一、导读
1、爬虫基础知识
2、优秀国产开源爬虫框架webmagic剖析
二、爬虫基础
1、爬虫的本质
爬虫的本质:基于Http协议请求目标地址获取响应结果解析并存储。
2、HTTP请求
(1)、请求头(Request Headers):包装了http请求的基本信息,比较重要的如:user-agent、referer、cookie、accept-language(接受语言)、请求方法(post、get)。
(2)、响应头(Response Headers):包装了服务器返回的头信息,如content-language内容语言、content-type内容的类型text/html等 、server服务器类型(tomcat、jetty、nginx等)、status响应状态(如:200、302、404等等)。
(3)、Response:服务端具体的返回,类型多种多样,有html页面、js代码、json串、css样式、流等等。
3、解析
通常情况下,web返回的基本都是html页面、json。
(1)、xpath
xml路径语言,具备很强的解析能力,chrome、firefox都有对应的工具生成xpath语法,可以很方便的对标准html文件进行解析。
(2)、jsonpath
jsonpath是一个json解析的利器,非常类似于xpath语法,用非常简洁的表达式解析json串。
(3)、css选择器
这里的css选择器和jquery有点类似,通过元素的css样式来定位元素,大名鼎鼎的jsoup提供丰富的css选择器
(4)、正则表达式
(5)、字符串分割
4、难点
(1)、分析请求
ajax的普及,很多网站都采用了动态渲染的模式,请求不再是简单的返回html的模式,那么给爬取带来了巨大的难度,一般只能靠分析异步请求返回的json来具体分析,解析成我们需要的数据格式。还有一类是通过服务端内部转发来渲染页面,这类是最难的,请求不是通过浏览器来请求,而是再服务端跳转几次才渲染给浏览器,这时候需要使用模拟器来模拟请求,如selenium等。
(2)、网站的限制
cookie限制:很多网站是要登陆后才能绕过filter才能访问,这时候必须模拟cookie
user-agent:有的网站为了防爬虫,必须要求是真正浏览器才能访问,这时候可以模拟 user-agent
请求加密:网站的请求如果加密过,那就看不清请求的本来面目,这时候只能靠猜测,通常加密会采用简单的编码,如:base54、urlEncode等,如果过于复杂,只能穷尽的去尝试
IP限制:有些网站,会对爬虫ip进行限制,这时候要么换ip,要么伪装ip
曲线方案:对应pc端,很多网站做的防护比较全面,有时候可以改一下思路,请求app端服务试试,通常会有意想不到的收获。
(3)、爬取深度
网站通常的表现形式是一个页面超链接着另外的页面,理论上是无限延伸下去的,这时候必须设置一个爬取深度,不能无穷无尽的爬取。
5、总结
爬虫本质上只做了两件事情:请求和解析结果,但是爬虫的开发是非常困难的,需要不停的分析网站的请求,不停的跟随目标网站来升级自己的程序,试探解密、破解目标网站限制,把它当做网络攻防一点也不为过。
三、webmagic架构解析
webmagic是一个优秀的国产爬虫框架、简单易用、提供多种选择器,如css选择器、xpath、正则等等,预留了多个扩展接口,如Pipeline、Scheduler、Downloader等。
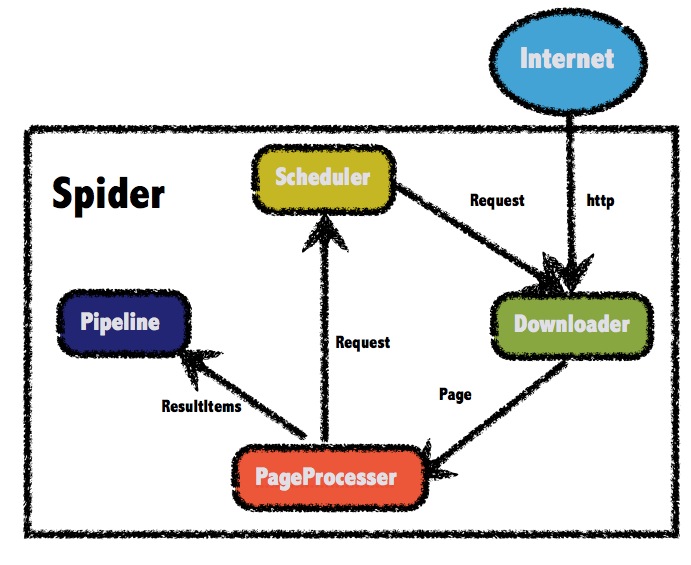
上图复制于webmagic官方文档,webmagic由四部分组成
Downloader:负责请求url获取访问的数据(html页面、json等)。
PageProcessor:解析Downloader获取的数据。
Pipeline:PageProcessor解析出的数据由Pipeline来进行保存或者说叫持久化。
Scheduler:调度器通常负责url去重,或者保存url队列,PageProcessor解析出的url可以加入Scheduler队列,用于下一次的爬取。
Webmagic使用非常简单,实现PageProcessor 接口,即可利用Spider类启动爬虫任务了。
Spider.create(new GithubRepoPageProcessor()) //从"https://github.com/code4craft"开始抓 .addUrl("https://github.com/code4craft") //开启5个线程抓取 .thread(5) //启动爬虫 .run();
下面重点解析一下Spider类的几个重要方法,包括锁的使用
1、addUrl
public Spider addUrl(String... urls) { for (String url : urls) { addRequest(new Request(url)); } signalNewUrl(); return this; } private void addRequest(Request request) { if (site.getDomain() == null && request != null && request.getUrl() != null) { site.setDomain(UrlUtils.getDomain(request.getUrl())); } scheduler.push(request, this); }
scheduler.push(request, this),把需要爬取的url加入到Scheduler队列。
2、initComponent
protected void initComponent() { if (downloader == null) { this.downloader = new HttpClientDownloader(); } if (pipelines.isEmpty()) { pipelines.add(new ConsolePipeline()); } downloader.setThread(threadNum); if (threadPool == null || threadPool.isShutdown()) { if (executorService != null && !executorService.isShutdown()) { threadPool = new CountableThreadPool(threadNum, executorService); } else { threadPool = new CountableThreadPool(threadNum); } } if (startRequests != null) { for (Request request : startRequests) { addRequest(request); } startRequests.clear(); } startTime = new Date(); }
初始化downloader、pipelines、threadPool线程池,这里有必要说明一下,webmagic默认down是HttpClientDownloader、默认pipeline是ConsolePipeline.
2、run
run方法是整个爬行运行的核心
public void run() { checkRunningStat(); initComponent(); logger.info("Spider {} started!",getUUID()); while (!Thread.currentThread().isInterrupted() && stat.get() == STAT_RUNNING) { final Request request = scheduler.poll(this); if (request == null) { if (threadPool.getThreadAlive() == 0 && exitWhenComplete) { break; } // wait until new url added waitNewUrl(); } else { threadPool.execute(new Runnable() { @Override public void run() { try { processRequest(request); onSuccess(request); } catch (Exception e) { onError(request); logger.error("process request " + request + " error", e); } finally { pageCount.incrementAndGet(); signalNewUrl(); } } }); } } stat.set(STAT_STOPPED); // release some resources if (destroyWhenExit) { close(); } logger.info("Spider {} closed! {} pages downloaded.", getUUID(), pageCount.get()); }
(1)、任务结束时机
队列为空并且所有正在运行请求完成,且设置了exitWhenComplete为true,这时才会退出任务,这时候必须注意一点是,当页面请求过于慢,导致新解析的url来不及进队列,这时候任务退出导致爬取不完整。一般设置exitWhenComplete为false,但是有时候开启两个爬虫,必须等上一个爬虫完成,才运行下一个爬虫,这时候就会出问题了。实现这种场景,得改一下webmagic源码
(2)、等待新请求时间,默认是30s
private void waitNewUrl() { newUrlLock.lock(); try { //double check if (threadPool.getThreadAlive() == 0 && exitWhenComplete) { return; } newUrlCondition.await(emptySleepTime, TimeUnit.MILLISECONDS); } catch (InterruptedException e) { logger.warn("waitNewUrl - interrupted, error {}", e); } finally { newUrlLock.unlock(); } }
(3)、若scheduler队列里有url,在把任务丢进线程池,页面download成功,则执行pageProcessor的process方法,如果有pipeline,则执行pipeline链里的process方法
private void onDownloadSuccess(Request request, Page page) { onSuccess(request); if (site.getAcceptStatCode().contains(page.getStatusCode())){ pageProcessor.process(page); extractAndAddRequests(page, spawnUrl); if (!page.getResultItems().isSkip()) { for (Pipeline pipeline : pipelines) { pipeline.process(page.getResultItems(), this); } } } sleep(site.getSleepTime()); return; }
有一点要注意,对于PageProcessor接口和Pipeline接口的实现,特别要注意线程安全的问题,切记不可对单例集合对象塞元素。
(4)、线程池CountableThreadPool的execute方法
public void execute(final Runnable runnable) { if (threadAlive.get() >= threadNum) { try { reentrantLock.lock(); while (threadAlive.get() >= threadNum) { try { condition.await(); } catch (InterruptedException e) { } } } finally { reentrantLock.unlock(); } } threadAlive.incrementAndGet(); executorService.execute(new Runnable() { @Override public void run() { try { runnable.run(); } finally { try { reentrantLock.lock(); threadAlive.decrementAndGet(); condition.signal(); } finally { reentrantLock.unlock(); } } } }); }
这里有死锁的风险,当threadAlive数大于等于threadNum线程数,reentrantLock.lock()申请锁,循环condition.await(),与此同时 executorService.execute方法中的threadAlive的decrementAndGet也必须reentrantLock.lock()申请锁,此时,两方互相等待资源而造成死锁,这个小bug调整一下,无碍大局。到时候官方提一个issues
总体说来,Webmagic架构清晰,扩展容易,使用方便,是一款不错的爬虫框架。
快乐源于分享。
此博客乃作者原创, 转载请注明出处

