前文我们介绍了redis持久化及其中的一种方法——RDB。本文将介绍另一种方式——AOF。
请大家带着三个问题来思考这两种方法:
1. 如果一个系统中同时存在AOF和RDB,它们是冲突还是协作?
2. 为什么AOF会在RDB之后产生出现?
3. 相比于RDB,本文介绍的AOF会有什么优缺点?
AOF(Append Only File)
官网介绍
官网的原文介绍如下:
AOF advantages - Using AOF Redis is much more durable: you can have different fsync policies: no fsync at all, fsync every second, fsync at every query. With the default policy of fsync every second write performances are still great (fsync is performed using a background thread and the main thread will try hard to perform writes when no fsync is in progress.) but you can only lose one second worth of writes.
- The AOF log is an append only log, so there are no seeks, nor corruption problems if there is a power outage. Even if the log ends with an half-written command for some reason (disk full or other reasons) the redis-check-aof tool is able to fix it easily.
- Redis is able to automatically rewrite the AOF in background when it gets too big. The rewrite is completely safe as while Redis continues appending to the old file, a completely new one is produced with the minimal set of operations needed to create the current data set, and once this second file is ready Redis switches the two and starts appending to the new one.
- AOF contains a log of all the operations one after the other in an easy to understand and parse format. You can even easily export an AOF file. For instance even if you flushed everything for an error using a FLUSHALL command, if no rewrite of the log was performed in the meantime you can still save your data set just stopping the server, removing the latest command, and restarting Redis again.
AOF disadvantages - AOF files are usually bigger than the equivalent RDB files for the same dataset.
- AOF can be slower than RDB depending on the exact fsync policy. In general with fsync set to every second performances are still very high, and with fsync disabled it should be exactly as fast as RDB even under high load. Still RDB is able to provide more guarantees about the maximum latency even in the case of an huge write load.
- In the past we experienced rare bugs in specific commands (for instance there was one involving blocking commands like BRPOPLPUSH) causing the AOF produced to not reproduce exactly the same dataset on reloading. This bugs are rare and we have tests in the test suite creating random complex datasets automatically and reloading them to check everything is ok, but this kind of bugs are almost impossible with RDB persistence. To make this point more clear: the Redis AOF works incrementally updating an existing state, like MySQL or MongoDB does, while the RDB snapshotting creates everything from scratch again and again, that is conceptually more robust. However - 1) It should be noted that every time the AOF is rewritten by Redis it is recreated from scratch starting from the actual data contained in the data set, making resistance to bugs stronger compared to an always appending AOF file (or one rewritten reading the old AOF instead of reading the data in memory). 2) We never had a single report from users about an AOF corruption that was detected in the real world.
|
AOF是什么:
以日志的形式来记录每个写操作,将Redis执行过的所有写指令记录下来(读操作不记录),只许追加文件但不可以改写文件,redis启动之初会读取该文件重新构建数据,换言之,redis重启的话就根据日志文件的内容将写指令从前到后执行一次以完成数据的恢复工作。
Aof保存的是appendonly.aof文件。
配置位置
AOF启动/修复/恢复
我们打开redis配置文件:我们可以看到注释的介绍:Redis默认异步地把数据集DUMP到磁盘上。这种模式在很多应用中已经足够。但是redis在处理时可能导致几分钟的写丢失。(丢失的程度依赖于配置的苦熬找save选项)。AOF是redis持久化的另一种可替代方案。等等等等。这回答了我们一开始提出的第二个问题——为什么有了RDB之后还会出现AOF。
############################## APPEND ONLY MODE ############################### # By default Redis asynchronously dumps the dataset on disk. This mode is # good enough in many applications, but an issue with the Redis process or # a power outage may result into a few minutes of writes lost (depending on # the configured save points). # # The Append Only File is an alternative persistence mode that provides # much better durability. For instance using the default data fsync policy # (see later in the config file) Redis can lose just one second of writes in a # dramatic event like a server power outage, or a single write if something # wrong with the Redis process itself happens, but the operating system is # still running correctly. # # AOF and RDB persistence can be enabled at the same time without problems. # If the AOF is enabled on startup Redis will load the AOF, that is the file # with the better durability guarantees. # # Please check http://redis.io/topics/persistence for more information. appendonly no # The name of the append only file (default: "appendonly.aof") appendfilename "appendonly.aof"
数据正常恢复
启动:设置Yes
修改默认的appendonly no,改为yes
将有数据的aof文件复制一份保存到对应目录(config get dir)。养成备份配置文件的好习惯,必要时能够及时恢复。
恢复:重启redis然后重新加载
我们还是实践一下:
首先,不是修改配置文件,而是备份一份原有的配置文件!!!好习惯very重要!!!
第二步才是修改配置文件,将appendonly修改为yes。
# Please check http://redis.io/topics/persistence for more information. appendonly yes
第三步,我们将redis启动目录下原先的dump.rdb删除掉,防止干扰我们的实验。
第四步,我们启动redis服务,如果服务原先开着请关闭重启。
[hadoop@localhost ~]$ sudo /usr/local/bin/redis-server myconfig/redis.conf [sudo] password for hadoop: [hadoop@localhost ~]$ [hadoop@localhost ~]$ [hadoop@localhost ~]$ ps -ef | grep redis root 27506 1 0 14:18 ? 00:00:00 /usr/local/bin/redis-server 127.0.0.1:6379 hadoop 27511 24886 0 14:18 pts/1 00:00:00 grep --color=auto redis [hadoop@localhost ~]$ [hadoop@localhost ~]$ [hadoop@localhost ~]$ [hadoop@localhost ~]$ /usr/local/bin/redis-cli -p 6379 127.0.0.1:6379> 127.0.0.1:6379> 127.0.0.1:6379> keys * (empty list or set) 127.0.0.1:6379>
我们此时因为之前的dump文件删除了,现在redis中没有任务数据。但是启动redis服务时,redis已经生成了appendonly.aof文件。我们查看内容,发现是空的,因为我们还没有增加或者修改过任何数据。
-rw-r--r--. 1 root root 0 Nov 25 14:18 appendonly.aof drwxr-xr-x. 2 hadoop hadoop 6 Nov 19 2016 Desktop drwxr-xr-x. 2 hadoop hadoop 6 Nov 19 2016 Documents drwxr-xr-x. 4 hadoop hadoop 4096 Nov 5 16:27 Downloads drwxr-xr-x. 2 hadoop hadoop 6 Nov 19 2016 Music drwxrwxr-x. 2 hadoop hadoop 44 Nov 25 14:03 myconfig drwxr-xr-x. 2 hadoop hadoop 6 Nov 19 2016 Pictures drwxr-xr-x. 2 hadoop hadoop 6 Nov 19 2016 Public drwxrwxr-x. 2 hadoop hadoop 63 May 9 2017 shellspace drwxrwxr-x. 3 hadoop hadoop 74 Apr 17 2017 software -rw-r--r--. 1 root root 187 Dec 24 2016 start_hdfs_yarn.sh drwxr-xr-x. 2 hadoop hadoop 6 Nov 19 2016 Templates -rw-r--r--. 1 root root 270 Dec 25 2016 testhdfs.sh drwxr-xr-x. 2 hadoop hadoop 6 Nov 19 2016 Videos [hadoop@localhost ~]$ cat appendonly.aof [hadoop@localhost ~]$ [hadoop@localhost ~]$
之后,我们尝试添加一些数据:
127.0.0.1:6379> 127.0.0.1:6379> set k1 10 OK 127.0.0.1:6379> set k2 20 OK 127.0.0.1:6379> set k3 30 OK 127.0.0.1:6379> set k4 40 OK 127.0.0.1:6379> set k5 50 OK 127.0.0.1:6379> incr k1 (integer) 11 127.0.0.1:6379> incr k1 (integer) 12 127.0.0.1:6379> incr k1 (integer) 13 127.0.0.1:6379> incr k1 (integer) 14 127.0.0.1:6379> incr k1 (integer) 15 127.0.0.1:6379>
我们会发现redis的appendonly.aof文件中将我们刚才的所有操作都记录下来了,注意是操作!
aof文件中有一些值是一些控制符,类似于回车、分隔之类的意思,其他还是能够被人读懂的:首先选择0号库,select 0。这个其实我们没有输入select命令,只不过redis客户端登陆后默认进入的是0号库,所以redis这里把这些默认操作也记录了。之后可以看到我们刚才每一步的set和incr操作。
[hadoop@localhost ~]$ cat appendonly.aof *2 $6 SELECT $1 0 *3 $3 set $2 k1 $2 10 *3 $3 set $2 k2 $2 20 *3 $3 set $2 k3 $2 30 *3 $3 set $2 k4 $2 40 *3 $3 set $2 k5 $2 50 *2 $4 incr $2 k1 *2 $4 incr $2 k1 *2 $4 incr $2 k1 *2 $4 incr $2 k1 *2 $4 incr $2 k1 [hadoop@localhost ~]$
之后我们关闭redis服务重启再看:
这里我们在关闭之前,(其实我中间走开了一会儿),回来看看,这时候redis的dump.rdb文件已经在save策略的影响下生成了。
[hadoop@localhost ~]$ ll total 20 -rw-r--r--. 1 root root 278 Nov 25 14:25 appendonly.aof drwxr-xr-x. 2 hadoop hadoop 6 Nov 19 2016 Desktop drwxr-xr-x. 2 hadoop hadoop 6 Nov 19 2016 Documents drwxr-xr-x. 4 hadoop hadoop 4096 Nov 5 16:27 Downloads -rw-r--r--. 1 root root 112 Nov 25 14:25 dump.rdb drwxr-xr-x. 2 hadoop hadoop 6 Nov 19 2016 Music drwxrwxr-x. 2 hadoop hadoop 44 Nov 25 14:03 myconfig drwxr-xr-x. 2 hadoop hadoop 6 Nov 19 2016 Pictures drwxr-xr-x. 2 hadoop hadoop 6 Nov 19 2016 Public drwxrwxr-x. 2 hadoop hadoop 63 May 9 2017 shellspace drwxrwxr-x. 3 hadoop hadoop 74 Apr 17 2017 software -rw-r--r--. 1 root root 187 Dec 24 2016 start_hdfs_yarn.sh drwxr-xr-x. 2 hadoop hadoop 6 Nov 19 2016 Templates -rw-r--r--. 1 root root 270 Dec 25 2016 testhdfs.sh drwxr-xr-x. 2 hadoop hadoop 6 Nov 19 2016 Videos [hadoop@localhost ~]$
这个我们先不管,我们关闭redis服务:(刚发现之前的所有文章中似乎没写这种关闭redis-server的方法,即在客户端登录模式下输入shutdown命令。这里补充介绍下,输入后redis服务就停止了,你也查不到redis-server的进程了,然后启动redis-server就算重启了。之前我文章里似乎都是直接kill -9的:))
127.0.0.1:6379> shutdown not connected> exit [hadoop@localhost ~]$
言归正传,我们再看看redis服务启动目录:发现shutdown之后,dump.rdb的时间更新了;但是appendonly.aof文件的日期还是刚才输入最后一条修改命令时的时间。
所以说,shutdown命令可以触发rdb的dump操作,但对aof方式没有任何影响。
[hadoop@localhost ~]$ ll total 20 -rw-r--r--. 1 root root 278 Nov 25 14:25 appendonly.aof drwxr-xr-x. 2 hadoop hadoop 6 Nov 19 2016 Desktop drwxr-xr-x. 2 hadoop hadoop 6 Nov 19 2016 Documents drwxr-xr-x. 4 hadoop hadoop 4096 Nov 5 16:27 Downloads -rw-r--r--. 1 root root 112 Nov 25 14:31 dump.rdb drwxr-xr-x. 2 hadoop hadoop 6 Nov 19 2016 Music drwxrwxr-x. 2 hadoop hadoop 44 Nov 25 14:03 myconfig drwxr-xr-x. 2 hadoop hadoop 6 Nov 19 2016 Pictures drwxr-xr-x. 2 hadoop hadoop 6 Nov 19 2016 Public drwxrwxr-x. 2 hadoop hadoop 63 May 9 2017 shellspace drwxrwxr-x. 3 hadoop hadoop 74 Apr 17 2017 software -rw-r--r--. 1 root root 187 Dec 24 2016 start_hdfs_yarn.sh drwxr-xr-x. 2 hadoop hadoop 6 Nov 19 2016 Templates -rw-r--r--. 1 root root 270 Dec 25 2016 testhdfs.sh drwxr-xr-x. 2 hadoop hadoop 6 Nov 19 2016 Videos [hadoop@localhost ~]$
之后,我们为了观察aof,还是现将dump.rdb文件删除之后,再启动redis服务:
[hadoop@localhost ~]$ rm dump.rdb rm: remove write-protected regular file ‘dump.rdb’? y [hadoop@localhost ~]$
(本文出自oschina博主HappyBKs的博文:https://my.oschina.net/happyBKs/blog/1579757)
[hadoop@localhost ~]$ sudo /usr/local/bin/redis-server myconfig/redis.conf [sudo] password for hadoop: [hadoop@localhost ~]$ /usr/local/bin/redis-cli -p 6379 127.0.0.1:6379> keys * 1) "k5" 2) "k1" 3) "k4" 4) "k3" 5) "k2" 127.0.0.1:6379>
从上面的例子我们还可以看出,redis服务可以同时生成aof和rdb文件,说明aof和rdb方式两者可以共存。
关于这个我们用配置文件中的注释做个总结:
# AOF and RDB persistence can be enabled at the same time without problems. # If the AOF is enabled on startup Redis will load the AOF, that is the file # with the better durability guarantees.
AOF和RDB的谁优先
那么,如果同时存在rdb和aof文件,redis会优先加载谁呢?
我们再做个试验:
我们再次将redis服务shutdown。当然dump.rdb文件又生成了。我们打开appendonly.aof文件,在文件末尾输入一大堆乱七八糟的字符,没错就是把aof文件搞坏。
注意,这时候我们并没有启动redis服务,现在目录里同时存在完好的dump.rdb文件和被我们改坏的appendonly.aof文件。那么如果我此时启动redis服务,会怎么样呢?如果能够正常启动,说明redis服务优先加载的是rdb;如果没能启动成功,说明redis优先启动的是aof。
hadoop@localhost ~]$ sudo /usr/local/bin/redis-server myconfig/redis.conf [sudo] password for hadoop: [hadoop@localhost ~]$ ps -ef | grep redis hadoop 29050 24886 0 15:26 pts/1 00:00:00 grep --color=auto redis [hadoop@localhost ~]$ [hadoop@localhost ~]$ /usr/local/bin/redis-cli -p 6379 Could not connect to Redis at 127.0.0.1:6379: Connection refused Could not connect to Redis at 127.0.0.1:6379: Connection refused not connected>
从上面可以看出,redis没有启动成功。这说明,在同时存在rdb和aof文件的情况下,redis会优先选择aof进行数据恢复。
AOF文件修复方法
那么如果我们在实际生产中,网络丢包、延迟、病毒、大文件运行失败等等导致aof文件破损。aof文件损坏了,该怎么修复呢?
首先修复的第一步——备份待修复的aof文件!备份!备份!备份!好习惯!
备份被写坏的AOF文件
[hadoop@localhost ~]$ cp appendonly.aof appendonly_bak.aof [hadoop@localhost ~]$ ll total 24 -rw-r--r--. 1 hadoop hadoop 359 Nov 25 15:16 appendonly.aof -rw-r--r--. 1 hadoop hadoop 359 Nov 25 15:30 appendonly_bak.aof
修复:
redis-check-aof --fix进行修复
[hadoop@localhost ~]$ /usr/local/bin/redis-check-aof --fix appendonly.aof 0x 116: Expected prefix ';', got: '*' AOF analyzed: size=359, ok_up_to=278, diff=81 This will shrink the AOF from 359 bytes, with 81 bytes, to 278 bytes Continue? [y/N]: y Successfully truncated AOF [hadoop@localhost ~]$
恢复:重启redis然后重新加载
[hadoop@localhost ~]$ sudo /usr/local/bin/redis-server myconfig/redis.conf [sudo] password for hadoop: [hadoop@localhost ~]$ [hadoop@localhost ~]$ [hadoop@localhost ~]$ /usr/local/bin/redis-cli -p 6379 127.0.0.1:6379> 127.0.0.1:6379> keys * 1) "k5" 2) "k2" 3) "k1" 4) "k3" 5) "k4" 127.0.0.1:6379> get k1 "15" 127.0.0.1:6379>
redis除了提供了aof的修复命令,还提供了dump.rdb的,这里我就不做介绍了,请大家触类旁通redis-check-rdb。
AOF的配置策略
还记得我们上上篇博客文章罗列的配置大纲吗?我们把遗留的AOF配置策略留到本文这里说。
APPEND ONLY MODE追加
appendonly 默认no,改成yes打开aof持久化方式
appendfilename 默认appendonly.aof。一般地球人不去改它。
appendfsync:AOF,其实是也是一种同步的写。redis提供了几种文件同步策略:
always:同步持久化 每次发生数据变更会被立即记录到磁盘 性能较差但数据完整性比较好
everysec:出厂默认推荐,异步操作,每秒记录 如果一秒内宕机,有数据丢失
no
默认选择的是everysec,这种方式是中庸之道,数据完整性不及always,最多损失1秒的数据。
# The fsync() call tells the Operating System to actually write data on disk # instead of waiting for more data in the output buffer. Some OS will really flush # data on disk, some other OS will just try to do it ASAP. # # Redis supports three different modes: # # no: don't fsync, just let the OS flush the data when it wants. Faster. # always: fsync after every write to the append only log. Slow, Safest. # everysec: fsync only one time every second. Compromise. # # The default is "everysec", as that's usually the right compromise between # speed and data safety. It's up to you to understand if you can relax this to # "no" that will let the operating system flush the output buffer when # it wants, for better performances (but if you can live with the idea of # some data loss consider the default persistence mode that's snapshotting), # or on the contrary, use "always" that's very slow but a bit safer than # everysec. # # More details please check the following article: # http://antirez.com/post/redis-persistence-demystified.html # # If unsure, use "everysec". # appendfsync always appendfsync everysec # appendfsync no
上面这三种策略中,always虽然能够保证数据的完整性,但是会带来严重的消耗。这在超高并发的环境下是不可想象的,之前的redis特别篇中我已经提到CAP原理。在真实的高并发环境下,如果真的要做取舍一定是取AP,毕竟高可用是最重要的。
还有另一个问题,在高并发环境下,大量的数据被写入和修改,那么aof文件会变得非常臃肿。有的时候显得很笨拙。例如k1的值为0,你incr k1了一万次,那么也会在aof文件中写入incr k1一万次操作;其实如果能只记录一个set k1 10000,一句也就搞定了,效果一样,精简多了。所以我们引入了redis aof的另外一个概念或者说特性机制,rewrite重写。
关于重写,也有三种方式,我先罗列:
no-appendfsync-on-rewrite:重写时是否可以运用Appendfsync,用默认no即可,保证数据安全性。
auto-aof-rewrite-min-size:设置重写的基准值
auto-aof-rewrite-percentage:设置重写的基准值
rewrite
重写机制是什么:
AOF采用文件追加方式,文件会越来越大为避免出现此种情况,新增了重写机制, 当AOF文件的大小超过所设定的阈值时,Redis就会启动AOF文件的内容压缩,只保留可以恢复数据的最小指令集.可以使用命令bgrewriteaof
重写原理
AOF文件持续增长而过大时,会fork出一条新进程来将文件重写(也是先写临时文件最后再rename),遍历新进程的内存中数据,每条记录有一条的Set语句。重写aof文件的操作,并没有读取旧的aof文件,而是将整个内存中的数据库内容用命令的方式重写了一个新的aof文件,这点和快照有点类似
触发机制
Redis会记录上次重写时的AOF大小,默认配置是当AOF文件大小是上次rewrite后大小的一倍且文件大于64M时触发。请见配置文件默认是,auto-aof-rewrite-percentage 100的意思是超过100%,也就是一倍;auto-aof-rewrite-min-size 64mb是查过64mb。
这里插一句,假如你到一家新公司,老板把公司吹的天花乱坠,什么技术有多牛,业务量有多大。如果他们使用aof来做redis持久化,这时候,你只要偷偷看一眼他们redis的这个配置项auto-aof-rewrite-min-size,如果是64mb,那么你就应该心领神会了——这个公司要么业务量根本没这么大,要么这个公司的人并不怎么牛。真正大型系统,3gb都是起步,64mb根本是在搞笑。这个配置时观察一个公司水平的一个很好的维度。
# When the AOF fsync policy is set to always or everysec, and a background # saving process (a background save or AOF log background rewriting) is # performing a lot of I/O against the disk, in some Linux configurations # Redis may block too long on the fsync() call. Note that there is no fix for # this currently, as even performing fsync in a different thread will block # our synchronous write(2) call. # # In order to mitigate this problem it's possible to use the following option # that will prevent fsync() from being called in the main process while a # BGSAVE or BGREWRITEAOF is in progress. # # This means that while another child is saving, the durability of Redis is # the same as "appendfsync none". In practical terms, this means that it is # possible to lose up to 30 seconds of log in the worst scenario (with the # default Linux settings). # # If you have latency problems turn this to "yes". Otherwise leave it as # "no" that is the safest pick from the point of view of durability. no-appendfsync-on-rewrite no # Automatic rewrite of the append only file. # Redis is able to automatically rewrite the log file implicitly calling # BGREWRITEAOF when the AOF log size grows by the specified percentage. # # This is how it works: Redis remembers the size of the AOF file after the # latest rewrite (if no rewrite has happened since the restart, the size of # the AOF at startup is used). # # This base size is compared to the current size. If the current size is # bigger than the specified percentage, the rewrite is triggered. Also # you need to specify a minimal size for the AOF file to be rewritten, this # is useful to avoid rewriting the AOF file even if the percentage increase # is reached but it is still pretty small. # # Specify a percentage of zero in order to disable the automatic AOF # rewrite feature. auto-aof-rewrite-percentage 100 auto-aof-rewrite-min-size 64mb # An AOF file may be found to be truncated at the end during the Redis # startup process, when the AOF data gets loaded back into memory. # This may happen when the system where Redis is running # crashes, especially when an ext4 filesystem is mounted without the # data=ordered option (however this can't happen when Redis itself # crashes or aborts but the operating system still works correctly). # # Redis can either exit with an error when this happens, or load as much # data as possible (the default now) and start if the AOF file is found # to be truncated at the end. The following option controls this behavior. # # If aof-load-truncated is set to yes, a truncated AOF file is loaded and # the Redis server starts emitting a log to inform the user of the event. # Otherwise if the option is set to no, the server aborts with an error # and refuses to start. When the option is set to no, the user requires # to fix the AOF file using the "redis-check-aof" utility before to restart # the server. # # Note that if the AOF file will be found to be corrupted in the middle # the server will still exit with an error. This option only applies when # Redis will try to read more data from the AOF file but not enough bytes # will be found. aof-load-truncated yes
小总结
好,最后把aof的一些要点总结一下:
优势
每修改同步:appendfsync always 同步持久化 每次发生数据变更会被立即记录到磁盘 性能较差但数据完整性比较好
每秒同步:appendfsync everysec 异步操作,每秒记录 如果一秒内宕机,有数据丢失
不同步:appendfsync no 从不同步
劣势
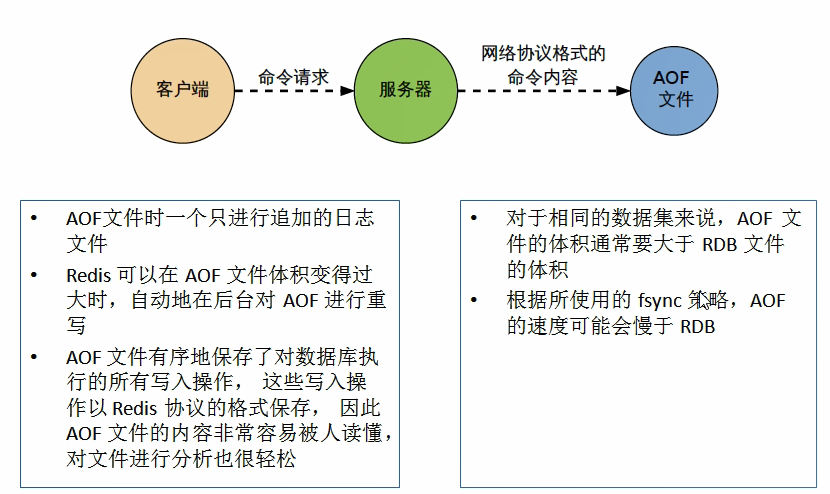
相同数据集的数据而言aof文件要远大于rdb文件,恢复速度慢于rdb
aof运行效率要慢于rdb,每秒同步策略效率较好,不同步效率和rdb相同
大总结(RDB和AOF选哪个)
官网建议
Ok, so what should I use? The general indication is that you should use both persistence methods if you want a degree of data safety comparable to what PostgreSQL can provide you. If you care a lot about your data, but still can live with a few minutes of data loss in case of disasters, you can simply use RDB alone. There are many users using AOF alone, but we discourage it since to have an RDB snapshot from time to time is a great idea for doing database backups, for faster restarts, and in the event of bugs in the AOF engine. Note: for all these reasons we'll likely end up unifying AOF and RDB into a single persistence model in the future (long term plan). The following sections will illustrate a few more details about the two persistence models. |
RDB持久化方式能够在指定的时间间隔能对你的数据进行快照存储
AOF持久化方式记录每次对服务器写的操作,当服务器重启的时候会重新执行这些命令来恢复原始的数据,AOF命令以redis协议追加保存每次写的操作到文件末尾.
Redis还能对AOF文件进行后台重写,使得AOF文件的体积不至于过大。
只做缓存:如果你只希望你的数据在服务器运行的时候存在,你也可以不使用任何持久化方式.
同时开启两种持久化方式
在这种情况下,当redis重启的时候会优先载入AOF文件来恢复原始的数据。因为在通常情况下AOF文件保存的数据集要比RDB文件保存的数据集要完整。
RDB的数据不实时,同时使用两者时服务器重启也只会找AOF文件。那要不要只使用AOF呢?
作者建议不要,因为RDB更适合用于备份数据库(AOF在不断变化不好备份),快速重启,而且不会有AOF可能潜在的bug,留着作为一个万一的手段。
性能建议
因为RDB文件只用作后备用途,建议只在Slave上持久化RDB文件,而且只要15分钟备份一次就够了,只保留save 900 1这条规则。
如果Enalbe AOF,好处是在最恶劣情况下也只会丢失不超过两秒数据,启动脚本较简单只load自己的AOF文件就可以了。代价一是带来了持续的IO,二是AOF rewrite的最后将rewrite过程中产生的新数据写到新文件造成的阻塞几乎是不可避免的。只要硬盘许可,应该尽量减少AOF rewrite的频率,AOF重写的基础大小默认值64M太小了,可以设到5G以上。默认超过原大小100%大小时重写可以改到适当的数值。
如果不Enable AOF ,仅靠Master-Slave Replication 实现高可用性也可以。能省掉一大笔IO也减少了rewrite时带来的系统波动。代价是如果Master/Slave同时倒掉,会丢失十几分钟的数据,启动脚本也要比较两个Master/Slave中的RDB文件,载入较新的那个。新浪微博就选用了这种架构。
最后,我们梳理一下我们介绍rdb引入aof,进而引入后一篇将要整理的文章中的主从复制,整个的技术遇到的问题及演化过程如下:
RDB不完整 -> AOF ,AOF频繁IO -> 主从复制

