时有一个很大问题:它不会对当前线程产生阻塞,在面对类似消费者-生产者的模型时,就必须额外地实现同步策略以及线程间唤醒策略,这个实现起来就非常麻烦。BlockingQueue很好的解决了多线程中,如何高效安全“传输”数据的问题。可以将BlockingQueue队列应用于生产者--消费者队列。
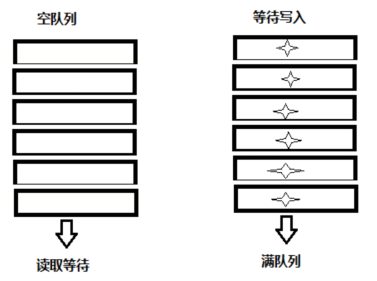
当试图在空队列里读数据时,读的线程就会做一个等待,等待另外一个线程往队列里写数据时,等待线程就会唤醒,并且拿到数据。反之当队列满时,试图写数据得线程就会等待,直到有线程从另一端拿数据时,写数据的线程将会唤醒。
它是基于数组的阻塞队列实现,属于有界队列。可以指定先进先出或先进后出,内部用一个定长的数组缓存队列中的数据对象。因为没有实现读写分离,所以生产者和消费者不能完全并行。
ArrayBlockingQueue<String> array = new ArrayBlockingQueue<String>(5); array.put("a"); array.put("b"); array.add("c"); array.add("d"); array.add("e"); //array.add("f");这里放开会报异常,因为已经添加了5个元素了 //2秒后返回false,表示添加失败 System.out.println(array.offer("a", 2, TimeUnit.SECONDS));
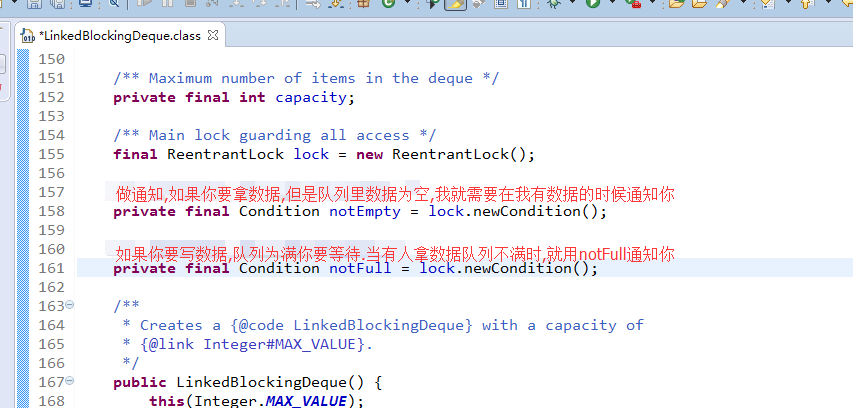
它是基于链表的阻塞队列实现,属于无界队列。内部用一个链表缓存队列中的数据对象,它实现了读写分离,所以可以高效的处理并发数据,生产者和消费者也可以完全并行。其内部是使用ReentrantLock和Condition实现生产者和消费者模式。(ReentrantLock和Condition的解读可以访问博主的另外一篇文章:【Java并发基础】concurrent包工具类详解):
//阻塞队列 LinkedBlockingQueue<String> q = new LinkedBlockingQueue<String>(); q.offer("a"); q.offer("b"); q.offer("c"); q.offer("d"); q.offer("e"); q.add("f"); System.out.println(q.size());//6 for (Iterator iterator = q.iterator(); iterator.hasNext();) { String string = (String) iterator.next(); System.out.print(string+" ");//a b c d e f } System.out.println(); List<String> list = new ArrayList<String>(); //从队列中取三个元素放到list集合里,并返回队列的长度 System.out.println(q.drainTo(list, 3));//3 System.out.println(list.size());//3 for (String string : list) { System.out.print(string+" ");//a b c }
一种没有缓冲的队列,生产者生产的数据会直接被消费者获取并消费。SynchronousQueue单纯add的时候会报full异常,因为它没有容量,但是可以多线程的取和加:
//需要先取数据,才能向SynchronousQueue添加数据,直接添加会报错 final SynchronousQueue<String> q = new SynchronousQueue<String>(); //q.add("adsa ");// java.lang.IllegalStateException: Queue full Thread t1 = new Thread(new Runnable() { @Override public void run() { try { System.out.println(q.take()); } catch (InterruptedException e) { e.printStackTrace(); } } }); t1.start(); Thread t2 = new Thread(new Runnable() { @Override public void run() { q.add("asdasd"); } }); t2.start(); }
到这里博主介绍完了常用的Java并发容器,博主是个普通的程序猿,水平有限,文章难免有错误,欢迎牺牲自己宝贵时间的读者,就本文内容直抒己见,博主的目的仅仅是希望对读者有所帮助。

