1.开始前准备
1.1 python3,本文代码使用Python3来写。没有安装Python3的童鞋请先安装Python3哦
1.2 requests库,Requests 是用Python语言编写,基于 urllib,采用 Apache2 Licensed 开源协议的 HTTP 库。它比 urllib 更加方便,可以节约我们大量的工作,完全满足 HTTP 测试需求。
下载方法:
pip install requests
1.3 pycharm,一款功能强大的PythonIDE!下载官方版本后,使用license sever免费使用(同系列产品类似),具体参照http://www.cnblogs.com/hanggegege/p/6763329.html。
2.爬取分析
我们的目标是实现一个能够代替淘宝搜索获取商品信息的脚本,那么我们先来分析分析具体应该如何实现吧!
我们尝试一下通过网页上的“搜索”按钮来获取一些信息。我们随便输入一个商品名称:电脑
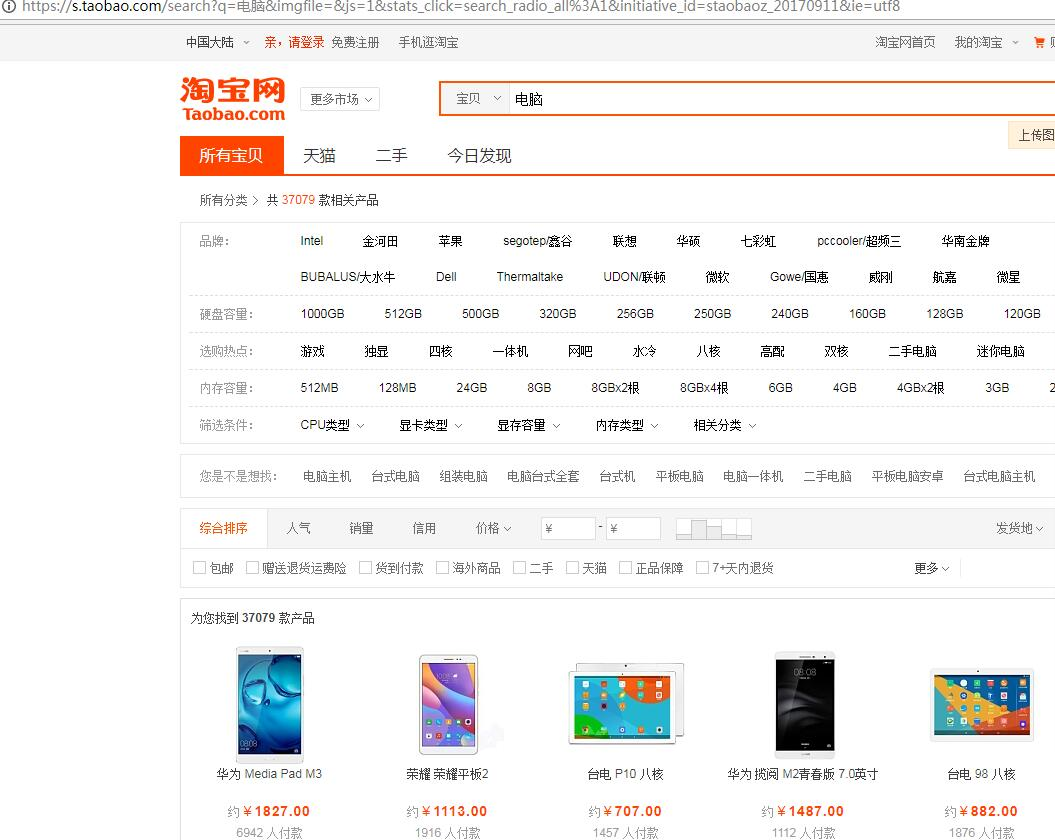
重复几次相同操作查询不同名称商品后,我们发现了一些规律,通过观察url参数我们发现,只要在https://s.taobao.com/search?q=后面加上你需要查询的商品名称就能获取你想要的淘宝商品信息了!我们就以这个为突破口,去写目标脚本吧!
3.代码过程分析与演示
首先我们导入所需要的库:
import requests import re
我们先来看看电脑信息页面的源代码,去发现其中商品信息的规律,再用正则表达式去实施全局匹配,右键上图页面查看源代码:
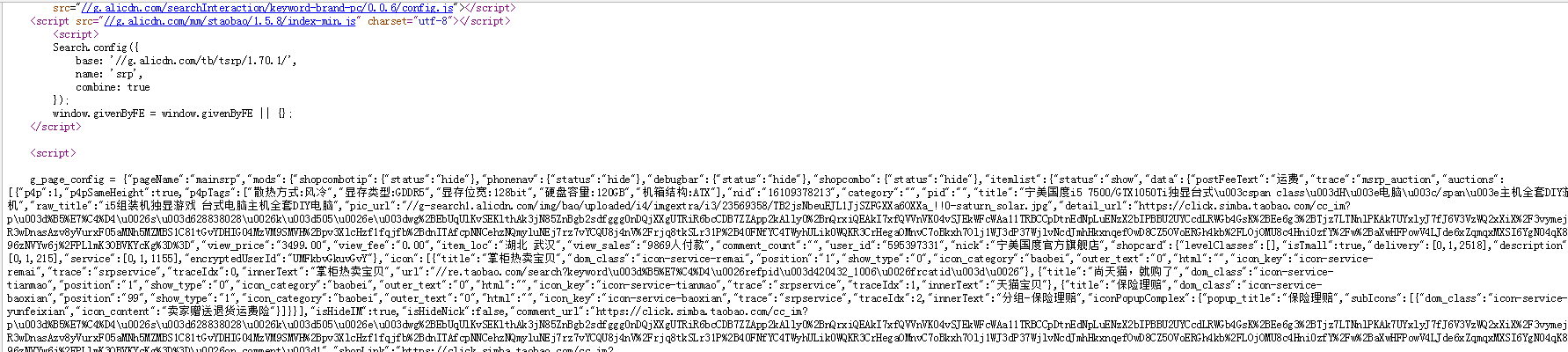
仔细观察这段代码,通过对一组数据的分析得到:商品名称在raw_title当中,商品价格view_price当中,通过这个规律 ,我们来写两个正则表达式,匹配页面上的所有商品价格与名称!
我们先来写个函数获取网页代码信息:
def getHTMLText(url): try: r = requests.get(url) r.raise_for_status() r.encoding = r.apparent_encoding return r.text #这几行不懂的可以去查查requests库的文档哦 except: return ""
接着,我们再写个函数把获取商品信息:
def parsePage(ilt, html): try: plt = re.findall(r'\"view_price\"\:\"[\d\.]*\"', html) #本文代码的精髓就在这两行了 tlt = re.findall(r'\"raw_title\"\:\".*?\"', html) for i in range(len(plt)): price = eval(plt[i].split(':')[1]) title = eval(tlt[i].split(':')[1]) ilt.append([price, title]) except: print("")
最后,我们需要写个函数把商品信息列出来:
def printGoodsList(ilt): tplt = "{:4}\t{:8}\t{:16}" print(tplt.format("序号", "价格", "商品名称")) count = 0 for g in ilt: count = count + 1 print(tplt.format(count, g[0], g[1]))
现在我们来写个main()函数来测试我们的代码吧!
def main(): goods = input('请输入要查找的商品名称:') depth = 3 #爬取的页码深度,可以自己调哦 start_url = 'https://s.taobao.com/search?q=' + goods infoList = [] for i in range(depth): try: url = start_url + '&s=' + str(44 * i) #去翻页看看url的变化就知道为什么这么些了 html = getHTMLText(url) parsePage(infoList, html) except: continue printGoodsList(infoList)
项目完整代码:
import requests import re def getHTMLText(url): try: r = requests.get(url, timeout=30) r.raise_for_status() r.encoding = r.apparent_encoding return r.text except: return "" def parsePage(ilt, html): try: plt = re.findall(r'\"view_price\"\:\"[\d\.]*\"', html) tlt = re.findall(r'\"raw_title\"\:\".*?\"', html) for i in range(len(plt)): price = eval(plt[i].split(':')[1]) title = eval(tlt[i].split(':')[1]) ilt.append([price, title]) except: print("") def printGoodsList(ilt): tplt = "{:4}\t{:8}\t{:16}" print(tplt.format("序号", "价格", "商品名称")) count = 0 for g in ilt: count = count + 1 print(tplt.format(count, g[0], g[1])) def main(): goods = input('请输入要查找的商品名称:') depth = 3 start_url = 'https://s.taobao.com/search?q= ' + goods infoList = [] for i in range(depth): try: url = start_url + '&s=' + str(44 * i) html = getHTMLText(url) parsePage(infoList, html) except: continue printGoodsList(infoList) main()
我们来看看运行效果图:

大功告成!
(ps:本文代码参照中国慕课网课程)
谢谢观看!

