PS:本文针对ElasticSearch版本6.0.0,各位看官看之前麻烦看一下自己使用的版本,版本不一样,使用也不一样。
通常我们认为一个集群是一组拥有相同cluster_name的节点组成的,因此也可以变相的认为单节点就构成了一个集群。
之前有提到如何在服务器上部署es的单个实例,在安装完之后我们来查看这个由单节点构成的集群的cluster health,执行命令curl 'http://127.0.0.1:9200/_cluster/health?pretty',
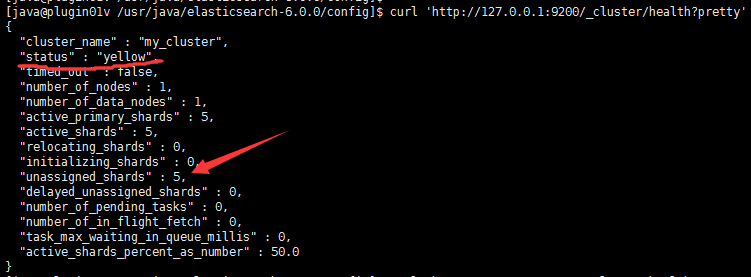
可以发现这个单节点集群的健康状态显示为yellow,而不是完全健康的状态,这代表着所有的主分片都正常运行,集群可以正常工作,但是副本分片没有全部正常运行。
具体到这个案例中,集群健康显示为yellow的原因是因为所有的副本分片都没有分配到节点中,看上方截图的unassigned shards 。这是因为副本分片本就是用来做冗余备份的,如果只有一个节点,副本分片和主分片都存在同一个节点中,一旦失去唯一节点,则所有数据都会丢失,所以备份没有意义,es没有给副本分片分配到节点中。
既然这个原因是只有单个节点导致的,则可以通过在单机上部署多个节点来解决该问题。对于部署多个节点,官方文档的建议是:可以完全依照启动第一个节点的方式启动一个新的节点。。。。亲测并不能行。。。。
下面是具体操作步骤,遇到的问题和解决方案:
- 按照官方文档所述,直接又执行了一遍命令:./bin/elasticsearch -d -Ecluster.name=my_cluster -Enode.name=node_2, 现状是直接报错了,错误信息如下:

错误信息提示要么是没有目录的写权限要么是node.max_local_storage_nodes 这个配置参数没有配置或者配置的是1;官方文档搜一下会发现es默认不允许单机开启多个node的,该参数限制了单机可以开启的es实例个数。
2. 修改$ES_HOME/config下的文件elasticsearch.yml,增加配置项node.max_local_storage_nodes: 2
3. kill之前运行的节点,然后依次执行如下命令:
1 ./bin/elasticsearch -d -Ecluster.name=my_cluster -Enode.name=node_1 2 curl 'http://127.0.0.1:9200/_cluster/health?pretty'; 3 ./bin/elasticsearch -d -Ecluster.name=my_cluster -Enode.name=node_2 4 curl 'http://127.0.0.1:9200/_cluster/health?pretty';
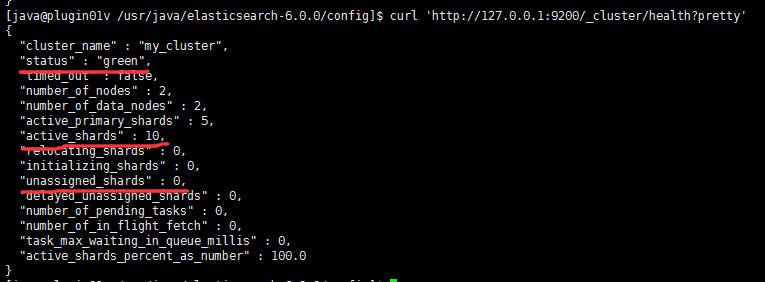
可以看到创建node_1之后,集群健康状态是yellow,但是创建node_2之后,健康状态就是green了,此时unassigned_shards也是0,如下图:
4. 上面其实已经算是实现了本文的功能,但是可以看到上文所有的操作步骤都是通过命令行实现的,如果需要开启很多个实例并且每个实例都有些不一样的话,显然命令行不是一个明智的选择。可以考虑在$ES_HOME/config下创建单独文件夹来存放节点单独的配置文件,一个节点对应一个文件夹, 操作如下:
[java@plugin01v /usr/java/elasticsearch-6.0.0/config]$ mkdir my_cluster [java@plugin01v /usr/java/elasticsearch-6.0.0/config]$ cp elasticsearch.yml jvm.options log4j2.properties my_cluster/ [java@plugin01v /usr/java/elasticsearch-6.0.0/config]$ cd my_cluster/ [java@plugin01v /usr/java/elasticsearch-6.0.0/config/my_cluster]$ ll total 16 -rw-rw---- 1 java java 3521 Dec 7 21:37 elasticsearch.yml -rw-rw---- 1 java java 2672 Dec 7 18:20 jvm.options -rw-rw---- 1 java java 5091 Dec 7 18:20 log4j2.properties
再修改elasticsearch.yml的配置内容(此处提一下遇到的坑,网上很多博客里面的配置都是非常老的版本的es了,直接用的话会导致很多报错,读者一定要看下对应的版本):
#集群名称,用以区分节点属于哪个集群 cluster.name: my_cluster node.name: node_2 #是否让这个节点作为默认的master node.master: false node.data: true network.host: 0.0.0.0 #对外http访问端口 http.port: 9201 #集群内部通信端口 transport.tcp.port: 9301 #存放节点数据的目录 path.data: /usr/java/elasticsearch-6.0.0/data1 #存放日志的目录 path.logs: /usr/java/elasticsearch-6.0.0/logs1 #发现其他节点的主机列表 discovery.zen.ping.unicast.hosts: ["127.0.0.1:9300"] #默认情况下单机不允许开启多个node,该配置限制了单节点上可以开启的es实例个数 node.max_local_storage_nodes: 2 thread_pool.index.queue_size: 400 thread_pool.bulk.queue_size: 5000 bootstrap.memory_lock: fals
5. 修改完之后执行命令:./bin/elasticsearch -Epath.conf=/usr/java/elasticsearch-6.0.0/config/my_cluster -Ecluster.name=my_cluster -Enode.name=node_2 会发现有报错,看一下错误信息:

查看了文档和官方论坛,对于为什么不能使用-Epath.conf也没有一个明确的解释,只看到说可以用脚本来启动节点。遂写了两个启动脚本:
#!/bin/bash #es实例启动脚本 CURRENT_PROJECT=$(pwd)/.. //节点的配置信息 export ES_PATH_CONF=$CURRENT_PROJECT/config/default DATA=$CURRENT_PROJECT/data LOGS=$CURRENT_PROJECT/logs REPO=$CURRENT_PROJECT/backups NODE_NAME=node_1 CLUSTER_NAME=my_cluster BASH_ES_OPTS="-Epath.data=$DATA -Epath.logs=$LOGS -Epath.repo=$REPO -Enode.name=$NODE_NAME -Ecluster.name=$CLUSTER_NAME" $CURRENT_PROJECT/bin/elasticsearch -d $BASH_ES_OPTS
6. 分别执行两个脚本,第一个脚本正常运行,第二个就报错了,错误信息是:
- max file descriptors [4096] for elasticsearch process is too low, increase to at least [65536]
- max virtual memory areas vm.max_map_count [65530] is too low, increase to at least [262144]
对应修改如下:
[pengzecheng@plugin01v /usr/java/elasticsearch-6.0.0/logs1] sudo su [root@plugin01v /usr/java/elasticsearch-6.0.0/scripts] ulimit -n //查看最大文件描述符个数 1024 [root@plugin01v /usr/java/elasticsearch-6.0.0/scripts] ulimit -n 65536 //设置 [root@plugin01v /usr/java/elasticsearch-6.0.0/scripts] sysctl -w vm.max_map_count=262144 [root@plugin01v /usr/java/elasticsearch-6.0.0/scripts] su java //切换到elasticsearch的执行账号,注意此时不可以退出root,因为文件描述符的设置只在当前session生效 [java@plugin01v /usr/java/elasticsearch-6.0.0/scripts] sh my_cluster_node_2.sh //执行第二个脚本成功
最后,查看一下各个节点对应的最大文件描述符,执行命令:curl -XGET 'localhost:9200/_nodes/stats/process?filter_path=**.max_file_descriptors&pretty'
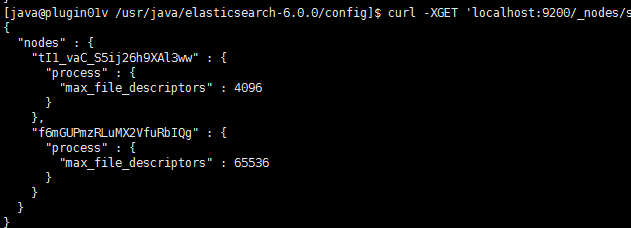
符合预期。。。

