对于云上的用户来说,业务日志里面报超时问题处理起来往往比价棘手,因为1) 问题点可能在云基础设施层,也有可能在业务软件层,需要排查的范围非常广;2) 这类问题往往是不可复现问题,抓到现场比较难。在本文里就分析下如何来分辨和排查这类问题的根本原因。
业务超时 != 网络丢包
由于业务的形态不同,软件实现语言和框架的不同,业务日志中打印出的信息可能是各不相同,比如如下关键字:
"SocketTimeOut", "Read timed out", "Request timeout" 等
从形式看都属于网络超时这一类,但是需要明确一个概念:这类问题是发生的原因是请求超过了设定的timeout时间,这个设置有可能来自客户端,服务器端或者网络中间节点,这是直接原因。网络丢包可能会导致超时,但是并不是充分条件。总结业务超时和网络丢包的关系如下:
网络丢包可能造成业务超时,但是业务超时的原因不一定是丢包。
明确了这个因果关系后,我们再来看怎么分析业务超时。如果武断地将业务超时等同于网络抖动丢包,那这个排查分析过程就完全错过了业务软件层本身的原因,很容易进入困局。
本文会从云基础设施层和业务软件层对业务超时做分析,总体来讲基础设置层面的丢包原因相对容易排查,阿里云有完善的底层监控,根据业务日志报错的对应时间段,从监控数据中可以确定是否有基础设施网络问题。而业务层的超时通常是软件层面的设置,和软件实现及业务形态都有关系,这种往往是更加难以排查的。
网络丢包为什么导致业务超时
网络抖动可能造成业务超时,其主要原因是网络抖动会带来不同程度的延迟。本文以互联网大部分应用以来的TCP为对象来介绍,一个丢包对数据传输的完整性其实是没有影响的,因为TCP协议本身已经有精密的设计来处理丢包,乱序等异常情况。并且所有重传的处理都在内核TCP协议栈中完成,操作系统用户空间的进程对这个处理实际上是不感知的。丢包唯一的副作用的就是会增加延迟,如果这段延迟的时间足够长,达到了应用进程设置的某个Timeout时间,那么在业务应用侧表现出来的就是业务超时。
丢包出现时会不会发生超时,取决于应用进程的Timeout设置。比如数据传输中的只丢了一个TCP数据包,引发200 ms后的超时重传:
- 如果应用设置的Timeout为100 ms,TCP协议栈没有机会重传,应用就认为超时并关闭连接;
- 如果应用设置的Timeout为500 ms,则TCP协议栈会完成重传,这个处理过程对应用进程透明。应用唯一的感知就是处理这次报文交互比基线处理时长多了200 ms,对于时间敏感度不是非常高的应用来说这个影响非常小。
延迟到底有多大?
在设置应用进程Timeout时间时有没有可以参考的定量值呢?虽然TCP中的RTT/RTO都是动态变化的,但TCP丢包的产生的影响可以做一定的定量总结。
对丢包产生的延迟主要有如下两类:
- TCP建连超时。如果网络抖动不幸丢掉了TCP的第一个建连SYN报文,对与不太老的内核版本来说,客户端会在1秒(Draft RFC 2988bis-02中定义)后重传SYN报文再次发起建连。1秒对于内网环境来说非常大,对于阿里云一个区域的机房来说,正常的RTT都是小个位数毫秒级别,1秒内如果没有丢包足够完成百个数据报的交互。
- TCP中间数据包丢包。TCP协议处理中间的数据丢包有快速重传和超时重传两种机制。快速重传通常比较快,和RTT相关,没有定量的值。超时重传 (RTO, Retrasmission Timeout) 也和RTT相关,但是Linux中定义的RTO的最小值为,TCP_RTO_MIN = 200ms。所以在RTT比较小的网络环境下,即使RTT小于1ms,TCP超时重传的RTO最小值也只能是200ms。这类丢包带来的延迟相对小。
除了丢包,另外一类比较常见的延迟是TCP Delayed ACK带来的延迟。这个和协议设计相关,和丢包其实没有关系,在这里一并总结如延迟定量部分。在交互式数据流+Nagle算法的场景下比较容易触发。Linux中定义的Delayed ACK的最小值TCP_DELACK_MIN是40 ms。
所以总结下来有如下几个定量时间可以供参考:
- 40 ms, 在交互数据流中TCP Delayed ACK + Nagle算法开启的场景,最小delay值。
- 200 ms,在RTT比较小的正常网络环境中,TCP数据包丢包,超时重传的最小值。
- 1 s,较新内核版本TCP建立的第一个SYN包丢包时的重传时间,RFC2988bis中定义的initial RTO value TCP_TIMEOUT_INIT。
- 3 s, 较老内核版本TCP建立的第一个SYN包丢包时的重传时间,RFC 1122中定义的initial RTO value TCP_TIMEOUT_INIT。
云基础设施网络丢包
基础设施网络丢包的原因可能有多种,主要总结如下3类:
云基础设施网络抖动
网络链路,物理网络设备,ECS/RDS等所在的宿主机虚拟化网络都有可能出现软硬件问题。云基础设施已经做了完备的冗余,来保证出现问题时能快速隔离,切换和恢复。
现象: 因为有网络冗余设备并可以快速恢复,这类问题通常表现为某单一时间点网络抖动,通常为秒级。抖动的具体现象是在那个时段新建连接失败,已建立的连接中断,在业务上可能表现为超时。
影响面: 网络设备下通常挂很多主机,通常影响面比较大,比如同时影响多个ECS到RDS的连接。
云产品的限速丢包
很多网络云产品在售卖的时候有规格和带宽选项,比如ECS, SLB, NAT网关等。当云产品的流量或者连接数超过规格或者带宽限制时,也会出现丢包。这种丢包并非云厂商的故障,而是实际业务流量规模和选择云产品规格时的偏差所带来。这种问题通常从云产品提供的监控中就能分辨出来。
现象: 当流量或者连接数超过规格时,出现流量或者连接丢弃。问题可能间断并持续地出现,网络流量高峰期出现的概率更大。
影响面: 通常只影响单一实例。但对于NAT网关做SNAT的场景,可能影响SNAT后的多个实例。
运营商网络问题
在走公网的场景中,客户端和服务器之间的报文交互往往要经过多个AS (autonomous system)。若运营商中间链路出现问题往往会导致端到端丢包。
现象: 用双向mtr可以看到在链路中间某跳开始丢包。
影响面: 影响面可能较大,可能影响经过某AS链路的报文交互。但是对于单用户来说看到的影响通常只是对特定实例。
应用设置的Timeout引发的超时
上面分析了几种基础设施因为异常或限速等原因丢包导致应用超时的情况,总体来说只要能找出丢包点,就基本能找出根因。但有些情况下,各种网络监控表明并没有任何丢包迹象,这个时候就要从应用侧面来继续排查下了。因为应用的形态多样,下面以两个典型例子来说明为什么在没有网络丢包的情况下也会出现业务日志中的超时。
ECS云主机访问第三方API超时的例子
问题现象
用户云上ECS服务器需要通过HTTP协议访问第三方服务器的API,但是发现业务日志中时不时出现访问第三方API时的"Request timeout"报错,需要查出根因。
排查思路
- 根据基本思路,先从监控中查看ECS实例及链路有没有丢包。结果发现并没有能和业务日志中出现timeout报错时间点吻合的丢包。
- 在这种情况下,只能进一步利用问题复现时的抓包来一探究竟了。
抓包分析
拿到抓包后,可以通过Wireshark的“分析-专家信息”或者如下表达式来过滤是否有重传。
tcp.analysis.retransmission
结果确实没有看到任何一个丢包,这个也反证了该问题并非由丢包引起。如果不是丢包引起,那为什么会产生问题呢?这时候需要进一步来分析抓包。
我们可以注意到:在业务日志里其实有"Request Timeout"这样的关键字,从字面理解就是往外的HTTP请求超时。用HTTP协议的话来说,可以翻译成:“HTTP请求已经发给对端,但是在一段时间内对端并没有返回完整的响应”。沿着这个思路,我们可以看下报文里是否存在只有HTTP请求而没有HTTP响应的情况。在Wireshark里,可以用如下方法过滤没有HTTP响应的HTTP请求:
http.request.method == GET && !http.response_in
果然,我们发现了一些这样的HTTP请求。选择其中的一个HTTP请求,然后跟一下TCP stream看下报文交互的全过程如下:

根据抓包会有如下一些发现:
- TCP stream中可以看到一个TCP连接上有2个HTTP请求,所以ECS访问第三方API是用的长连接。
- 第一次HTTP GET请求(735号包),在65 ms后返回(778号包)。
- 第二次HTTP GET请求(780号包)没有对应的HTTP响应返回 (我们正是通过这个条件过滤的报文)。
- 第954号包,客户端没等收到HTTP响应就主动FIN掉了TCP连接。这是个很异常的行为,并且是客户端发起的。仔细观察FIN和第二个HTTP GET请求发出的时间间隔,发现大约300 ms。接着查看其他没有响应的HTTP stream,这个时间间隔大约300 ms。
至此我们有理由推断是ECS服务器在对第三方API发出HTTP请求300 ms后主动FIN掉了TCP连接。这可能是程序中客户端设置的超时时间,业务程序超时后可能有自己的重试逻辑。
用户最后确认了业务软件中有该超时设置。
问题总结
1) 那这个300 ms的超时时间设置是否合理呢?
从抓包中可以看出,ECS对端API服务器的RTT大约7 ms左右,推断是一个同城的访问。对于个位数毫秒级别的RTT,300 ms的超时时间其实已经有一定余量了,并且甚至可能可以允许一次超时重传(200 ms)。
2) 问题的根因?
该问题主要是由于对端API服务器处理请求的速度不稳定造成。有些请求在几十毫秒内就处理返回完,有些300 ms都没有处理完。这个不稳定可能和API服务器的资源水位和压力相关,但是这个是黑盒,需要对端分析了。
3) 解决方案
1> 最佳解决方案是联系对端API服务器的owner找到根因并根除。
2> 临时解决方案是调整增大ECS上设置的客户端超时时间。
ECS内网访问自建Redis超时的例子
ECS访问云服务RDS/Cache或者自建数据库/Cache超时是另外一类问题,下面用一个ECS内网访问字节Redis超时来说明这类问题。
问题现象
ECS上用Redis客户端Jedis访问自建在ECS上的Redis服务器,偶尔会出现如下报错:
redis.clients.jedis.exceptions.JedisConnectionException: java.Net.SocketTimeoutException: Read timed out
排查思路
- 这类问题很常见的原因是Redis慢查询,用户自查了Redis的大key和慢查询情况,没有发现时间特别长的查询。所以需要在网络层面进一步确认。
- 根据基本思路,先从监控中查看ECS实例及链路有没有丢包。结果发现并没有能和"Read timed out"报错时间点吻合的丢包。
- 进一步利用问题复现时的抓包来一探究竟了。因为问题偶发,需要在客户端利用tcpdump -C -W参数部署循环抓包,问题出现后停止循环抓包来查看。
抓包分析
拿到抓包后,同样先看有没有丢包重传,结果是没有发现丢包重传。和上一个例子不同,这个例子没有办法通过一定特征来过滤数据包。所以只能根据Jedis日志报错的时间点找到对应包的位置来进一步看有没有什么线索。
根据Jedis日志报错的时间点找到对应的报文,跟TCP stream看下报文交互的全过程如下(Jedis客户端是9.20,Redis服务器端是20.66):
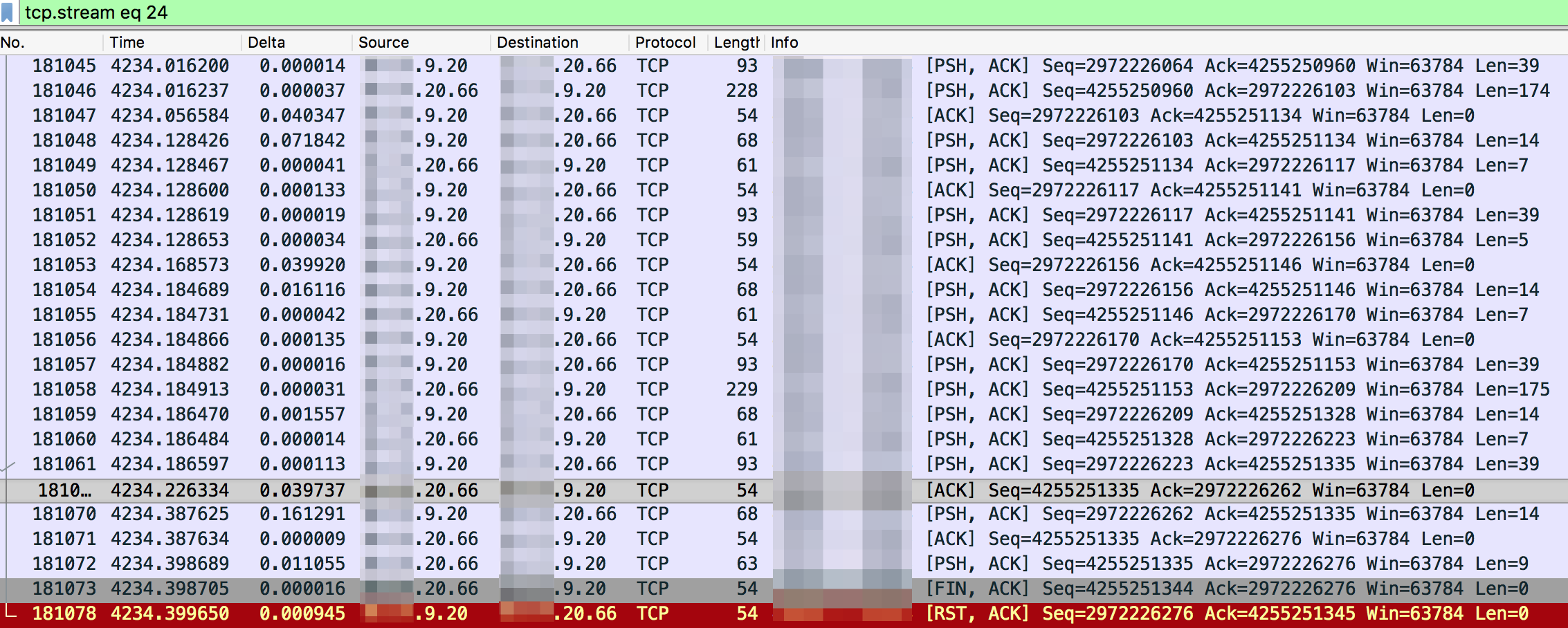
根据抓包有如下一些发现:
- 可以看到中间没有重传,网络上看起来是正常的。
- 客户端利用长连接访问服务器端,在结束连接之前已经包了非常多的Redis请求和响应。
- 181073 号包是服务器端FIN掉了连接,181078号包客户端接着发了TCP Reset。
上面这些信息量显然是不够说明为什么有"Read timed out"的报错。最后一个从客户端发起的TCP Reset可能会是干扰项,可以看到这个TCP Reset是在收到服务器端的FIN而发出的。对于正常TCP四次回收结束连接的过程,客户端在收到服务器的FIN后应该也发送个FIN给服务器结束连接。但是TCP有个Linger选项,可以控制这个行为,设置了Linger选项后可以让客户端直接回Reset,这样可以让双方快速关闭这组socket, 避免主动关闭放进入长达60秒的TIME_WAIT状态。看起来是客户端的Linger设置造成的,搜了下Jedis代码,在Connection.java (如下)里果然有这个设置,这样就能结束为什么客户端Reset掉TCP连接,这个行为是符合逻辑的。
socket = new Socket();
socket.setReuseAddress(true);
socket.setKeepAlive(true); // Will monitor the TCP connection is valid
socket.setTcpNoDelay(true); // Socket buffer Whether closed, to ensure timely delivery of data
socket.setSoLinger(true, 0); // Control calls close () method, the underlying socket is closed immediately
接着来看报文交互中的Redis命令是否正常。跟踪TCP stream可以看到ASCII形式的数据,如下:

可以看到客户端发了DEL命令后,又发了QUIT命令,可以对照报文看下。
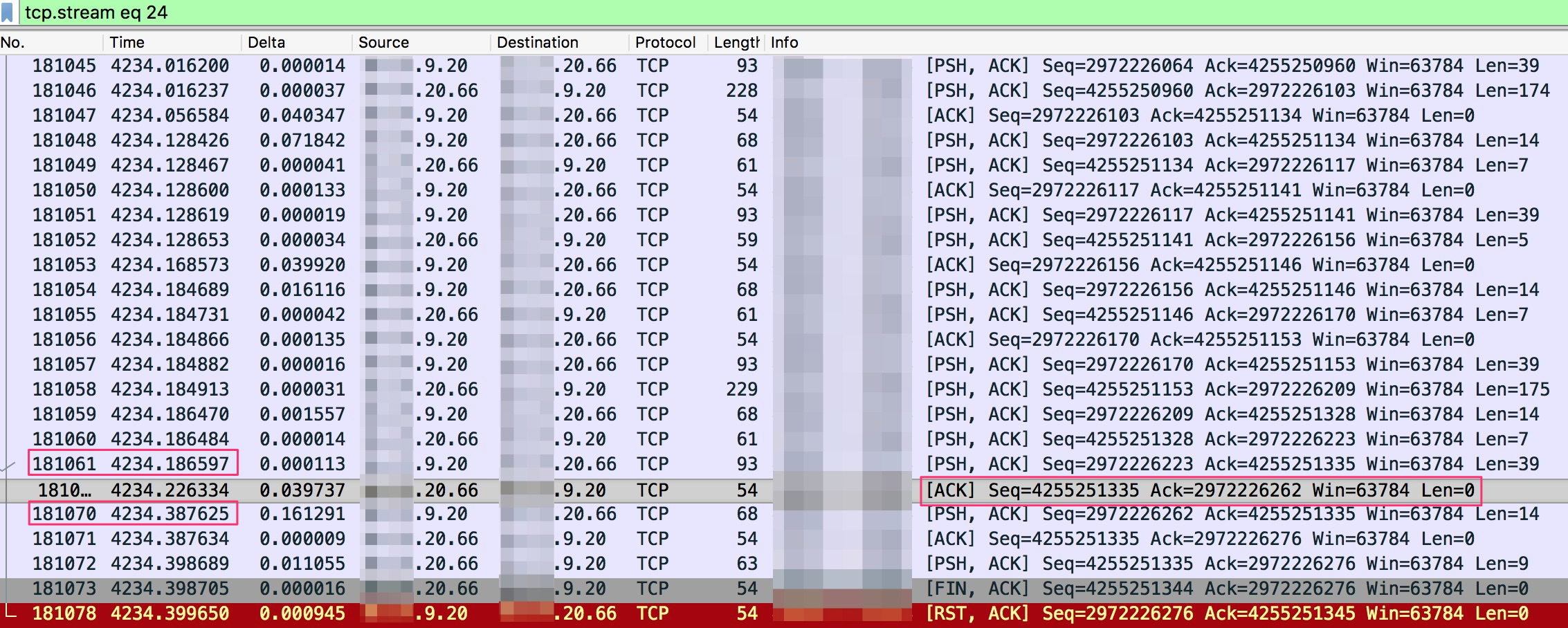
- 客户端在181061号包发出了DEL命令。
- 在3.9 ms后收到了Redis服务器的ACK,注意这只是个ACK包,报文长度是0,说明没带任何payload数据。
- 第181070号包,客户端又发出了QUIT命令,注意这个包和DEL命令的包相差间隔时间大概200 ms。Quit命令用于关闭与当前客户端与Redis服务器的连接,一旦所有等待中的回复(如果有的话)顺利写入到客户端,连接就会被关闭。
- 第181072号包,也就是在QUIT命令发出161 ms后,Redis服务器端回复了":1"和"+OK"。其中":1"响应DEL命令,"+OK"响应QUIT命令。
- 第181073号包,Redis用FIN报文结束了这个TCP长连接。
如上所述,这个连接被中断的关键点是客户端给Redis服务器发送了QUIT命令,至于为什么要发QUIT,并且是之前命令发出后200 ms没返回时发送QUIT,很有可能是有超时设置。查看另外几个TCP stream, 基本上都是以类似的模式结束了TCP长连接,基本上可以下这个结论了。
这个案例和第一个案例很类似,不同之点是在抓包里我们无法看到在超时时间过后客户端直接FIN掉连接,而是发了Redis QUIT命令,最终等到前面的命令执行完后才关闭连接。相比较第一种,这是一种更优雅的方法,前提是因为Redis存在QUIT命令,并且Jedis内化了这个操作。这个案例更清晰地说明了具体业务对连接行为的影响,需要利用报文来反推Redis客户端和服务器交互的行为。
总结
本文介绍了业务日志里面报超时问题处理起来需要考虑的两个层面:云基础设施层和业务软件层。有相当一部分的问题可能由于基础设施的网络丢包引起,通过网络监控和网络产品的云监控定位丢包点很重要,注意不要把业务超时等同于丢包;另一类业务软件层Timeout设置导致的超时,发生比例相对少,但需要更广泛的排查,并且不要轻易忽略了这类原因导致的超时。
作者:怀知
原文链接
本文为云栖社区原创内容,未经允许不得转载。

