文件在系统中的存储方式是二进制。
Buffer缓存对象是文件在内存中的二进制数据的十六进制的形式。
Buffer基本上都是配合着 fs 系统进行操作。
Buffer缓冲器
1、Buffer 使用
Buffer是一个比较特殊的模块,不像其他模块需要使用 require( ) 关键字加载。Buffer是自启动模块。
创建一个缓存对象:
方式一:new Buffer( ) ; // 6.0.0版本后被废弃了
方式二:填充方法-创建缓存对象的功能
Buffer.alloc( ) 和 Buffer.allocUnsafe( ),这两个方法的区别主要是表现在安全性和速率上。
//填充方法-创建缓存对象 let bufferObj = Buffer.alloc(8);//创建大小为8个字节的Buffer对象 console.log(bufferObj);//打印该对象。

1.1 Buffer对象具有循环填充的特性
let bufferObj = Buffer.alloc(8,"a"); console.log(bufferObj);

a 的ASCII值是十六进制的 61(十进制 97)
1.2 Buffer对象具有自动截取的特性
let bufferObj = Buffer.alloc(8,"abc"); console.log(bufferObj);

从左到右,若空间充足,则自动循环;若空间不够,则自动截断。
1.3 Buffer对象的大小通过字符串长度设定
let str = "abcde"; let bufferObj = Buffer.alloc(str.length,str); console.log(bufferObj);

这里的字符串是英文字符串,所以可以通过字符串的长度来设定Buffer对象的大小。
1.4 Buffer对象对于中文的处理
let str = "这是测试字符串"; console.log(str.length); let bufferObj = Buffer.alloc(str.length,str); console.log(bufferObj); console.log(bufferObj.toString());
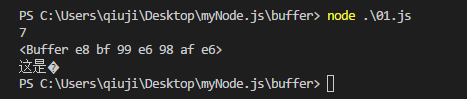
出问题了,字符串的长度是 7 没问题,但是 字符串“这是测试字符串”,出现乱码现象。原因是Node.js的程序默认以 utf8 字符集。一个utf8中的汉字占三个字节。所以,这里长度*3就没问题了。但是,如果我这里的编码不是utf8呢?比如 GBK,一个汉字占两个字节,那么这里长度*3就有问题了。这怎么解决呢?
好办,Buffer中提供Buffer.byteLength(string[, encoding]) 获取(指定字符集,默认utf8)字符串的字节数。将上面代码修改一下,如下,完美解决。
let str = "这是测试字符串"; let size = Buffer.byteLength(str); console.log(size); let bufferObj = Buffer.alloc(size,str); console.log(bufferObj); console.log(bufferObj.toString());

2、指定字符集创建缓存对象
Buffer.alloc(size,str [,encoding] ),这里的第三个参数用于指定字符集。但是,可惜的是Node.js支持的字符集存在很大的局限性。具体字符集如下(稍微了解一下):
'ascii' - 仅支持 7 位 ASCII 数据。如果设置去掉高位的话,这种编码是非常快的。
'utf8' - 多字节编码的 Unicode 字符。许多网页和其他文档格式都使用 UTF-8 。 65535
'utf16le' - 2 或 4 个字节,小字节序编码的 Unicode 字符。支持代理对(U+10000 至 U+10FFFF)。
'ucs2' - 'utf16le' 的别名。
'base64' - Base64 编码。当从字符串创建 Buffer 时,按照 RFC4648 第 5 章的规定,这种编码也将正确地接受“URL 与文件名安全字母表”。
'latin1' - 一种把 Buffer 编码成一字节编码的字符串的方式(由 IANA 定义在 RFC1345 第 63 页,用作 Latin-1 补充块与 C0/C1 控制码)。
'binary' - 'latin1' 的别名。
'hex' - 将每个字节编码为两个十六进制字符。
3、Buffer.alloc( ) 和 Buffer.allocUnsafe( )的比较
Buffer.alloc( ) : 安全但是效率较低;
Buffer.allocUnsafe( ) : 不安全但是效率高。
let obj1 = Buffer.alloc(10); // 00 安全性方法 效率低 let obj2 = Buffer.allocUnsafe(10); // 随机 00 非安全性 效率高 console.log(obj1); console.log(obj2);

上段代码使用Buffer.alloc( ) 和 Buffer.allocUnsafe( ) 两种方法大小为10 个字节的缓存对象,前者产生的都是 00,后者不是。00表示空,所以,前者表示空的,后者非空。那么这些数据哪里来的呢?它有一个高大上的名字,叫做幽灵数据,其实就是垃圾数据,由于Buffer.allocUnsafe( )的不安全性产生。

