
图片来源:https://pixabay.com/
作为一个几乎每天与时间序列数据打交道的人员,我发现panda Python包在时间序列的操作和分析方面有强大优势。
这篇关于panda时间序列数据处理的基本介绍可以带你入门时间序列分析。本文将主要介绍以下操作:
- 创建一个日期范围
- 处理时间戳数据
- 将字符串数据转换为时间戳
- 在数据框中索引和切片时间序列数据
- 重新采样不同时间段的时间序列汇总/汇总统计数据
- 计算滚动统计数据,如滚动平均值
- 处理丢失数据
- 了解unix/epoch时间的基础知识
- 了解时间序列数据分析的常见陷阱
接下来我们一起步入正题。如果想要处理已有的实际数据,你可能考虑从使用panda read_csv将文件读入数据框开始,然而在这里,我们将直接从处理生成的数据开始。
首先导入我们将会使用到的库,然后用它们创建日期范围
import pandas as pd
from datetime import datetime
import numpy as np
date_rng = pd.date_range(start='1/1/2018', end='1/08/2018', freq='H')
这个日期范围的时间戳为每小时一次。如果我们调用date_rng,我们会看到如下所示:
DatetimeIndex(['2018-01-01 00:00:00', '2018-01-01 01:00:00',
'2018-01-01 02:00:00', '2018-01-01 03:00:00',
'2018-01-01 04:00:00', '2018-01-01 05:00:00',
'2018-01-01 06:00:00', '2018-01-01 07:00:00',
'2018-01-01 08:00:00', '2018-01-01 09:00:00',
...
'2018-01-07 15:00:00', '2018-01-07 16:00:00',
'2018-01-07 17:00:00', '2018-01-07 18:00:00',
'2018-01-07 19:00:00', '2018-01-07 20:00:00',
'2018-01-07 21:00:00', '2018-01-07 22:00:00',
'2018-01-07 23:00:00', '2018-01-08 00:00:00'],
dtype='datetime64[ns]', length=169, freq='H')
我们可以检查第一个元素的类型:
type(date_rng[0])
#returns
pandas._libs.tslib.Timestamp
让我们用时间戳数据的创建一个示例数据框,并查看前15个元素:
df = pd.DataFrame(date_rng, columns=['date'])
df['data'] = np.random.randint(0,100,size=(len(date_rng)))
df.head(15)
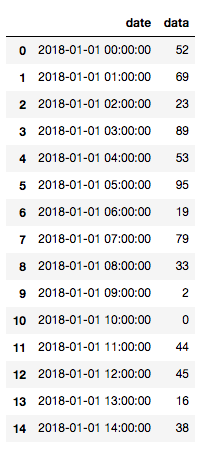
示例数据框
如果想进行时间序列操作,我们需要一个日期时间索引。这样一来,数据框便可以在时间戳上建立索引。
将数据框索引转换为datetime索引,然后显示第一个元素:
df['datetime'] = pd.to_datetime(df['date'])
df = df.set_index('datetime')
df.drop(['date'], axis=1, inplace=True)
df.head()

如果数据中的“时间”戳实际上是字符串类型和数值类型相比较,该怎么办呢?我们可以将date_rng转换为字符串列表,然后将字符串转换为时间戳。
string_date_rng = [str(x) for x in date_rng]
string_date_rng
#returns
['2018-01-01 00:00:00',
'2018-01-01 01:00:00',
'2018-01-01 02:00:00',
'2018-01-01 03:00:00',
'2018-01-01 04:00:00',
'2018-01-01 05:00:00',
'2018-01-01 06:00:00',
'2018-01-01 07:00:00',
'2018-01-01 08:00:00',
'2018-01-01 09:00:00',...
可以通过推断字符串的格式将其转换为时间戳,然后查看这些值:
timestamp_date_rng = pd.to_datetime(string_date_rng, infer_datetime_format=True)
timestamp_date_rng
#returns
DatetimeIndex(['2018-01-01 00:00:00', '2018-01-01 01:00:00',
'2018-01-01 02:00:00', '2018-01-01 03:00:00',
'2018-01-01 04:00:00', '2018-01-01 05:00:00',
'2018-01-01 06:00:00', '2018-01-01 07:00:00',
'2018-01-01 08:00:00', '2018-01-01 09:00:00',
...
'2018-01-07 15:00:00', '2018-01-07 16:00:00',
'2018-01-07 17:00:00', '2018-01-07 18:00:00',
'2018-01-07 19:00:00', '2018-01-07 20:00:00',
'2018-01-07 21:00:00', '2018-01-07 22:00:00',
'2018-01-07 23:00:00', '2018-01-08 00:00:00'],
dtype='datetime64[ns]', length=169, freq=None)
但是如果需要转换一个唯一的字符串格式呢?
我们可以创建一个任意的字符串形式的日期列表,并将它们转换为时间戳:
string_date_rng_2 = ['June-01-2018', 'June-02-2018', 'June-03-2018']
timestamp_date_rng_2 = [datetime.strptime(x,'%B-%d-%Y') for x in string_date_rng_2]
timestamp_date_rng_2
#returns
[datetime.datetime(2018, 6, 1, 0, 0),
datetime.datetime(2018, 6, 2, 0, 0),
datetime.datetime(2018, 6, 3, 0, 0)]
如果把它放到数据框中,将会如何?
df2 = pd.DataFrame(timestamp_date_rng_2, columns=['date'])
df2

回到最初的数据框架,让我们通过解析时间戳索引来查看数据:
假设只想查看本月2号的数据,可以使用如下索引。
df[df.index.day == 2]
顶部如图所示:

也可以通过数据框索引直接调用想查看的日期:
df['2018-01-03']

如何在特定日期之间选择数据?
df['2018-01-04':'2018-01-06']
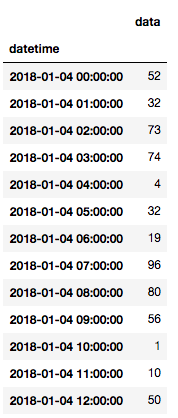
我们填充的基本数据框提供了频率以小时计的数据,但同样可以以不同的频率重新采样数据,并指定如何计算新样本频率的汇总统计信息。我们可以取每天频率下数据的最小值、最大值、平均值、总和等,而不是每小时的频率,如下面的例子,计算每天数据的平均值:
df.resample('D').mean()

那么诸如滚动平均值或滚动和之类的窗口统计信息呢?
让我们在原来的df中创建一个新列,计算3个窗口周期内的滚动和,然后查看数据框的顶部:
df ['rolling_sum'] = df.rolling(3).sum()
df.head(10)

可以看到,在这个正确的计算中,只有当存在三个周期可以回顾时,它才开始具有有效值。
这可以有效地帮我们了解到,当处理丢失的数据值时,如何向前或向后“滚动”数据。
这是我们的df,但有一个新的列,采取滚动求和并向后“滚动”数据:
df['rolling_sum'] = df.rolling(3).sum()
df.head(10)
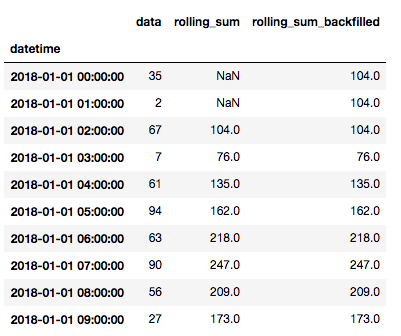
采用诸如平均时间之类的实际值用于填补丢失的数据,这种方法通常来说是有效的。但一定谨记,如果你正处理一个时间序列的问题,并且希望数据是切合实际的,那么你不应该向后“滚动”数据。因为这样一来,你需要的关于未来的信息就永远不可能在那个时间获取到。你可能更希望频繁地向前“滚动”数据,而不是向后“滚动”。
在处理时间序列数据时,可能会遇到Unix时间中的时间值。Unix时间,也称为Epoch时间,是自协调世界时(UTC) 1970年1月1日星期四00:00:00以后经过的秒数。使用Unix时间有助于消除时间戳的歧义,这样我们就不会被时区、夏令时等混淆。
下面是一个时间t在Epoch时间的例子,它将Unix/Epoch时间转换为UTC中的常规时间戳:
epoch_t = 1529272655
real_t = pd.to_datetime(epoch_t, unit='s')
real_t
#returns
Timestamp('2018-06-17 21:57:35')
如果我想把UTC中的时间转换为自己的时区,可以简单地做以下操作:
real_t.tz_localize('UTC').tz_convert('US/Pacific')
#returns
Timestamp('2018-06-17 14:57:35-0700', tz='US/Pacific')
掌握了这些基础知识后,就可以开始处理时间序列数据了。
以下是一些处理时间序列数据时要记住的技巧和常见的陷阱:
- 检查数据中可能由区域特定时间变化(如夏令时)引起的差异。
- 精心跟踪时区 - 让他人通过代码了解你的数据所在的时区,并考虑转换为UTC或标准化值以保持数据标准化。
- 丢失的数据可能经常发生 - 请确保记录清洁规则并考虑不回填在采样时无法获得的信息。
- 请记住,当重新采样数据或填写缺失值时,将丢失有关原始数据集的一定数量的信息。建议跟踪所有数据转换并跟踪数据问题根源。
- 重新采样数据时,最佳方法(平均值,最小值,最大值,总和等)取决于拥有的数据类型以及采样方式。请仔细考虑如何重新采样数据以进行分析。
以上为译文
本文由阿里云云栖社区组织翻译。
文章原标题《Basic Time Series Manipulation with Pandas》,译者:狮子家的袋鼠,审校:么凹。
原文链接
本文为云栖社区原创内容,未经允许不得转载。

