现如今城市生活节奏越来越快,用户在浏览一些视频时,并不想花费大量的时间来看一个完整的视频。更多时候,用户只想知道这个视频最精华的信息,也是基于这种需求,谷阿莫等影视评论者才得到如此多的关注。此时,视频摘要就体现出其价值所在了。
什么是视频摘要?
视频摘要,就是以自动或半自动的方式,通过分析视频的结构和内容存在的时空冗余,从原始视频中提取有意义的片段/帧。从摘要的技术处理过程来讲,视频摘要一般可以分成两种,静态视频摘要和动态视频摘要。现阶段,我们公司主要致力于静态视频摘要的研究。接下来就和大家说一下静态视频摘要。
什么是静态视频摘要?
静态视频摘要,又称为视频概要,即用一系列从原始视频流中抽取出来的静态语义单元来表示视频内容的技术。简单来说,就是在一段视频中提取出一些关键帧,通过将多个关键帧组合成视频摘要,使用户可以通过少量的关键帧快速浏览原始视频内容。进一步发展的话可以为用户提供快速的内容检索服务。
例如,公开课的视频中,提取出含有完整PPT的帧。我们将含有关键信息的所有帧提供给浏览者,可以使其在较短的时间内了解到较长视频的主要内容。又例如,将一个2小时的电影提取出其关键部分,组合成一个2分钟的预告片,也属于静态视频摘要。其提取流程大致如下:

静态视频摘要技术简介
静态视频摘要通过描述原始视频中的每帧图像的特征,通过对帧间的特征差异值比较,抽取出原始视频的关键帧。故,静态视频摘要的第一步,需要获取帧信息特征。
关于图片的特征提取,从2012年的AlexNet,到2014年的VGGNet和GoogleNet,几年的ILSVRC(ImageNet大规模视觉识别挑战赛)已经使得图片分类和特征提取达到了近乎完美的境界。静态视频摘要中的图片摘要工作基本无需耗费时间,利用已有的图片分类网络,提取出视频每一帧的图片特征信息,就可以解决。

(图片来源:http://www.jianshu.com/p/58168fec534d )
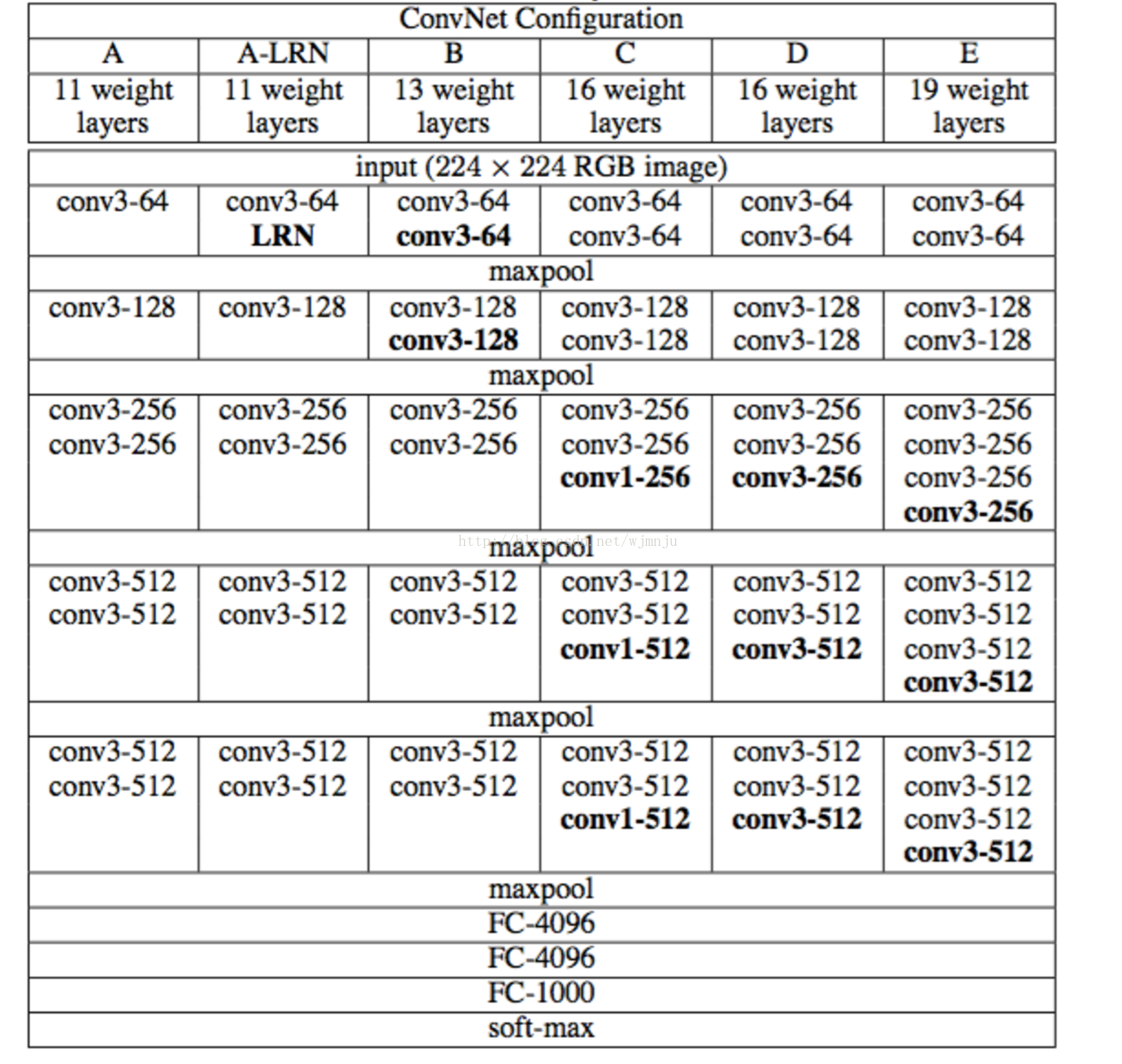
(VGG网络结构图,图片来源: http://x-algo.cn/index.php/2017/01/08/1471/ )
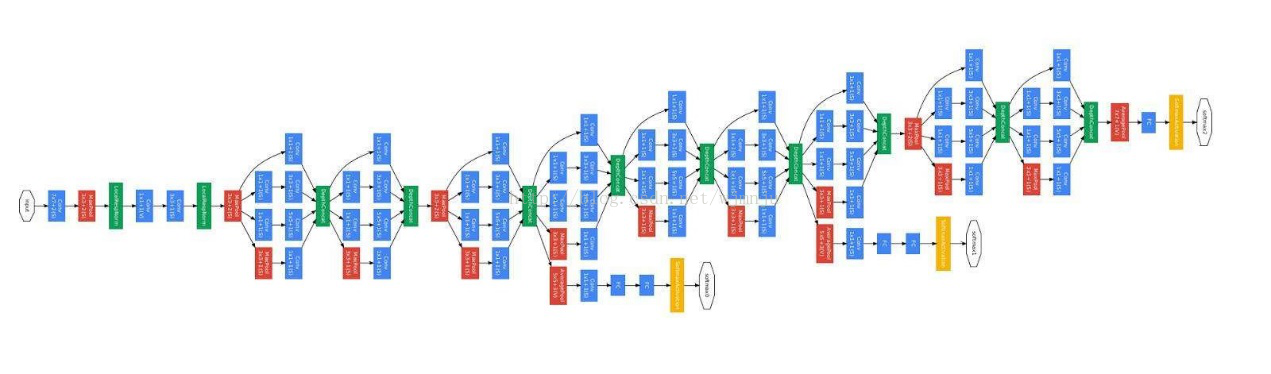
(Googlenet模型,Google官方论文配图)
但是人们在阅读一篇文章或观看一段视频的时候,往往不是根据单一的帧或单词进行理解,而是需要与前面所看过的内容相结合,完成对整体内容的理解。传统的神经网络不能做到这点,因此,在视频文本摘要中,往往需要一种特殊的神经网络——Recurrent Neural Networks(循环神经网络)。RNN是一种具有循环结构的网络,它可以持续保存前面的信息,其大致网络结构如下图:
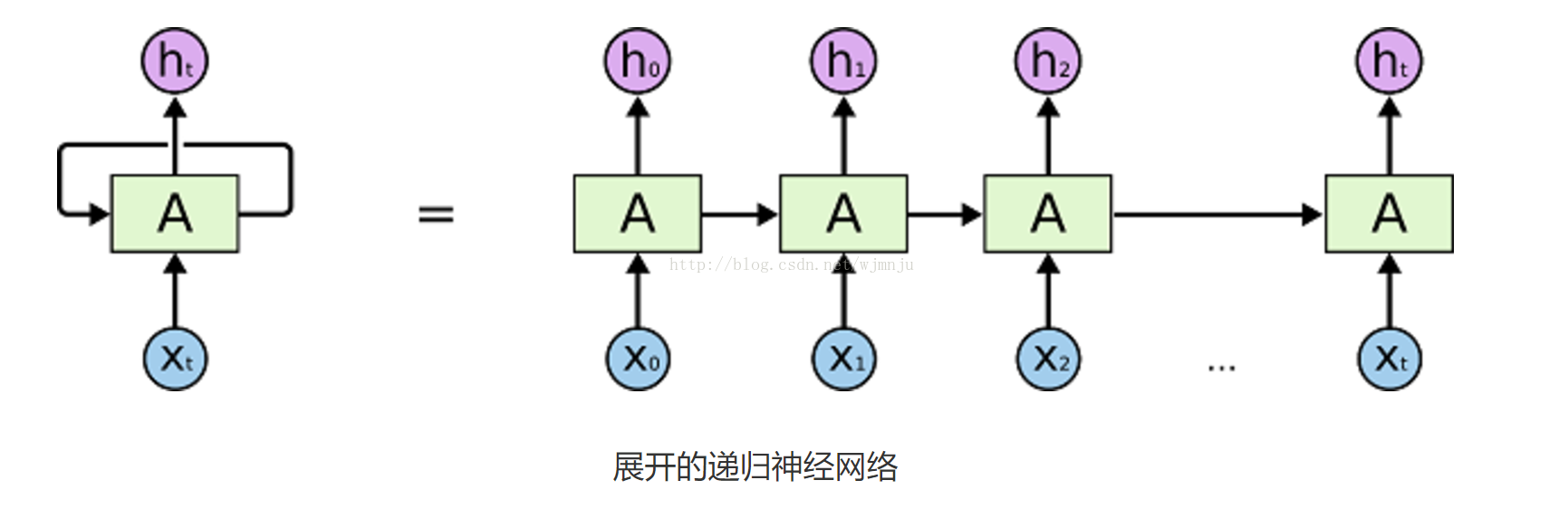
这样的一个神经网络,可以在做视频文本摘要中,保留一部分前文的信息,达到衔接上下文关系的目的。因此,它被广泛运用在文本类、摘要类的实验中。
但传统的RNN网络依旧存在其弊端,它无法连接到较远的前文信息。例如,当我们需要预测“I grew up in France... I speak fluent French”中的最后一个词“French”,我们需要与距离当前文较远的“France”取得联系,但是,当两个词间隔十分大的时候,RNN就会丧失远距离的学习能力。这个问题被称为“长期依赖问题”。
为了解决这个问题,一种新的网络被提出:Long Short Term 网络,简称LSTM,是一种特殊的循环神经网络,它由Hochreiter & Schmidhuber提出,被认为可以解决RNN所不能解决的长期依赖问题。与RNN不同,它利用一个叫做“输入门限层”的sigmoid层来决定需要丢弃或更新的值,在每一步中状态,保证各个信息实时存在且为最新的状态。这样的网络被广泛应用于需要上下文相关的实验模型中。
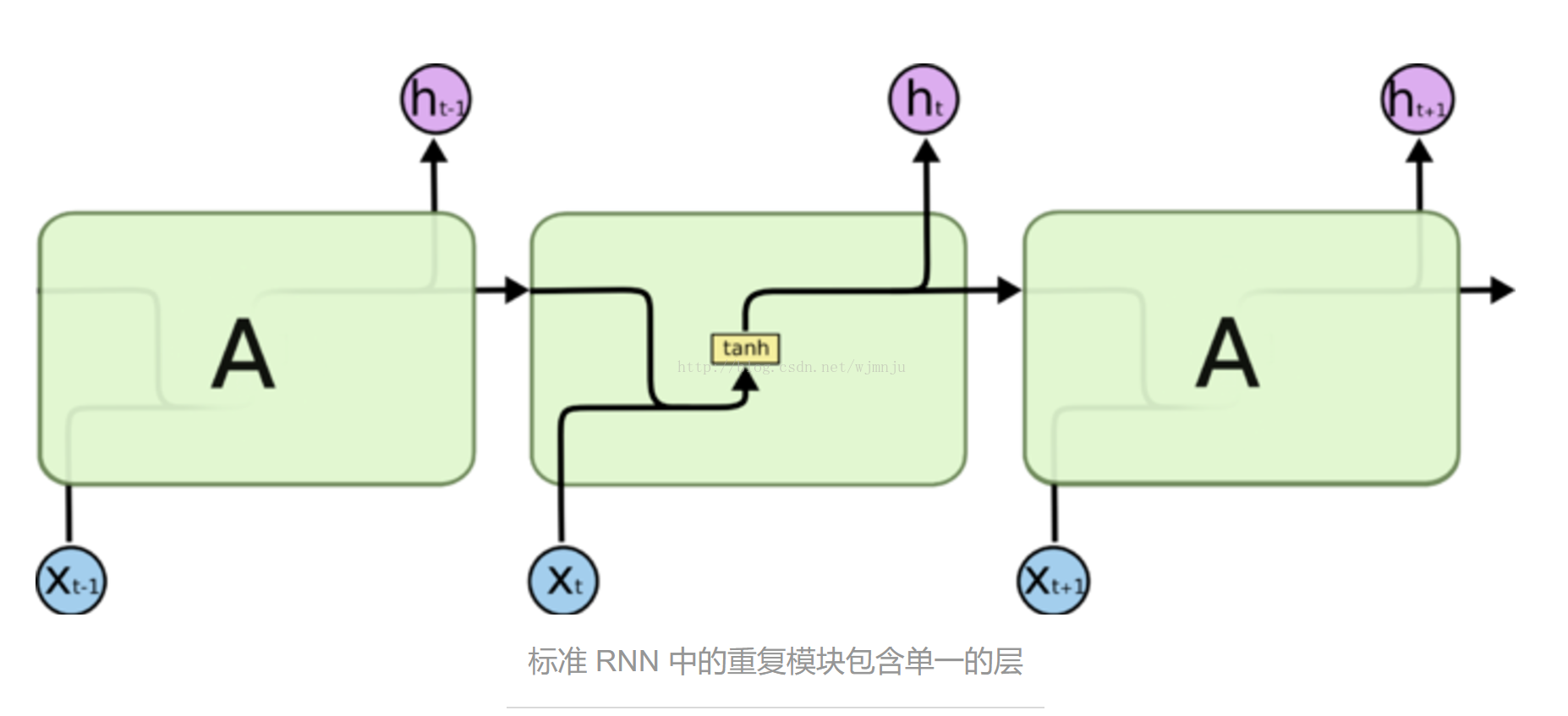
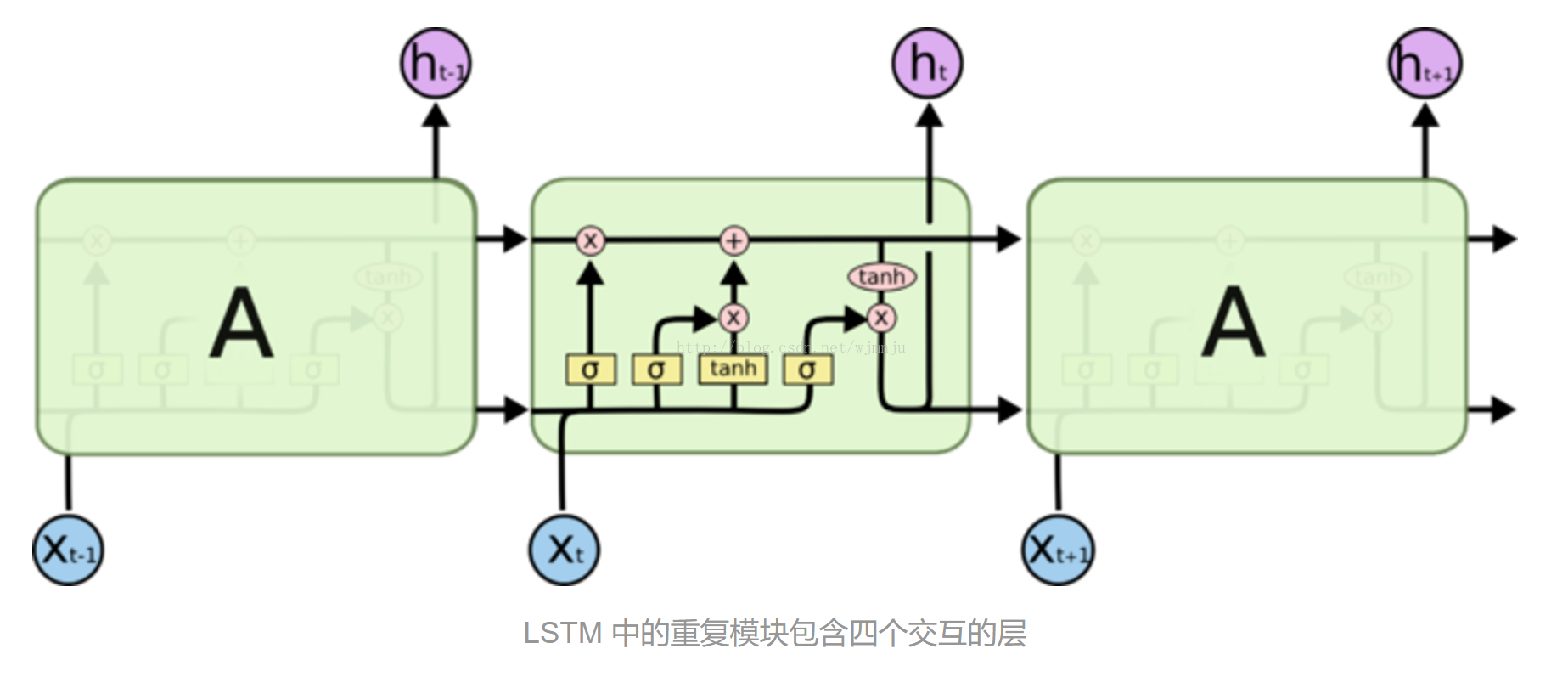
静态视频摘要的过程:
下面我们用一个例子来简述静态视频摘要的过程。2016年CVPR的文章《Video Summarization with Long Short-term Memory》就利用了LSTM来完成视频摘要。其主要模型如下:
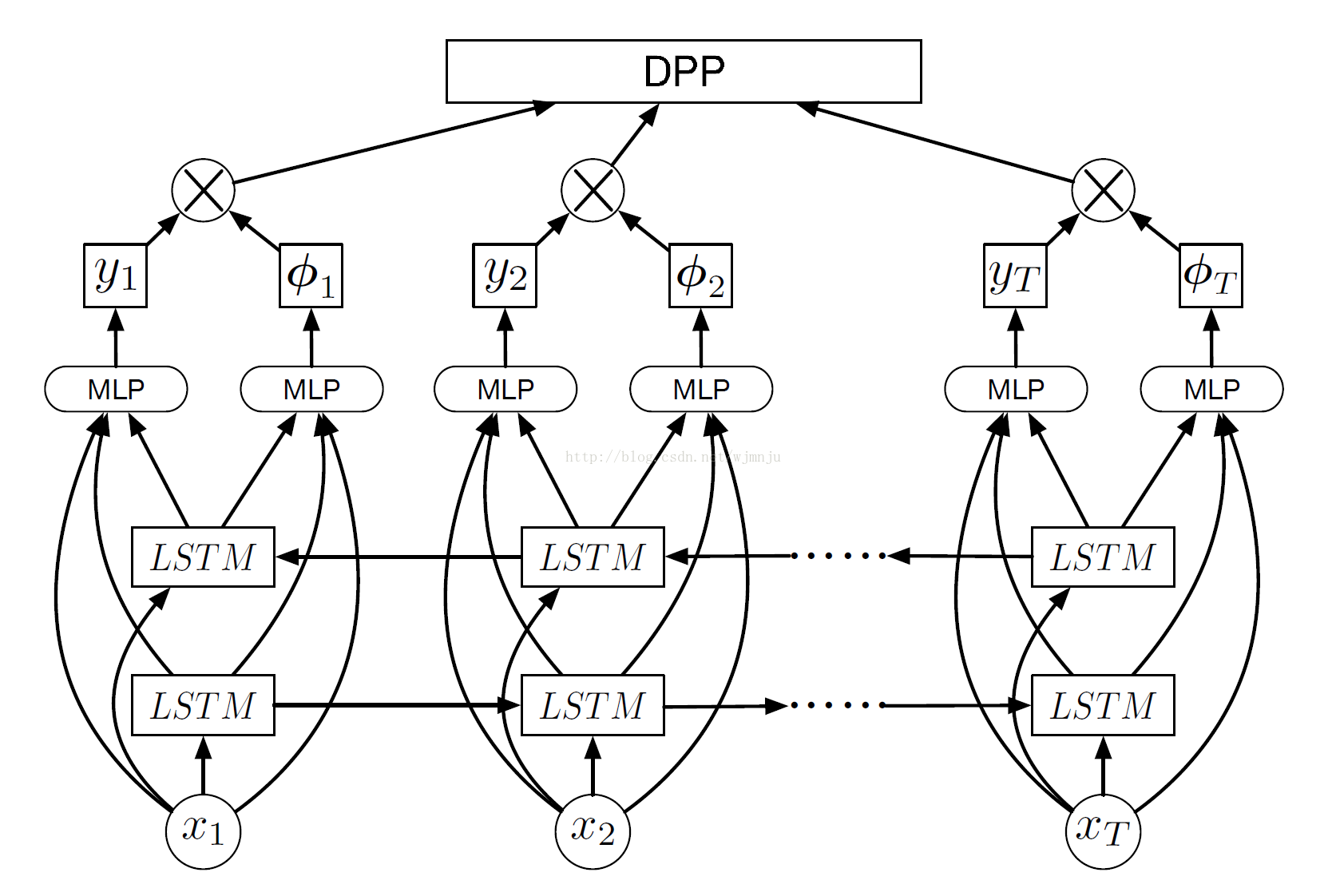
首先,利用GoogleNet网络获取视频每帧的关键信息,即为上图的X1…Xt。将特征信息输入网络中,经过双层LSTM之后,获得Y1…Yt即帧的分值,和ф1…фt为帧间的相似性。通过上图模型,我们利用获得的帧间相似性对整体视频进行时间分割,以避免关键帧重复。得到每一帧的关键性分值之后,根据分值大小以及所需要的关键帧数目,获得关键帧。
最后,根据客户需求或视频不同内容,可以将获得的关键帧处理为关键图集或对其进行聚类后重新组合,获得概括内容的短视频。
总结:
视频摘要的运用场合非常广泛,其技术也是近两年计算机视觉界发展的热门点。我们公司目前主要致力于会议场景相关的视频摘要,将视频摘要与文本摘要相结合,用更简单的结果向用户展示一个完整的会议场景,在缩减用户观看视频时间的同时,也使视频的内容变得更加简单。
联系我们,关注图鸭微信公众号


