时间序列是对某一个或者一组变量 x(t) 进行观察测量,将在一系列时刻 t1,t2,⋯,tn 所得到的离散数字组成的序列集合。
时间序列预测的机器学习的一种常见应用,例如预测股票和金融产品价格走势, 温度,天气的走势等等
传统的统计学时间序列预测的一些方法包括:
- AR (自回归模型 Auto Regression)
- MA (移动平均 Moving Average )
- ACF/PACF (自相关和偏自相关)
- ARIMA (AR和MA模型的结合)
-
卡尔曼滤波
但是这些传统的基于统计的方法用起来并不方便,你可能需要利用ACF/PACF找到一些时序数据的规律然后设置超参数来进行时序数据的分析。
facebook开源的prophet是另一个选择,利用prophet来进行时许数据的分析比较简单,但是本质上,prophet是基于另一盒开源工具pystan,仍然是基于统计来进行时序数据的分析。
利用深度神经网络,例如LSTM,我们也可以很方便的进行时序数据的分析,那么我们就看看如可利用TensorflowJS来进行时序数据的分析吧。
数据导入
我们要分析的数据集是一组模拟的航空旅客的数据信息,如下图:
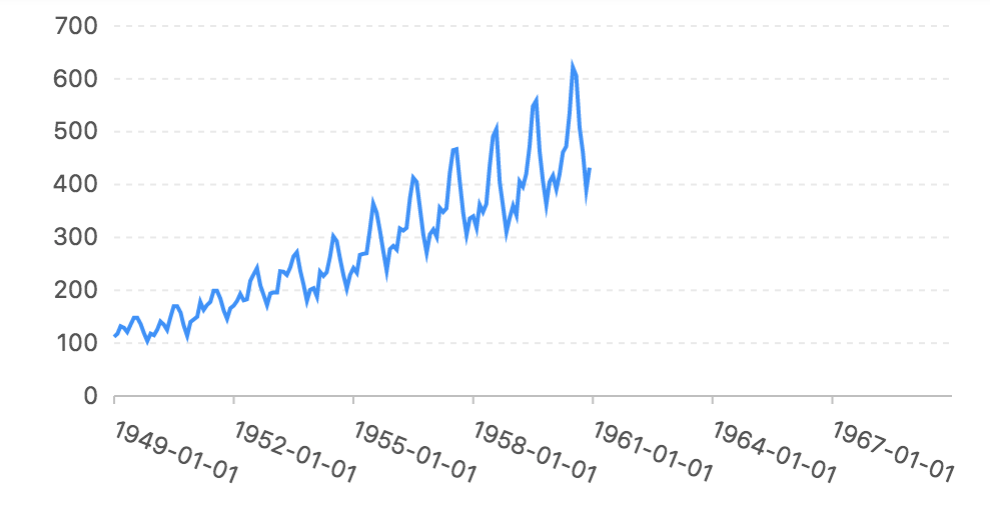
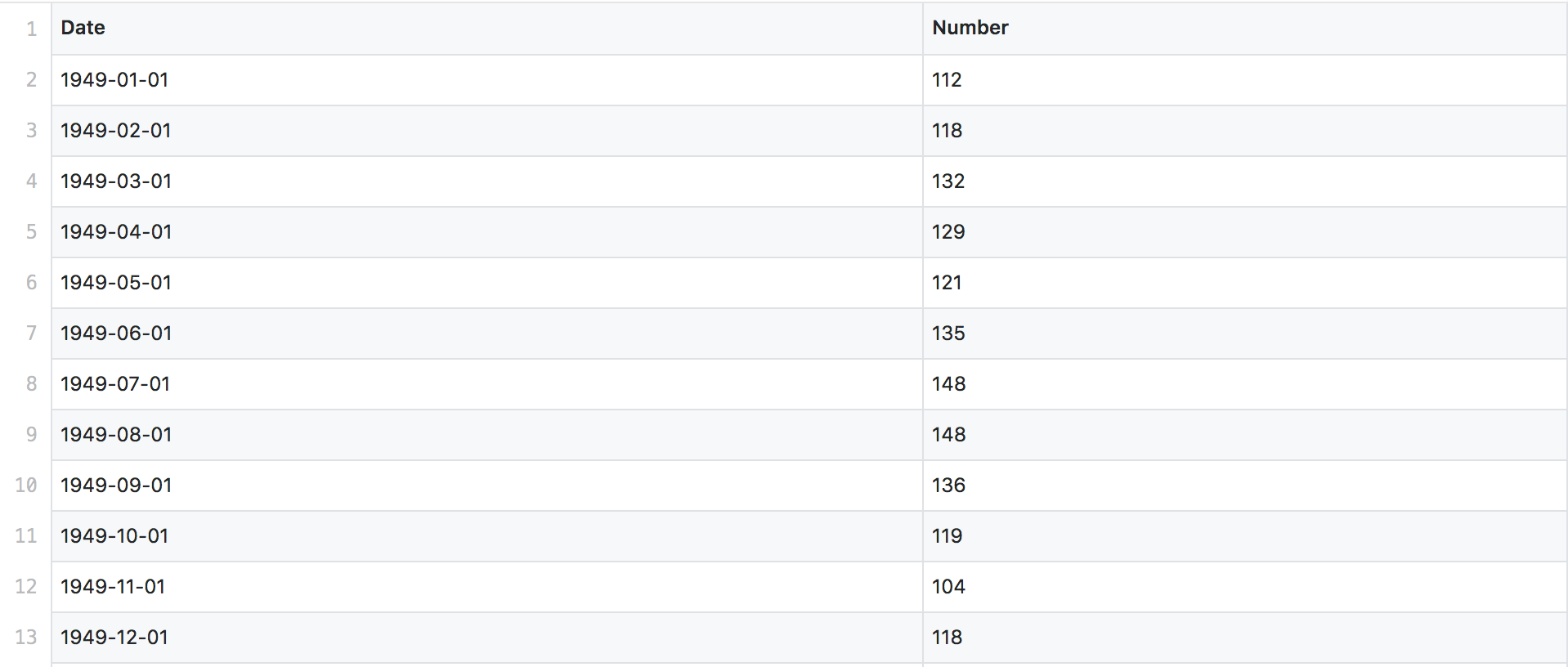
这组数据可以看成一个线性模型和一个震荡模型(正余弦)的叠加,我们看看LSTM能不能学习出这个规律。
async function loadData(path) {
return await d3.csv(path);
}
const airPassagnerData = await loadData(
"https://cdn.jsdelivr.net/gh/gangtao/datasets@master/csv/air_passengers.csv"
);
数据准备
在数据准备阶段,我们要为我们的LSTM模型准备训练数据。
首先我们对数据进行做一个标准化操作:
// Normalize data with value change
let changeData = [];
for (let i = 1; i < airPassagnerData.length; i++) {
const item = {};
item.date = airPassagnerData[i].Date;
const val = parseInt(airPassagnerData[i].Number);
const val0 = parseInt(airPassagnerData[i - 1].Number);
item.value = val / val0 - 1;
changeData.push(item);
}
也就是把绝对数据变成涨跌的百分比,标准化后的数据都在 -1 和 +1之间,反映了数据相对于前一个时间点的涨跌。
然后就是就是准备训练数据了,在准备训练数据之前,我们要理解一下LSTM的输入数据的形状:
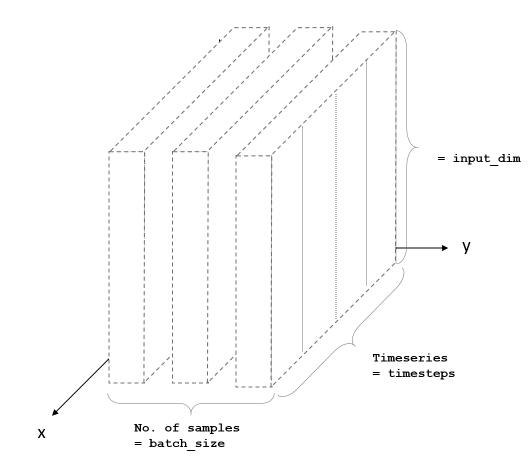
LSTM需要一个三维的数据输入,分别对应Batch(数据是一批一批进入神经网络训练),Input是输入数据的size和Timestep,时间。所以我们在构造训练数据的时候,需要针对时间维度创建训练数据。
const STEP_SIZE = 3;
const STEP_NUM = 24;
const STEP_OFFSET = 1;
const TARGET_SIZE = 12;
function buildX(data, stepSize, stepNum, stepOffset) {
let xData = [];
for (let n = 0; n < stepNum; n += 1) {
const startIndex = n * stepOffset;
const endIndex = startIndex + stepSize;
const item = data.slice(startIndex, endIndex).map(obj => obj.value);
xData.push(item);
}
return xData;
}
function makeTrainData(data, stepSize, stepNum, stepOffset, targetSize) {
const trainData = { x: [], y: [] };
const length = data.length;
const xLength = stepSize + stepOffset * (stepNum - 1);
const yLength = targetSize;
const stopIndex = length - xLength - yLength;
for (let i = 0; i < stopIndex; i += 1) {
const x = data.slice(i, i + xLength);
const y = data.slice(i + xLength + 1, i + xLength + 1 + yLength);
const xData = buildX(x, stepSize, stepNum, stepOffset);
const yData = y;
trainData.x.push(xData.map(item => item));
trainData.y.push(yData.map(item => item.value));
}
return trainData;
}
const trainData = makeTrainData(
changeData,
STEP_SIZE,
STEP_NUM,
STEP_OFFSET,
TARGET_SIZE
);
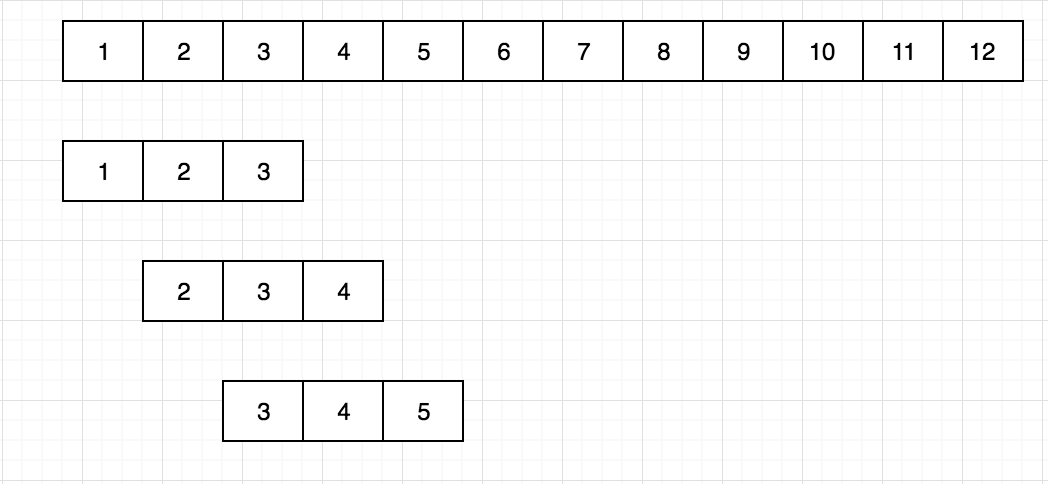
这里我们利用滑动时间窗口的方法来构建训练数据,用到了以下几个参数:
- STEP_SIZE
这个是数据窗口的大小,3表示每一个数据包含三个值,数据input维度就是3
- STEP_NUM
这个是一共要走多少步,24表示走24步,那个Time维度就是24
- STEP_OFFSET
这个offset决定了时间窗口向前移动的时候,每次走多少个时间单位,我这里取1,也就是每次走一步,这样第一个数据和第二个数据其实存在两个重复值。
- TARGET_SIZE
这个是我要预测的时间长度,12表示预测12个月的数据。
模型构建
模型的构建代码如下:
function buildModel() {
const model = tf.sequential();
//lstm input layer
const hidden1 = tf.layers.lstm({
units: LSTM_UNITS,
inputShape: [STEP_NUM, STEP_SIZE],
returnSequences: true
});
model.add(hidden1);
//2nd lstm layer
const output = tf.layers.lstm({
units: TARGET_SIZE,
returnSequences: false
});
model.add(output);
model.add(
tf.layers.dense({
units: TARGET_SIZE
})
);
model.add(tf.layers.activation({ activation: "tanh" }));
//compile
const rmsprop = tf.train.rmsprop(0.005);
model.compile({
optimizer: rmsprop,
loss: tf.losses.meanSquaredError
});
return model;
}
我们的网络一共有两个LSTM层,一个Dense层和一个激活层。优化器我们选择了rmsprop,损失函数是mse,因为我们其实一个回归模型。
利用TensorflowJS提供的模型导出功能,我们可以导出训练好的模型,并利用Netron(一个神经网络可视化工具,支持各种神经网络)来查看我们的模型。
const saveResults = await model.save('downloads://model-name');
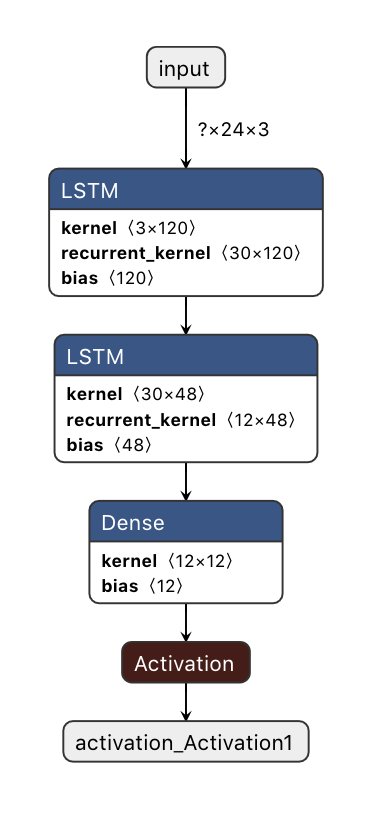
我第一次用Netron的时候,TensorflowJS导出的JSON模型有错误,我给作者提了一个Issue,当天修复,赞一个!
模型训练
训练数据和模型都准备好了,下一步我们就开始训练了。
async function trainBatch(data, model) {
const metrics = ["loss", "val_loss", "acc", "val_acc"];
const container = {
name: "show.fitCallbacks",
tab: "Training",
styles: {
height: "1000px"
}
};
const callbacks = tfvis.show.fitCallbacks(container, metrics);
console.log("training start!");
tfvis.visor();
const epochs = config.epochs;
const results = [];
const xs = tf.tensor3d(data.x);
const ys = tf.tensor2d(data.y);
const history = await model.fit(xs, ys, {
batchSize: config.batchSize,
epochs: config.epochs,
validationSplit: 0.2,
callbacks: callbacks
});
console.log("training complete!");
return history;
}
const trainData = makeTrainData(
changeData,
STEP_SIZE,
STEP_NUM,
STEP_OFFSET,
TARGET_SIZE
);
const model = buildModel();
model.summary();
为了监控训练的过程,我们使用了tfvis,它在DOM中提供了一个可视化的框架,可以很方便的监控训练过程。
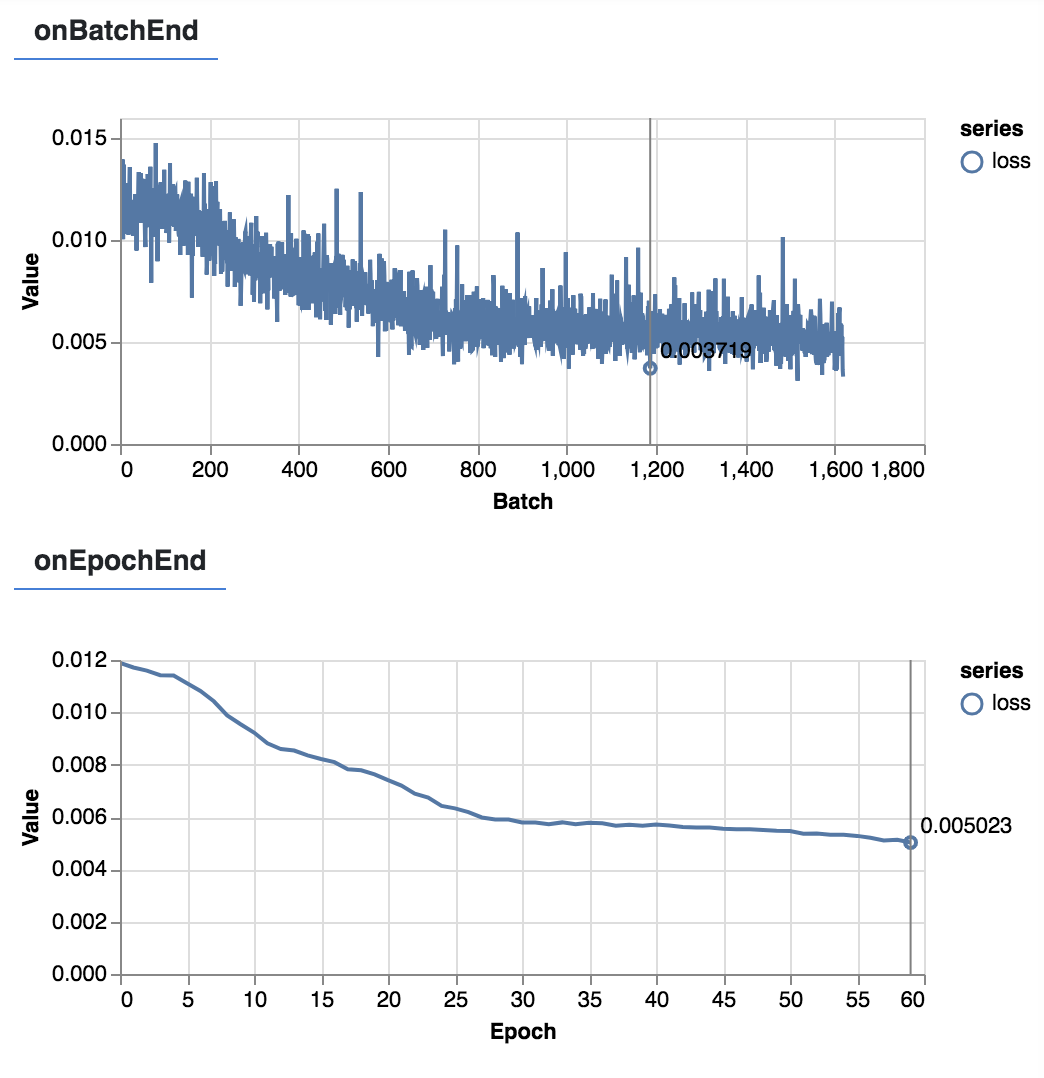
我们发现,从开始到第30的迭代,损失指标有明显的下降,这正是我们希望看到的,30个迭代后,损失下降的不明显。
预测
最后我们可以预测了,注意预测的时候,我们需要把标准化的涨跌数据还原为实际的值。
async function predict(model, input) {
const prediction = await model.predict(tf.tensor([input])).data();
return prediction;
}
const inputStart = changeData.length - X_LEN;
const inputEnd = changeData.length;
const input = changeData.slice(inputStart, inputEnd);
const predictInput = buildX(input, STEP_SIZE, STEP_NUM, STEP_OFFSET);
const prediction = await predict(model, predictInput);
// re-constructe predicted value based on change
const base = airPassagnerData[airPassagnerData.length-1];
const baseDate = moment(new Date(base.Date));
const baseValue = parseInt(base.Number);
let predictionValue = [];
let val = baseValue;
for( let i = 0; i < prediction.length; i+=1) {
const item = {};
const date = baseDate.add(1, 'months');
item.time = moment(date).format('YYYY-MM-DD');
item.value = val + val * prediction[i];
item.isPrediction = "Yes";
predictionValue.push(item);
val = item.value;
}
console.log(predictionValue);
let airPassagnerDataWithPrediction = [];
chartData.forEach(item => {
item.isPrediction = "No";
airPassagnerDataWithPrediction.push(item);
})
predictionValue.forEach(item => {
airPassagnerDataWithPrediction.push(item);
})
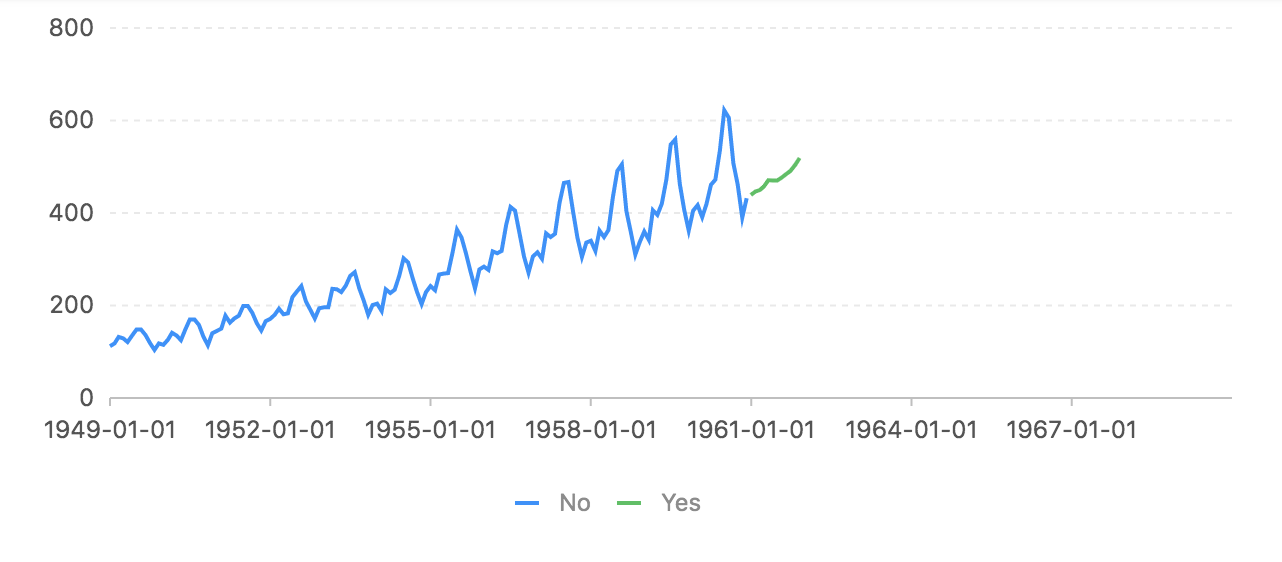
上图是训练了一个迭代后的结果。
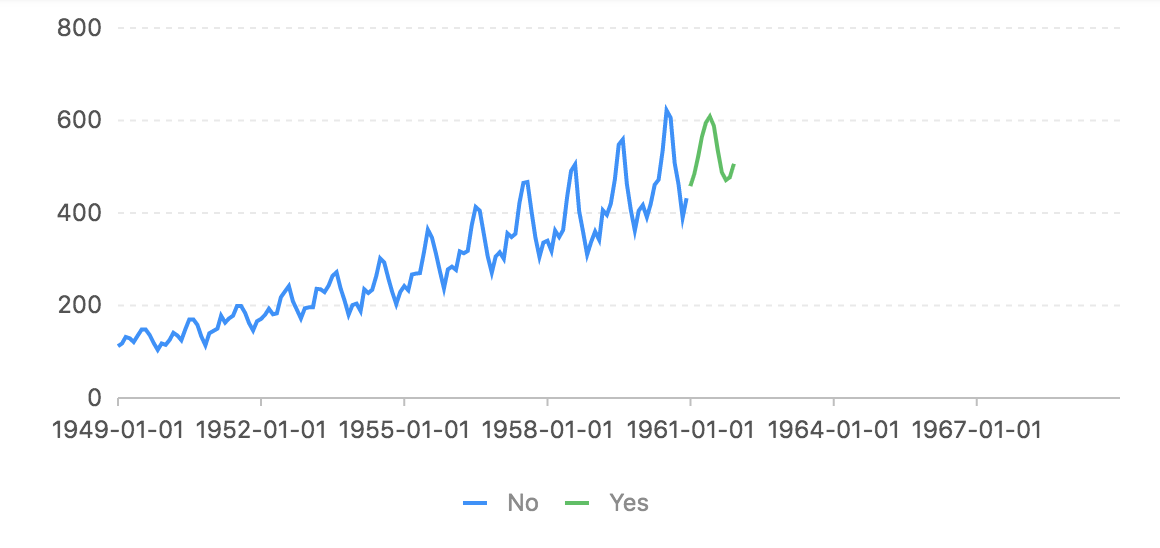
上图是10个迭代后的结果。
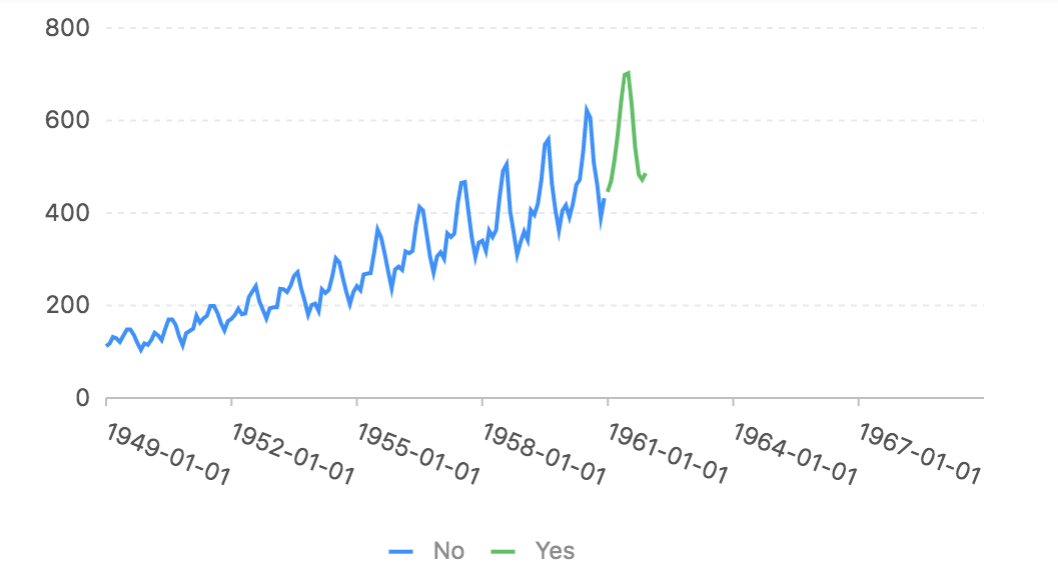
上图是我训练30个迭代后的结果,感觉LSTM很好的学习到了趋势和震荡。有兴趣的同学可以去跑我在Codepen上的代码。或者我的gist
总结
本文提供了一个使用LSTM来预测时间序列的例子。有一些经验分享给大家:
- 对于输入数据,一开始是的size是1,但是训练的效果很差,为了有好的训练效果,把Size增加到3,结果很不错。
- LSTM会有梯度消失的问题,如果选择合适的网络结构,参数需要有相当的经验和尝试。
- 在本文的问题中,复杂和更深的网络并不能带来效果的明显提升。
- 我们利用窗口滑动获取训练数据的过程和卷积操作很想,据说利用CNN也可以达到不错的效果,有兴趣的同学可以试一下。
参考

