本文作者:Adrian Colyer —— 现任伦敦 Accel 合伙人,曾担任 SpringSource 的 CTO 多年,在 VMware,Pivotal 担任过首席技术官(英文原文)。
十年来之不易的经验教训总结成了17页的论文(除去参考文献有13页),完整的 PDF 可以从这里下载。这篇论文可以大大的节省你研究的时间,同时也是一个分布式存储系统研究非常好的例子。在这个例子中,我们明确整个分布式存储系统是基于操作系统原生的文件系统之上。而由于种种的问题,Ceph 现在已经引入一个新的名为 BlueStore 的存储后端,该后端具有更好的性能和可预测性,并能够支持不断变化的存储硬件格局。自发布以来的两年中,已经有 70% 的Ceph用户在生产系统中使用 BlueStore 这个存储后端。
Ceph 是一种广泛使用的、开源的分布式文件系统,十年来一直都是在本地文件系统上构建分布式存储。Ceph 团队在使用几种流行的文件系统后,通过很长时间吸取的非常多的教训,这些教训使得他们质疑文件系统是否是作为存储后端的合适选择。而我们事后看来,这并不奇怪。
可是有时候,事后看来并不奇怪的事情可能也是最难发现的事情!
什么是分布式存储后端?
分布式文件系统提供了来自多个物理机的聚合存储的统一视图。它应提供高带宽,水平可伸缩性,容错性和强一致性。所述存储后端是软件模块直接管理连接至物理机的存储装置。
尽管不同的系统从存储后端需要不同的功能,但是其中两个功能(1)高效的事务处理和(2)快速的元数据操作 是最为普遍的;另一个新出现的要求是(3)支持最新出现的,而且无法向后兼容的存储硬件。
我们假设你已经知道了什么是“高效交易”和“快速元数据操作”。但是在继续之前,让我们快速看一下不断变化的硬件格局。
不断变化的硬件格局
为了增加容量,硬盘驱动器(HDD)供应商正在引入带状磁记录(SMR)技术。为了有效地使用这些驱动器,必须切换到使用其向后不兼容的区域接口。
区域接口……将磁盘作为256个MiB区域的序列进行管理,必须按顺序写入,从而鼓励采用日志结构,写时复制的设计。此设计与大多数成熟文件系统在写入之后的就地被覆盖的设计完全相反。
SSD 存储发生了类似的变化,其中一种称为区域命名空间(ZNS)的新 NVMe 标准可绕过闪存转换层(FTL)。
迄今为止,尝试修改生产文件系统以使其与区域接口一起使用均未成功,主要是因为它们正在覆盖文件系统。”
在本地文件系统上构建十年
如果您需要管理本地存储设备上的文件,则很显然文件系统是一个不错的切入点。毕竟,文件系统有很多工作要做:
生产文件系统的历史表明,它们平均需要十年才能成熟。
这是十多年来 Ceph 和其他许多人的最初设想。
Ceph 的核心是RADOS,即可靠的自治分布式对象存储 (Reliable Autonomic Distributed Object Store)服务。RADOS 网关对象存储区(相对于S3),RADOS块设备(相对于EBS)和CephFS分布式文件系统均基于 RADOS 构建。在过去的十多年中,RADOS 经过了多次迭代。
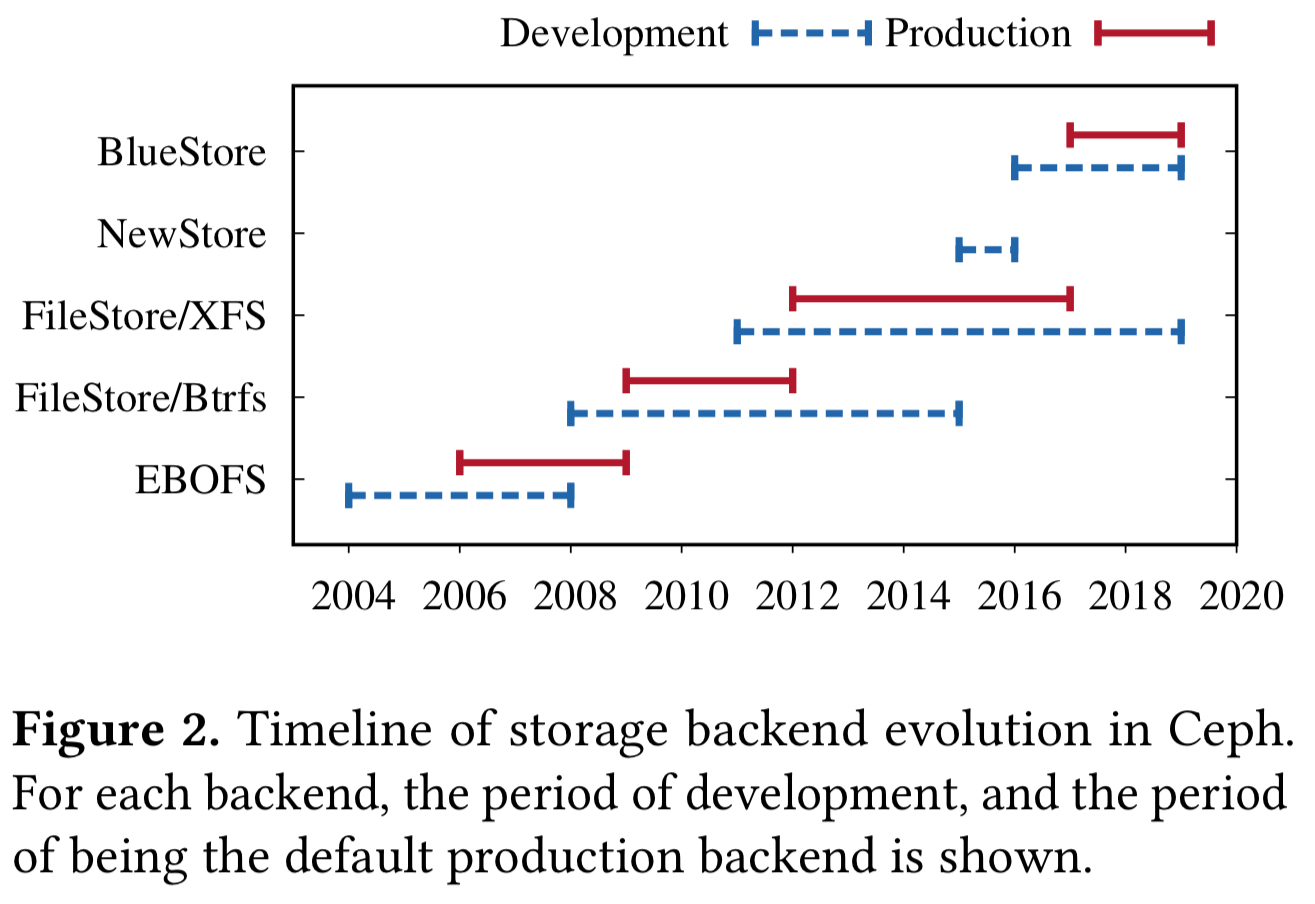
第一个实现方式(大约在2004年)是一个用户空间文件系统,称为基于范围和B树的目标文件系统。在2008年,随着Btrfs的出现,利用Btrfs的事务,重复数据删除,校验和和压缩构建了一个新的实现。
Btrfs上的FileStore是生产后端,这几年来,Btrfs一直不稳定,并遭受严重的数据和元数据碎片化的困扰。
最终,Btrfs被放弃,转而支持XFS,ext4和ZFS。其中,XFS成为了事实上的后端,因为它可以更好地扩展并且具有更快的元数据性能。
尽管XFS上的FileStore稳定,但仍遭受元数据碎片化的困扰,并未充分利用硬件的潜力。
在本地文件系统上构建存储后端的三个挑战
- 有效地执行事务处理
- 高性能的元数据操作
- 支持新的存储硬件
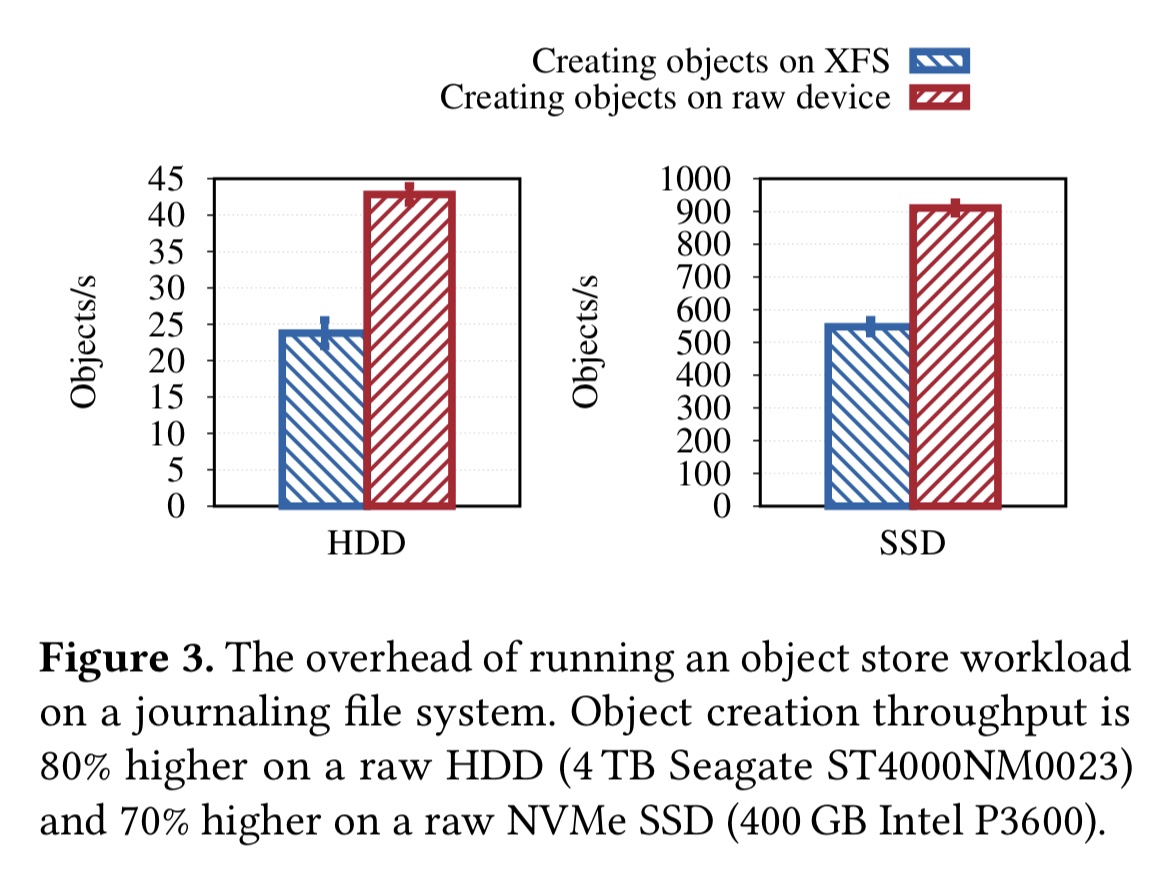
有效地执行事务处理
作者随着时间的推移尝试了三种不同的事务处理策略,每种策略都会导致显著的性能或复杂性开销。第一种方法是使用文件系统本身提供的内部事务处理机制。通常,尽管文件系统确实提供了一种事务处理机制,但对于对象存储用例来说还是太局限了(例如,一段时间内没有对Btrfs的回滚支持,如今,它根本没有事务处理系统调用)。
第二种方法是在用户空间中实现逻辑WAL(预写日志)。这导致缓慢的读取-修改-写入周期和两次写入。
第三种方法是将RocksDB用于元数据,该方法通过支持原子元数据操作来解决了其中一些问题,但引入了其他问题-特别是由于要求更频繁地刷新而导致较高的一致性开销。
高性能的元数据操作
本地文件系统中元数据操作的低效率是分布式文件系统不断努力的根源。
当目录中包含太多文件时,文件列举会变慢,因此标准做法是创建具有较大扇出(fan-out)和每个目录数百个条目的目录层次结构。大规模管理此过程是一个昂贵的过程 —— 仍有数百万个inode导致许多小的I/O操作,并且目录项会随着时间散布在磁盘上。“ 当所有Ceph OSD开始出现统一性能下降的情况时……这是一个众所周知的问题,多年来一直困扰着许多Ceph用户。”
支持现代硬件
我们之前已经看过这个问题。从根本上讲,这里的张力是写时复制语义与新兴区域接口语义不匹配。
也许有更好的方法……
在XFS上的FileStore之后,引入了NewStore,该对象将对象元数据存储在RocksDB中。这缓解了元数据碎片化的问题,但是当它放在日记文件系统的顶部时,引入了其自身的问题,具有高一致性开销。NewStore紧随其后的是使用原始磁盘的BlueStore。
BlueStore 是全新设计的存储后端,旨在解决使用本地文件系统的后端所面临的挑战。BlueStore 主要目标是:(1)快速元数据操作,(2)没有对象写入的一致性开销,(3)写时复制克隆操作,(4)没有日志记录双重写入,(5)优化HDD和SDD的I/O模式。
BlueStore在短短两年内就实现了所有这些目标,并成为Ceph中的默认存储后端。
BlueStore将元数据存储在RocksDB中,以确保快速的元数据操作。为了避免对象写入的任何一致性开销,它会将数据直接写入原始磁盘,因此对于一次数据写入,只有一次缓存刷新。它还对RocksDB(上游)进行了更改,以便将WAL文件用作元数据写入的循环缓冲区。RocksDB本身在BlueFS上运行,BlueFS是在原始存储设备上运行的最小文件系统。命名空间方案允许简单地通过更改被视为键的有效位数来将数百万个对象的集合拆分为多个集合。
BlueStore后端是写时复制。对于大于最小分配大小的写入,BlueStore提供了有效的克隆操作,并且可以避免日志重复写入。对于小于最小分配大小的写入,首先将元数据和数据插入RocksDB,并在提交后异步写入磁盘。
因为BlueStore提供了对I/O堆栈的完全控制,所以也可以有效地实现校验和和透明压缩。而且,RocksDB和BlueStore都已移植到可以在主机管理的SMR驱动器上运行,并且正在进行新的工作,以将持久性内存和具有新颖接口(例如ZNS SSD和KV SSD)的新兴NVMe设备组合为目标。
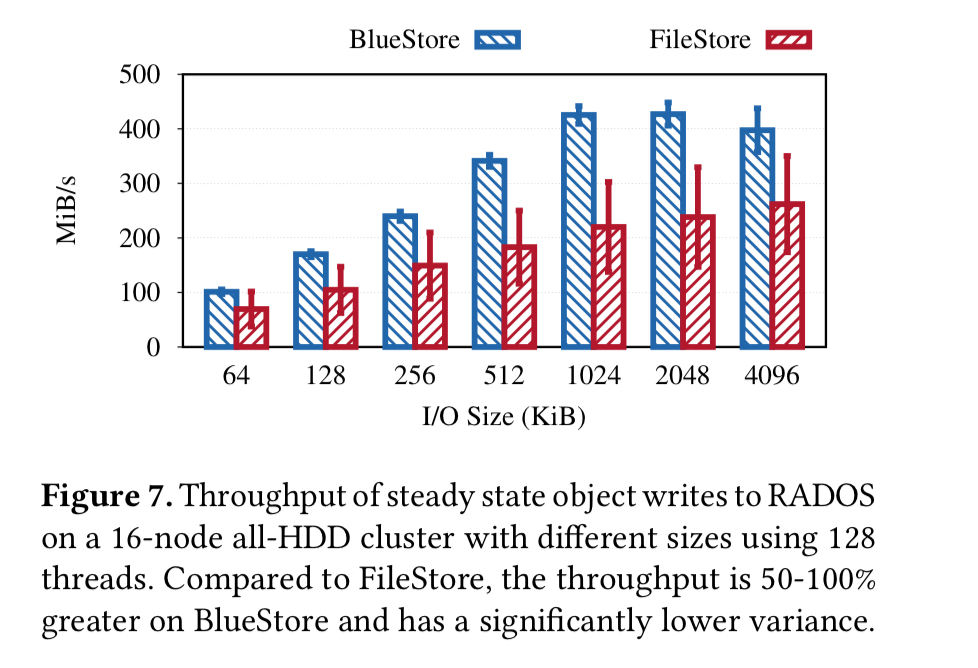
BlueStore的性能亮点
有关性能评估的全部详细信息,请参见论文中的§6。简而言之,与FileStore相比,BlueStore证明了稳态吞吐量提高了50-100%,后者的尾部等待时间降低了一个数量级。
将其提升到一个新的水平
寻找性能的最后每一点仍然面临三个挑战:
- 通过动态调整大小功能构建高效的用户空间缓存-PostgreSQL和RocksDB等其他项目共同面临的问题
- RocksDB的问题以及NVMe SSD上的写入放大,串行化和反序列化的CPU使用率高以及禁止自定义分片的线程模型。“ RocksDB和类似的键值存储的这些以及其他问题使Ceph团队不断的在研究更好的解决方案。”
- 在高端NVMe SSD上,工作负载越来越受CPU限制。“ 对于其下一代后端,Ceph社区正在探索减少CPU消耗的技术,例如最小化数据序列化和反序列化,以及将SeaStar框架与无共享模型一起使用…… ”
我们希望这篇经验文章将引发存储从业人员和研究人员之间有关设计分布式文件系统及其存储后端的新方法的讨论。

