快递轨迹管理
对于一个快递公司,在全国范围内有着大量的快递点、快递员、运输车辆以及仓储中心。而快递自产生后,就会在这些地点、人物之间流转。因而,一套完善的快递管理追踪系统是快递公司的重要管理工具;
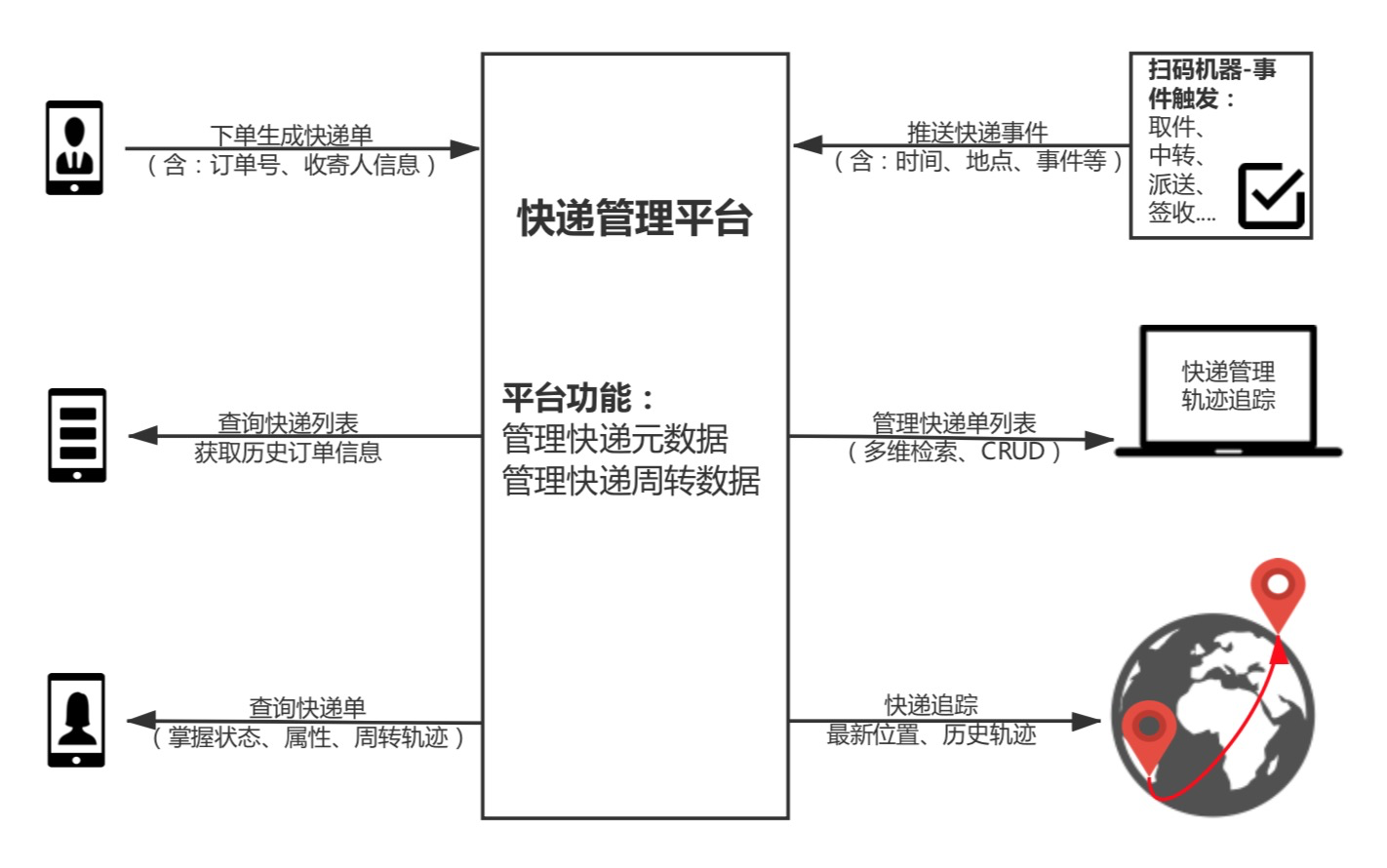
用户通过平台客户端下单后,产生唯一的快递单号作为唯一身份标识。快递除了订单号,还会有很多属性信息,如:邮寄人、邮寄人手机、邮寄人地址、收件人、快递类型等信息。生成快递订单后,用户的邮寄物品才会成为“快递”。快递公司配合扫码机器,将快递的流转事件、地点、时间等信息不定期推送至系统。快递流转信息不仅可以是简单的量化数据,也可以是描述性文字、地理位置等特殊信息。系统将流转信息记录成快递的监控数据,同时修改快递状态、实时位置等。直至快递送达收件人手中,结束快递生命周期。
通过系统,用户可以管理自己的历史邮寄单列表、收件列表,掌握自己邮寄中的快递轨迹。快递公司也可以查询、修改快递信息、追踪快递时效,并借助海量轨迹监控数据,掌握快递产生、收件的高频路线,在高频位置铺设更多的基础设施、转移调度快递员;
功能需求
面向用户:
1、用户在线下单生成快递单,等候快递员上门取件;
2、管理历史订单列表,了解快递明细;
3、追踪特定快递周转状态、运送轨迹;
面向平台:
1、借助扫码器,实现快递周转事件采集、存储;
2、统计、查询所有快递订单,实现全订单的管理:CRUD;
3、掌握所有邮寄中快递的实时位置;
4、掌握任意一个订单的周转状态、运送轨迹;
5、基于历史快递数据,分析快递时效;
6、方便掌握高频地域、路线,为增设基础设施、快递员提供依据;
等等...
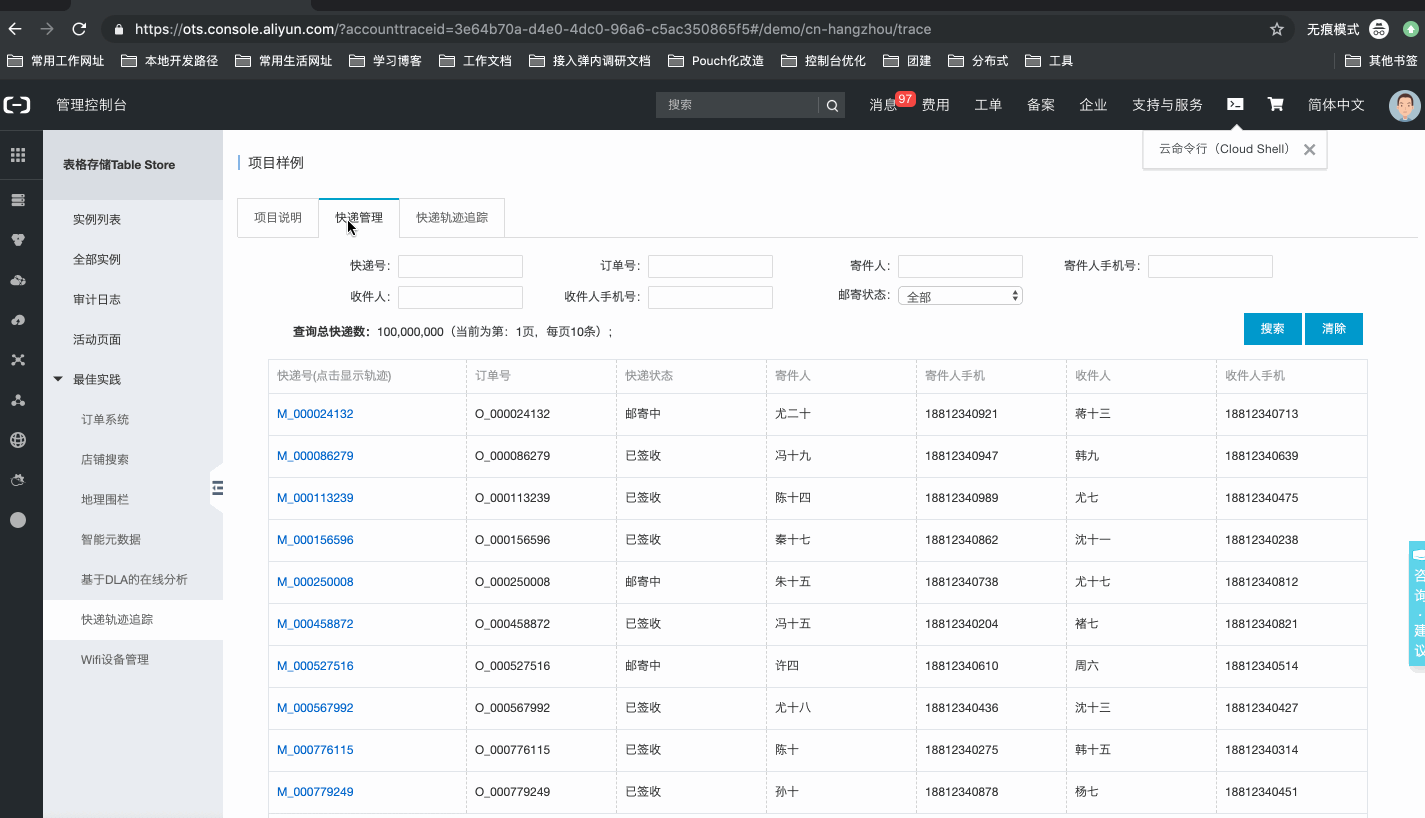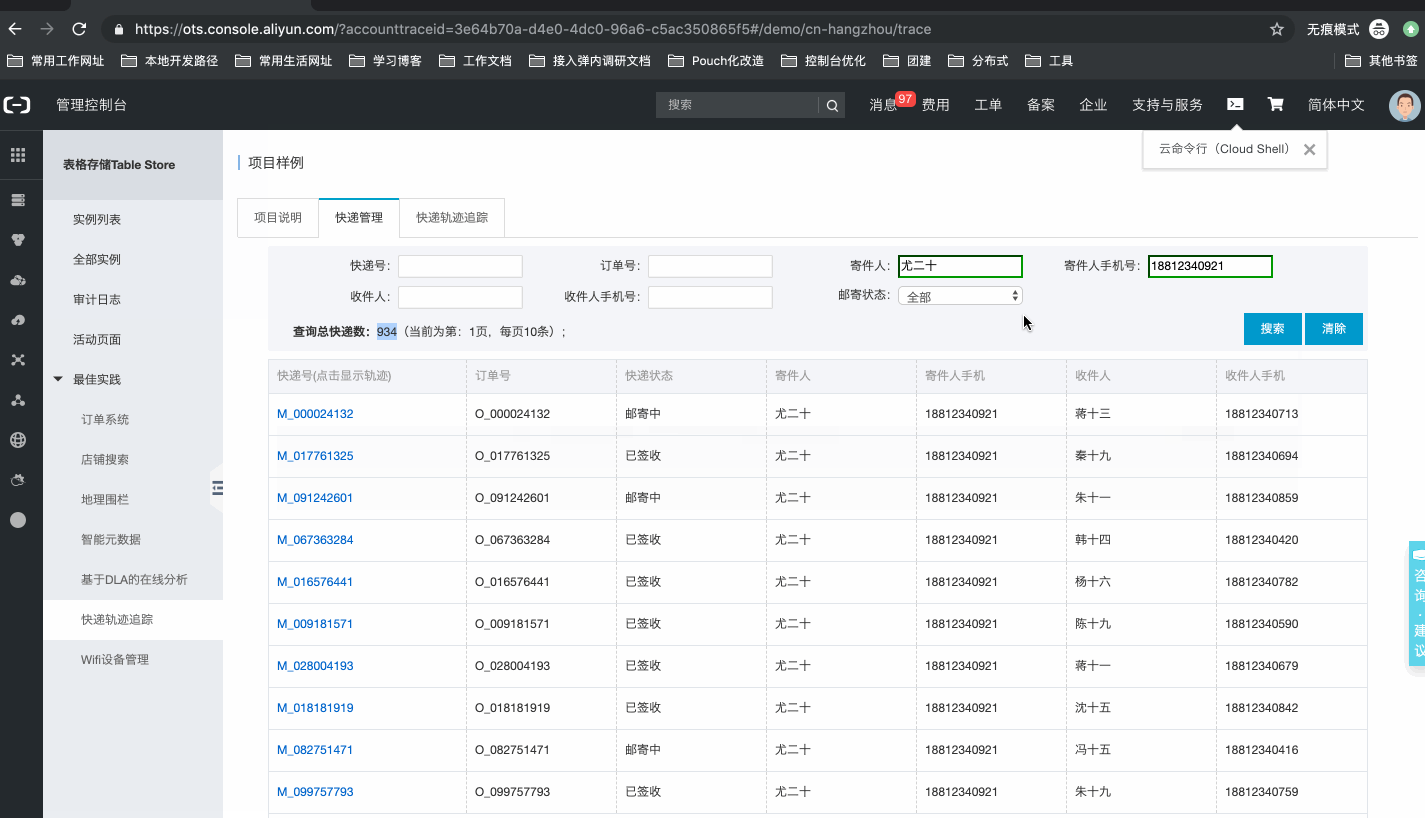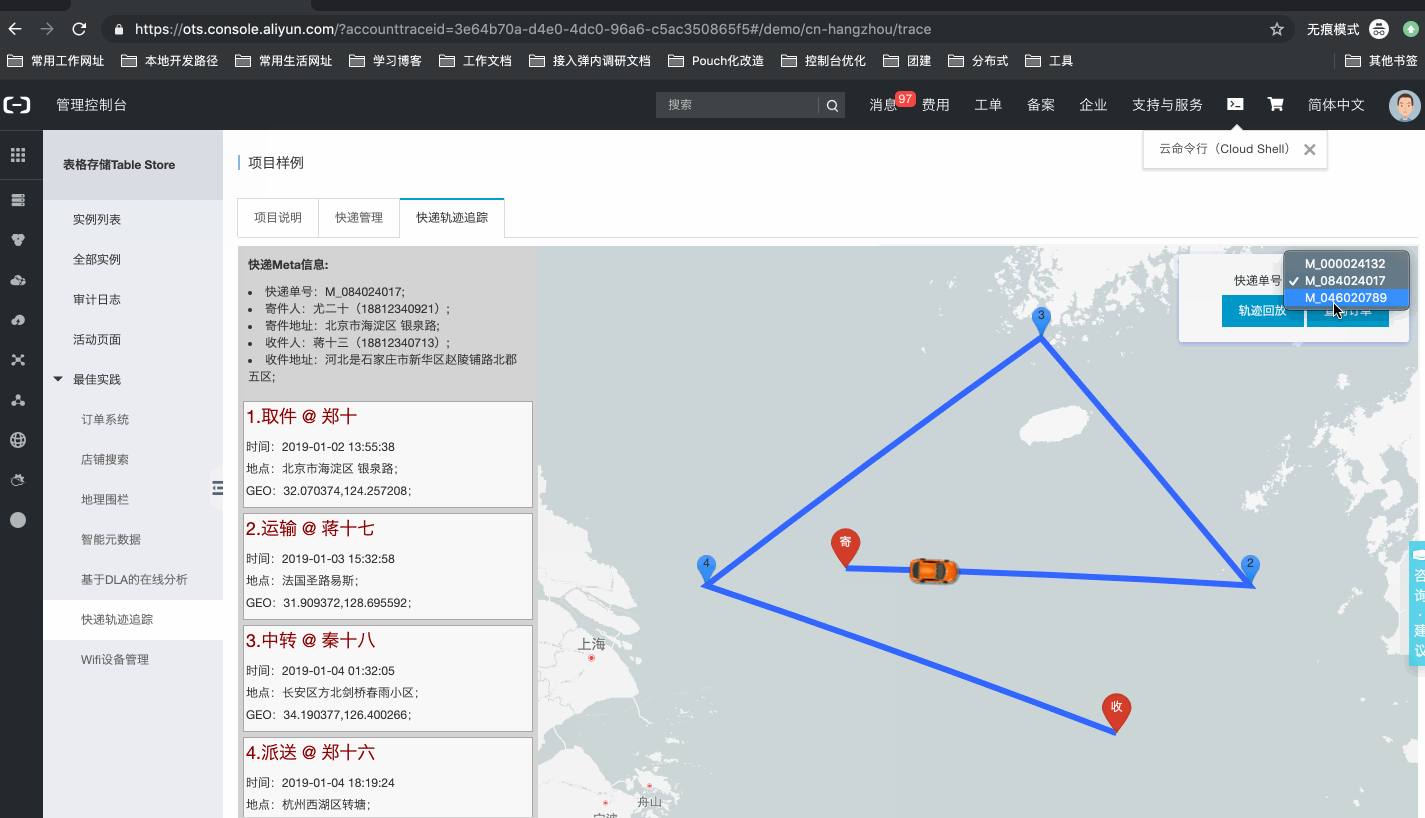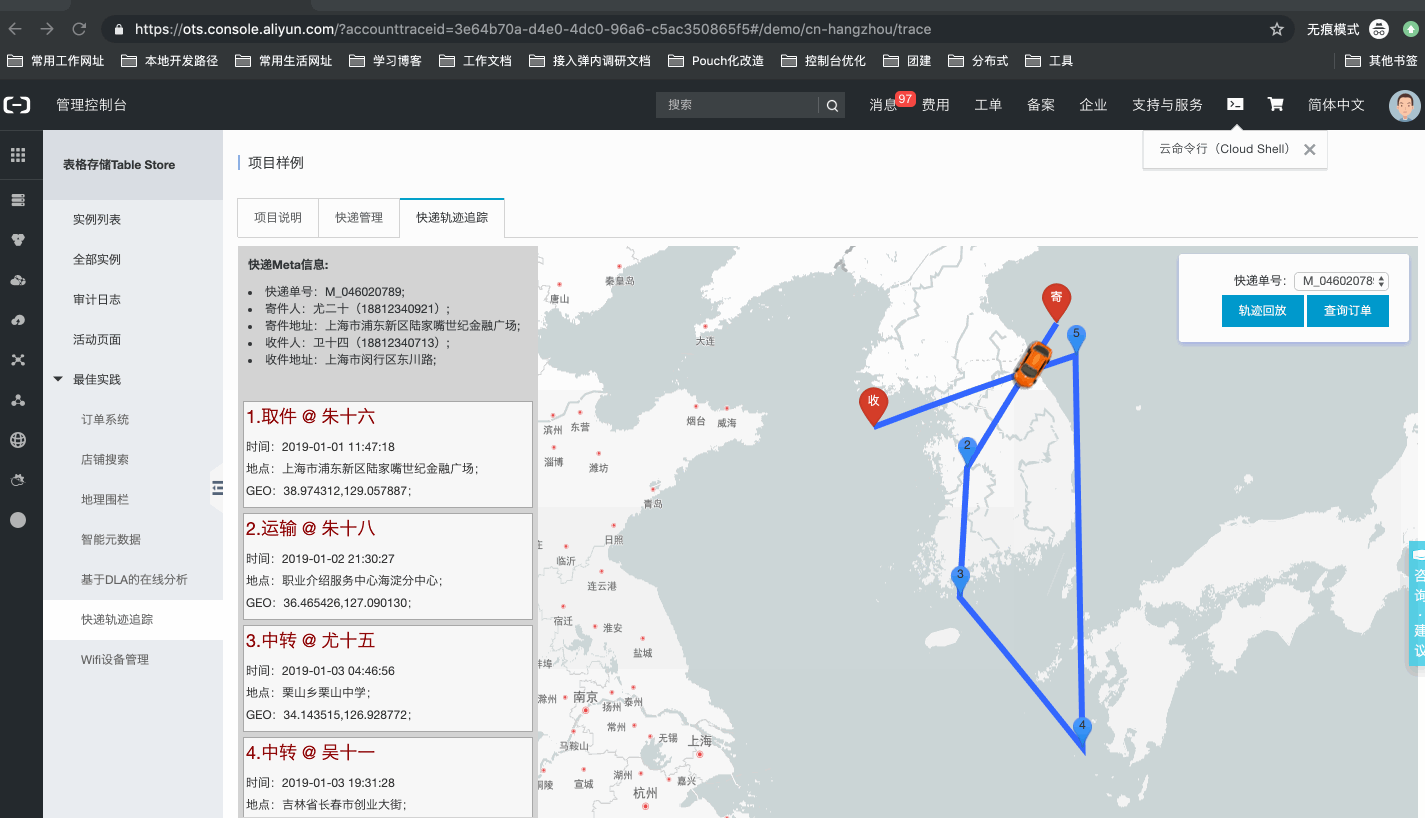
系统样例,如下所示:官网控制台地址:项目样例
实现方案
MySQL方案与难点
通常,用户会选用MySQL作为方案数据库,因为MySQL作为数库在查询、分析等功能上有优势,用户创建两个表:订单表、事件追踪表实现对快递数据的存储。
但是快递场景有几个强需求:
第一、需要有强大的查询、统计能力,实现快递单的管理;
第二、对于海量快递,有着高并发写入需求,对写入性能要求较高;
第三、数据持续膨胀,但历史快递订单、事件数据多为冷数据,存储成本需要尽可能低;
第四、数据未来挖掘潜在价值较高,需要有较好的计算生态;
而MySQL方案在面对第二、第三个强需求时,劣势凸显,海量并发、不断的数据膨胀、存储成本高一直以来都是关系型数据库的痛点;
表格存储方案
选择表格存储有以下优势:
其一、表格存储的多元索引(SearchIndex)功能轻松满足用户的多维查询、GEO检索、统计等功能需求;
其二、基于LSM tree打造的分布式NoSQL数据库,轻松支持海量高并发读、写,零运维轻松应对数据量的不断膨胀,理论上无上限。
其三、表格存储按量计费,提供容量型、高性能型两种实例,容量型对冷数据更适宜,提供了更低存储成本。
其四、更重要的,表格存储拥有较为完善的计算生态,提供全、增量通道服务,提供流计算、批计算一体的计算体系,对未来监控数据价值挖掘提供渠道。
表格存储在时序场景需求的技术点上拥有极高的匹配,而基于时序场景打造的Timestream模型更是将时序场景通用功能,封装成易用的场景接口,使用户更容易的基于表格存储,根据自身需求设计、打造不同特点的轨迹追踪系统;
数据结构设计
基于快递的时序,将快递的属性信息作为meta数据,而快递的周转路径、状态、位置等则为data数据,下面对两类数据做简单介绍。
快递元数据
meta数据管理着快递的属性信息,支持指标、标签、属性、地理位置、更新时间等参数,模型会为所有属性创建相应的索引,提供多维度条件组合查询(包含GEO查询)。其中Identifier是时间线的标识,包含两部分:name部分(监控指标标识)、tags部分(固有不可变参数集合)。
在快递场景中,用户通常是基于快递单号直接定位快递,因而tags使用空的。而属性信息则存储快递的邮寄人信息、收件人信息、邮寄起/止地址等,location字段,用于最新位置追踪,可不定期根据产生新的状态周转数据时更新。

快递轨迹数据
data数据记录着快递的状态周转信息,主要为量化数据、地理位置、文字表述等任意类型。data数据按照+有序排列,因而同一快递的所有数据物理上存在一起,且基于时间有序。这种数据存储方式,极大的提升了时间线的查询效率。对应到快递轨迹,监控数据主要记录了:【who】do【something】@【where】with the location【geo】以及联系方式等。

读写接口使用介绍
写数据
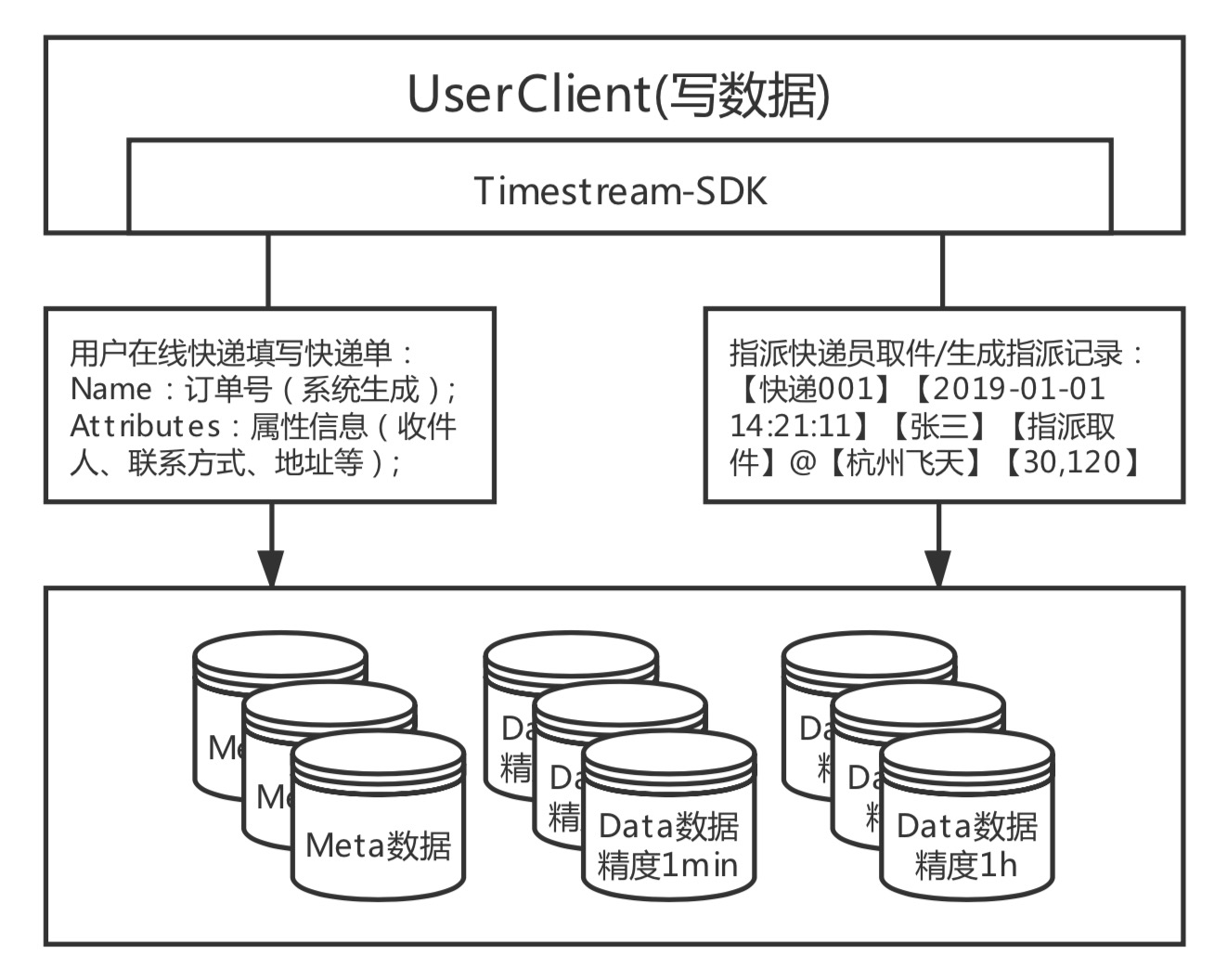
写接口根据数据类型分为两类:meta写入(新增快递)、data写入(快递周转数据)
- 新增快递:当用户通过系统直接下快递单后,产生唯一订单号,加上用户填写的快递单信息组成必要的凯迪数据。此时,就会生成一个时间线,产生一个meta数据;
- 快递周转:当快递发生取件、运输周转、派送、取件是,产生的状态转变数据时,就会产生一条追踪数据,通过data数据的写接口不定期的写入;
读数据
与写数据一样,针对两类数据提供了两类读接口:meta读取(快递查询)、data读取(查询快递轨迹)
- 查询快递:根据快递号、寄件人手机、收件人手机等信息,获取对应快递的列表,掌握所有快递的最新动态;
- 查询快递轨迹:基于单个meta的Identifier,获取该快递从产生到结束整个生命周期内的轨迹周转数据,可以通过列表、地图轨迹展示等方式,直观的了解快递的周转过程;

方案核心代码
SDK与样例代码
SDK使用:
时序模型Timestream模型集成于表格存储的SDK中,目前已在4.11.0版本中支持;
<dependency>
<groupId>com.aliyun.openservices</groupId>
<artifactId>tablestore</artifactId>
<version>4.11.0</version>
</dependency>
代码开源:
https://github.com/aliyun/tablestore-examples/tree/master/demos/MailManagement
建表准备
在创建完成实例后,用户需要通过时序模型的sdk创建相应的meta表(快递元数据)、data表(快递周转数据):
private void init() {
AsyncClient asyncClient = new AsyncClient(endpoint, accessKeyId, accessKeySecret, instance);
//快递抽象Timestream
TimestreamDBConfiguration mailConf = new TimestreamDBConfiguration("metaTableName");
mailDb = new TimestreamDBClient(asyncClient, mailConf);
}
public void createTable() {
mailDb.createMetaTable(Arrays.asList(//自定义索引
new AttributeIndexSchema("fromMobile", AttributeIndexSchema.Type.KEYWORD),
new AttributeIndexSchema("fromName", AttributeIndexSchema.Type.KEYWORD),
new AttributeIndexSchema("toMobile", AttributeIndexSchema.Type.KEYWORD),
new AttributeIndexSchema("toName", AttributeIndexSchema.Type.KEYWORD),
new AttributeIndexSchema("toLocation", AttributeIndexSchema.Type.GEO_POINT)
));
mailDb.createDataTable("dataTableName");
}
写数据
数据写入主要分两部分,meta表创建新快递、data表采集快递周转信息
创建快递单(meta表写入)
//metaWriter对应meta表,提供读、写接口
TimestreamMetaTable mailMetaWriter = mailDb.metaTable();
//identifier作为时间线的身份标识(unique),仅含:快递单号ID,
TimestreamIdentifier identifier = new TimestreamIdentifier.Builder("mail-id-001")
.build();
//基于identifier创建meta对象,并为meta设置更多属性,Attributes为属性参数
TimestreamMeta meta = new TimestreamMeta(identifier)
.addAttribute("fromName", whos.get(Rand.nextInt(whos.size())))
.addAttribute("fromMobile", "15812345678")
.addAttribute("toName", whos.get(Rand.nextInt(whos.size())))
.addAttribute("toMobile", "15812345678")
.addAttribute("toLocation", "30,120");
//创建新的时间线,然后写入监控数据
mailMetaWriter.put(meta);
采集快递周转事件(data表写入)
//dataWriter分别对应data表,提供读、写接口
TimestreamDataTable mailDataWriter = mailDb.dataTable("mailDataTableName");
TimestreamMeta meta;//meta上一步已经构建
//创建新的时间线,然后写入监控数据
mailDataWriter.write(
meta.getIdentifier(),
new Point.Builder(14500000000, TimeUnit.MILLISECONDS)
.addField("who", "张三")
.addField("do", "取件")
.addField("where", "云栖小镇")
.addField("location", "30,120")
.build()
);
数据读取
数据读取分为两类:
快递订单多维查询(meta表读取)
//reader对应meta表,提供读、写接口,此处名字为突出读功能
TimestreamMetaTable metaReader = mailDb.metaTable();
//构建筛选条件
Filter filter = AndFilter(
Name.equal("mail-id-001"),
Attribute.equal("fromMobile", "15812345678")
);
Iterator<TimestreamMeta> metaIterator = mailDb.metaTable()
.filter(filter)
.fetchAll();
while (iterator.hasNext()) {
TimestreamMeta meta = iterator.next();//deal with metas
}
快递轨迹追踪(data表读取)
//dataWriter分别对应data表,提供读、写接口
TimestreamDataTable dataReader = db.dataTable("dataTableName");
TimestreamMeta meta;//基于已获取的meta列表,分别获取每个快递的轨迹追踪
Iterator<Point> dataIterator = mailDb.dataTable(mailDataTableName)
.get(meta.getIdentifier())
.fetchAll();
while (iterator.hasNext()) {
Point point = iterator.next();//deal with points
long timestamp = point.getTimestamp(TimeUnit.MILLISECONDS);//毫秒单位时间戳
String location = point.getField("location").asString();//获取该点String类型的位置信息
}
作者:潭潭
原文链接
本文为云栖社区原创内容,未经允许不得转载。

