9 Activiti数据查询(二)
本文节选自《疯狂Workflow讲义(第2版)》。

本书代码目录:https://gitee.com/yangenxiong/CrazyActiviti
本章要点
Activiti的数据查询、排序机制
9.1 排序方法
Query中提供了asc和desc方法,这两个方法可以设置查询结果的排序方式,但是调用这两个方法的前提是,必须告诉Query对象,是按何种条件进行排序,例如要按照ID排序,就要调用相应查询对象的orderByXXX方法。例如GroupQuery的orderByGroupId、orderByGroupName等方法,如果不调用这些方法而直接使用asc或者desc方法,则会抛出ActivitiException,异常信息为:You should call any of the orderBy methods first before specifying a direction。要求Activiti进行排序,却不告诉它以哪个字段进行排序,因此会抛出该异常。代码清单6-7中调用asc和desc方法。
代码清单6-7:codes\06\6.2\sort-data\src\org\crazyit\activiti\Sort.java
/** * Query的排序 * @author yangenxiong * */ public class Sort { /** * @param args */ public static void main(String[] args) { //创建流程引擎 ProcessEngine engine = ProcessEngines.getDefaultProcessEngine(); // 得到身份服务组件实例 IdentityService identityService = engine.getIdentityService(); // 写入5条用户组数据 createGroup(identityService, UUID.randomUUID().toString(), "1", "typeA"); createGroup(identityService, UUID.randomUUID().toString(), "2", "typeB"); createGroup(identityService, UUID.randomUUID().toString(), "3", "typeC"); createGroup(identityService, UUID.randomUUID().toString(), "4", "typeD"); createGroup(identityService, UUID.randomUUID().toString(), "5", "typeE"); //调用orderByGroupId和asc方法,结果为按照ID升序排序 System.out.println("asc排序结果:"); List<Group> datas = identityService.createGroupQuery().orderByGroupName().asc().list(); for (Group data : datas) { System.out.println(" " + data.getId() + "---" + data.getName()); } System.out.println("desc排序结果"); //调用orderByGroupName和desc方法,结果为名称降序排序 datas = identityService.createGroupQuery().orderByGroupName().desc().list(); for (Group data : datas) { System.out.println(" " + data.getId() + "---" + data.getName()); } } // 将用户组数据保存到数据库中 static void createGroup(IdentityService identityService, String id, String name, String type) { // 调用newGroup方法创建Group实例 Group group = identityService.newGroup(id); group.setName(name); group.setType(type); identityService.saveGroup(group); } }
代码清单6-7中,调用了asc和desc方法(代码清单中的粗体部分),输出的结果如下:
asc排序结果: 35987ec6-de7f-4d36-920f-71d27b586817---1 3273d754-a77f-4a7b-ac88-b529cc5e3d35---2 590f5597-d662-4c35-a35c-c2828468878d---3 f8decda9-ceb9-4172-ad61-ae3d2a8a4e8e---4 0f50f928-a7ff-4b77-b4fd-578773c0fb2f---5 desc排序结果 0f50f928-a7ff-4b77-b4fd-578773c0fb2f---5 f8decda9-ceb9-4172-ad61-ae3d2a8a4e8e---4 590f5597-d662-4c35-a35c-c2828468878d---3 3273d754-a77f-4a7b-ac88-b529cc5e3d35---2 35987ec6-de7f-4d36-920f-71d27b586817---1
注意:调用asc或者desc,只是让Query设置排序方式,orderByXXX方法、asc方法和desc方法均返回Query本身,如果需要得到最终结果集,还需要调用list或者listPage方法。
9.2 ID排序问题
在Activiti的设计中,每个数据表的主键均设计为字符型,这样的设计使得Activiti各个数据表的主键可以灵活设置,但是如果使用数字字符串作为其主键,那么按照ID排序,就会带来排序问题,请看代码清单6-8。
代码清单6-8:codes\06\6.2\sort-data\src\org\crazyit\activiti\SortProblem.java
/** * Query的的排序问题 * @author yangenxiong * */ public class SortProblem { /** * @param args */ public static void main(String[] args) { //创建流程引擎 ProcessEngine engine = ProcessEngines.getDefaultProcessEngine(); // 得到身份服务组件实例 IdentityService identityService = engine.getIdentityService(); // 写入5条用户组数据 createGroup(identityService, "1", "GroupA", "typeA"); createGroup(identityService, "12", "GroupB", "typeB"); createGroup(identityService, "13", "GroupC", "typeC"); createGroup(identityService, "2", "GroupD", "typeD"); createGroup(identityService, "3", "GroupE", "typeE"); //根据ID升序排序 System.out.println("asc排序结果"); List<Group> datas = identityService.createGroupQuery().orderByGroupId().asc().list(); for (Group data : datas) { System.out.print(data.getId() + " "); } } // 将用户组数据保存到数据库中 static void createGroup(IdentityService identityService, String id, String name, String type) { // 调用newGroup方法创建Group实例 Group group = identityService.newGroup(id); group.setName(name); group.setType(type); identityService.saveGroup(group); } }
代码清单6-8中,加入了5条用户组数据,需要注意的是,这5条用户组数据,ID分别为:1、12、13、2、3,然后调用orderByGroupId方法,并且设置为升序排序,期望的结果应该是:1、2、3、12、13,而此处输出结果却是:1、12、13、2、3,产生这种现象是由于ID_列字段数据类型是字符型,以MySQL为例,如果字段类型为字符型,而实际存储的是数据的话,那么进行排序时,会将其看作字符型,因此会产生以上的ID顺序错乱,详细请看图6-2所示。
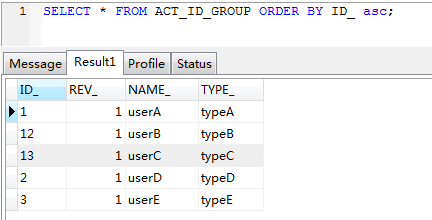
图6-2 MySQL的排序
如图6-2所示,在MySQL中执行普通的ORDER BY语句,可以看到数据库排序结果与程序结果一致,前面已经讲到,这样的顺序错乱是由于ID_列数据类型为字符型导致,如果需要使用正确的排序,可以使用以下的MySQL语句进行排序:SELECT * FROM ACT_ID_GROUP ORDER BY ID_ ASC,此处在ORDER BY ID_后加了“+0”语句,再进行查询后,可以看到结果如图6-3所示。
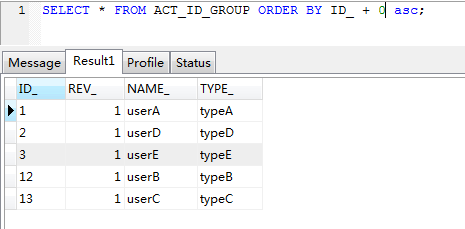
图6-3 处理后的MySQL排序
如图6-3所示,MySQL已经展示了“正确”的排序结果。如果想在代码中解决该排序问题,可以将Query转换为AbstractQuery,再调用orderBy方法,请见以下代码片断:
AbstractQuery aq = (AbstractQuery)identityService.createGroupQuery(); List<Group> datas = aq.orderBy(new GroupQueryProperty("RES.ID_ + 0")).asc().list();
将GroupQuery转换为AbstractQuery,再调用orderBy方法,构造一个GroupQueryProperty,构造参数的字符串为“RES.ID + 0”。执行代码并输出结果后,可以发现结果正确。但笔者不建议使用该方式,因为官方API中并没有提供AbstractQuery与GroupQueryProperty,一旦后面的Activiti版本中修改了这两个类,那我们的代码也需要进行修改。除了该方法,也可以使用Activiti提供的原生SQL查询,详细请见6.2.10章节。
9.3 多字段排序
在进行数据查询时,如果想对多个字段进行排序,例如根据名称降序、根据ID升序这样的排序方式,那么在调用asc和desc方法时就需要注意,asc和desc方法会根据Query实例(AbstractQuery)中的orderProperty属性来决定排序的字段,由于orderProperty是AbstractQuery的类属性,因此如果在第二次调用orderByXXX方法后,会覆盖第一次调用时所调置的值。具体测试结果如代码清单6-9所示。
代码清单6-9:codes\06\6.2\sort-data\src\org\crazyit\activiti\SortMix.java
/** * Query的多字段排序 * @author yangenxiong * */ public class SortMix { /** * @param args */ public static void main(String[] args) { //创建流程引擎 ProcessEngine engine = ProcessEngines.getDefaultProcessEngine(); // 得到身份服务组件实例 IdentityService identityService = engine.getIdentityService(); // 写入5条用户组数据 createGroup(identityService, "1", "GroupE", "typeB"); createGroup(identityService, "2", "GroupD", "typeC"); createGroup(identityService, "3", "GroupC", "typeD"); createGroup(identityService, "4", "GroupB", "typeE"); createGroup(identityService, "5", "GroupA", "typeA"); //优先按照id降序、名称升序排序 System.out.println("ID降序排序:"); List<Group> datas = identityService.createGroupQuery() .orderByGroupId().desc() .orderByGroupName().asc().list(); for (Group data : datas) { System.out.println(" " + data.getId() + "---" + data.getName() + " "); } System.out.println("名称降序排序:"); //下面结果将按名称排序 datas = identityService.createGroupQuery().orderByGroupId() .orderByGroupName().desc().list(); for (Group data : datas) { System.out.println(" " + data.getId() + "---" + data.getName() + " "); } } // 将用户组数据保存到数据库中 static void createGroup(IdentityService identityService, String id, String name, String type) { // 调用newGroup方法创建Group实例 Group group = identityService.newGroup(id); group.setName(name); group.setType(type); identityService.saveGroup(group); } }
代码清单6-9中,均使用了两个字段进行排序,第一个查询中,告诉Query实例,使用groupId进行降序排序,再使用名称升序排序,输出结果如下:
ID降序排序: 5---GroupA 4---GroupB 3---GroupC 2---GroupD 1---GroupE
输出结果为优先按照ID进行降序排序,符合预期。第二个查询中,虽然也调用了orderByGroupId方法,但是由于没有马上调用desc方法,而是调用了其他的orderBy方法,因此原来的orderByGroupId方法所设置的排序属性(Query的orderProperty属性)将会被orderByGroupName替换,最终输入结果如下:
名称降序排序: 1---GroupE 2---GroupD 3---GroupC 4---GroupB 5---GroupA
根据输出结果可以看出,最终按照名称降序排序。根据上面的测试可以看出,asc与desc方法会生成(根据查询条件)相应的查询语句,如果调用了orderByXXX方法却没有调用一次asc或者desc方法,则该排序条件会被下一个设置的查询条件所覆盖。
9.4 singleResult方法
该方法根据查询条件,到数据库中查询唯一的数据记录,如果没有找到符合条件的数据,则返回null,如果找到多于一条的记录,则抛出异常,异常信息为:Query return 2 results instead of max 1,代码清单6-10中使用singleResult方法,并且体现三种查询结果。
代码清单6-10:codes\06\6.2\single-result\src\org\crazyit\activiti\SingleResult.java
/** * 使用Query的singleResult方法 * @author yangenxiong * */ public class SingleResult { public static void main(String[] args) { //创建流程引擎 ProcessEngine engine = ProcessEngines.getDefaultProcessEngine(); // 得到身份服务组件实例 IdentityService identityService = engine.getIdentityService(); // 写入5条用户组数据 createGroup(identityService, UUID.randomUUID().toString(), "GroupA", "typeA"); createGroup(identityService, UUID.randomUUID().toString(), "GroupB", "typeB"); createGroup(identityService, UUID.randomUUID().toString(), "GroupC", "typeC"); createGroup(identityService, UUID.randomUUID().toString(), "GroupD", "typeD"); createGroup(identityService, UUID.randomUUID().toString(), "GroupE", "typeE"); //再写入一条名称为GroupA的数据 createGroup(identityService, UUID.randomUUID().toString(), "GroupA", "typeF"); //查询名称为GroupB的记录 Group groupB = identityService.createGroupQuery() .groupName("GroupB").singleResult(); System.out.println("查询到一条GroupB数据:" + groupB.getId() + "---" + groupB.getName()); //查询名称为GroupF的记录 Group groupF = identityService.createGroupQuery() .groupName("GroupF").singleResult(); System.out.println("没有groupF的数据:" + groupF); //查询名称为GroupA的记录,这里将抛出异常 Group groupA = identityService.createGroupQuery() .groupName("GroupA").singleResult(); } // 将用户组数据保存到数据库中 static void createGroup(IdentityService identityService, String id, String name, String type) { // 调用newGroup方法创建Group实例 Group group = identityService.newGroup(id); group.setName(name); group.setType(type); identityService.saveGroup(group); } }
在代码清单6-10中,写入了6条用户组数据,其中需要注意的是最后一条数据,名称与第一条数据名称一致,目的是为了测试使用singleResult方法,在查询到多条记录时抛出异常。代码清单6-10中的粗体字代码分别为三种情况:正常使用singleResult方法返回第一条数据,查询不到任何数据,查询出多于一条数据抛出异常。程序运行结果如下:
查询到一条GroupB数据:deed85ac-d76c-4e7a-b5f6-4d48eb8340ee---GroupB 没有groupF的数据:null 16:52:12,936 ERROR CommandContext - Error while closing command context org.activiti.engine.ActivitiException: Query return 2 results instead of max 1
9.5 用户组数据查询
前面章节中,以用户组数据为基础,讲解了Activiti的数据查询机制以及一些公用的查询方法。Activiti的每种数据均自己对应的查询对象,例如用户组的查询对象为GroupQuery,它继承了AbstractQuery,除了拥有基类的方法(6.2.2至6.2.8的方法)外,它还拥有自己的查询以及排序方法:
groupId(String groupId):根据ID查询与参数值一致的记录。
groupMember(String groupMemberUserId):根据用户ID查询用户所在的用户组,用户组与用户为多对多关系,因此一个用户有可能属于多个用户组。
groupName(String groupName):根据用户组名称查询用户组。
groupNameLike(String groupName):根据用户组名称模糊查询用户组数据。
groupType(String groupType):根据用户组类型查询用户组数据。
orderByGroupId():设置排序条件为根据ID排序。
orderByGroupName():设置排序条件为根据名称排序。
orderByGroupType():设置排序条件为根据类型排序。
potentialStarter(String procDefId):根据流程定义的ID,查询有权限启动该流程定义的用户组。
代码清单6-11演示了如何使用GroupQuery的部分查询方法。
代码清单6-11:codes\06\6.2\group-query\src\org\crazyit\activiti\GroupQuery.java
/** * * @author yangenxiong * */ public class GroupQuery { public static void main(String[] args) { // 创建流程引擎 ProcessEngine engine = ProcessEngines.getDefaultProcessEngine(); // 得到身份服务组件实例 IdentityService identityService = engine.getIdentityService(); // 写入5条用户组数据 String aId = UUID.randomUUID().toString(); createGroup(identityService, aId, "GroupA", "typeA"); createGroup(identityService, UUID.randomUUID().toString(), "GroupB", "typeB"); createGroup(identityService, UUID.randomUUID().toString(), "GroupC", "typeC"); createGroup(identityService, UUID.randomUUID().toString(), "GroupD", "typeD"); createGroup(identityService, UUID.randomUUID().toString(), "GroupE", "typeE"); // groupId方法 Group groupA = identityService.createGroupQuery().groupId(aId).singleResult(); System.out.println("groupId method: " + groupA.getId()); // groupName方法 Group groupB = identityService.createGroupQuery().groupName("GroupB").singleResult(); System.out.println("groupName method: " + groupB.getName()); // groupType方法 Group groupC = identityService.createGroupQuery().groupType("typeC").singleResult(); System.out.println("groupType method: " + groupC.getName()); // groupNameLike方法 List<Group> groups = identityService.createGroupQuery().groupNameLike("%group%").list(); System.out.println("groupNameLike method: " + groups.size()); } // 将用户组数据保存到数据库中 static void createGroup(IdentityService identityService, String id, String name, String type) { // 调用newGroup方法创建Group实例 Group group = identityService.newGroup(id); group.setName(name); group.setType(type); identityService.saveGroup(group); } }
代码清单6-11调用了GroupQuery的4个查询方法,输出结果如下:
1 userB userC 5
注:GroupQuery的设置排序条件方法,在前小节中已经体现,本小节不再赘述。另外groupMember和potentialStarter方法,将在用户组与用户关系、流程定义章节中描述。
9.6 原生SQL查询
各个服务组件中,提供了createNativeXXXQuery的方法,返回NativeXXXQuery的实例,这些对象均是NativeQuery的子接口。使用NativeQuery的方法,可以传入原生的SQL进行数据查询,主要使用sql方法传入SQL语句,使用parameter方法设置查询参数,代码清单6-12中使用了原生SQL查询用户组数据。
代码清单6-12:codes\06\6.2\native-query\src\org\crazyit\activiti\NativeQueryTest.java
/** * 使用NativeQuery * * @author yangenxiong * */ public class NativeQueryTest { public static void main(String[] args) { // 创建流程引擎 ProcessEngine engine = ProcessEngines.getDefaultProcessEngine(); // 得到身份服务组件实例 IdentityService identityService = engine.getIdentityService(); // 写入5条用户组数据 createGroup(identityService, UUID.randomUUID().toString(), "GroupA", "typeA"); createGroup(identityService, UUID.randomUUID().toString(), "GroupB", "typeB"); createGroup(identityService, UUID.randomUUID().toString(), "GroupC", "typeC"); createGroup(identityService, UUID.randomUUID().toString(), "GroupD", "typeD"); createGroup(identityService, UUID.randomUUID().toString(), "GroupE", "typeE"); // 使用原生SQL查询全部数据 List<Group> groups = identityService.createNativeGroupQuery() .sql("select * from ACT_ID_GROUP").list(); System.out.println("查询全部数据:" + groups.size()); // 使用原生SQL按条件查询,并设入参数,只查到一条数据 groups = identityService.createNativeGroupQuery() .sql("select * from ACT_ID_GROUP where NAME_ = 'GroupC'") .list(); System.out.println("按条件查询:" + groups.get(0).getName()); // 使用parameter方法设置查询参数 groups = identityService.createNativeGroupQuery() .sql("select * from ACT_ID_GROUP where NAME_ = #{name}") .parameter("name", "GroupD").list(); System.out.println("使用parameter方法按条件查询:" + groups.get(0).getName()); } // 将用户组数据保存到数据库中 static void createGroup(IdentityService identityService, String id, String name, String type) { // 调用newGroup方法创建Group实例 Group group = identityService.newGroup(id); group.setName(name); group.setType(type); identityService.saveGroup(group); } }
代码清单6-12中粗体字代码,进行了三次原生SQL查询,第二次与第三次查询设置了参数,第三次参数使用了parameter设置参数。由于最终调用查询的是MyBatis的SqlSession,因此写SQL时,需要使用#{}。除了用户组数据外,其他的数据,都可以使用原生SQL查询。运行代码清单6-12,输出结果如下:
查询全部数据:5 按条件查询:GroupC 使用parameter方法按条件查询:GroupD
使用原生SQL查询较为灵活,可以满足大部分的业务需求,但笔者还是建议尽量少使用原生SQL查询,这样做增强了代码与数据库结构的耦合性。
本文节选自《疯狂Workflow讲义(第2版)》。

