前言
注(es官方api文档):https://www.elastic.co/guide/en/elasticsearch/client/index.html
Elasticsearch 5.5 入门必会(一)
一、Java项目构建
- 客户端调用Maven依赖,客户端我配置的是slf4j+log4j2,配置太多就不贴上来了
<dependency> <groupId>org.elasticsearch</groupId> <artifactId>elasticsearch</artifactId> <version>5.5.1</version> </dependency> <!-- 这个一定要引入,这是使用transport的jar --> <dependency> <groupId>org.elasticsearch.client</groupId> <artifactId>transport</artifactId> <version>5.5.1</version> </dependency> <!-- es 的jar 对guava有依赖 --> <dependency> <groupId>com.google.guava</groupId> <artifactId>guava</artifactId> <version>18.0</version> </dependency>
- Java连接ES 节点代码如下
Settings settings = Settings.builder() //集群名称 .put("cluster.name", "onesearch") //自动嗅探 .put("client.transport.sniff", true) .put("discovery.type", "zen") .put("discovery.zen.minimum_master_nodes", 1) .put("discovery.zen.ping_timeout", "500ms") .put("discovery.initial_state_timeout", "500ms") .build(); Client client = new PreBuiltTransportClient(settings) .addTransportAddress(new InetSocketTransportAddress(InetAddress.getByName(ip), 9300));
启动程序不报错就代表您已经成功和ES建立连接。
二、Java客户端操作索引数据
- 入门时期看官方文档心中会冒出“麻买皮”三个字,因为官方文档有时候给你一个冷不丁的例子,有时候干脆贴除了Rest方式的JSON代码,万只草泥马没有在奔跑,正在疯狂吃草,Java API方式实际上也是拼装了JSON字符串,然后通过netty去和ES通信,对比http的方式访问的话SDK可以自动嗅探节点还是不错的,一个节点挂了还能用另外一个,http因为制定了单个IP,所以没有这个优势
实例一:我怎样写数据到ES里面去
/** * ES的基本类型可以去官网查看 * 如果您使用map的方式去写入数据并且创建索引,es会自动根据map的value数据类型来自动转换 * 比如age是int,es里面使用有integer,不赘述 * 使用map有个大缺陷(除非自己封装对象保存),当你保存java.util.Date类型进去的时候ES会全部转成UTC来保存 * 这个只能通过后面的api方式定义索引field的一些属性来指定才行 **/ @Test public void createData() { Map<String, Object> map = new HashMap<String, Object>(); // map.put("name", "Smith Wang"); map.put("name", "Smith Chen"); // map.put("age", 20); map.put("age", 5); // map.put("interests", new String[]{"sports","film"}); map.put("interests", new String[] { "reading", "film" }); // map.put("about", "I love to go rock music"); map.put("about", "I love to go rock climbing"); IndexResponse response = client.prepareIndex("megacorp", "employee", UUID.randomUUID().toString()) .setSource(map).get(); System.out.println("写入数据结果=" + response.status().getStatus() + "!id=" + response.getId()); }
- 说明:prepareIndex第一个参数是 index(索引) ,第二个是type(类型),第三个是记录ID(不推荐使用UUID,后面会说)
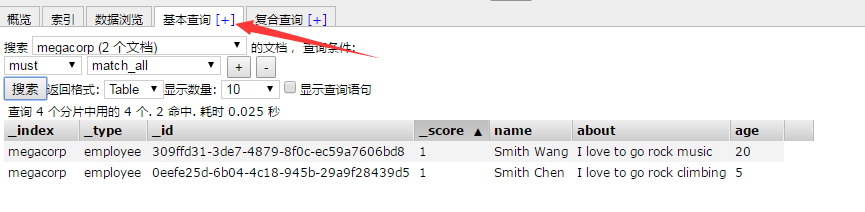
然后在基本查询里面就可以查到你刚刚插入的数据了
---------------------------------------------------------------------------------------------------
实例二:我怎样从ES中根据字段来查询数据(其实我的实例都是根据Elasticsearch权威指南上翻译过来的,因为书中全部都是rest方式,不是Java api方式)
/** * match使用,会被分词查询 */ @Test public void match() { SearchRequestBuilder requestBuilder = client.prepareSearch("megacorp").setTypes("employee") .setQuery(QueryBuilders.matchQuery("about", "rock climbing")); System.out.println(requestBuilder.toString()); SearchResponse response = requestBuilder.execute().actionGet(); System.out.println(response.status()); if (response.status().getStatus() == 200) { for (SearchHit hits : response.getHits().getHits()) { System.out.println(hits.getSourceAsString()); } } }
OK,这些都是最基本的操作了!看似没有难度
三、通过Java API编写复杂的查询语句
/** * matchphrase使用,短语精准匹配 * 不使用matchPhraseQuery会导致 rock climbing被拆分查询 */ @Test public void matchPhrase() { SearchRequestBuilder requestBuilder = client.prepareSearch("megacorp").setTypes("employee") .setQuery(QueryBuilders.matchPhraseQuery("about", "rock climbing")); System.out.println(requestBuilder.toString()); SearchResponse response = requestBuilder.execute().actionGet(); System.out.println(response.status()); if (response.status().getStatus() == 200) { for (SearchHit hits : response.getHits().getHits()) { System.out.println(hits.getSourceAsString()); } } }
@Test public void highlight() { HighlightBuilder highlightBuilder = new HighlightBuilder(); // highlightBuilder.preTags(FragmentSettings.prefix);//设置前缀 // highlightBuilder.postTags(FragmentSettings.subfix);//设置后缀 highlightBuilder.field("about"); // highlightBuilder.fragmenter(FragmentSettings.SPAN) // .fragmentSize(FragmentSettings.HIGHLIGHT_MAX_WORDS).numOfFragments(5); SearchRequestBuilder requestBuilder = client.prepareSearch("megacorp").setTypes("employee") .setQuery(QueryBuilders.matchPhraseQuery("about", "rock climbing")).highlighter(highlightBuilder); System.out.println(requestBuilder.toString()); SearchResponse response = requestBuilder.execute().actionGet(); System.out.println(response.status()); if (response.status().getStatus() == 200) { for (SearchHit hits : response.getHits().getHits()) { System.out.println(hits.getSourceAsString()); // 这里使用hight field来覆盖source里面的字段即可 System.out.println(hits.getHighlightFields()); } } }
@Test public void aggregation() { SearchRequestBuilder searchBuilder = client.prepareSearch("megacorp").setTypes("employee") .addAggregation(AggregationBuilders.terms("by_interests").field("interests") .subAggregation(AggregationBuilders.terms("by_age").field("age")).size(10)); System.out.println(searchBuilder.toString()); SearchResponse response = searchBuilder.execute().actionGet(); if (response.status().getStatus() == 200) { for (SearchHit hits : response.getHits().getHits()) { System.out.println(hits.getSourceAsString()); } } StringTerms terms = response.getAggregations().get("by_interests"); for (StringTerms.Bucket bucket : terms.getBuckets()) { System.out.println("-interest:" + bucket.getKey() + "," + bucket.getDocCount()); if (bucket.getAggregations() != null && bucket.getAggregations().get("by_age") != null) { LongTerms ageTerms = bucket.getAggregations().get("by_age"); for (LongTerms.Bucket bucket2 : ageTerms.getBuckets()) { System.out.println("--------by age:" + bucket2.getKey() + "," + bucket2.getDocCount()); } } } }
/** * 聚合类+求平均年龄 * 求和使用AggregationBuilders.sum * 注意AggregationBuilders.terms("by_interests") by_interests是分组的一个key,返回结果时你根据key反 * 过来取值即可 */ @Test public void aggregationAvg() { SearchRequestBuilder searchBuilder = client.prepareSearch("megacorp").setTypes("employee") .addAggregation(AggregationBuilders.terms("by_interests").field("interests") .subAggregation(AggregationBuilders.avg("avg_age").field("age")).size(10)); System.out.println(searchBuilder.toString()); SearchResponse response = searchBuilder.execute().actionGet(); if (response.status().getStatus() == 200) { for (SearchHit hits : response.getHits().getHits()) { System.out.println(hits.getSourceAsString()); } } StringTerms terms = response.getAggregations().get("by_interests"); for (StringTerms.Bucket bucket : terms.getBuckets()) { System.out.println("-interest:" + bucket.getKey() + "," + bucket.getDocCount() + ","); InternalAvg agg = bucket.getAggregations().get("avg_age"); System.out.println("---------avg age:" + agg.value() + ",count=" + agg.getValueAsString()); } }
四、通过Java API进行索引操作
- 下面是官方给出的创建索引,并且指定字段类型的操作,这里很“麻买皮”
@Test public void createIndexInfo() { client.admin().indices().prepareCreate("megacorp") .setSettings(Settings.builder().put("index.number_of_shards", 4).put("index.number_of_replicas", 1)) .addMapping("employee", "{\n" + " \"properties\": {\n" + " \"age\": {\n" + " \"type\": \"integer\"\n" + " },\n" + " \"name\": {\n" + " \"type\": \"text\"\n" + " },\n" + " \"interests\": {\n" + " \"type\": \"text\",\n" + " \"fielddata\": true\n" + " },\n" + " \"about\": {\n" + " \"type\": \"text\"\n" + " }\n" + " }\n" + "}", XContentType.JSON) .get(); }
- 当然,官方也给出了一个比较优雅的解决方案(XContentBuilder),如下
XContentBuilder mapping = JsonXContent.contentBuilder() .startObject() .startObject("productIndex") .startObject("properties") .startObject("title").field("type", "string").field("store", "yes").endObject() .startObject("description").field("type", "string").field("index", "not_analyzed").endObject() .startObject("price").field("type", "double").endObject() .startObject("onSale").field("type", "boolean").endObject() .startObject("type").field("type", "integer").endObject() .startObject("createDate").field("type", "date").endObject() .endObject() .endObject() .endObject(); 相当于: { { "productIndex":{ "properties": { "title":{ "type":"string", "store":"yes" } }, .. } } }
总的来说,这种解决方式会比拼接字符串好一点,不会感觉很low
- 完整的API方式创建索引(这里麻烦凑合看下,因为我做了一个从关系数据库抽取数据写到ES的完整操作),看一下重点关注代码行即可,我其实做了XML相关的改造,将数据库字段映射成ES字段操作,您先关注简单的创建流程
@Test public void createIndexWithXML() throws Exception { //重点关注代码行 IndicesExistsRequestBuilder indices = client.admin().indices().prepareExists("test"); List<SqlMappingConfig> mappingList = ElasticXMLReader.getSearchInfoList(); //重点关注代码行 if(!indices.execute().actionGet().isExists()) { //重点关注代码行 XContentBuilder builder = JsonXContent.contentBuilder(); builder.startObject().startObject("properties"); SqlMappingConfig mapping = mappingList.get(0); for(Column column : mapping.getSearchInfo().getColumns()) { builder.startObject(column.getAttriMap().get("index-column")); for(Entry<String, String> entry : column.getAttriMap().entrySet()) { if(!entry.getKey().equals("index-column") && !entry.getKey().equals("sql-column")) { builder.field(entry.getKey().equals("data-type")?"type":entry.getKey(), entry.getValue()); } } builder.endObject(); } builder.endObject().endObject(); //重点关注代码行 PutMappingRequest mappingRequest = Requests.putMappingRequest(mapping.getSearchInfo().getIndex()).type(mapping.getSearchInfo().getType()); mappingRequest.source(builder); //重点关注代码行 CreateIndexResponse response = client.admin().indices().prepareCreate(mapping.getSearchInfo().getIndex()) .setSettings(Settings.builder().put("index.number_of_shards", 8).put("index.number_of_replicas", 1)) .addMapping(mapping.getSearchInfo().getType(), mappingRequest.source(),XContentType.JSON).execute().actionGet(); System.out.println(response.isAcknowledged()); } }
最后
很多人有洁癖,喜欢用纯SDK代码方式来操作API,我也踩了无数的坑,上面的代码都是我一步步试出来的,之前加了一个es的学习群,但是不知道是不是我问的问题太简单了,在里面问问题都没有人指导,后来很遗憾的退出了那个群。不过很感谢那个群,我学到了一个东西,就是Elasticsearch-sql工具,这个工具支持关系型数据库的语句转 es的查询参数,很方便! 通过生成的json参数,可以反过来照抄来写Java代码(虽然很别扭,但是已经很不错了)
后面我会写一篇关于关系型数据库的查询语句 变成 ES Java代码的样例出来,还请关注

