在前面的文章中,我们对kafka的基本使用方式和架构原理进行了介绍,本文则主要介绍kafka中日志的存储原理,主要内容包括kafka日志存储格式、日志文件的管理方式、日志索引文件的格式和日志压缩等功能。
作为一款消息系统,日志就是将消息持久化到磁盘上的数据,这份数据的存储方式将会极大的影响其吞吐量和扩展性,而kafka日志由于其优秀的设计,为其实现这些特性提供了不可忽略的作用。总结来说,kafka日志主要具有如下特点:
- 极高的压缩比例。kafka日志不仅会对其key和value进行压缩,而且还会对每条消息的偏移量、时间戳等等元数据信息进行压缩;
- batch的方式存储数据。在存储上,kafka日志是以批次的方式进行数据的存储,每个批次的大小默认为4KB,每个批次的元数据中会存储其起始偏移量、时间戳和消息长度等信息;
- 追加的方式写入数据。由于kafka日志都是写入磁盘的,而磁盘的顺序写入效率是非常高的,kafka写入采用的就是追加的方式写入消息,这样可以避免磁头的随机移动,从而提升写入速率;
- 使用索引文件提升查询性能。kafka不仅会存储消息日志文件,还会为每个消息日志文件创建一个索引文件,而且索引都是以batch为单位进行存储的,也即只会为batch的起始位移和时间戳建立索引,而不会为每条消息都建立索引。
1. 日志存储格式
最新版本的kafka日志是以批为单位进行日志存储的,所谓的批指的是kafka会将多条日志压缩到同一个batch中,然后以batch为单位进行后续的诸如索引的创建和消息的查询等工作。对于每个批次而言,其默认大小为4KB,并且保存了整个批次的起始位移和时间戳等元数据信息,而对于每条消息而言,其位移和时间戳等元数据存储的则是相对于整个批次的元数据的增量,通过这种方式,kafka能够减少每条消息中数据占用的磁盘空间。这里我们首先展示一下每个批次的数据格式:
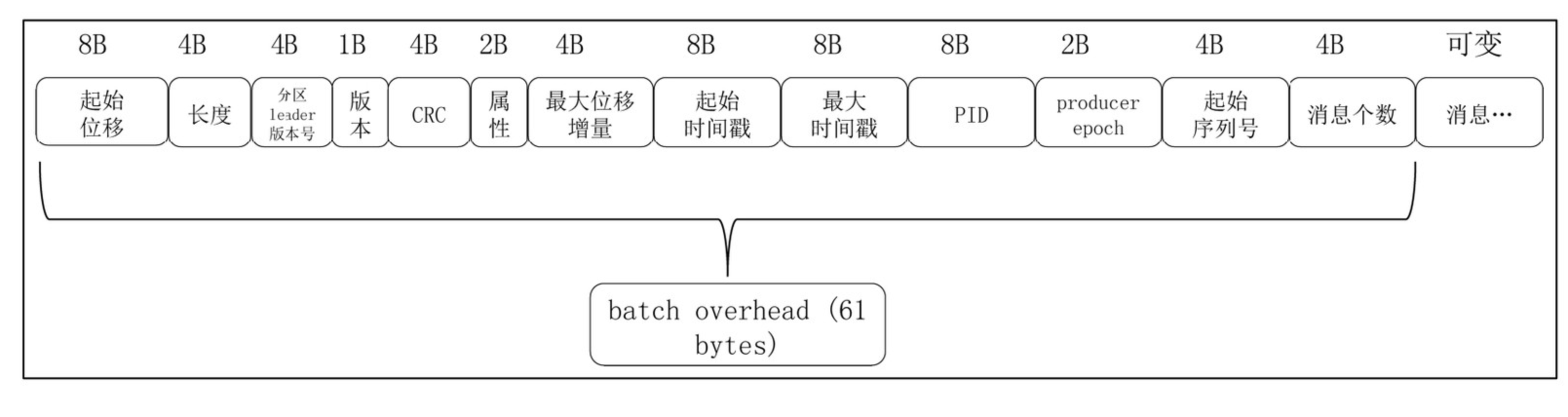
图中消息批次的每个元数据都有固定的长度大小,而只有最后面的消息个数的是可变的。如下是batch中主要的属性的含义:
- 起始位移:占用8字节,其存储了当前batch中第一条消息的位移;
- 长度:占用了4个字节,其存储了整个batch所占用的磁盘空间的大小,通过该字段,kafka在进行消息遍历的时候,可以快速的跳跃到下一个batch进行数据读取;
- 分区leader版本号:记录了当前消息所在分区的leader的服务器版本,主要用于进行一些数据版本的校验和转换工作;
- CRC:对当前整个batch的数据的CRC校验码,主要是用于对数据进行差错校验的;
- 属性:占用2个字节,这个字段的最低3位记录了当前batch中消息的压缩方式,现在主要有GZIP、LZ4和Snappy三种。第4位记录了时间戳的类型,第5和6位记录了新版本引入的事务类型和控制类型;
- 最大位移增量:最新的消息的位移相对于第一条消息的唯一增量;
- 起始时间戳:占用8个字节,记录了batch中第一条消息的时间戳;
- 最大时间戳:占用8个字节,记录了batch中最新的一条消息的时间戳;
- PID、producer epoch和起始序列号:这三个参数主要是为了实现事务和幂等性而使用的,其中PID和producer epoch用于确定当前producer是否合法,而起始序列号则主要用于进行消息的幂等校验;
- 消息个数:占用4个字节,记录当前batch中所有消息的个数;
通过上面的介绍可以看出,每个batch的头部数据中占用的字节数固定为61个字节,可变部分主要是与具体的消息有关,下面我们来看一下batch中每条消息的格式:

这里的消息的头部数据就与batch的大不相同,可以看到,其大部分数据的长度都是可变的。既然是可变的,这里我们需要强调两个问题:
-
对于数字的存储,kafka采用的是Zig-Zag的存储方式,也即负数并不会使用补码的方式进行编码,而是将其转换为对应的正整数,比如-1映射为1、1映射为2、-2映射为3、2映射为4,关系图如下所示:

通过图可以看出,在对数据反编码的时候,我们只需要将对应的整数转换成其原始值即可;
-
在使用Zig-Zag编码方式的时候,每个字节最大为128,而其中一半要存储正数,一半要存储负数,还有一个0,也就是说每个字节能够表示的最大整数为64,此时如果有大于64的数字,kafka就会使用多个字节进行存储,而这多个字节的表征方式是通过将每个字节的最大位作为保留位来实现的,如果最高位为1,则表示需要与后续字节共同表征目标数字,如果最高位为0,则表示当前位即可表示目标数字。
kafka使用这种编码方式的优点在于,大部分的数据增量都是非常小的数字,因此使用一个字节即可保存,这比直接使用原始类型的数据要节约大概七倍的内存。
对于上面的每条消息的格式,除了消息key和value相关的字段,其还有属性字段和header,属性字段的主要作用是存储当前消息key和value的压缩方式,而header则供给用户进行添加一些动态的属性,从而实现一些定制化的工作。
通过对kafka消息日志的存储格式我们可以看出,其使用batch的方式将一些公共信息进行提取,从而保证其只需要存储一份,虽然看起来每个batch的头部信息比较多,但其平摊到每条消息上之后使用的字节更少了;在消息层面,kafka使用了数据增量的方式和Zig-Zag编码方式对数据进行的压缩,从而极大地减少其占用的字节数。总体而言,这种存储方式极大的减少了kafka占用的磁盘空间大小。
2. 日志存储方式
在使用kafka时,消息都是推送到某个topic中,然后由producer计算当前消息会发送到哪个partition,在partition中,kafka会为每条消息设置一个偏移量,也就是说,如果要唯一定位一条消息,使用<topic, partition, offset>三元组即可。基于kafka的架构模式,其会将各个分区平均分配到每个broker中,也就是说每个broker会被分配用来提供一个或多个分区的日志存储服务。在broker服务器上,kafka的日志也是按照partition进行存储的,其会在指定的日志存储目录中为每个topic的partition分别创建一个目录,目录中存储的就是这些分区的日志数据,而目录的名称则会以<topic-patition>的格式进行创建。如下是kafka日志的存储目录示意图:

这里我们需要注意的是,图中对于分区日志的存储,当前broker只会存储分配给其的分区的日志,比如图中的connect-status就只有分区1和分区4的目录,而没有分区2和分区3的目录,这是因为这些分区被分配在了集群的其他节点上。在每个分区日志目录中,存在有三种类型的日志文件,即后缀分别为log、index和timeindex的文件。其中log文件就是真正存储消息日志的文件,index文件存储的是消息的位移索引数据,而timeindex文件则存储的是时间索引数据。如下图所示为一个分区的消息日志数据:
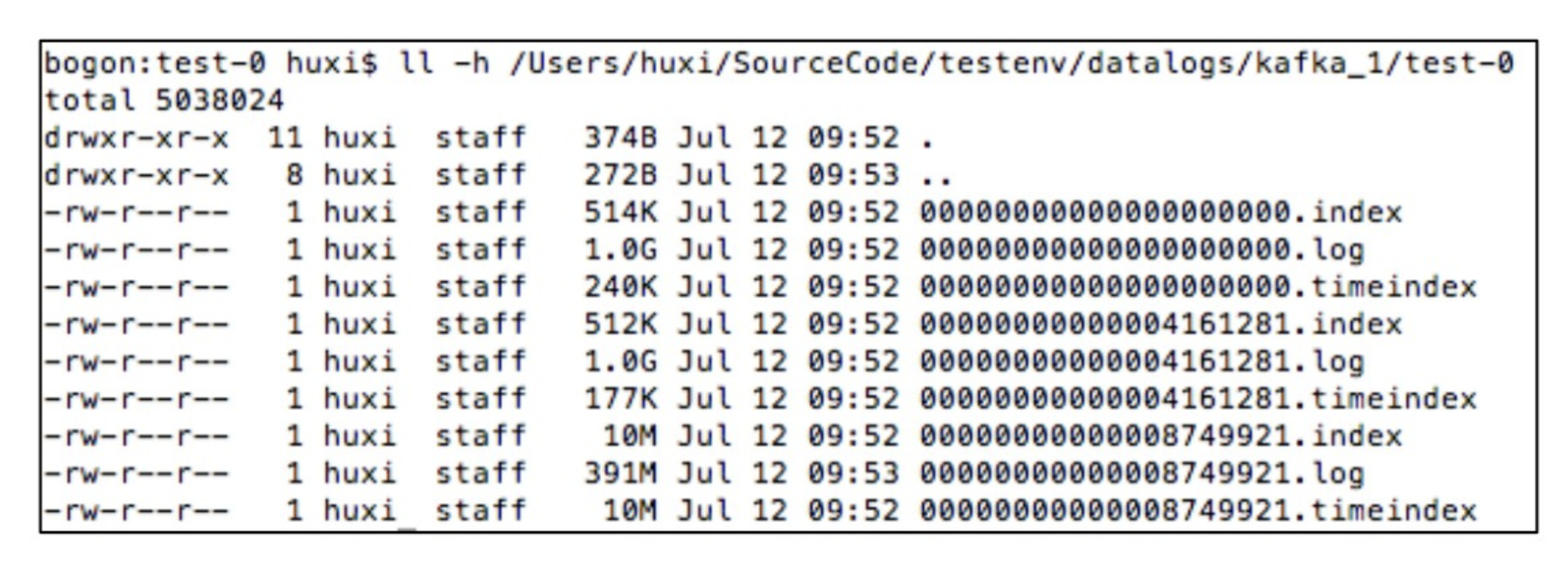
从图中可以看出,每种类型的日志文件都是分段的,这里关于分段的规则主要有如下几点需要说明:
- 在为日志进行分段时,每个文件的文件名都是以该段中第一条消息的位移的偏移量来命名的;
- kafka会在每个log文件的大小达到1G的时候关闭该文件,而新开一个文件进行数据的写入。可以看到,图中除了最新的log文件外,其余的log文件的大小都是1G;
- 对于index文件和timeindex文件,在每个log文件进行分段之后,这两个索引文件也会进行分段,这也就是它们的文件名与log文件一致的原因;
- kafka日志的留存时间默认是7天,也就是说,kafka会删除存储时间超过7天的日志,但是对于某些文件,其部分日志存储时间未达到7天,部分达到了7天,此时还是会保留该文件,直至其所有的消息都超过留存时间;
3. 索引文件
kafka主要有两种类型的索引文件:位移索引文件和时间戳索引文件。位移索引文件中存储的是消息的位移与该位移所对应的消息的物理地址;时间戳索引文件中则存储的是消息的时间戳与该消息的位移值。也就是说,如果需要通过时间戳查询消息记录,那么其首先会通过时间戳索引文件查询该时间戳对应的位移值,然后通过位移值在位移索引文件中查询消息具体的物理地址。关于位移索引文件,这里有两点需要说明:
-
由于kafka消息都是以batch的形式进行存储,因而索引文件中索引元素的最小单元是batch,也就是说,通过位移索引文件能够定位到消息所在的batch,而没法定位到消息在batch中的具体位置,查找消息的时候,还需要进一步对batch进行遍历;
-
位移索引文件中记录的位移值并不是消息真正的位移值,而是该位移相对于该位移索引文件的起始位移的偏移量,通过这种方式能够极大的减小位移索引文件的大小。如下图所示为一个位移索引文件的格式示意图:

如下则是具体的位移索引文件的示例:

关于时间戳索引文件,由于时间戳的变化比位移的变化幅度要大一些,其即使采用了增量的方式存储时间戳索引,但也没法有效地使用Zig-Zag方式对数据进行编码,因而时间戳索引文件是直接存储的消息的时间戳数据,但是对于时间戳索引文件中存储的位移数据,由于其变化幅度不大,因而其还是使用相对位移的方式进行的存储,并且这种存储方式也可以直接映射到位移索引文件中而无需进行计算。如下图所示为时间戳索引文件的格式图:

如下则是时间戳索引文件的一个存储示例:

可以看到,如果需要通过时间戳来定位消息,就需要首先在时间戳索引文件中定位到具体的位移,然后通过位移在位移索引文件中定位到消息的具体物理地址。
4. 日志压缩
所谓的日志压缩功能,其主要是针对这样的场景的,比如对某个用户的邮箱数据进行修改,其总共修改了三次,修改过程如下:
email=john@gmail.com
email=john@yahoo.com.cn
email=john@163.com
在这么进行修改之后,很明显,我们主要需要关心的是最后一次修改,因为其是最终数据记录,但是如果我们按顺序处理上述消息,则需要处理三次消息。kafka的日志压缩就是为了解决这个问题而存在的,对于使用相同key的消息,其会只保留最新的一条消息的记录,而中间过程的消息都会被kafka cleaner给清理掉。但是需要注意的是,kafka并不会清理当前处于活跃状态的日志文件中的消息记录。所谓当前处于活跃状态的日志文件,也就是当前正在写入数据的日志文件。如下图所示为一个kafka进行日志压缩的示例图:

图中K1的数据有V1、V3和V4,经过压缩之后只有V4保留了下来,K2的数据则有V2、V6和V10,压缩之后也只有V10保留了下来;同理可推断其他的Key的数据。另外需要注意的是,kafka开启日志压缩使用的是log.cleanup.policy,其默认值为delete,也即我们正常使用的策略,如果将其设置为compaction,则开启了日志压缩策略,但是需要注意的是,开启了日志压缩策略并不代表kafka会清理历史数据,只有将log.cleaner.enable设置为true才会定时清理历史数据。
在kafka中,其本身也在使用日志压缩策略,主要体现在kafka消息的偏移量存储。在旧版本中,kafka将每个consumer分组当前消费的偏移量信息保存在zookeeper中,但是由于zookeeper是一款分布式协调工具,其对于读操作具有非常高的性能,但是对于写操作性能比较低,而consumer的位移提交动作是非常频繁的,这势必会导致zookeeper称为kafka消息消费的瓶颈。因而在最新版本中,kafka将分组消费的位移数据存储在了一个特殊的topic中,即__consumer_offsets,由于每个分组group的位移信息都会提交到该topic,因而kafka默认为其设置了非常多的分区,也即50个分区。另外,consumer在提交位移时,使用的key为groupId+topic+partition,而值则为当前提交的位移,也就是说,对于每一个分组所消费的topic的partition,其都只会保留最新的位移。如果consumer需要读取位移,那么只需要按照上述格式组装key,然后在该topic中读取最新的消息数据即可。
5. 小结
本文首先对kafka的日志设计的优点进行了介绍,然后着重讲解了日志存储格式、日志目录规划、日志索引文件的格式以及日志压缩的功能。

