一、概述
RabbitMQ用于的服务和Zipkin服务端的通信,代替服务和Zipkin服务端通过http协议的通信,实现了微服务和Zipkin服务端的解耦,微服务不再需要知道Zipkin服务端的网络地址。利用Mysql或Elasticsearch实现追踪数据的持久化(Zipkin默认是将追踪数据存在内存中,如服务端重启或宕机,会导致历史数据丢失,所以追踪数据持久化很有必要), 本文基于Elasticsearch持久化数据。
二、功能开发实现
1.创建zipkin-stream-server服务
建普通的SpringBoot项目zipkin-stream-server,在pom.xml文件中增加如下依赖(RabbitMQ和Elasticsearch的安装和部署不在本文介绍,可自行度娘)
<dependencies> <dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-sleuth-zipkin-stream</artifactId> </dependency> <dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-starter-stream-rabbit</artifactId> </dependency> <dependency> <groupId>io.zipkin.java</groupId> <artifactId>zipkin-autoconfigure-ui</artifactId> <scope>runtime</scope> </dependency> <dependency> <groupId>io.zipkin.java</groupId> <artifactId>zipkin-autoconfigure-storage-elasticsearch-http</artifactId> <version>1.24.0</version> <optional>true</optional> </dependency> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-test</artifactId> <scope>test</scope> </dependency> </dependencies>
在ZipKinStreamServerApplication主方法上添加@EnableZipkinStreamServer注解,启用ZipkinStreamServer功能。
@EnableZipkinStreamServer @SpringBootApplication public class ZipkinStreamServerApplication { public static void main(String[] args) { SpringApplication.run(ZipkinStreamServerApplication.class, args); } } 修改配置文件,增加rabbitmq和elasticsearch相关配置
spring.application.name=zipkin-stream-server server.port=9110 spring.sleuth.enabled=false spring.sleuth.sampler.percentage=1 zipkin.storage.type=elasticsearch zipkin.storage.elasticsearch.hosts=127.0.0.1:9200 zipkin.storage.elasticsearch.max-requests=64 zipkin.storage.elasticsearch.index=zipkin zipkin.storage.elasticsearch.index-shards=5 zipkin.storage.elasticsearch.index-replicas=1 #rabbitmq配置 spring.rabbitmq.host=10.17.5.62 spring.rabbitmq.port=5672 spring.rabbitmq.username=admin spring.rabbitmq.password=admin spring.rabbitmq.virtual-host=/dev
启动服务
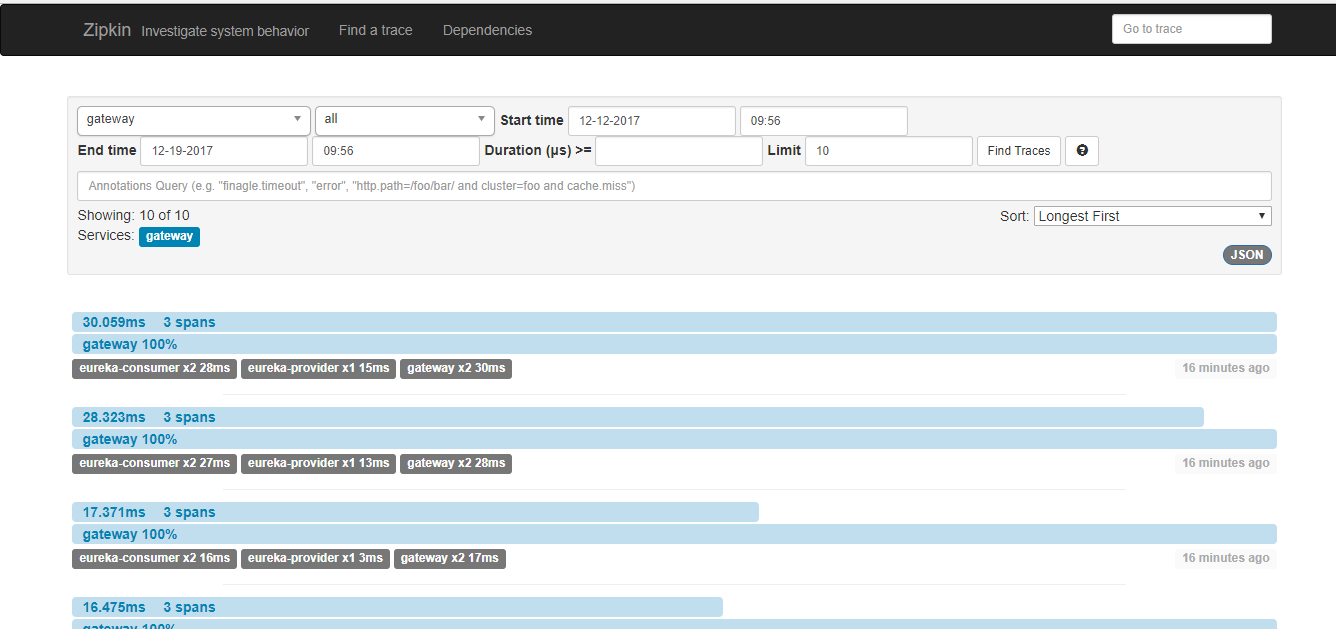
2.给原先服务增加链路追踪支持
给eureka-provider、eureka-consumer、gateway三个服务增加如下依赖(去掉spring-cloud-starter-zipkin依赖)
<!-- <dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-starter-zipkin</artifactId> </dependency>--> <dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-sleuth-zipkin-stream</artifactId> </dependency> <dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-starter-stream-rabbit</artifactId> </dependency>
修改配置文件,增加rabbitmq相关配置
#rabbitmq配置 spring.rabbitmq.host=10.17.5.62 spring.rabbitmq.port=5672 spring.rabbitmq.username=admin spring.rabbitmq.password=admin spring.rabbitmq.virtual-host=/dev
重新部署启动服务,调用zuul接口,观察zipkin-server页面,生成调用链路
RabbitMQ中生成一个名字为sleuth.sleuth的Queues
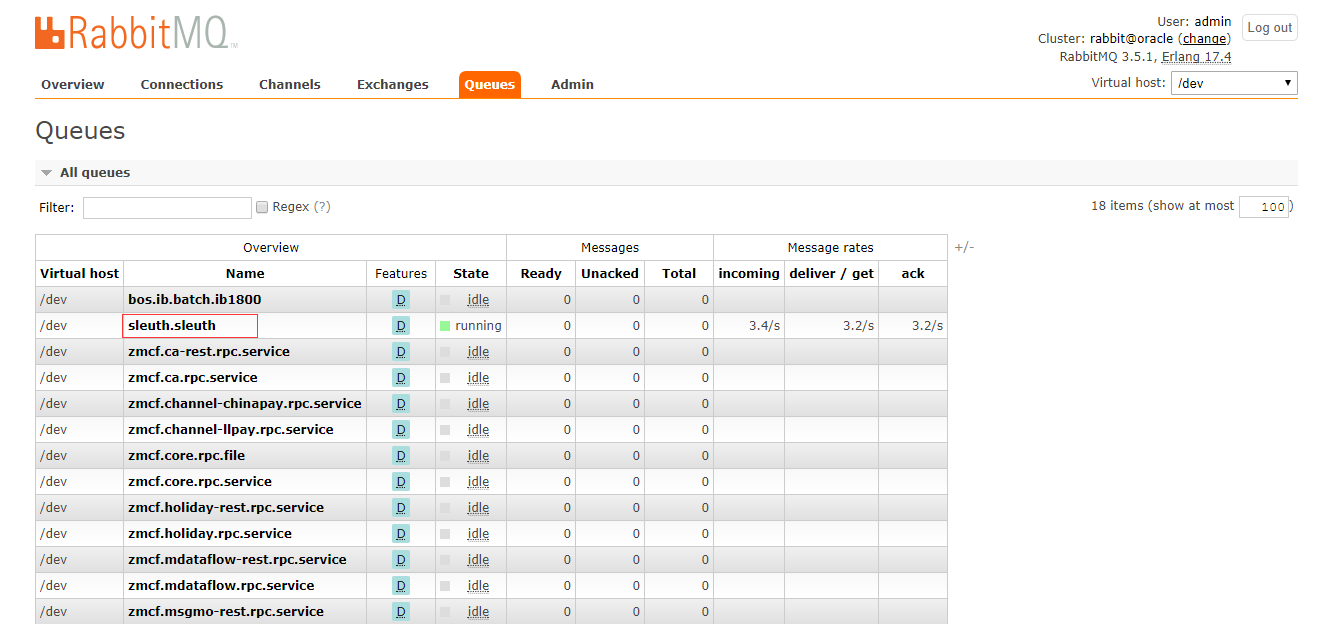
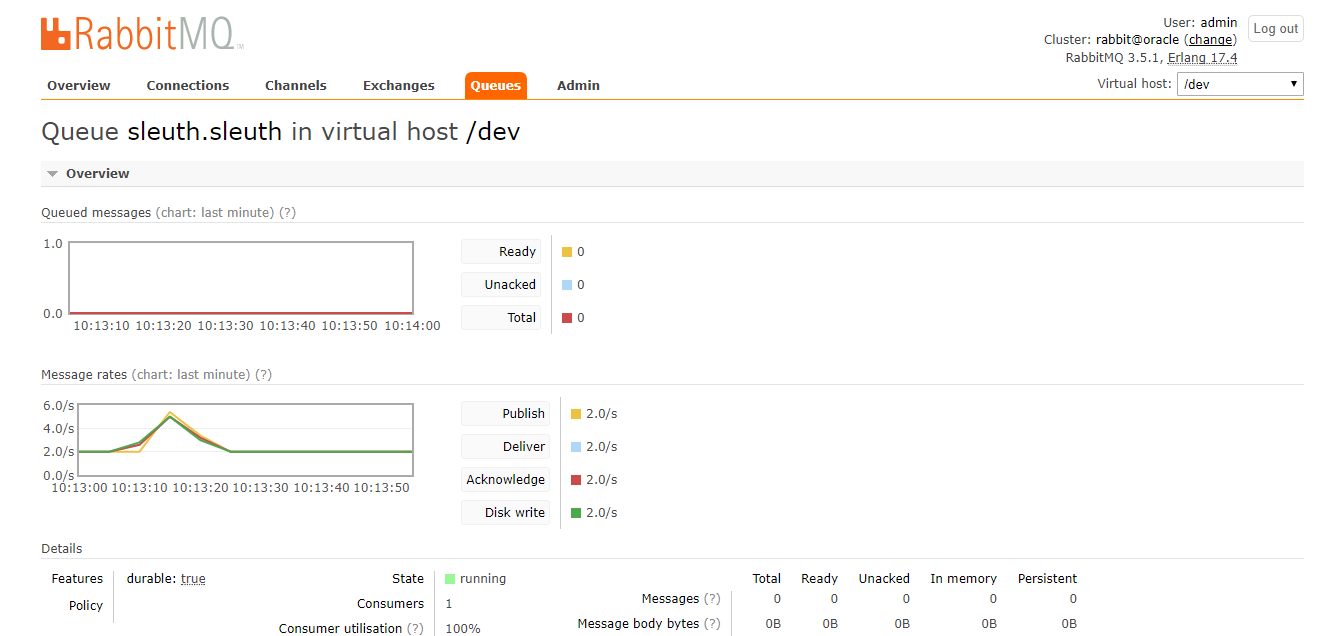
Zipkin链路页面
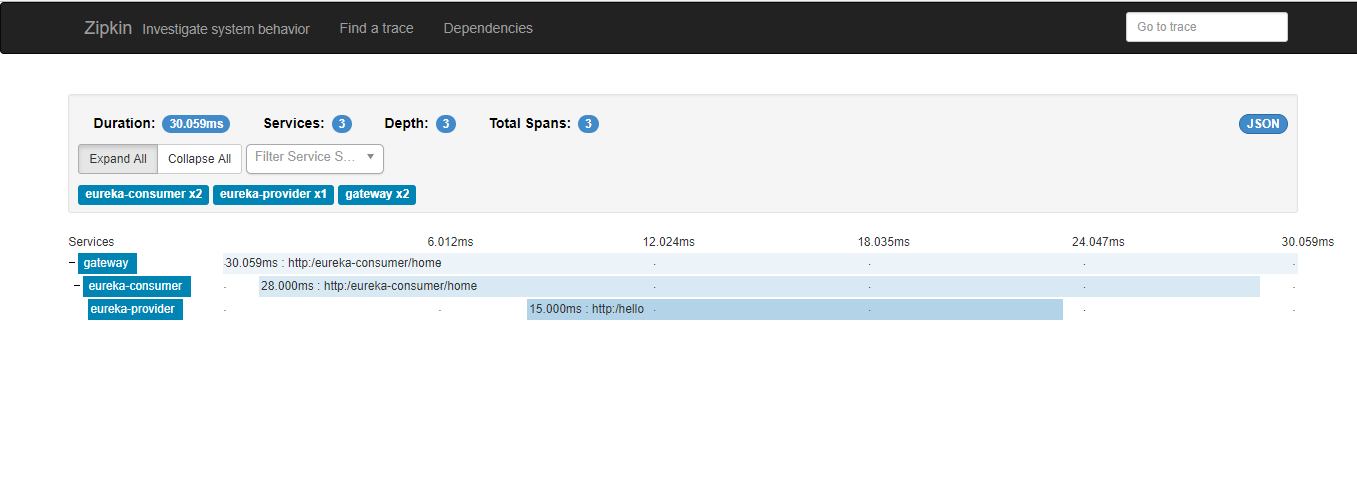
数据持久化到elasticsearch

三、小结
当然,数据持久化也可以选择mysql或者其他数据库,只需要修改引入的依赖包和响应的配置文件即可,本文不再赘述。
码云地址:https://gitee.com/gengkangkang/springcloud.git
github地址:https://github.com/gengkangkang/springcloud.git


