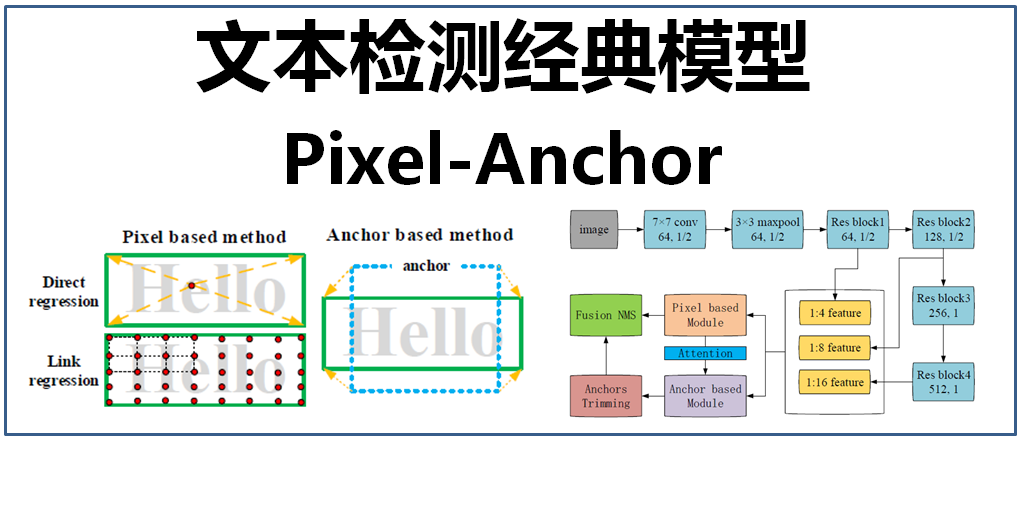
文本检测是深度学习中一项非常重要的应用,在前面的文章中已经介绍过了很多文本检测的方法,包括CTPN(详见文章:大话文本检测经典模型CTPN)、SegLink(详见文章:大话文本检测经典模型SegLink)、EAST(详见文章:大话文本检测经典模型EAST)、PixelLink(详见文章:大话文本检测经典模型PixelLink),这些文本检测方法主要分为两类,一类是基于像素级别的图像语义分割方法(pixel-based),另一类是采用通用目标检测(使用锚点)的方法(anchor-based),这两种方法的优劣如下:
- 基于像素级别的图像语义分割方法(pixel-based):通过图像语义分割获得可能的文本像素,通过像素点进行回归或对文本像素进行聚合得到文本框位置,经典的检测模型有PixelLink、EAST等。该方法具有较高的精确率,但对于小尺度的文本由于像素过于稀疏而导致检测率不高(除非对图像进行大尺度放大)。
- 采用通用目标检测(使用锚点)的方法(anchor-based):在通用物体检测的基础上,通过设置较多数量的不同长宽比的锚来适应文本尺度变化剧烈的特性,以达到文本定位的效果,经典的检测模型有CTPN、SegLink等。该方法对文本尺度本身不敏感,对小尺度文本的检测率高,但是对于较长且密集的文本行而言,锚匹配方式可能会无所适从(需要根据实际调整不同大小的网络感受野,以及锚的宽高比)。另外,由于该方法是基于文本整体的粗粒度特征,而不是基于像素级别的精细特征,因此,检测精度往往不如基于像素级别的文本检测。
pixel-based、anchor-based方法示意图如下:
那么有没有将pixel-based和anchor-based两种方法的优点结合在一起的检测方法呢?
答案是有的,这就是本文要介绍的端到端深度学习文本检测方法 Pixel-Anchor
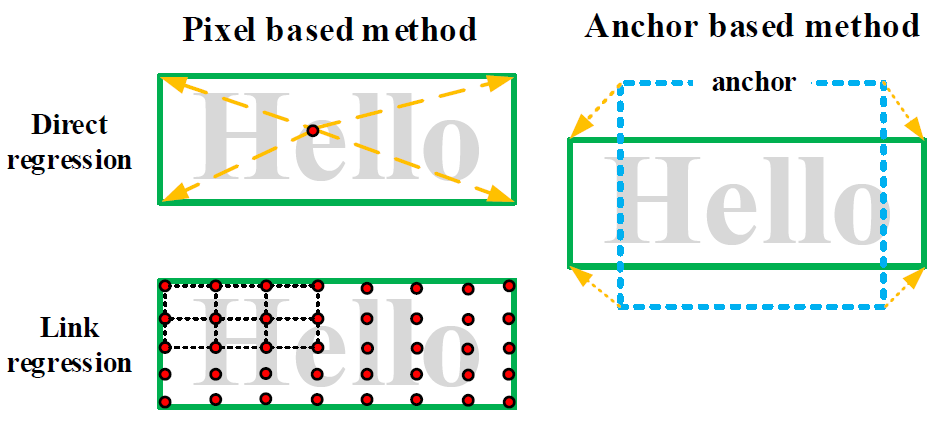
1、Pixel-Anchor网络结构
Pixel-Anchor的网络结构如下图所示:

该网络采用ResNet-50作为网络的主干结构(ResNet网络的介绍详见文章:大话CNN经典模型ResNet),提取出1/4, 1/8, 1/16的feature map(特征图)出来,作为像素级别语义分割模块(Pixel based Module)和锚检测回归模块(Anchor based Module)的基础特征,通过特征共享的方式把像素级别语义分割和锚检测回归放入到一个网络之中,其中,pixel-based模块得到的输出结果通过注意力机制送入到anchor-based模块中(注意力机制的介绍详见文章:大话注意力机制),使得锚检测回归模块检测效率高、精确度高,最后通过融合NMS(非极大值抑制)得到最终的检测结果。
下面分别对像素级别语义分割模块(Pixel based Module)和锚检测回归模块(Anchor based Module)进行介绍。
2、像素级别语义分割模块(Pixel based Module)
该模块的结构如下:
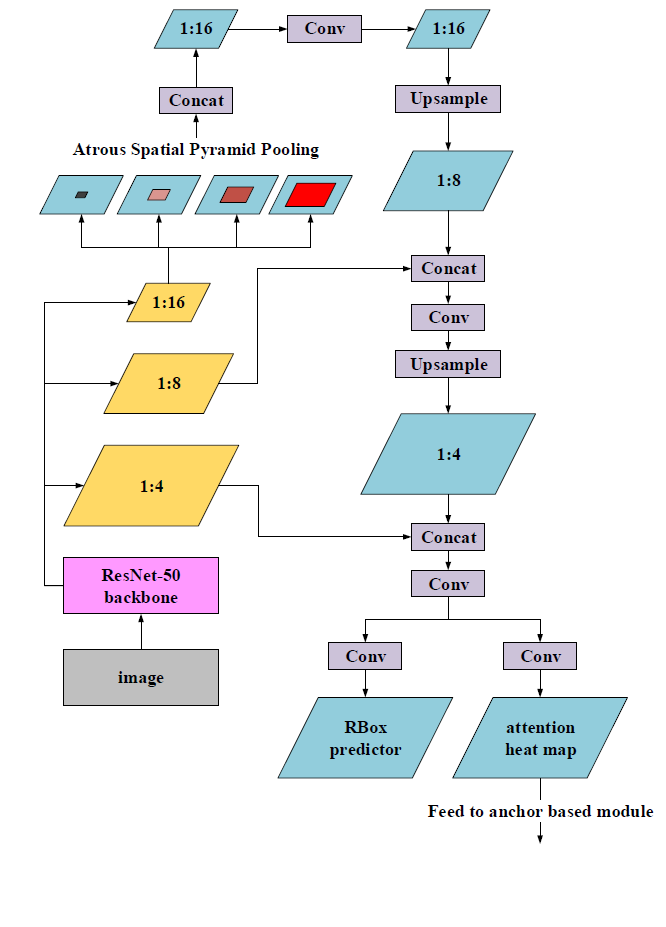
该结构将FPN(特征金字塔网络)、ASPP(Atrous Spatial Pyramid Pooling,膨胀空间金字塔池化)操作组合在一起进行特征提取和处理。
输入图像首先经过ResNet-50主干网络分别提取出1/4, 1/8, 1/16的feature map(特征图)形成特征金字塔。在1/16的feature map(特征图)中,为了既不牺牲特征空间分辨率,又可扩大特征感受野,采用了ASPP(Atrous Spatial Pyramid Pooling,膨胀空间金字塔池化)方法,这是一种低代价(low cost)的增加网络感受野的方法。那什么是ASPP方法呢?
ASPP是利用Atrous Convolution(膨胀卷积),将不同扩张率的扩张卷积特征结合到一起(如取最大值),如下图:
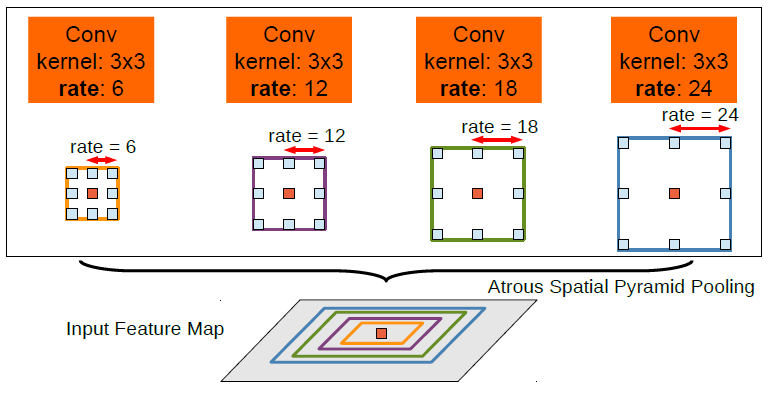
在这个pixel-based模块中设置ASPP的膨胀率为{3, 6, 9, 12, 15, 18}。接着作一次卷积操作(Conv),再用因子为2倍的双线性插值进行上采样(Upsample),特征图变为1/8,并和来自网络主干的1/8特征图进行拼接(concat)。接下来重复一次,先做卷积(Conv),再进行上采样(Upsample),特征图变为1/4,并和来自网络主干的1/4特征图进行拼接(concat)。最后输出两部分:旋转框预测器(RBox predictor)和注意力热力图(attention heat map)。
- 旋转框预测器(RBox predictor)的结果包括6个通道,分别是每个像素是文本的可能性、该像素到所在文本边界框的上下左右距离、文本边界框的旋转角度。
- 注意力热力图(attention heat map)包括一个通道,表示每个像素是文本的可能性,将输出到anchor-based模块。
3、锚检测回归模块(Anchor based Module)
该模块的结构如下图:
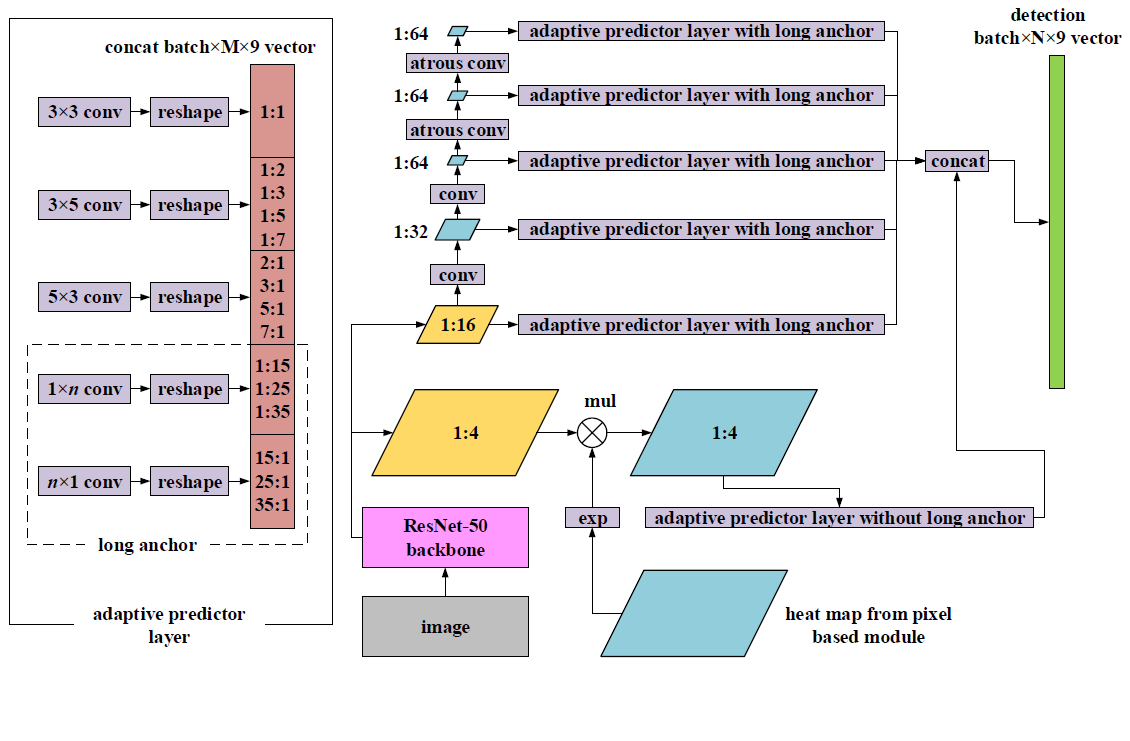
先看该图的右半部分,该模块主要是针对输入图像在ResNet-50中提取的1/4特征图、1/16特征图进行操作。
- 对于1/4特征图,由于其处于底层,具有一定的分辨率,对于检测较小的文字具有一定优势,另外,为了增加该层的语义信息,还与pixel-based模块输出的注意力热力图(attention heat map)进行exp操作(exponential)和点乘,exp操作使每个像素成为正样本文本的概率映射到[1.0,e]范围之内,既可保留背景信息,又加强检测信息,可很大程度上减少错误检测。
- 对于1/16特征图,为了获取更大的感受野、获得多尺度信息,进一步进行特征提取,分别为1/32特征图、1/64特征图、1/64特征图、1/64特征图,其中,为避免出现很小的特征图,在后面两个特征图中,采用了atrous conv(膨胀卷积),以实现分辨率不变,并能获得较大感受野,这四层特征图在其后都加入APL层(adaptive predictor layer,自适应预测层)。
APL层(adaptive predictor layer,自适应预测层),见上图的左半部分,该层分别为不同的卷积核搭配不同的宽高比锚,以适应不同尺度、不同角度的文本。主要分为以下5类:
- a)、正方形anchors:宽高比=1:1,卷积滤波器大小为3x3,主要为了检测方正规整的文字;
- b)、中等水平anchors:宽高比={1:2,1:3,1:5,1:7},卷积滤波器大小为3x5,主要为了检测水平倾斜的文字;
- c)、中等垂直anchors:宽高比={2:1,3:1,5:1,7:1},卷积滤波器大小为5x3,主要为了检测垂直倾斜的文字;
- d)、长的水平anchors:宽高比={1:15,1:25,1:35},卷积滤波器大小为1xn,主要为了检测水平长行的文字;
- e)、长的垂直anchors:宽高比={15:1,25:1,35:1},卷积滤波器大小为nx1,主要为了检测竖排长行的文字。
经过以上APL层之后,将得到的proposal(候选框)进行拼接,从而预测最终的四边形区域。
为了实现对密集文本的检测,作者还提出了anchor density(锚密度),如下图:
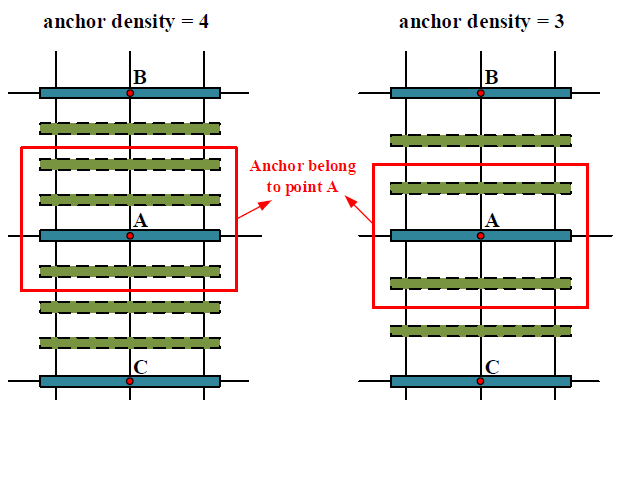
每个anchor(锚点)通过复制出一些偏移量以更好地覆盖密度文本,主要有:
- 正方形anchor在水平和垂直方向都进行复制
- 水平anchor在垂直方向复制
- 垂直anchor在水平方向复制
4、后处理
在推导阶段,采用融合NMS(非极大值抑制)方法获得最终的检测结果,用anchor-based模块检测小文本和长文本,用pixel-based模块检测中等大小的文本。在anchor-based模块,1/4特征图上的所有anchor(锚点)和在其它特征图上的所有长anchor(锚点)都会被保留下来,这些anchors足够覆盖小文本,而对于长文本、大角度文本,不具有检测能力;在pixel-based模块,将小于10像素,以及宽高比不在[1:15, 15:1]范围内的文字过滤掉。最终,收集所有保留的候选文本框,通过融合NMS方法获得最终的检测结果。
5、Pixel-Anchor检测效果
Pixel-Anchor在小文本、大角度文本、长文本行,以及自然场景文本检测中,均取得了比较好的效果,如下图:
(1)小文本检测效果

(2)大角度文本检测效果

(3)长文本行检测效果

(4)自然场景文本检测效果(基于ICDAR 2015)

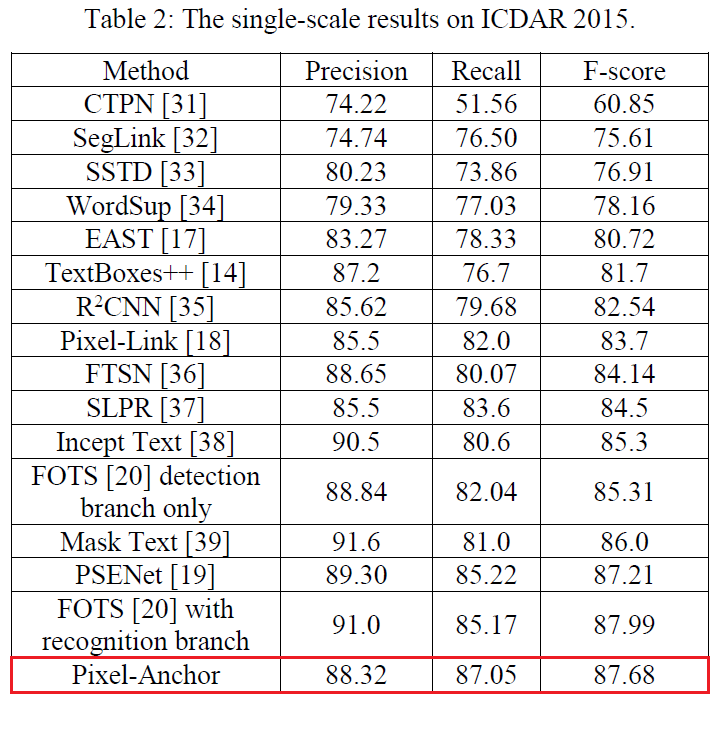
经在ICDAR 2015数据集上进行测试,并与CTPN、SegLink、EAST、Pixel-Link等方法进行对比,Pixel-Anchor方法的检测效果非常不错,如下表:
6、总结
Pixel-Anchor作为一个端对端的深度神经网络框架,对各种尺度、角度的文本均有很不错的检测效果,主要有两大创新点:
- 第一是把像素级别的图像语义分割以及基于锚的检测回归方法通过共享基础特征、注意力机制高效融合在一起,使文本检出率高、精准度高,实现可端到端训练的检测网络。
- 第二是在锚点检测回归这个模块中引入了APL层(Adaptive Predictor Layer,自适应预测层),该层根据各特征图感受野的不同,调整锚的长宽比、卷积核的形状以及锚的空间密度,以高效地获取各特征图上的文本检测结果,适应性更强。
欢迎关注本人的微信公众号“大数据与人工智能Lab”(BigdataAILab),获取更多信息
推荐相关阅读
1、AI 实战系列
2、大话深度学习系列
3、图解 AI 系列
4、AI 杂谈
5、大数据超详细系列

