我们都知道,离线计算有Hive,使用过的知道,需要先定义一个schema,比如针对HDFS这种存储对标mysql定义一个schema,schema的本质是什么?主要描述下面这些信息
1)当前存储的物理位置的描述
2)数据格式的组成形式
然后Hive可以让用户定义一段sql,针对上面定义的schema进行,sql的本质是什么,是业务逻辑的描述。然后Hive内部会将这段sql进行编译转化为原生的底层MapReduce操作,通过这种方式,屏蔽底层技术原理,让业务开发人员集中精力在schema和sql业务逻辑上,flink sql平台也正是做同样的事情。
一开始经过跟上海同事的讨论,选择Uber的Athenax作为技术选型,通过翻阅源码,发现还是有很多不完善的地方,比如配置文件采用yaml,如果做多集群调度,平台代码优化,多存储扩展机制,都没有考虑得很清楚,所以代码拿过来之后基本上可以说按照对yarn和flink的理解重新写了一遍。
下面是平台代码的思路
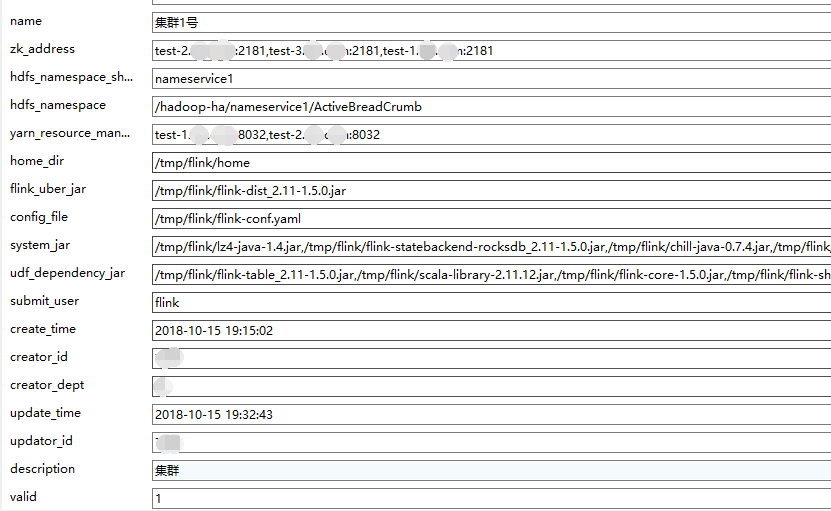
1)通过springboot提供HTTP API,提供多集群定义,存储在mysql里
一个集群需要定义的信息点如下:
2)提供HTTP API让业务进行Job定义
这里的Job定义包含3个方面:job的输出输出的schema定义,job的业务逻辑定义(sql),job需要的yarn资源定义,具体来说如下所示:
Job定义
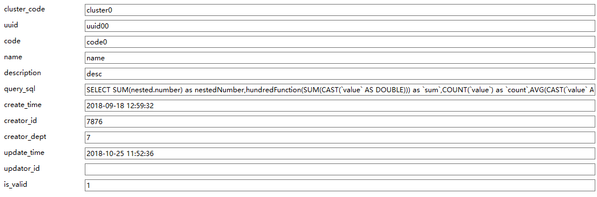
文中的sql定义
SELECT SUM(nested.number) as nestedNumber,
hundredFunction(SUM(CAST(`value` AS DOUBLE))) as `sum`,
COUNT(`value`) as `count`,
AVG(CAST(`value` AS DOUBLE)) as `avg`,
MAX(CAST(`value` AS DOUBLE)) as `max`,
MIN(CAST(`value` AS DOUBLE)) as `min`,
TUMBLE_END(`time`, INTERVAL '3' SECOND) as `time`
FROM input.`ymm-appmetric-dev-self1`
WHERE metric IS NOT NULL AND `value` IS NOT NULL
and `time` IS NOT NULL
GROUP BY metric,TUMBLE(`time`, INTERVAL '3' SECOND)
输入/输出schema定义,以kafka为例,输入和输出格式差不多
{
"brokerAddress":"略",
"topic":"dev-metric",
"schemas":[
{"key":"sum","type":"double"},
{"key":"count","type":"int"},
{"key":"avg","type":"double"},
{"key":"max","type":"double"},
{"key":"min","type":"double"},
{"key":"time","type":"timestamp"},
{"key":"nestedNumber","type":"int"}
]
}
对于业务来说,“打开IDE->了解flink语法写java代码->打包成jar->提交到yarn集群”这一环节省去了,直接打开界面,点击按钮定义sql,写一段业务逻辑sql,提交此业务到mysql,关闭浏览器即可.由平台进行调度(秒级),永远不用担心这个任务某一天挂了怎么办,平台会自动发现自动拉起.提交一次永远不需要再人工干预,除非逻辑发生变化,在逻辑发生变化时也简单,打开任务修改再提交,关闭浏览器,结束,平台会发现job变化杀死老任务拉起新任务.
下面讲一下平台内部是如何实现的
3)集群自动发现
如果平台维护方想增加一个集群,通过界面直接定义一个存在mysql即可,后台线程会自动发现,为每个集群创建一个线程,多节点情况下,整个环境中某个特定集群的多个线程通过ZK进行抢占决定哪个线程当前为这个集群服务.
增加JVM关闭钩子,在JVM退出时,主动关闭ZK客户端,释放ZK上的临时节点.
4)UDF的支持&自动发现
平台支持平台级UDF的定义,由平台人员进行维护,平台人员编写脚本,通过base64编码存在mysql里,归属到某个集群,这个集群的扫描线程发现有必要进行编译时,实时编译成class常驻内存,同时,打包成jar包上传到远程HDFS,后面会将此路径放入到具体job的classpath路径下. job就可以正确发现UDF.
当UDF没有发生变化时,线程不会编译,而是复用上一次的编译结果.
5)程序可以任意部署,不依赖大数据环境
程序本身不依赖大数据环境的配置,具体是指不需要依赖当前宿主机.../etc/hadoop/*.xml文件
通过读取cluster的配置,动态生成XML配置,再生成HDFS/YARN的客户端client,这样,平台代码可以任意部署到物理机/容器中,只要环境可以通过TCP连接到对应域名/ip即可.
6)如何做任务调度-任务的自动发现
这里的任务调度是指:哪些任务需要下线,哪些任务需要第一次上线,哪些任务需要重新上线,
这里的业务逻辑就是比较mysql里job的时间戳和yarn集群里任务的时间戳
yarn集群里任务的时间戳是通过提交时打上Tag标记,就是为了下一次比较用。
这里有一个细节,就是Athenax的做法是先算出所有要杀死的任务,杀死,再拉起所有要拉起的任务,个人认为这里不妥,优化之后的做法是:按照任务级别,算出(killaction,startaction),对于单个job来说,二者至少存在1个action,然后以任务为级别进行调度,不再是之前的大一统提交方式,这样就算单个任务调度异常,也不影响其它任务,做到了任务之间做隔离.
通过时间戳的方式,就不难理解业务一旦修改任务,平台发现时间戳有变化,就可以自动杀死老任务,拉起新任务,不需要人工操作.
7)拉起任务中的编译工作
一个job需要拉起时,会实时结合(输入schema,SQL业务逻辑,输出schema)进行编译,
正如hive会翻译成原生的mapreduce操作,flink sql编译工作会翻译成原生的flink jobgraph
这部分是抽取了athenax里的编译工作做2开
代码如下:
private JobCompilerResult compile(Map inputs, String originSql,
ExternalCatalog output, ResourceDTO resourceDTO,
ClusterDTO athenaxCluster,
Configuration flinkConf) throws Exception {
// 解析sql
LoggerUtil.info("to be compiled sql : [{}]", originSql);
SqlNodeList stmts = (SqlNodeList) new CalciteSqlParser().parse(originSql);
Validator validator = new Validator();
validator.validateQuery(stmts);
HashMap udfMap = validator.getUserDefinedFunctions();
String selectSql = validator.getStatement().toString();
List additionalResources = validator.getAdditionalResources();
LoggerUtil.info("succeed to parse sql,result is : [{}]", stmts);
LoggerUtil.info("udf {}", udfMap);
LoggerUtil.info("statement {}", selectSql);
LoggerUtil.info("additionalResources {}", additionalResources);
// 准备编译,输出Flink的JobGraph
LoggerUtil.info("begin to create execution environment");
StreamExecutionEnvironment localExecEnv = StreamExecutionEnvironment
.createLocalEnvironment();
//非常重要
setFeature(localExecEnv,
resourceDTO.getTaskManagerCount() * resourceDTO.getSlotPerTaskManager(), flinkConf);
StreamTableEnvironment tableEnv = StreamTableEnvironment.getTableEnvironment(localExecEnv);
LoggerUtil.info("tableEnv : {} ", tableEnv);
// 注册UDF,收归到平台了,也就是说,只支持平台开发人员预定义,暂时不支持业务自定义
for (Map.Entry e : udfMap.entrySet()) {
final String name = e.getKey();
String clazzName = e.getValue();
LoggerUtil.info("used udf specified by business : {}", name);
}
registerSDF(athenaxCluster, tableEnv);
LoggerUtil.info("all udf registerd , bingo");
// 开始注册所有的input相关的schema
for (Map.Entry e : inputs.entrySet()) {
LoggerUtil.info("Registering input catalog {}", e.getKey());
tableEnv.registerExternalCatalog(e.getKey(), e.getValue());
}
LoggerUtil.info("all input catalog registerd , bingo");
Table table = tableEnv.sqlQuery(selectSql);
LoggerUtil.info("succeed to execute tableEnv.sqlQuery(...)");
LoggerUtil.info("table {}", table);
LoggerUtil.info("bingo! input work done completely,let us handle output work now!!!");
// 开始注册output
List outputTables = output.listTables();
for (String t : outputTables) {
table.writeToSink(getOutputTable(output.getTable(t)));
}
LoggerUtil.info("handle output ok");
// 生成JobGraph
StreamGraph streamGraph = localExecEnv.getStreamGraph();
JobGraph jobGraph = streamGraph.getJobGraph();
// this is required because the slots are allocated lazily
//如果为true就会报错,然后flink内部就是一直重启,所以设置为false
jobGraph.setAllowQueuedScheduling(false);
LoggerUtil.info("create flink job ok {}", jobGraph);
JobGraphTool.analyze(jobGraph);
// 生成返回结果
JobCompilerResult jobCompilerResult = new JobCompilerResult();
jobCompilerResult.setJobGraph(jobGraph);
ArrayList paths = new ArrayList();
Collection values = udfMap.values();
for (String value : values) {
paths.add(value);
}
jobCompilerResult.setAdditionalJars(paths);
return jobCompilerResult;
}
这部分工作要理解,需要对Calcite有基础
8)多存储的支持
平台在一开始编写的时候,就考虑到了多存储支持,虽然很多任务是从kafka->计算->Kafka
但是平台并不只满足于这一点,因为写到kafka之后,可能还需要业务再去维护一段代码取读取kafka的消息进行消费,如果有的业务希望直接能把结果写到mysql,这个时候就是需要对多存储进行扩展
通过设计和扩展机制,平台开发人员只需要定义储存相关的类,针对schema定义的解析工作已经再父类中完成,所有存储类共用,这样可以灵活支持多存储,平台开发人员只需要把重点放在特定存储性质的支撑即可.
PS:编写此类存储类需要对fink job内部的运行机制,否则会造成资源泄露和浪费.
平台内部已经针对每种类型进行了定义
// 存储类型
//排名不分先后
public static int STORAGE_REDIS = 1 << 0; //1
public static int STORAGE_MYSQL = 1 << 1; //2
public static int STORAGE_ROCKETMQ = 1 << 2; //4
public static int STORAGE_KAFKA = 1 << 3; //8
public static int STORAGE_PULSAR = 1 << 4; //16
public static int STORAGE_OTHER0 = 1 << 5; //32
public static int STORAGE_OTHER1 = 1 << 6; //64
public static int STORAGE_OTHER2 = 1 << 7; //128
public static int STORAGE_RABBITMQ = 1 << 8; //256
public static int STORAGE_HBASE = 1 << 9; //512
public static int STORAGE_ES = 1 << 10;//1024
public static int STORAGE_HDFS = 1 << 11;//2048
目前支持的情况如下:
输入:Kafka
输出:Kafka/Mysql
PS:输出mysql是基于flink官方的提供类实现的第一版,经过分析源码,mysql sink官方这部分代码写得太随意,差评.
后续当业务有需求时,需要结合zebra做2次开发.毕竟运维不会提供生产环境的ip和端口等信息,只会提供一个数据源字符串标识.这样更贴合公司内部的运行环境
9)任务提交
一旦生成flink原生的job,就可以准备提交工作
这部分需要对yarn的运行机制比较清楚,比如任务提交到RM上经过哪些状态变化,ApplicationMaster如何申请资源启动TaskManager, 具体的job是如何提交给JobManager的,平台开发人员需要对此有基本的原理掌握,当初也是0基础开始学习,通过快速翻阅源代码掌握一些运行机制,方可安心进行平台开发.
10)其它优化
针对yarn client的参数优化,保证可在一定时间内返回,否则可能一直卡死
针对flink job的平台级优化,比如禁止缓存,让信息立刻传输到下一个环节(默认100毫秒延迟)
定义flink job的重启次数,当发生异常时可自行恢复等
11)压测结果
输入:本地启动7个线程,发送速度
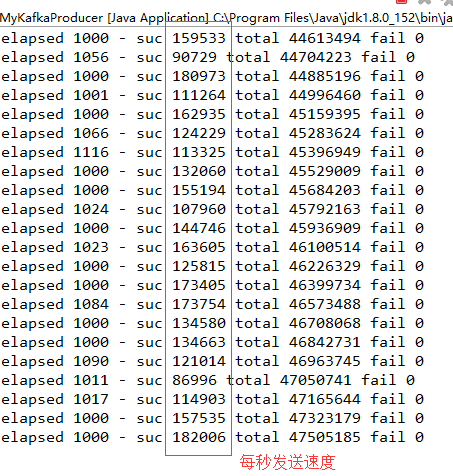
每秒发送到kafka 十几万条
接收topic描述
ymm-appmetric-dev-self1 开发环境 partitions 6 replication 1
flink任务描述
2个TaskManager进程 每个进程800M内存 每个进程3个线程,
并行度 2*3=6
flink计算任务所用sql
SELECT SUM(nested.number) as nestedNumber,
hundredFunction(SUM(CAST(`value` AS DOUBLE))) as `sum`,
COUNT(`value`) as `count`,
AVG(CAST(`value` AS DOUBLE)) as `avg`,
MAX(CAST(`value` AS DOUBLE)) as `max`,
MIN(CAST(`value` AS DOUBLE)) as `min`,
TUMBLE_END(`time`, INTERVAL '3' SECOND) as `time`
FROM input.`ymm-appmetric-dev-self1`
WHERE metric IS NOT NULL AND `value` IS NOT NULL and `time` IS NOT NULL
GROUP BY metric, TUMBLE(`time`, INTERVAL '3' SECOND)
输出topic
ymm-appmetric-dev-result partitions 3
观察flink consumer端的消费速度
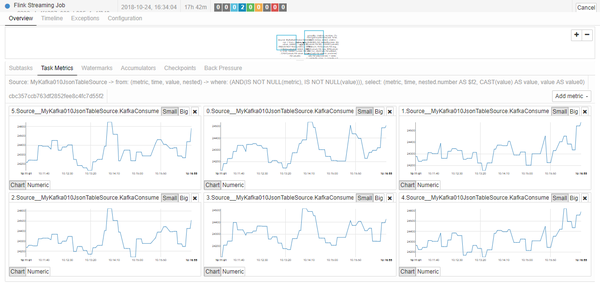
每个线程的消费速度在24000上下浮动,并发度6,每秒可消费kafka消息14万+,应该说目前不会碰到性能瓶颈.
其它
本次测试发送数据条数:4.3 亿条
耗时:56分钟
对于业务开发人员来说,我觉得好处就是
1)不需要懂flink语法(你真的想知道flink的玩法?好吧我承认你很好学)
2)不需要打开IDE写java代码(你真的想写Java代码?好吧我承认你对Java是真爱)
3)提交一次,不再需要人工介入(你真的想在假期/晚上/过节/过年 担心任务挂掉?好吧我承认你很敬业)
只需要
1)界面点击操作,定义你的schema
2)写一段你所擅长的sql
3)点击提交按钮
4)关闭浏览器
5)关闭电脑
其它的就交给平台吧!
后续:针对平台来说,后续的主要工作是根据业务需求扩展多存储
如果再长远,那就是要深度阅读flink源码对平台进行二次优化

