本文首发于个人微信公众号: <andyqian>,期待你的关注!
前言
今天我们以String类中的getBytes()方法为例,来看一看JDK源码中的默认字符集,getBytes()方法在帮助文档中是 这样写的:
Encodes this String into a sequence of bytes using the platform’s default charset, storing the result into a new byte array.
意思是:使用平台的默认字符集将此 String 编码为 byte 序列,并将结果存储到一个新的 byte 数组中。
恩,那我们就来对不同平台的默认字符集这个问题。一探究竟。
初探源码
首先我们进入getBytes()源码中:
public byte[] getBytes() { return StringCoding.encode(value, 0, value.length); }
该方法中直接返回StringCoding.encode(value,0,value.length),那就再点击进去看看。代码如下:
static byte[] encode(char[] ca, int off, int len) { String csn = Charset.defaultCharset().name(); try { // use charset name encode() variant which provides caching. return encode(csn, ca, off, len); } catch (UnsupportedEncodingException x) { warnUnsupportedCharset(csn); } try { return encode("ISO-8859-1", ca, off, len); } catch (UnsupportedEncodingException x) { // If this code is hit during VM initialization, MessageUtils is // the only way we will be able to get any kind of error message. MessageUtils.err("ISO-8859-1 charset not available: " + x.toString()); // If we can not find ISO-8859-1 (a required encoding) then things // are seriously wrong with the installation. System.exit(1); return null; } }
在这里,我们看到了。在上述方法中,通过 Charset.defaultCharset().getName() 获取系统默认的字符集。那我们就再点击进去看看,代码如下:
public static Charset defaultCharset() { if (defaultCharset == null) { synchronized (Charset.class) { String csn = AccessController.doPrivileged( new GetPropertyAction("file.encoding")); Charset cs = lookup(csn); if (cs != null) defaultCharset = cs; else defaultCharset = forName("UTF-8"); } } return defaultCharset; }
其实,在上述代码中,我们最关心的是这一行代码:
String csn = AccessController.doPrivileged( new GetPropertyAction("file.encoding"));
点击进去后。如下所示:
public class GetPropertyAction implements PrivilegedAction<String> { private String theProp; private String defaultVal; public GetPropertyAction(String var1) { this.theProp = var1; } public GetPropertyAction(String var1, String var2) { this.theProp = var1; this.defaultVal = var2; } public String run() { String var1 = System.getProperty(this.theProp); return var1 == null?this.defaultVal:var1; }
在这里,我们已经看到了熟悉的代码:
System.getProperty(this.theProp);
到此,我们就可以在不同的平台做实验了。
此次实验的平台有:
-
Linux平台
系统: Ubuntu 14.04 LTS (中文环境)
-
Windows平台
系统: Windows 7 (中文环境)
不同平台的默认字符集实验
测试JDK版本: java version “1.7.0_79”
步骤:
windows编码
D:\testpdfPath>javac Test.java D:\testpdfPath>java Test GBK
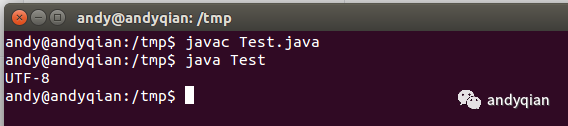
Linux (会话编码为UTF-8)编码(默认为UTF-8):
[andy@andyqian /tmp] $ javac Test.java [andy@andyqian /tmp] $ java Test UTF-8
如图所示:

Linux (会话编码为GBK)编码:
[andy@andyqian /tmp] $ ls Test.java [andy@andyqian /tmp] $ javac Test.java [andy@andyqian /tmp] $ java Test GBK
以上试验表明:
Windows中文环境下,默认编码为:GBK。
Linux系统中文环境下,默认编码为: UTF-8。
不同的系统 file.encoding 的表现是不一样的。到此,我们已经查看了getBytes()中的默认字符集源码。
实验代码:
上述试验代码,非常简单,如下所述,有兴趣试验的朋友,可以新建一个Java类,命名为Test.java,复制到其中即可。
/** * author: andy * date: 17-11-24 * blog: www.andyqian.com * version: 0.0.1 * description: */ public class Test { public static void main(String[] args){ System.out.println(System.getProperty("file.encoding")); } }
这里需要注意的是: 直接复制到IDEA中,获取的结果可能会受idea影响。这也我直接使用原始命令来编译的原因。
SSH 远程编码:
这里说个题外话,SSH本地机器编码会影响远程机器当前会话的编码。怎么说呢? 我们继续做实验。
机器准备:
一台编码为 en_US.UTF-8 编码的机器。
一台编码为 zh_GBK 编码的机器。
(备注: 两台相同编码的机器也可以,修改一台机器的编码即可。)
首先,我们通过Xshell直接来连接远程机器(UTF-8)通过locale命令查看系统编码如下:
[andy@andyqian /tmp/test] $ locale LANG=en_US.UTF-8 LC_CTYPE="en_US.UTF-8" LC_NUMERIC="en_US.UTF-8" LC_TIME="en_US.UTF-8" LC_COLLATE="en_US.UTF-8" LC_MONETARY="en_US.UTF-8" LC_MESSAGES="en_US.UTF-8" LC_PAPER="en_US.UTF-8" LC_NAME="en_US.UTF-8" LC_ADDRESS="en_US.UTF-8" LC_TELEPHONE="en_US.UTF-8" LC_MEASUREMENT="en_US.UTF-8" LC_IDENTIFICATION="en_US.UTF-8" LC_ALL=
注意此时的系统编码为: UTF-8
1. 紧接着,我们先查看本地机器(GBK)的编码,
[andy@andyqian02 /home/andyqian] $ locale LANG=zh_CN.GBK LC_CTYPE="zh_CN.GBK" LC_NUMERIC="zh_CN.GBK" LC_TIME="zh_CN.GBK" LC_COLLATE="zh_CN.GBK" LC_MONETARY="zh_CN.GBK" LC_MESSAGES="zh_CN.GBK" LC_PAPER="zh_CN.GBK" LC_NAME="zh_CN.GBK" LC_ADDRESS="zh_CN.GBK" LC_TELEPHONE="zh_CN.GBK" LC_MEASUREMENT="zh_CN.GBK" LC_IDENTIFICATION="zh_CN.GBK" LC_ALL=
再通过本地主机(GBK),ssh连接到 远程主机机器(UTF-8)上,使用locale命令查看系统编码如下:
-
[andy@andyqian02 /home/andyqian] $ ssh andyqian@192.168.1.1 andyqian@192.168.1.1's password:
登录后,查看编码:
-
[andy@andyqian01 /home/andyqian] $ locale LANG=zh_CN.GBK LC_CTYPE="zh_CN.GBK" LC_NUMERIC="zh_CN.GBK" LC_TIME="zh_CN.GBK" LC_COLLATE="zh_CN.GBK" LC_MONETARY="zh_CN.GBK" LC_MESSAGES="zh_CN.GBK" LC_PAPER="zh_CN.GBK" LC_NAME="zh_CN.GBK" LC_ADDRESS="zh_CN.GBK" LC_TELEPHONE="zh_CN.GBK" LC_MEASUREMENT="zh_CN.GBK" LC_IDENTIFICATION="zh_CN.GBK" LC_ALL=
(备注: 192.168.1.1 请替换成自己的主机地址)
注意此时远程主机当前会话的编码已经变成了
zh_CN.GBK
此时通过:
System.getProperty("file.encoding")
获取到的编码为: GBK
这里再次证明。系统的默认编码,在不同场景下,表现形式也不一样,很容易造成乱码。我就吃过这样的亏。泪奔…
小结
上面以getBytes()这个常用的方法,一步一步查看JDK源码,也动手实验了,不同系统的表现形式。其实想表达的是,多动手实验,会发现非常有意思,印象也会深刻很多。收获也会不一样。
精简版:
-
有关编码的方法一定要指定特定编码,不要使用系统默认编码。避免不同系统默认编码不一致,导致乱码。
-
多动手试验。
最后:祝大家周末愉快!

扫码关注,一起进步
个人博客: http://www.andyqian.com

