在Hadoop中,MapReduce将产生大量的数据交互,因而带宽将是Hadoop中最稀缺的资源,如何减少数据的交互量将显得尤为重要。序列化指的是将数据以流的形式进行压缩,压缩之后的数据可以保存在文件中,进行数据交互或者是对象的克隆等。因而数据如何存储在流中,以及其序列化和反序列化的效率将直接影响着Hadoop的I/O效率。
在Java语言中,其内嵌了序列化的机制,我们在使用的时候只需要实现Serializable接口即可,该接口中没有任何方法,只是作为一个标识。但是Java内嵌的序列化机制有一个非常显著的缺点就是其占用内存非常高,对于一个只有三个长整数(long)类型的类来说,其占用内存可高大120字节,而对于一个四个长整数(long)类型的类,其占用的字节更可达到190字节。这是由于Java在序列化该类对象时不仅会保存该对象的参数数据,还会将该类的属性,方法以及类名等标识序列化到文件中,并且如果该类有父类,那么其也会被保存起来,这就导致了Java序列化机制产生了大量的冗余数据。
在Java序列化机制中,对象只要实现了Serializable接口,我们就可以用ObjectOutputStream.writeObject()方法将对象写入流中,或者调用ObjectInputStream将对象从流中读取出来。在Hadoop中,其序列化和反序列化正好反过来了。其定义了一个Writable接口,具体代码如下:
@InterfaceAudience.Public @InterfaceStability.Stable public interface Writable { /** * 将当前对象序列化到DataOutput流中 */ void write(DataOutput out) throws IOException; /** * 从DataInput流中读取数据 */ void readFields(DataInput in) throws IOException; }
Writable接口声明了两个方法,write(DataOutput)方法用于将当前对象写入到流中,readFields(DataInput)方法则将流中的数据反序列化到当前对象中。相较于Java的序列化机制,这种序列化机制有三个优点:
- 从流中读取数据到当前对象中,因而当前对象可以复用,这将极大减轻垃圾回收机制的负担;
- 读取和写入数据的时候变化的是输入输出流,序列化和反序列化的对象类型是不变的,因而流中则可以只保存必要的数据即可,这将减少大量的带宽消耗;
- 由于序列化和反序列化的的数据量减少了,并且结合Hadoop的压缩机制,这对I/O效率有很大提升。
如下是一个实现了Writable接口的具体实例:
@InterfaceAudience.Private @InterfaceStability.Evolving public class Block implements Writable, Comparable<Block> { private long blockId; private long numBytes; private long generationStamp; @Override public void write(DataOutput out) throws IOException { writeHelper(out); } @Override public void readFields(DataInput in) throws IOException { readHelper(in); } final void writeHelper(DataOutput out) throws IOException { out.writeLong(blockId); out.writeLong(numBytes); out.writeLong(generationStamp); } final void readHelper(DataInput in) throws IOException { this.blockId = in.readLong(); this.numBytes = in.readLong(); this.generationStamp = in.readLong(); if (numBytes < 0) { throw new IOException("Unexpected block size: " + numBytes); } } // other methods }
这里Block.write()方法调用了writeHelper方法,writeHelper则直接调用DataOutput.writeLong()方法将三个全局属性直接写入到流中;Block.readFields()方法则调用了readHelper()方法,该方法直接从流中依次读取三个属性到当前对象的全局属性中。
除了Writable接口,Hadoop还提供了很多其他的序列化接口规范,具体的有如下几种:
- RawComparator:其有一个compare(byte[] b1, int s1, int l1, byte[] b2, int s2, int l2)方法,使用时无需将两个流中的两个对象分别反序列化为具体对象进行比较,而是直接在流中读取相应字段的字节数据进行比较;
- WritableComparator:该类是RawComparator的一个具体实现,其进行的是两个WritableComparable实例的比较;
- WritableComparable:该接口继承了Writable和Comparable接口,因而其具有将数据序列化和反序列化到流中,以及与其他WritableComparable实例进行比较的功能;
- WritableComparable具体实例:对于WritableComparable实例,其主要有两种类型的实现----可变长度类型和不可变长度类型,可变长度类型指的是其存储在流中的数据长度不是固定的,如VIntWritable,不可变长度类型指的是其存储在流中的长度是其数据类型的长度,如IntWritable和LongWritable等。
如下是Writable相关类结构图:
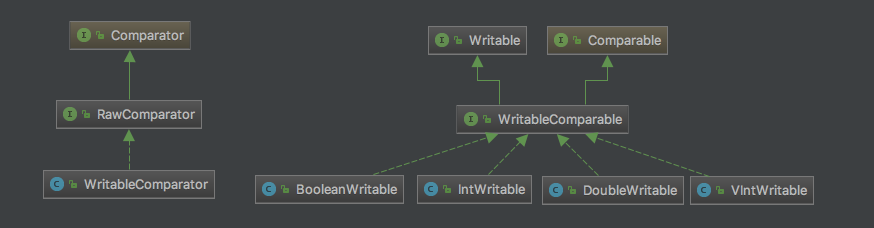
这里,我们主要对VIntWritable的源码进行相关的讲解,以此具体说明如何将一个整型数据序列化到流中,并且介绍Hadoop是如何实现根据整型数据的具体大小来动态存储数据以节省空间的。如下是VIntWritable的源码:
@InterfaceAudience.Public @InterfaceStability.Stable public class VIntWritable implements WritableComparable<VIntWritable> { // 存储具体的数据 private int value; public VIntWritable() {} public VIntWritable(int value) { set(value); } /** Set the value of this VIntWritable. */ public void set(int value) { this.value = value; } /** Return the value of this VIntWritable. */ public int get() { return value; } @Override public void readFields(DataInput in) throws IOException { // 从流中读取数据到value中 value = WritableUtils.readVInt(in); } @Override public void write(DataOutput out) throws IOException { // 将数据写入到流中 WritableUtils.writeVInt(out, value); } @Override public boolean equals(Object o) { if (!(o instanceof VIntWritable)) return false; VIntWritable other = (VIntWritable)o; return this.value == other.value; } @Override public int hashCode() { return value; } @Override public int compareTo(VIntWritable o) { int thisValue = this.value; int thatValue = o.value; return (thisValue < thatValue ? -1 : (thisValue == thatValue ? 0 : 1)); } @Override public String toString() { return Integer.toString(value); } }
可以看到,VIntWritable在底层调用的是WritableUtils进行数据的写入和读取,首先我们看看WritableUtils.writeVInt()方法,该方法是将一个整数以可变长度的形式存储到输出流中,如下是其源代码:
public static void writeVInt(DataOutput stream, int i) throws IOException { writeVLong(stream, i); } public static void writeVLong(DataOutput stream, long i) throws IOException { if (i >= -112 && i <= 127) { stream.writeByte((byte)i); return; } int len = -112; if (i < 0) { // i=-115 i=-121 i=537 i ^= -1L; // i=114 i=120 len = -120; } long tmp = i; // tmp=114 0111 0010 tmp=120 0111 1000 tmp=537 0010 0001 1001 while (tmp != 0) { tmp = tmp >> 8; //tmp=0 tmp=0 tmp=0010 0 len--; // len=-121 tmp=-121 len=-113 -114 } stream.writeByte((byte)len); len = (len < -120) ? -(len + 120) : -(len + 112); // len=2 for (int idx = len; idx != 0; idx--) { int shiftbits = (idx - 1) * 8; // shiftbits=8 long mask = 0xFFL << shiftbits; // 0xFFL即 1111 1111 mask=1111 1111 0000 0000 stream.writeByte((byte)((i & mask) >> shiftbits)); } }
对于数据的写入,最终调用的是writeVLong()方法,在writeVLong()方法中,其主要做如下几件事情:①判断i是否在[-112, 127]内,如果在则将其转换为一个byte类型存储,占用一个字节;②判断i是否在[128, +∞)内(不能用一个字节保存的正数),如果在,则将第一个字节存储为[-120, -113]之间的一个数字,后续字节则存储i数字部分占用的字节数,字节数则是由第一个字节与-112的差值决定的,比如比如i为537,其二进制数为0000 0000 0000 0000 0000 0010 0001 1001,其有数字部分未2个字节,因而第一个字节为-114(=-112-2),接下来两个字节则保存537的最后两个字节部分,并且其是以倒序的方式存储的;③判断i是否在(-∞, -129]内(不能用一个字节保存的负数),如果在,则第一个字节保存的数字为[-128, -120]之间的一个数字,其与-120的差值表示接下来将用几个字节保存i的具体数据。
总结来说,如果一个整数能够用一个字节保存,并且在-112~127的范围内,那么将在流中使用一个字节保存该数字;如果该整数为正数,并且大于127,那么其将使用第一个字节表示其正负和数字部分占用的字节,第一个字节的数字范围在-120~-113之间表示其为正数,其与-112的差值表示其占用的字节数;如果该整数为负数,并且小于-128,那么第一个字节将保存一个-128~-121之间的数字,该区间表示其为负数,并且其与-120的差值表示数字部分占用的字节数。
本文首先讲解了序列化的基本作用,接着比较了Java序列化与Hadoop序列化的区别,说明了为了适应Hadoop大量的I/O请求其序列化机制所做的处理,并且讲解了Hadoop序列化的相关类图,最后我们以一个具体的实例VIntWritable讲解了Hadoop是如何以最大化节省内存的方式存储整型数据的。

