前几天发表了本文的图片版,本文原来是在 word 编写的,后来想要发布到开源中国的博客,为了图方便,就直接截图上传到博客了。很多朋友看了之后留言,想要文字版的。本文篇幅非常长,把文字整理到博客真的非常费时。还好终于整理好了,献给你们,希望对你们有帮助。
本文源代码上传到了码云,请点击 LambdaExpression 获取。
本文微信公众号同步发布,微信扫一扫文章末尾二维码或搜索 郑宝填 即可关注。
目 录
1. LAMBDA 表达式是什么
2. LAMBDA 表达式用在何处
2.1. 方法一:创建方法,寻找符合条件的会员,但方法所指定的条件是硬编码
2.2. 方法二:创建一个适应性更好的方法,去寻找符合条件的会员
2.3. 方法三:在独立类中定义筛选会员的条件
2.4. 方法四:在匿名类中定义筛选会员的条件
2.5. 方法五:使用 LAMBDA 表达式规定筛选会员的条件
2.6. 方法六:在标准函数式接口环境中,使用 LAMBDA 表达式
2.7. 方法七:让程序的所有功能都使用 LAMBDA 表达式
2.8. 方法八:使用泛型,进一步提高方法的适应性
2.9. 方法九:使用聚合操作,并用 LAMBDA 表达式作为聚合操作的参数
3. 在 GUI 应用程序中使用 LAMBDA 表达式
4. LAMBDA 表达式语法
5. 变量访问权限
6. 目标类型
6.1. 目标类型和方法参数
7. 序列化
8. 方法引用
8.1. 访问静态方法
8.2. 访问特定对象的实例方法
8.3. 访问特定类型的随机对象的实例方法
8.4. 访问构造函数
1. Lambda 表达式是什么
Lambda 表达式是 Java 8 的新特性,是 Oracle 公司为了增强 Java 基础功能而引入的一种编程语法。请注意, Lambda 表达式是一种新的 Java 编程语法,你将会看到你以前所没有看到的 Java 编程语法,相信能够让你耳目一新。
首先,需要指出的是,对于第一次接触 Lamdba 表达式的程序员来说,尽管 Lambda 表达式看起来很新鲜,但需要注意的是, Lamdba 表达式本质是一个函数式接口( functional interface )的实现类的实例。
函数式接口:一个加上注解 @FunctionalInterface 的接口,例如接口 Comparator<T> 。这样的接口只有一个抽象方法( 方法被 public abstract 修饰,或是默认没有任何修饰)。注解 @FunctionalInterface 是一个信息型( informative annotation )的注解,标示接口是一个函数式的接口,区别于普通的接口。需要注意的是,函数式接口中的默认方法,因为他们已经有了默认实现,所以他们并不计入抽象方法。关于默认方法,以后会讲,此处暂时不展开。另外,函数式接口所定义的抽象方法若是和顶级类 Object 定义的抽象方法一样,该方法不计入函数式接口的抽象方法。比如,函数式接口定义了这样一个方法,“ int hashCode(); ”,因为 Object 顶级类也定义这样一个抽象方法,“ public native int hashCode(); ”,所以抽象方法 hashCode 不计入函数式接口的抽象方法。这时你在思考,为何这样的抽象方法不计入呢?原因很简单。 Java 语法规定,任何类都有一个默认的上级类,那就是顶级类 Object,并对顶级 Object 的抽象方法做了默认实现。在本例中,函数式接口的实现类也是一样,它也默认继承了顶级类 Object ,并顶级类 Object 的抽象方法 hashCode 做了默认实现,这相当于,对函数式接口中定义的 hashCode 也做了默认实现,函数式接口的实现类若是不想覆盖抽象方法 hashCode ,保持默认实现,在 Java 语法上讲,完全没有问题。正是因为这些抽象方法(函数式接口和顶级类 Object 都定义的抽象方法),在函数式接口的实现类中可以不覆盖,所有它们不计入函数式接口的抽象方法。只有全新定义的抽象方法能被计入函数式接口的抽象方法,而且只有唯一的一个。
需要指出的是,若是一个接口的定义符合函数式接口的定义,即使没有加上注解 @FunctionalInterface ,编译器同样会认为它是一个函数式接口。@FunctionalInterface 是一个信息型的注解,起到标示的作用,让人一目了然。同时,若是一个接口加上此注解,但是,定义却是不符合函数式接口的定义,编译器便会报出错误。所以,我们建议,若是你想定义一个函数式接口,最好还是写上注解 @FunctionalInterface ,虽然这不是必须的。
我们说过, Lambda 表达式是函数式接口实现类的实例,那么,编写Lambda 表达式,实际上,就是在编写函数式接口唯一的抽象方法的实现。
Lambda 表达式有如下特点:
1.调用方法时,它可以作为方法的参数。调用方法时,需要给方法参数传值,这个值可以是基础类型的值,也可以是一个类的实例。在 Java 8 中,你可以把一个 Lambda 表达式传递给方法,作为方法的参数。 Lambda 表达式是函数式接口实现类的实例,所以, lambda 表达式作为方法的参数,实际就是把类实例作为方法的参数。编写 Lambda 表达式,实际是编写函数式接口唯一的抽象方法的实现。因此,它是具备某种行为,或者说是具备某种功能的代码单元,这样的功能代码,可以传递给方法的参数。
2.方法引用( Method References )更加简洁和可读性更好,它由lambda 表达式演变而来。关于方法引用,我们接下来会详细的讲解,你会见识它这一振奋人心的特性。
3.默认方法的功能允许你把新的默认方法添加到老旧的接口中,但依旧能够保持兼容性。一般来说,我们定义了接口,接着就会给这个接口添加一个或一个以上的实现类。在后期的程序版本升级中,我们需要修改早期定义的接口,为之添加新的方法。若是这些方法是默认的,也即是 public abstract,那么,该接口的所有实现类都必须做相应的修改,为这些新添加的抽象方法添加实现。若是不去修改这些实现类,那么,编译报错,出现了代码兼容性的问题。于是,我们就开始思考,能否做到,为早期的接口添加方法的同时,不用去修改它的实现类,代码依旧可以不报错,保持兼容性呢?若是把这些在早期定义的接口中新添加的方法定义为默认方法,即有关键字 default,这样可以保证兼容性。默认方法,即是在接口定义它时,已经为之做了默认实现的方法。既然如此,接口的实现类可以重写它,也可以不重写它,保持它默认的实现。再次提醒一下,默认方法的定义,需要加上关键字 default。关于默认方法,以后会详细讲解,此处暂时不展开。
4.静态方法的功能允许你把新的静态方法添加到老旧的接口中,但依旧能够保持兼容性。静态方法即是静态的默认方法。在接口定义方法中,加上关键字 static。既然静态方法也是默认方法,为早期的接口添加静态方法的同时,不用去修改它的实现类,代码依旧可以不报错,保持兼容性。关于静态方法,以后会详细讲解,此处暂时不展开。
5. Java 8 新添加了一些类和增强了一些类(修改原有的类,使之功能更加强大),很好的利用了 Lambda 表达式和 Stream 。关于 Stream,接下类我们会详细的讲解。
许多的方法,它的参数是接口类型的,当我们的程序调用这个方法时,需要为之传递一个实现了这个接口的实现类的实例。此处,我们假设有一个方法 F,它的参数是接口类型 I,为了调用这个方法 F,一种比较笨拙的方式是,定义一个类,假设为 B,类 B 实现接口 I,创建类 B 的实例,拿着类 B 的实例作为方法 F 的参数。显然,人们意识到了这种调用方法的笨拙,于是,就出现了匿名的实现类。我们知道,匿名的实现类,不需要独立创建接口的实现类,在给方法传递参数时即可直接实例化一个匿名类的实例,同时,不需要指定接口实现类的类名(即称之为匿名)。这样的方式,显得更加的简洁和方便。
但是,有了匿名实现类,我们依旧面临一个问题。若是接口只有一个抽象方法,为了实现这个抽象方法,我们还要为之创建匿名实现类,这样还是显得很笨拙和不清晰。在这样的情景中,使用 Lambda 表达式,你将会看到更加简洁和可读性更好的代码。如同前面所讲,调用方法时, Lambda 可以作为方法的参数。Lambda 表达式是函数式接口实现类的实例,所以,Lambda 表达式作为方法的参数,实际就是把一个类实例作为方法的参数。Lambda 表达式表达或是设计了一组功能,把它传递给方法作为参数,实际上,可以理解为把一组功能传递给了方法。因此,为了让代码更加简洁,编程更加高效,调用方法(该方法的参数类型是接口类型)时,若接口有多个抽象方法,我们可以创建这个接口的匿名实现类的实例,作为方法的参数。若是接口只有唯一一个抽象方法,比如函数式接口,我们可以创建这个接口的 Lambda 表达式,作为调用方法的参数,把一组功能传递给方法。比如说,在一个 GUI ( Graphical User Interface )程序中,我们点击按钮,就会调用响应函数,我们可以把 Lambda 表达式作为响应函数的参数,传递给响应函数。这个 Lambda 表达式规定了响应逻辑,比如弹出一个提示窗口给 GUI 使用用户。
2. Lambda 表达式用在何处
我们假设有这样一种情景,我们要创建一个社交网络应用( social networking application ),管理员应该能够管理所有的应用会员( members of the social networking application ),当会员符合一定的条件,管理员就会对他们执行一些操作,比如给他们发送消息。下面,我们详细地描述这个场景。
业务:对符合条件,被选中的会员执行一些操作;
执行者:管理员;
前置条件:管理员已经登录社交网络应用;
后置条件:只对符合条件,被选中的会员执行一些操作,而不是针对所有会员。
详细业务:1. 管理员指定条件;2. 管理员指定操作;3.管理员点击提交按钮;4. 系统后台找出符合条件的会员;5.系统后台对符合条件的会员执行操作。
扩展:管理员在点击提交按钮之前,或者是在管理员指定的操作发生之前,管理员能够预览符合指定条件的会员。
业务发生的频率:一天能发生多次。
假设社交网络应用的会员实体类如下所示:
package cn.lambda.test; import java.time.LocalDate; public class Person { // 性别枚举 public enum Sex { MALE, FEMALE } private String name; // 姓名 private LocalDate birthday; // 生日 private Sex gender; // 性别 private String emailAddress; // 邮件地址 private int age; // 年龄 public void printPerson() { // 打印会员的个人信息 } // getter setter methods }
假设所有应用会员存储在集合 List<Person> roster 对象中。
下面我们使用 9 种方法实现上述的场景,设计的难度由浅到深,适应性由窄到广。一开始,我们使用单纯( naive )的方法,接着呢,我们使用独立类和匿名类改善这个方法,最终,我们使用 Lambda 表达式,让方法变得高效并且简洁。
2.1. 方法一:创建方法,寻找符合条件的会员,但方法所指定的条件是硬编码
因为这个方法只能匹配一种条件,即年龄大于指定的数字,若是需要匹配其他的条件,比如性别是男的,一种最简单的方式就是,再次创建一个方法,让他匹配另一种条件,即性别。
public static void printPersonsOlderThan(List<Person> roster, int age) { for (Person p : roster) { if (p.getAge() >= age) { p.printPerson(); } } }
这个方法的适应性很窄,若是你的程序进行升级,这个方法很有可能就不能用了。假设你修改了会员实体类的数据结构,把年龄 age 的数据类型修改为字符 String 类型;假设你修改了计算年龄的算法,年龄小于某个指定的数字。这样的一些修改,这个方法不但不能实现业务,而且有可能编译错误。另外,就算后期不去升级程序,为了适应匹配其他的条件,比如指定性别,指定邮件地址等,我们需要创建许多类似的方法去满足业务的需要。
2.2. 方法二:创建一个适应性更好的方法,去寻找符合条件的会员
如下这个方法比起上一个例子的方法 printPersonsOlderThan ,它的适应性更好,目标会员的条件是他们的年龄范围。
public static void printPersonsWithinAgeRange(List<Person> roster, int low, int high) { for (Person p : roster) { if (low <= p.getAge() && p.getAge() < high) { p.printPerson(); } } }
若是把会员的年龄作为筛选条件,这个方法 printPersonsWithinAgeRange 适应性比起上一个例子要好。但问题是,若是要把会员的性别作为筛选条件呢?或是要把会员的年龄范围和指定性别作为联合筛选条件呢?若是你决定改变会员实体类的数据结构,比如增加会员的关系状态,地理位置,接着要把他们作为筛选条件呢?很显然,我们需要创建很多方法满足各种条件的筛选,这些方法是分离的( separate method ),独立的,因此代码是很易碎的( brittle code )。一种替换这些易碎代码的方案是,把筛选的条件定义在一个独立的类中。
2.3. 方法三:在独立类中定义筛选会员的条件
public static void printPersons(List<Person> roster, CheckPerson tester) { for (Person p : roster) { if (tester.test(p)) { p.printPerson(); } } }
在这个方法中,所有的应用会员放在 List 集合 roster 中,遍历每一个会员,判断他是否符合条件。方法的第二个 CheckPerson 接口类型的参数 tester,它就是筛选会员的条件。判断的方式是调用 tester.test 方法,若是该方法返回 true, 表明当前会员符合条件,调用当前会员的 printPerson 方法,打印会员的信息。
方法的第二个参数是 CheckPerson 接口类型的,我们需要定义接口 CheckPerson。
package cn.lambda.test; public interface CheckPerson { boolean test(Person p); }
下面我们需要为这个接口 CheckPerson 定义实现类,实现抽象方法 test,实现的逻辑,即筛选条件,是符合美国义务兵役制度的会员,假设符合这一制度的具体条件是男性且年龄在 18 至 25 岁之间。
package cn.lambda.test; class CheckPersonEligibleForSelectiveService implements CheckPerson { public boolean test(Person p) { return p.getGender() == Person.Sex.MALE && p.getAge() >= 18 && p.getAge() <= 25; } }
为了能够完成这个场景,最后我们需要调用方法 printPersons。
List<Person> roster = ... printPersons(roster, new CheckPersonEligibleForSelectiveService());
这个方法 printPersons 看起来不是那么易碎了,就算我们后期升级程序,需要修改了会员实体类 Person 的数据结构,或是修改筛选条件,我们依旧不需要改变这个方法printPersons ,因为这个方法不再出现判断条件,更没有出现会员实体类 Person 的任何字段。具体的判断条件被定义在一个独立的接口实现类中。但是,我们依旧面临一个问题,为了能够筛选出符合条件的应用会员,我们需要去维护一个接口 CheckPerson 和一个实现类 CheckPersonEligibleForSelectiveService ,这依旧是件麻烦事。于是我们想到了改进的方案,使用匿名类( anonymous class )代替独立定义的接口实现类。比如这个例子中,实现类 CheckPersonEligibleForSelectiveService 就是独立定义的,下一个例子我们要使用匿名类替换它。
2.4. 方法四:在匿名类中定义筛选会员的条件
printPersons 的第二个参数是 CheckPerson 接口类型的,在本例子中,调用方法 printPersons 时,此参数是一个匿名类的实例。在这个匿名类中,规定了筛选应用会员的条件,即符合美国义务兵役制,制度的具体内容就是应用会员是男性且年龄介于 18 岁至 25 岁之间。
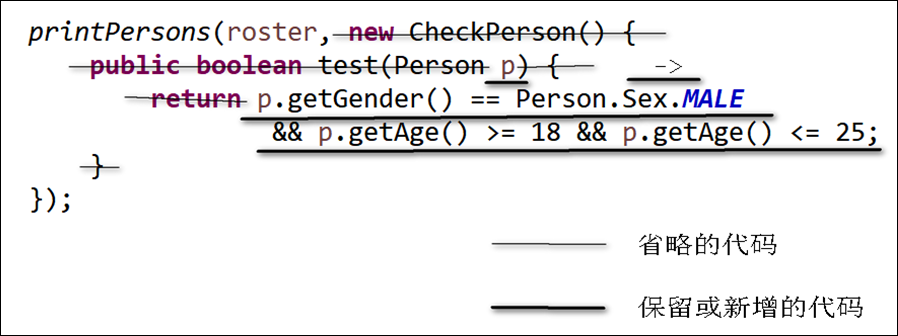
List<Person> roster = ... printPersons(roster, new CheckPerson() { public boolean test(Person p) { return p.getGender() == Person.Sex.MALE && p.getAge() >= 18 && p.getAge() <= 25; } });
我们发现,这个方法的调用,有效地减少了代码量,因为我们不再需要在独立的实现类中定义筛选会员的条件。但是,这并不完美,接口 CheckPerson 的定义非常简单,只有唯一一个抽象方法 test,我们的定义了该接口的匿名实现类,实现了抽象方法 test,并创建了匿名类的实例,有关匿名类的代码看起来太多了,因为它仅仅只需实现一个抽象方法 test。下一个例子,我们正式使用 Lambda 表达式代替匿名类,你会看到更加简洁和可读性更好的代码。
2.5. 方法五:使用 Lambda 表达式规定筛选会员的条件
接口 CheckPerson 是一个函数式接口,因为该接口只有唯一一个抽象方法 test。前面强调过,一个接口的定义一旦符合函数式接口的定义,那么编译器就会认为它是一个函数式接口,不管该接口是否加上注解 @FunctionalInterface 。显然,定义接口 CheckPerson 时,我们并没有加上注解 @FunctionalInterface 。 Lambda 表达式的本质是函数式接口的实现类实例,因此编写 Lambda 表达式本质就是在编写函数式接口唯一一个抽象方法的实现逻辑。既然抽象方法只有唯一一个,Lambda 表达式可以省略抽象方法的名字。下面我们调用方法 printPersons ,使用 Lambda 表达式代替匿名类,请注意 printPersons 的第二个参数。
List<Person> roster = ... printPersons(roster, (Person p) -> p.getGender() == Person.Sex.MALE && p.getAge() >= 18 && p.getAge() <= 25);
由于 Lambda 表达式从匿名类演化而来,二者从本质上也是相同。那我们一起分析,相比较于匿名类,Lambda 表达式有哪些新的表现形式。在本例中,Lambda 表达式省略了“ new 接口 一对小括号 一对大括号”和“抽象方法声明的前部分”的代码,即省略了“new CheckPerson(){...} ”和“public boolean test ”,只剩下抽象方法声明的后部分,小括号以及小括号里面的方法参数类型和参数名字,即“(Person p) ”。紧接着小括号,有一个指向右边的箭头,箭头左边是抽象方法声明的后部分,小括号以及小括号里面的方法参数类型和参数名字,箭头右边是抽象方法的实现逻辑。实现逻辑部分,省略了一对大括号和 return 关键字,只剩下一条表达式语句。相信你可以感受到, Lambda 表达式是多么的简洁,并且看起来很清晰,因为它省略了许多不必要的代码。关于 Lambda 表达式的语法,接下来我们还会全面的讲解,此处咱不展开,需要指出的是,本例中的 Lambda 表达式还可以进一步简化。箭头左边,小括号可以省略,参数的类型可以省略,只剩下参数的名字,即 p 。
List<Person> roster = ... printPersons(roster, p -> p.getGender() == Person.Sex.MALE && p.getAge() >= 18 && p.getAge() <= 25); }
若你第一次看到 Lambda 表达式,相信会被它的简洁性和可读性所震撼。即便如此,Java 设计者们依旧觉得还可以让程序代码更少,让设计更加的细腻和极致。更进一步的设计就涉及标准的函数式接口,我们自定义了函数式接口 CheckPerson ,与之对应就是 JDK 提供的标准函数式接口,下一个例子我们就来聊聊标准函数式接口。
2.6. 方法六:在标准函数式接口环境中,使用 Lambda 表达式
我们再次仔细观察之前自定义的函数式接口 CheckPerson 。
package cn.lambda.test; public interface CheckPerson { boolean test(Person p); }
这个接口极其简单,有唯一一个抽象方法(所有函数式接口都有这个特征),抽象方法 test 有一个参数和一个 boolean 类型的返回值。这个抽象方法是如此的简单,我们完全没有必要自己写代码把它定义在我们的程序里,这种事情可以交给 JDK 去做。因此,JDK 定义了几种标准的函数式接口,其中一个标准的函数式接口的抽象方法就是接收一个参数和一个 boolean 类型的返回值,我们的程序可以直接利用这个标准的函数式接口。 JDK 定义的几种函数式接口,放在包 java.util.function 中。
我们可以使用标准函数式接口 Predicate<T> 替代自定义函数式接口 CheckPerson 。我们看以看到, Predicate<T> 有唯一一个抽象方法 boolean test(T t) ,几个默认方法( 关键字 default ),一个静态方法( 关键字 static ),由于默认方法和静态方法都有默认的实现逻辑,因此它们都不算是抽象方法。
标准函数式接口 Predicate<T> ,它代表着一个断言, Predicate 的中文意思就是断言。有些人可能对断言这个词有些陌生,通俗地讲,断言就是对一个对象或是一个基本数据作出判断,要么判断为 true ,要么判断为 false ,可见,断言的结果是 boolean 类型的。既然涉及到断言(判断),就需要断言标准和等待断言的对象或是等待断言的基本数据。泛型接口 Predicate<T> 的尖括号有一个类型参数 T,它是该接口抽象方法 test 的参数类型。抽象方法的类型为 T 的参数就是等待断言的对象,那断言的标准是什么呢?我们先来看看 Predicate<T> 唯一的抽象方法 test 的定义:
boolean test(T t);
该抽象方法的功能是根据断言标准,对等待断言的对象,也就是参数 T t ,评估出结果。若是等待断言的对象 T t 符合断言标准,该抽象方法返回 true ,否则返回 false 。标准函数式接口的实现方式可以使用匿名类,也可以使用 Lambda 表达式,但无论使用哪一种,都必须对唯一的抽象方法 test 作出实现,实现的逻辑就是断言的标准。比如,实现的逻辑是筛选出符合美国义务兵役制度,具体条件是男性且年龄在 18 至 25 岁之间的应用会员。其中,“符合美国义务兵役制度,具体条件是男性且年龄在18至25岁之间”是断言标准,“应用会员”就是等待断言的对象。
在此处,我们有必要简单回忆一下泛型的知识。 Predicate<T> 是一个泛型接口,和泛型类一样,泛型接口可以在尖括号“ <> ”中,指定一个或多个类型参数。对于接口 Predicate<T> 而言,它只有一个类型参数,那就是 T 。 T 称之为泛型参数,泛型类,泛型接口称之为泛型类型( generic type )。当我们创建或声明泛型类实例,或是创建泛型接口的实现类的实例,或是声明泛型接口类型的实例时,需要给泛型参数指定一个实际类型的参数,如此一来,泛型类,或是泛型接口就具有了实际类型的参数,此时,他们称之为参数化类型( parameterized type )。请注意泛型类型和参数化类型的区别,前者的参数类型是泛型,后者的参数类型是实际类型。下面代码中的 Predicate<Person> 就是一个参数化类型,因为它的参数是实际类型 Person 。
interface Predicate<Person> { boolean test(Person t); }
这个参数化类型 Predicate<Person> 的抽象方法有一个 boolean 类型的返回值和一个参数,参数类型是 Person ,这和自定义的函数式接口 CheckPerson 的抽象方法 test 一模一样。因此,我们不必再去自定义 CheckPerson ,而是使用标准函数式接口 Predicate<T> 代替它。
public static void printPersonsWithPredicate(List<Person> roster, Predicate<Person> tester) { for (Person p : roster) { if (tester.test(p)) { p.printPerson(); } } }
接下来,我需要调用这个方法 printPersonsWithPredicate ,筛选出符合条件的应用会员,条件是符合美国义务兵役制度的会员,假设符合这一制度的具体条件是男性且年龄在 18 至 25 岁之间。
List<Person> roster = ... printPersonsWithPredicate(roster, p -> p.getGender() == Person.Sex.MALE && p.getAge() >= 18 && p.getAge() <= 25);
在本例中,方法 printPersonsWithPredicate 使得我们的代码更加简洁了,省略了自定义函数式接口 CheckPerson 。但是,这个方法的适应性依旧较窄。现有代码的逻辑是,遍历应用的每一个会员,若是会员符合指定的条件,就把会员的信息打印出来。请注意,对符合条件的会员所执行的操作就是打印出他的信息,这就把操作写死了。若要想要改变操作了,不想打印会员信息了,这个方法就不适用了。在本例中,方法 printPersonsWithPredicate 的参数使用了一个标准函数式接口,用来接收 Lambda 表达式,该 Lambda 表达式是一个判断标准。标准的函数式接口有好几个,下一个例子,我们使用其他的标准函数式接口,不再对符合条件的会员所执行的操作写死,改造后,方法的适应性变得更好。
2.7. 方法七:让程序的所有功能都使用 Lambda 表达式
除了对符合条件的会员执行打印信息的操作“ printPerson() ”外,我们还可以使用一个 Lambda 表达式,传递给方法,在这个方法中,对这些符合条件的会员执行更多的操作。也就是说,我们可以使用 Lambda 表达式代替 printPerson() ,使得操作适用更多的情况,而不单单是打印信息。既然操作使用 Lambda 表达式,那么方法的定义中需要一个函数式接口类型的参数,用来接收表达操作的 Lambda 表达式( Lambda 表达式的本质是函数式接口的实现类的实例)。我们思考操作这个动作,它需要一个参数,在本例中,该参数代表一个会员,一个 Person 类型的参数。有了这个 Person 类型的参数,操作才能对会员开展。另外,操作不需要返回值( void )。方法的定义中需要一个函数式接口类型的参数,首先,通常我们需要去定义函数式接口。但是,通过我们刚刚的分析,该函数式接口的抽象方法需要一个参数并且没有返回值,正好标准函数式接口有这样一个接口,它就是 Consumer<T> 。因此,我们没有必要去自定义函数式接口。
标准函数式接口 Consumer<T> 代表执行一个操作,它的抽象方法接收单个参数且没有结果(返回值为 void )。尖括号“ <> ”有一个类型参数,代表该接口的抽象方法的参数类型。它有一个抽象方法和一个默认方法,抽象方法定义如下:
void accept(T t);
该抽象方法对指定的参数 T t 执行一个操作。
public static void processPersons(List<Person> roster, Predicate<Person> tester, Consumer<Person> block) { for (Person p : roster) { if (tester.test(p)) { block.accept(p); } } }
你仔细观察这个方法 processPersons,和上一个例子的方法 printPersonsWithPredicate 相比,你会发现它多了一个标准函数式接口类型的参数 Consumer<Person> block ,这个参数是用来接收表达操作的 Lambda 表达式的,操作即是对符合条件的应用会员执行操作。在 printPersonsWithPredicate 方法中,只能对符合条件的会员执行打印信息的操作,代码是“ p.printPerson(); ”,而在本例的方法 processPersons 中,代码被替换成了“ block.accept(p); ”,表示方法 processPersons 不再把符合条件的会员所执行操作限制死,具体的操作由调用方法 processPersons 的调用者决定时。调用者使用 Lambda 表达式决定操作的具体内容,把 Lambda 表达式作为方法 processPersons 的第三个参数,传递给方法 processPersons 。
最终,为了是实现我们的业务场景,我们需要调用方法 processPersons :
List<Person> roster = ... processPersons(roster, p -> p.getGender() == Person.Sex.MALE && p.getAge() >= 18 && p.getAge() <= 25, p -> p.printPerson());
关注 processPersons 的第三个参数,它代表对符合条件的应用会员执行操作的 Lambda 表达式。该 Lambda 表达式只有一个参数,即 p ,它对标准函数式接口 Consumer<T> 的抽象方法 accept 的实现逻辑是“ p -> p.printPerson()); ”,即打印出会员的信息,当然,它也可以是其他的实现逻辑,其他的操作。也许,现在你对 processPersons 方法的第三个参数的内涵依旧不是很能理解。下面,我们尝试使用匿名实现类的方式来调用 processPerson 方法,相信你会有更深的认识。
List<Person> roster = ... processPersons(roster, p -> p.getGender() == Person.Sex.MALE && p.getAge() >= 18 && p.getAge() <= 25, new Consumer<Person>() { @Override public void accept(Person t) { t.printPerson(); } });
我们再来看看 processPersons 方法的定义:
public static void processPersons(List<Person> roster, Predicate<Person> tester, Consumer<Person> block) { for (Person p : roster) { if (tester.test(p)) { block.accept(p); } } }
它的第三个参数是 Consumer<Person> block ,当调用 processPersons 时,我们需要为之传递一个实现了标准函数式接口 Consumer<Person> 的实现类的实例。这个实例可以是匿名类的实例,也可以是 Lambda 表达式。此处,这个实例是匿名实现类的实例。因为接口 Consumer<Person> 有唯一一个抽象方法 accept ,所以,匿名实现类需要对这个抽象方法进行实现,实现的逻辑是“ t.printPerson(); ”,即打印应用会员信息。在对方法 processPersons 定义时,关于第三个参数,即代表对符合条件的应用会员执行操作,有这样的代码,“ block.accept(p); ”,最终调用这个方法 processPersons 时,真正执行的就是 Consumer<Person> 实现类的 accept 方法。在此例中,真正执行的就是匿名类的 accept 方法或 Lambda 表达式的 accept 方法(当然, Lambad 表达式已经看不到 accept 方法名了),即打印应用会员信息,“ t.printPerson(); ”。
在这个例子的方法 processPersons 中,对符合条件的应用会员执行的操作可以适应多种情况,显然它的适应性变得更好了。到此为止,相信你心中仍是有个疑问,对符合条件的应用会员所执行的操作,目前是直接针对会员这个实体类的对象操作的,即直接对 Person 类型的对象进行操作,比如 t.printPerson() ,直接使用 Person 对象调用 printPerson() 方法。若是想要对会员的某些属性直接进行操作,那该怎么办呢?比如说,我想要直接操作会员的邮件地址,把会员的邮件地址打印出来。请你注意我的用词“直接”。换言之,标准函数式接口 Consumer<T> 的抽象方法的类型不是 Person ,而是 String 类型(会员邮件地址是 String 类型)。显然,在这样的场景下,首先,我们需要对符合条件的应用会员执行一个提取(转化)操作,把会员的邮件地址提取出来,接着把邮件地址作为标准函数式接口 Consumer<T> 抽象方法的参数,这样,方能直接针对会员的邮件地址进行操作。这儿,涉及到一个提取(转化)操作,这个提取方法需要一个参数,即 Person 类型的参数,它是应用会员,它是提取的原材料。还需要一个返回值,即 String 类型的的返回值,它是邮件地址,他是提取的目标。这个提取操作同样可以使用 Lambda 表达式来表达,既然涉及到新的 Lambda 表达式, processPersons 需要一个新的函数式接口类型的参数,用来接收这个表达提取的 Lambda 表达式。根据刚刚的分析,这个函数式接口的抽象方法需要一个参数,一个返回值,恰好有一个标准的函数式接口可以满足要求,这样一来我们没有必须自定义函数式接口,直接使用这个标准函数式接口,它就是 Function<T, R> 。
Function<T, R> 是一个标准的函数式接口,它接收一个参数,产出一个结果(一个返回值)。它是一个泛型接口,尖括号有两个类型的参数,第一个类型参数 T 表示抽象方法的参数类型,第二个类型参数 R 表示抽象方法的返回值类型。它有两个默认方法,一个静态方法,一个抽象方法,抽象方法如下所示:
R apply(T t);
该抽象方法代表着对参数 T t 执行一个功能( function ),比如执行一个提取或是转化功能,得到类型为 R 的结果。 T t 是执行功能的原材料,R 是执行功能的目标结果的类型。
public static void processPersonsWithFunction(List<Person> roster, Predicate<Person> tester, Function<Person, String> mapper, Consumer<String> block) { for (Person p : roster) { if (tester.test(p)) { String data = mapper.apply(p); block.accept(data); } } }
我们关注以下这两行代码:
String data = mapper.apply(p); block.accept(data);
方法 apply 的参数 p ,是符合条件的应用会员。方法 apply 对会员 p 执行一个功能(转化或提取),得到 String 类型的 data( data 代表什么意思?具体的意思由调用者决定。在本例中, data 代表会员的邮件地址)。接着,accept 方法对会员的邮件地址执行一个操作。现在你可以看到,程序不再直接针对应用会员执行操作,而是直接针对会员的邮件地址进行操作。相信你也注意到,方法 processPersonsWithFunction 的第四个参数 Consumer<String> block ,标准函数式接口 Consumer 的类型参数不再是 Person 类型的,已被修改为 String 类型了。
最终,为了是实现我们的业务场景,我们需要调用方法 processPersonsWithFunction :
List<Person> roster = ... processPersonsWithFunction(roster, p -> p.getGender() == Person.Sex.MALE && p.getAge() >= 18 && p.getAge() <= 25, p -> p.getEmailAddress(), email -> System.out.println(email));
传递给 processPersonsWithFunction 的第三个参数的是 Lambda 表达式,该 Lambda表达式代表提取符合条件的应用会员的邮件地址(把符合条件的应用会员转化为会员的邮件地址)。第四个参数仍然是一个 Lambda 表达式,该表达式代表对邮件地址执行一个操作,即打印邮件地址。作为初学者,也许现在你对processPersonsWithFunction 方法的第三、第四个参数的内涵依旧不是很能理解。下面,我们尝试使用匿名实现类的方式来调用processPersonsWithFunction 方法,相信你会有更深的认识。
List<Person> roster = ... processPersonsWithFunction(roster, p -> p.getGender() == Person.Sex.MALE && p.getAge() >= 18 && p.getAge() <= 25, new Function<Person, String>() { @Override public String apply(Person t) { return t.getEmailAddress(); } }, new Consumer<String>() { @Override public void accept(String t) { System.out.println(t); } });
2.8. 方法八:使用泛型,进一步提高方法的适应性
我们仔细观察方法 processPersonsWithFunction 的定义,该方法的所有参数声明都是实际类型。
public static void processPersonsWithFunction(List<Person> roster, Predicate<Person> tester, Function<Person, String> mapper, Consumer<String> block) { for (Person p : roster) { if (tester.test(p)) { String data = mapper.apply(p); block.accept(data); } } }
然而,在这个方法体的逻辑中,和参数的实际类型联系并都不密切。比如,第一个参数是元素类型是 Person 类型的应用会员集合 roster 。方法体的逻辑中对这个集合进行遍历时,单个 Person p 并没有访问 Person 类的任何属性和方法。另外,对于 List<X> 集合 roster ,方法体逻辑同样没有访问 List<X> 类的任何属性和方法。第二个参数是等待断言的对象类型是 Person 类型的断言 tester ,方法逻辑中关于 tester 有这样的代码,“ tester.test(p) ”,依旧没有访问 Person 类的任何属性和方法。第三个参数和第四个参数也是同样的情况。既然如此,在方法的定义中,参数声明类型应该使用泛型,让它的适应性更进一步。另外,我们知道集合 List<X> 是集合大家庭的一员,集合都是直接或间接实现了接口 Iterable<X> ,所以,我们可以使用 Iterable<X> 类替代 List<X> 。
public static <X, Y> void processElements(Iterable<X> source, Predicate<X> tester, Function<X, Y> mapper, Consumer<Y> block) { for (X p : source) { if (tester.test(p)) { Y data = mapper.apply(p); block.accept(data); } } }
最终,为了是实现我们的业务场景,我们需要调用方法 processElements :
List<Person> roster = ... processElements(roster, p -> p.getGender() == Person.Sex.MALE && p.getAge() >= 18 && p.getAge() <= 25, p -> p.getEmailAddress(), email -> System.out.println(email) );
对方法 processElements 的调用和对方法 processPersonsWithFunction 的调用没有不同。只是,方法 processElements 的适应性得到更进一步的提升。
值得关注的是, processElements 这个方法的执行流程,通过分析执行流程,我们可以为此进入另一个话题。
1.从集合数据源中获取一个资源对象( source object )。在本例中,遍历集合 List<Person> roster,获取一个一个的应用会员 Person 。需要注意的是,roster 的类型是 List<X> ,同样也是类型 Iterable<X> 。
2.使用断言,筛选资源对象。经筛选后,资源对象成为了已筛选对象( filtered object )。在本例中,筛选符合美国义务兵役制度的应用会员,制度的具体条件是男性且年龄在 18 至 25 岁之间。断言参数是标准函数式接口类型, Predicate<X> tester ,我们使用 Lambda 表达式为该参数传值。
3.对已筛选对象执行转化操作。经转化后,已筛选对象成为了已映射对象( mapped object )。在本例中,把筛选出来的应用会员转化为会员邮件地址(从筛选出来的应用会员中提取他们的邮件地址)。转化操作参数是标准函数式接口类型, Function<X, Y> mapper ,我们使用 Lambda 表达式为该参数传值。
4.对已映射对象执行操作。在本例中,该操作就是打印会员的邮件地址。操作参数是标准函数式接口类型, Consumer<Y> block ,我们使用 Lambda 表达式为该参数传值。
我们可以清楚的看到,以上执行流程是一环接一环。集合数据源->资源对象->已筛选对象->已映射对象->操作。为了执行这个流程,我们的方法 processElements 一共声明了 4 个参数,其中一个是集合类型,三个是标准函数式接口类型。
1.针对第一个集合类型的参数 Iterable<X> source ,我们对它进行遍历,获取资源对象。于是我们思考,能否让 JDK 自动遍历?
2.针对第二个标准函数式接口类型的参数 Predicate<X> tester ,我们调用它的 test 方法对资源对象进行断言,获取已筛选对象。于是我们思考,能否让 JDK自动进行断言?
3. 针对第三个标准函数式接口类型的参数 Function<X, Y> mapper ,我们调用它的 apply 方法对已筛选对象进行转化,获得已映射对象。于是我们思考,能否让 JDK 自动进行转化?
4. 针对第四个标准函数式接口类型的参数 Consumer<Y> block ,我们调用它的 accept 方法对已映射对象执行一个操作,于是我们思考,能否让 JDK自动执行一个操作?
答案是肯定的,这需要用到聚合操作( aggregate operation )。关于聚合操作,以后会详细的讲解。下面的例子,我们先给出一个聚合操作完成我们的场景,并对聚合操作作简单解释,目的是让大家感受一个聚合操作的简洁、高效。
2.9. 方法九:使用聚合操作,并用 Lambda 表达式作为聚合操作的参数
下面我将用一句话来表达我们的业务场景,因为聚合操作从头到尾就是一条语句,这是聚合操作的典型特性,就像流水线一般,从头流到尾,不需要中断。这句话是,在应用会员列表中筛选出符合美国义务兵役制度的会员并打印出会员的邮件地址。
public static <X, Y> void processWithAggregate( Collection<X> source, Predicate<X> tester, Function<X, Y> mapper, Consumer<Y> block) { source.stream().filter(tester).map(mapper).forEach(block); }
下面简单介绍上述聚合操作中涉及到的四个 API。
default Stream<X> stream() : 使用方法 processWithAggregate的第一个参数 Collection<X> source 作为数据源,返回一个有序流( sequential Stream ),这个有序流的类型是 Stream<X> ,核心作用是能够自动遍历 Collection<X> source 中元素,并对元素(资源对象)执行各种操作。既然如此,拥有了有序流,我们不再需要手工遍历 Collection<X> source了。需要注意的是,该方法 stream 的返回值是一个泛型接口类型 Stream<X> ,尖括号“ <> ”的类型参数 X 和 Collection<X> 中的 X 保持一致。也就是说,集合中的元素类型和有序流中的元素类型是一致的。这样描述之后,你可能会误会元素存放在 Stream<X> 类型的有序流中,请你务必注意, Stream<X> 类型的有序流不会存放任何元素,它的功能是自动遍历和操作元素,元素是存放在集合中的。
Stream<X> filter(Predicate<? super X> predicate) :对有序流的元素(资源对象)使用断言进行筛选,返回一个新的有序流,新有序流中的元素是经过筛选的元素(已筛选对象)。 Filter 方法有一个参数 predicate 代表断言,关于断言前面已做详述。方法 filter 的参数是标准函数式泛型接口类型 Predicate<? super X> predicate ,尖括号“ <> ”的类型参数是 X 或 X 的父类型。该方法的返回值是一个泛型接口 Stream<X> ,尖括号“ <> ”的类型参数是 X 。之所有会有这样含义的类型参数,因为调用方法 filter (调用者)的是一个 Stream<X> 类型的实例,该实例由方法 stream 返回。
<Y> Stream<Y> map(Function<? super X, ? extends Y> mapper) :对已筛选元素(已筛选对象)执行转化操作,返回一个新的有序流,新有序流中的元素是经过转化的元素(已映射对象)。方法 map 有个参数 mapper 代表转化,关于转化前面已做详述。方法 map 的参数是标准函数式泛型接口类型 Function<? super X, ? extends Y> , 尖括号“ <> ”有两个类型参数,第一个类型参数是 X 或是 X 的父类型,它是等待转化的对象的类型,即源对象类型,第二个类型参数 Y 或 Y 的子类型,它是转化后的对象类型,即目标对象类型。 Y 可以是任意类型,在 map 方法定义的开始部分已做了声明。方法 map 的返回值是个泛型接口 Stream<Y> ,尖括号“ <> ”的类型参数是 Y ,这和目标对象的类型保持一致,该方法的返回值就是包含目标对象的有序流。之所以会有这样含义的类型参数,因为调用方法 map (调用者)的是一个 Stream<X> 类型的实例,该实例由方法 filter 返回。
void forEach(Consumer<? super Y> action) :对已转化的元素(已映射对象)执行一个操作,该方法没有返回值,不再有新的有序流产生,流结束了,方法 foreach 是个终止操作。方法有个参数 action 代表操作,关于操作前面已做详述。方法 forEach 的参数是标准函数式泛型接口类型 Consumer<? super Y> action ,尖括号“ <> ”的类型参数是 Y 或是 Y 的父类型,之所有会有这样含义的类型参数,因为调用方法 forEach (调用者)的是一个 Stream<Y> 类型的实例,该实例由方法 map 返回。
相信你已经发现,和方法 processElements 相比,方法 processWithAggregate 的第一个参数类型由 Iterable<X> 修改成了Collection<X> 。 Collection<X> 也是集合大家庭中较为顶级的接口,它继承了顶级接口 Iterable<X> 。 Collection<X> 接口有默认方法 stream ,功能是把集合作为数据源,返回一个有序流。但是,顶级接口 Iterable<X> 没有这样的方法,故需要把 Iterable<X> 替换成 Collection<X> 。
API filter、map、forEach 称之为聚合操作,聚合操作对集合的元素进行处理时,不是直接针对集合进行的,而是针对有序流,这就是为什么我们需要调用集合的 stream 方法,去获得一个有序流。有序流可以理解为元素的序列( sequence of elements ),它的主要功能是用来自动遍历和处理元素。和集合的重大区别是,有序流并不存储元素,元素是存储在集合中的。既然有序流不存储数据,那么,它的数据来自哪里?通过管道在源头获取数据。何为源头?集合就是源头之一。到目前为止,我们所接触到的有序流的数据都是来自集合。实际上,它的数据来源不止是集合,在以后的例子中,你将会看到不同的数据来源。何为管道?管道就是流操作序列。比如 filter -> map -> forEach ,你会发现他们一环扣一环,就像是一条流水线,故称为管道,即流操作序列。再一次强调,有序流并不存储数据,它是通过管道在源头获取数据。通常来说,聚合操作接收 Lambda 表达式作为参数的值,这些 Lambda 表达式具体规定聚合操作的内容。
关于聚合操作,还有很多关于功能和性能的重要知识,这些特性非常有吸引力,这些以后再讲,此处暂不展开。
最终,为了实现我们的业务场景,我们需要调用方法 processWithAggregate :
List<Person> roster = ... processWithAggregate(roster, p -> p.getGender() == Person.Sex.MALE && p.getAge() >= 18 && p.getAge() <= 25, p -> p.getEmailAddress(), email -> System.out.println(email) );
3. 在 GUI 应用程序中使用 Lambda 表达式
GUI 的全称是 Graphical User Interface ,翻译成中文是图形用户界面。 GUI 应用程序可以理解成桌面应用程序,我们日常使用的浏览器、 QQ、 Word、 Eclipse 等都属于 GUI应用程序。使用 Java 语言开发 GUI 应用程序不是很流行,这类应用程序通常使用 C++ 语言开发而成。当然,若是使用 Java 语言开发 GUI 应用程序, Lambda 也有很多的应用场景,在此我们做一些简单的介绍。如果你没打算从事开发 Java GUI 应用程序的工作,本节的内容你稍做了解即可。
GUI 应用程序开发最常见的场景就是需要去响应各种事件,比如键盘事件,鼠标事件,滚动事件等。为了响应事件,程序需要创建事件处理器,创建事件处理器通常需要实现事件处理器接口,事件处理器接口通常是函数式接口,只有唯一一个抽象方法。我们先来看一个使用 JavaFX 实现的 Java GUI 应用程序的代码片段。
Button btn = new Button(); btn.setText("Say 'Hello World'"); btn.setOnAction(new EventHandler<ActionEvent>() { @Override public void handle(ActionEvent event) { System.out.println("Hello World!"); } });
方法 setOnAction 的定义如下:
public final void setOnAction(EventHandler<ActionEvent> value);
为了响应按钮 Button btn 的鼠标单击事件,我们需要为它创建一个事件处理器。“ btn.setOnAction ”即是为按钮创建事件处理器。在本例中,匿名类的实例就是事件处理器,并把这个实例作为方法 setOnAction 的参数。该方法的参数 EventHandler<ActionEvent> value ,其类型是一个函数式接口类型,只有唯一一个抽象方法 “ void handle(T event) ”,所以,我们可以使用 Lambda 表达式来代替匿名类的实例,让它作为方法 setOnAction 的参数。
Button btn = new Button(); btn.setText("Say 'Hello World'"); btn.setOnAction( event -> System.out.println("Hello World!") );
4. Lambda 表达式语法
一个 Lambda 表达式由以下几个部分组成:
1.参数部分。参数有类型,有名字,多个参数使用逗号分隔,并用小括号括起来。比如前面多次出现的 Lambda 表达式:
p -> p.getGender() == Person.Sex.MALE && p.getAge() >= 18 && p.getAge() <= 25
你会觉得这个表达式的参数怪怪的,我们先来看这个表达式的参数的完整的代码:
(Person p) -> p.getGender() == Person.Sex.MALE && p.getAge() >= 18 && p.getAge() <= 25
Lambda 表达式的参数类型可以省略。若是只有唯一一个参数,小括号可以省略。到目前为止,我们所接触到的函数式接口的抽象方法都只接受一个参数,下面,我们来看一个它的抽象方法接受两个参数的标准函数式接口 BiFunction<T, U, R> 。
BiFunction<T, U, R> 的功能是能够接受两个参数,并产出一个结果。该泛型接口的尖括号“ <> ”有三个类型参数,第一个类型参数 T 代表抽象方法第一个参数的类型,第二个类型参数 U 代表抽象方法第二个参数的类型,第三个类型参数 R 代表抽象方法的返回值的类型。以下是该标准函数式接口抽象方法的定义:
R apply(T t, U u);
该抽象方法对指定的参数 T t , U u 执行一个功能(转化、提取等操作),返回一个 R 类型的结果。
BiFunction<String, Integer, Float> biFunction = (firstAddend, secondAddend) -> Float.parseFloat(firstAddend) + secondAddend;
这个 Lambda 表达式代表对两个参数 String firstAddend, Integer secondAddend 执行一个功能,得到一个 Float 类型的结果。具体来说,就是对两个参数进行加法运算,得到和。我们假设 String firstAddend 是数字符串,所以使用 Float.parseFloat(firstAddend) 转为 Float 类型,接着和 Integer secondAddend 进行加法运算,得到 Float 类型的和。
2.箭头 -> 。
3.方法体。Lambda 表达式的方法体和普通函数的方法一样,使用花括号“{} ”括起来。花括号里面写 Java 语句。比如前面多次出现的 Lambda 表达式:
p -> p.getGender() == Person.Sex.MALE && p.getAge() >= 18 && p.getAge() <= 25
你会觉得这个表达式的方法体怪怪的,我们先来看这个表达式的完整的代码:
(Person p) -> { return p.getGender() == Person.Sex.MALE && p.getAge() >= 18 && p.getAge() <= 25; }
若 Lambda 表达式的方法体只有一条语句,形式为“ {return 表达式;} ”,则这三部分“花括号 return ; ”可以省略,只留下“表达式”。

我们再来看一个前面写过的 lambda 表达式:
email -> System.out.println(email)
我们先来看这个 Lambda 表达式的方法体的完整代码:
email -> { System.out.println(email); }
若 Lambda 表达式的方法体只有一条语句,形式为“ {执行没有返回值的代码;} ”,则这两部分“{} ;”可以省略,只留下“执行没有返回值的代码”。

在讲解 Lambda 表达式参数部分时,我们写过这样的 Lambda 表达式:
BiFunction<String, Integer, Float> biFunction = (firstAddend, secondAddend) -> Float.parseFloat(firstAddend) + secondAddend;
现在我们对这个 Lambda 表达式进行改造,让它的方法体的逻辑丰富起来。
BiFunction<String, Integer, Float> biFunction2 = (firstAddend, secondAddend) -> { Float firstAddendFloat = null; try { firstAddendFloat = Float.parseFloat(firstAddend); } catch (NumberFormatException e) { System.out.println("第一个加数格式不正确,请输入数字类型的字符"); return 0f; } return firstAddendFloat + secondAddend; };
该 Lambda 表达式方法体语句不止一条,花括号就不能省略了。
5. 变量访问权限
我们多次强调, Lambda 表达式本质是函数式接口的实现类实例,编写 Lambda 表达式,就是在编写函数式接口唯一抽象方法的是实现。既然如此, 和其他类型的变量一样,Lambda 表达式通常出现在块( blocks )内。
块指的是0 条或更多的 Java 语句,这些语句使用花括号“ {} ”围起来。块能出现在很多地方并且块中还能有块。
package cn.lambda.test; public class AccessVariable { public static void main(String[] args) { // 大块开始 boolean condition = true; if (condition) { // 小块 1 开始 System.out.println("条件为 true 。"); } // 小块 1 结束 else { // 小块 2 开始 System.out.println("条件为 false 。"); } // 小块 2 结束 } // 大块结束 }
Lambda 表达式若是出现在块内,这就涉及到访问块内、块外变量的权限问题。和匿名类( anonymous classes )和局部类( local classes )一样, Lambda 表达式也能访问块内、块外变量。在本节中,我们以局部类和 Lambda 表达式做比较说明,讲解 Lambda 表达式是如何访问这些变量的。一开始,我们需要回忆局部类是如何访问块内和块外变量的。
局部类区别于独立类,独立类单独定义在 Java 文件中( .java 文件 ),类名和 Java 文件名保持一致,编译后会有独立的字节码文件( .class 文件 )。而局部类不能定义在独立的 Java 文件中,它在独立类的内部定义,最常见的是定义在独立类的方法的方法体中,即方法体所在的块。
package cn.lambda.test; public class LocalClassExample { private static String regularExpression = "[^0-9]"; // 正则表达式,非数字 // 格式化号码 public static void validatePhoneNumber(final String phoneNumber1, final String phoneNumber2) { final int numberLength = 10; // 有效号码位数 // int numberLength = 10; class PhoneNumber { // 经格式化的号码(去掉号码中非数字的部分) private String formattedPhoneNumber = null; // 格式化号码 PhoneNumber(String phoneNumber) { // 修改块内局部变量,错误: numberLength = 7; // 修改块外类的成员变量,正确: regularExpression = "[^a-z]"; String currentNumber = phoneNumber.replaceAll(regularExpression, ""); if (currentNumber.length() == numberLength) formattedPhoneNumber = currentNumber; else formattedPhoneNumber = null; } } } }
我们定义了一个独立类 LocalClassExample ,它有一个 static String 类型的成员变量 regularExpression ,是个正则表达式,代表非数字。有个静态方法 validatePhoneNumber ,两个参数 String phoneNumber1 , String phoneNumber2 ,该方法用来格式化号码。在方法体中定义了一个局部类 PhoneNumber 。方法体的多条语句组成了块,可见,该局部类 PhoneNumber 定义在方法体所在的块中。在这个方法体的块中,有两部分内容,一部分是 final int 类型的变量 numberLength ,代表有效号码的位数,另一部分内容就是局部类 PhoneNumber 。因为变量 numberLength 和局部类 PhoneNumber 处于同一个块,相对于局部类 PhoneNumber 而言,变量 numberLength 称之为局部变量( local variables ),类 LocalClassExample 的成员变量 regularExpression 称之为块外类成员变量,方法 validatePhoneNumber 的两个参数 String phoneNumber1 , String phoneNumber2 称之为块外方法参数变量。请你分清楚这三种变量,局部类 PhoneNumber 变量访问的权限就是针对这三种变量的,它们分别是局部变量、块外类成员变量、块外方法参数变量。
局部类有一个 String formattedPhoneNumber 的成员变量,代表经过格式化的号码,把原号码的非数字部分去掉就成为了格式化号码。有一个构造函数,构造函数的功能就是对原号码进行格式化。在局部类的构造函数中,我们关注这一条语句,“ phoneNumber.replaceAll(regularExpression, ""); ”,这条语句把原号码中的非数字字符替换掉,用到的变量 regularExpression 是块外类成员变量,这说明局部类可以访问块外类成员变量。并且这种访问权限非常大,不但可以读取,还可以修改,局部类修改块外类的成员变量是被允许的。
在局部类的构造函数中,我们关注这一条表达式,“ currentNumber.length() == numberLength ”,原号码替换掉非数字的字符后,判断号码位数是否和有效的号码位数相等。用到的变量 numberLength 是局部变量,这说明局部类可以访问局部变量。但是,访问的权限不是很大。局部类访问的局部变量必须是 final ,比如“ final int numberLength = 10; ”。但这不代表局部变量一旦声明为非 final ,编译器就会报错。比如,“ int numberLength = 10; ”,在局部变量 numberLength 的生命周期内(从它在方法 validatePhoneNumber 声明的地方开始,一直到该方法结束),不去对 numberLength 进行赋值,编译器是不会报错的。声明一个非 final 的局部变量并初始化后,在其生命周期内,不再对其进行赋值,编译器就认为它是 final 的,声明时有无加上关键字 final ,其效果一样。但是,若是在局部变量 numberLength 的生命周期内,对它进行赋值,局部类访问局部变量 numberLength ,编译器就会报错。比如,局部变量 numberLength 被声明为非 final ,在局部类的构造函数对其赋值,比如,“ numberLength = 7; ”,编译器会报出错误“ Local variable numberLength defined in an enclosing scope must be final or effectively final ”,翻译成中文即是“局部变量 numberLength ,定义在把它围住的范围内(块内),必须是 final 或 有效 final ”。虽然可以不把局部变量声明为 final ,但我们还是建议声明为 final,一是防止局部变量初始化后,我们对它进行赋值(一旦赋值,就会编译错误),二是一目了然,起到重要的提示作用。
在编译器的报错信息中,我们注意到了有效 final 这个词, final 和 有效 final 有何区别?对于一个基本类型的变量,一旦被声明为 final 且进行初始化,接下来有语句对它进行赋值,编译器就会报错“ The final local variable a cannot be assigned. It must be blank and not using a compound assignment ”,译成中文大意是“ final 局部变量不能被赋值 ”,这样的 final 称之为有效 final 。但是,一个对象的引用被声明为 final 且指向一个对象,仅仅代表该对象引用不能指向新的对象,但是,该对象引用指向的对象的属性值却是可以被修改的,这称之为非有效 final 。这句话相当绕口,我们再来看看局部变量“ final int numberLength = 10; ”,它属于基础类型,所以该 final 是有效 final 。但是,我们把 int 类型修改为 NumberLengthClass 类型,“ final NumberLengthClass numberLength = new NumberLengthClass(10); ”,该 final 就属于非有效 final 了, 类 NumberLengthClass 定义如下:
package cn.lambda.test; public class NumberLengthClass { private int numberLength; // 有效号码位数 public NumberLengthClass(int numberLength) { super(); this.numberLength = numberLength; } public int getNumberLength() { return numberLength; } public void setNumberLength(int numberLength) { this.numberLength = numberLength; } }
我们在局部变量 NumberLengthClass numberLength 的生命周期内,对它进行赋值(对象引用指向新的对象),比如,在局部类对它进行赋值,“ numberLength = new NumberLengthClass(9); ”,编译报错“ The final local variable numberLength cannot be assigned, since it is defined in an enclosing type ”,译成中文“ final 局部变量 numberLength 不能被赋值,因为它被定义在把它围住的范围内(块内)”。但是,在局部变量 NumberLengthClass numberLength 的生命周期内,修改它指向的对象的属性值,编译却是通过的。比如,在局部类修改它指向的对象的属性值,“ numberLength.setNumberLength(5); ”,编译不会报错。正是因为如此,“ final NumberLengthClass numberLength = new NumberLengthClass(10); ”,称之为非有效 final 。
Java 语法规定,局部类能访问局部变量,但局部变量必须是 final ,所以建议程序员把局部变量声明为 final 。但是,由于非有效 final 的存在,存在修改局部变量而编译器却不报错的情况。但请你务必注意,即便编译器不报错,即便有非有效 final 的存在,你依旧不要尝试去修改局部变量的值,否则,你将可能尝到难以发现原因的苦头。至于其中的原理,我们就不再此处展开,因为这已经偏离本节的主题。
事实上,局部类还可以访问块外方法的参数变量。但是,和访问局部变量一样,块外方法的参数变量必须是 final 的。我们可以在局部类 PhoneNumber 定义一个方法 printOriginalNumbers ,用来访问块外方法的参数变量,代表获取原始号码。
package cn.lambda.test; public class LocalClassExampleTest { // 格式化号码 public static void validatePhoneNumber(final String phoneNumber1, final String phoneNumber2) { class PhoneNumber { public void printOriginalNumbers() { // 修改块外方法参数变量,错误: phoneNumber1 = "123-456-7890"; System.out.println("原始号码,第一个是 " + phoneNumber1 + " ,第二个是 " + phoneNumber2); } } } }
局部类访问局部变量和块外方法参数变量,有句专业的表达,叫做捕获变量和参数( it captures that variable or parameter )。此情景中,局部变量称之为被捕获变量( captured variable ),块外方法参数变量称之为被捕获参数( captured parameter )。
最后,把这个例子的完整代码附上。
package cn.lambda.test; public class LocalClassExample { private static String regularExpression = "[^0-9]"; // 正则表达式,非数字 // 格式化号码 public static void validatePhoneNumber(final String phoneNumber1, final String phoneNumber2) { final int numberLength = 10; // 有效号码位数 // int numberLength = 10; class PhoneNumber { // 经格式化的号码(去掉号码中非数字的部分) private String formattedPhoneNumber = null; // 格式化号码 PhoneNumber(String phoneNumber) { // 修改块内局部变量,错误: numberLength = 7; // 修改块外类的成员变量,正确: regularExpression = "[^a-z]"; String currentNumber = phoneNumber.replaceAll(regularExpression, ""); if (currentNumber.length() == numberLength) formattedPhoneNumber = currentNumber; else formattedPhoneNumber = null; } // 获取格式化的号码 public String getNumber() { return formattedPhoneNumber; } // 获取原始号码 public void printOriginalNumbers() { // 修改块外方法参数,错误: phoneNumber1 = "123-456-7890"; System.out.println("原始号码,第一个是 " + phoneNumber1 + " ,第二个是 " + phoneNumber2); } } PhoneNumber myNumber1 = new PhoneNumber(phoneNumber1); PhoneNumber myNumber2 = new PhoneNumber(phoneNumber2); myNumber1.printOriginalNumbers(); if (myNumber1.getNumber() == null) System.out.println("第一个是无效号码"); else System.out.println("第一个是格式化号码是 " + myNumber1.getNumber()); if (myNumber2.getNumber() == null) System.out.println("第二个是无效号码"); else System.out.println("第二个是格式化号码是 " + myNumber2.getNumber()); } public static void main(String... args) { validatePhoneNumber("123-456-7890", "456-7890"); } }
在局部类定义了一些变量,这些变量可以是局部类成员变量,也可以是局部类方法的参数变量。若是这些变量和块外的变量重名,这些局部类变量便会遮蔽( shadow )块外的变量。
package cn.lambda.test; public class OuterClass { private int x = 96; // 1.块外类成员变量 x,值等于 96 // 2.块外方法参数变量 x,值等于 97 public void outerClassMethod(int x) { // 局部变量不能和块外方法参数变量重名 int x = 100; class LocalClass { // 3.局部类成员变量 x,值等于 98 private int x = 98; // 4.局部类方法参数变量 x ,值等于 99 public void localClassMethod(int x) { System.out.println(x); // 获得第 4 个 x 的值 System.out.println(this.x); // 获得第 3 个 x 的值 System.out.println(OuterClass.this.x); // 获得第 1 个 x 的值 // 第 2 个 x 的值无法直接获取。 } } LocalClass localClass = new LocalClass(); localClass.localClassMethod(99); } public static void main(String... args) { OuterClass outerClassInstance = new OuterClass(); outerClassInstance.outerClassMethod(97); } }
我们定义了一个独立的类 OuterClass ,独立类内若是定义了局部类,独立类也称之为外部类,所以我们给这个独立类取名为 OuterClass 。它有一个成员变量 x ,相对于局部类 LocalClass而言,此 x 称之为块外类成员变量 x ,我们把它标记为第 1 个 x ,值是 96 。独立类 OuterClass 有个方法 outerClassMethod ,方法参数变量名字也叫做 x ,相对于局部类 LocalClass 而言,此 x 称之为块外方法参数变量 x ,我们把它标记为第 2 个 x 。主函数调用此方法时,传入的值是 97 ,所以第 2 个 x 的值是 97 。方法 outerClassMethod 的方法体所在块定义了局部类 LocalClass ,局部类有个成员变量,名字也叫做 x ,此 x 称之为局部类成员变量 x ,我们把它标记为第 3 个 x ,值等于 98 。局部类 LocalClass 有个方法 localClassMethod ,方法参数变量名字也叫做 x ,此 x 称之为局部类方法参数变量 x ,我们把它标记为第 4 个 x 。调用该方法时,传入的值是 99 ,所以该 x 的值等于 99 。
现在我们来关注局部类 LocalClass 的方法 localClassMethod ,这个方法有三行语句。第一行语句,“ System.out.println(x); ”,此 x 是指的是第 4 个 x ,即局部类的方法参数变量 x 。第二行语句,“ System.out.println(this.x); ”,此 x 指的是第 3 个 x ,即局部类的成员变量 x 。主函数创建了外部类 OuterClass 的实例 outerClassInstance ,接着使用该实例调用它的方法 outerClassMethod ,在该方法中,定义了局部类 LocalClass ,并创建了局部类的实例 localClass ,并使用该实例调动它的方法 localClassMethod 。从调用的顺序来看,程序先创建了外部类 OuterClass 的实例 outerClassInstance ,接着才创建局部类 LocalClass 的实例 localClass 。因此,局部类 LocalClass 的方法 localClassMethod 第二行语句,“ System.out.println(this.x); ”, this.x 即是当前对象的 x ,定义为局部类的成员变量的 x 。该方法的第三行语句, “ System.out.println(OuterClass.this.x); ” ,此 x 指的是第 1 个 x ,OuterClass.this.x 即是外部类(块外类)当前对象的 x ,定义为块外类成员变量 x 。
需要特别注意的是,第 2 个 x ,即块外方法参数变量 x ,若是坚持不改名字或借助临时变量等手段,局部类 LocalClass 的方法 localClassMethod 再也无法直接访问。另外,局部变量不能取名为 x ,因为 Java 的一条基本语法是,“方法体所定义的变量不能和方法的参数变量重名。”当然,在实际的开发工作中,无论是块内变量还是块外变量,我们应当尽量避免重名,否则,特别容易引起混淆。若是有重名情况发生时,变量的取值就会遵循遮蔽的语法。
关于局部类访问块内和块外变量的,我们总结如下:
1.可以访问局部变量,但是局部变量必须是 final 。
2.可以访问块外方法参数变量,但是块外方法参数变量必须是 final 。
3.可以访问块外类成员变量,权限很大,能读能写。
4.局部类的成员变量或是方法参数变量,会遮蔽块外类(外部类)的同名变量。
关于 lambda 表达式,上述第 1、2、3 点特征,它也具备。但是,它不具备第 4 点特征。即lambda 表达式的方法参数变量,不会遮蔽块外类(把它围住的那个类)的同名变量。虽然 lambda 表达式是从匿名类演化而来, lambda 表达式的定义是匿名类的定义的简化版。但是,lambda 表达式和匿名类还是有区别的。 请注意这句话, Lambda 表达式被词法定界了( Lambda expressions are lexically scoped. )。词法定界不是很好理解,表达式若是被词法定界,意味着它不会继承父接口的任何成员变量,没有遮蔽功能。我们知道, lambda 表达式是函数式接口的实现类实例,所以,定义 lambda 表达式,实际上要经历两件事情。第一件事情是定义函数式接口实现类,第二件事情是创建该实现类实例。 this 称之为当前对象,但是, 定义 lambda 表达式时,也就是定义函数式接口实现类时, lambda 表达式代表的实现类本身没有 this 对象,此时若是使用 this 对象,指的是把 lambda 表达式围住的类的当前对象,而不是 lambda 表达式代表的实现类的当前对象。 lambda 表达式被词法定界的表现总结如下:
1. 不会继承父接口的任何成员变量。
2. 没有遮蔽功能。
3. lambda 表达式代表的实现类没有 this 对象,this 对象指的是把 lambda 表达式围住的类的当前对象。
下面我们结合匿名类,举例说明 lambda 表达式被词法定界的表现。
package cn.lambda.test; @FunctionalInterface public interface Animal { // 动物共同特征,能呼吸 boolean breath = true; // 获取动物特征 void getFeature(); }
定义一个函数式接口 Animal ,该接口代表动物,有一个 boolean 类型的属性是 breath ,代表动物都能呼吸。接口中的属性的默认修饰符是 public static final 。该接口有一个方法 getFeature ,代表获取动物的特征。一开始,我们使用匿名类实现该函数式接口。该匿名类代表鸟类,鸟类从动物继承了能呼吸的特征。另外,它有自己的独特特征,即能飞行,有飞行高度的属性。
package cn.lambda.test; public class TestAnimal { public static void main(String[] args) { Animal bird = new Animal() { private int flighAltitude = 500; // 飞行高度,鸟类独特特征 @Override public void getFeature() { System.out.println("动物共同特征,能呼吸: " + breath); System.out.println("鸟类飞行高度: " + this.flighAltitude); } }; bird.getFeature(); } }
在匿名类的定义中,你会发现匿名实现类能够继承函数式接口的成员变量 breath ,因此,语句 [ System.out.println("动物共同特征,能呼吸: " + breath); ] 可以正常输出 true 。但若是使用 lambda 表达式,你会惊讶的发现,该语句会报错。关注这行语句, [ System.out.println("鸟类飞行高度: " + this.flighAltitude); ] ,输出结果是 500 。请你注意, flighAltitude 是匿名实现类的成员变量, this 代表匿名实现类的当前对象,而不是把匿名类围住的类的当前对象,即不是 TestAnimal 类的当前对象。若是使用 lambda 表达式, 此处的 this 成了 TestAnimal 类的当前对象。下面,我们使用 lambda 表达式实现该函数式接口。
package cn.lambda.test; public class TestAnimalWithLambda { private boolean testClass = true; public void bird() { Animal bird = () -> { // 错误: lambda 表达式不会继承父接口成员变量 // System.out.println("动物共同特征,能呼吸: " + breath); System.out.println("鸟类飞行高度: " + this.testClass); }; bird.getFeature(); } public static void main(String[] args) { new TestAnimalWithLambda().bird(); } }
在 lambda 表达式的定义中,语句 [ System.out.println("动物共同特征,能呼吸: " + breath); ] ,编译报错 “ breath cannot be resolved to a variable ”,译成中文“ breath 无法解析成变量”,这是因为 lambda 表达式不会继承父接口的任何成员变量。关注这一行代码 [ System.out.println("鸟类飞行高度: " + this.testClass); ] ,this 不是 lambda 表达式代表的实现类的当前对象,而把 lambda 表达式围住的类的当前对象,即是 TestAnimalWithLambda 类的当前对象, testClass 是 TestAnimalWithLambda 类的成员变量。
前面我们讲解局部类变量的遮蔽功能时,定义过一个类 OuterClass ,现在对它进行改造,在局部类的方法 localClassMethod 使用 lambda 表达式。
package cn.lambda.test; import java.util.function.Consumer; public class LambdaScope { private int x = 96; // 1.块外独立类成员变量 x,值等于 96 // 2.块外独立类方法参数变量 x,值等于 97 public void outerClassMethod(int x) { class LocalClass { // 3.块外局部类成员变量 x,值等于 98 private int x = 98; // 4.块外局部类方法参数变量 x ,值等于 99 public void localClassMethod(int x) { // int y = 0; // 此处若有上述语句,Lambda 表达式参数变量名字不能是 y Consumer<Integer> consumer = p -> { System.out.println(x); // 获得第 4 个 x 的值 System.out.println(this.x); // 获得第 3 个 x 的值 System.out.println(LambdaScope.this.x); //获得第 1 个 x 的值 // 第二个 x 的值无法直接获取。 }; consumer.accept(99); } } LocalClass localClass = new LocalClass(); localClass.localClassMethod(99); } public static void main(String... args) { LambdaScope outerClassInstance = new LambdaScope(); outerClassInstance.outerClassMethod(97); } }
以上代码注释是站在 lambda 表达式的角度上进行的,它所在块是局部类的 LocalClass 的方法 localClassMethod 的方法体。 Lambda 表达式的参数变量名字是 p ,若是修改为 x ,编译报错,“ Lambda expression's parameter x cannot redeclare another local variable defined in an enclosing scope. ”,译成中文“把 lambda 表达式围住的范围,已经定了局部变量 x , lambda 表达式的参数变量不能再次声明为 x.”。把 lambda 表达式围住的范围,指的是局部类 LocalClass ,局部类的方法 localClassMethod 参数变量已经取名为 x ,因此 lambda 表达式的参数变量名字就不能取名为 x 了。之所以 lambda 表达式不能和局部变量或块外方法参数变量重名,是因为 lambda 表达式没有遮蔽功能。
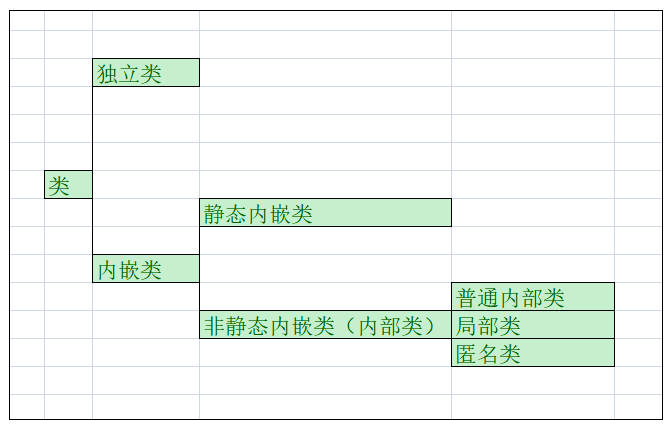
上面我们提到而来匿名类,局部类,独立类等类,你可能有点混淆。局部 Java 的语法规则,类分为这么几种。粗粒度地分为独立类( independent classes ),内嵌类( nested classes )。内嵌类分为静态内嵌类( static nested classes )和非静态内嵌类( non-static nested classes ),非静态内嵌类也称之为内部类( inner classes )。内部类有普通内部类和特别的内部类,特别内部类有两个,分别是局部类( local classes )和匿名类( anonymous classes )。
6. 目标类型
我们来看一看前面写了多次的 lambda 表达式。
p -> p.getGender() == Person.Sex.MALE && p.getAge() >= 18 && p.getAge() <= 25
该 lambda 表达式的含义是挑选符合美国义务兵役制度的会员,符合这一制度的具体条件是男性且年龄在 18 至 25 岁之间。我们暂且把这个 lambda 表达式称之为挑选会员 lambda 表达式。若是仅仅只看这个表达式,我们能知道的信息非常有限。我们仅能知道有个函数式接口,它的抽象方法接受一个参数,返回一个 boolean 类型结果。至于是哪一个函数式接口,需要观察 lambda 表达式所处的环境( context or situation )。在前面的例子中,我们定义这样两个方法:
public static void printPersons(List<Person> roster, CheckPerson tester); public static void printPersonsWithPredicate(List<Person> roster, Predicate<Person> tester);
接着,我们使用挑选会员 lambda 表达式作为这两个方法的参数,对它们进行调用:
List<Person> roster = ... printPersons(roster, (Person p) -> p.getGender() == Person.Sex.MALE && p.getAge() >= 18 && p.getAge() <= 25); List<Person> roster = ... printPersonsWithPredicate(roster, p -> p.getGender() == Person.Sex.MALE && p.getAge() >= 18 && p.getAge() <= 25);
方法 printPersons 的第二个参数是函数式接口 CheckPerson 类型,它的抽象方法接受一个参数,返回一个 boolean 类型的结果。挑选会员 lambda 表达式刚好符合这一特性,所以它可以作为方法 printPersons 的第二个参数,该 lambda 表达式的类型就是CheckPerson 类型。
方法 printPersonsWithPredicate 的第二参数是函数式接口 Predicate 类型,它的抽象方法同样接受一个参数,返回一个 boolean 类型的结果。挑选会员 lambda 表达式刚好符合这一特性,所以它可以作为方法 printPersonsWithPredicate 的第二个参数, 该 lambda 表达式的类型就是 Predicate 类型。
可见,在不同的环境(本例是作为方法的实参), lambda 表达式可以属于不同函数接口的实现类的实例,会有不同的类型。只要 lambda 表达式符合函数式接口的抽象方法的定义,它就可以成为该函数式接口的实现类的实例。
每个方法都有自己期望的参数类型,比如方法 printPersons 的第二个参数期望的类型是函数式接口 CheckPerson 类型,方法 printPersonsWithPredicate 的第二参数期望的类型是函数式接口 Predicate 类型,方法期望的参数类型称之为目标类型( target type )。编译器在 lambda 表达式所处的环境里(比如, lambda 作为方法的实参),根据目标类型,确认 lambda 表达式的类型。 Lambda 表达式所处的环境,不单单是作为方法的实参,还可以是以下这些环境:
1.变量声明;
2.赋值;
3.返回值;
4.数组初始化;
5.方法实参;
6.Lambda 表达式方法体;
7.条件表达式( condition ? result1 : result2 );
8.强制转换表达式。
6.1. 目标类型和方法参数
当 lambda 所处的环境是作为方法的实参,若是不同的方法取不同的名字,目标类型很好确认,就像是方法printPersons 的第二参数和方法 printPersonsWithPredicate 的第二个参数,前者目标类型是CheckPerson ,后者是 Predicate。但是,若是在一个类中,存在重载的两个方法,目标类型该如何确定呢?JDK 有这样两个函数式接口:
@FunctionalInterface public interface Runnable { public abstract void run(); } @FunctionalInterface public interface Callable<V> { V call() throws Exception; }
我们自定义一个类 TargetType ,该类有两个重载的方法 invoke 。
package cn.lambda.test; import java.util.concurrent.Callable; public class TargetType { public static void invoke(Runnable r) { r.run(); } public static <T> T invoke(Callable<T> c) throws Exception { return c.call(); } public static void main(String[] args) throws Exception { String s = invoke(() -> "done"); } }
主函数调用方法 invoke ,那么,哪一个invoke 方法会被调用?若是没有返回值的 invoke方法被调用,则目标类型和 lambda 表达式类型是函数式接口 Runnable 类型,若是有返回值的 invoke 方法被调用,则目标类型和 lambda 表达式类型是函数式接口 Callable 类型。答案是有返回值的那个 invoke 方法会被调用。定义在主函数的 lambda 表达式没有方法参数,但有返回值。有返回值的 invoke 方法的参数类型是 Callable 类型,该接口的抽象方法 call 正好是没有参数,但有返回值,和定义在主函数的 lambda 表达式相匹配。没有返回值的 invoke 方法的参数类型是 Runnable 类型,该接口的抽象方法 run 既无参数也无返回值,和定义在主函数的 lambdad 表达式不匹配,所以主函数调用的 invoke 是有返回值的 invoke 方法, 目标类型和 lambda 表达式的类型是函数式接口 Callable 类型。
7. 序列化
Lambda 表达式只要符合以下的条件,它是可以序列化的:
1.它的目标类型是可序列化的;
2.它所捕获的变量是可序列化的。
但是,和内部类(包括普通内部类、局部类和匿名类)一样,序列化 lambda 表达式是非常不推荐的。至于其中的原因,大家可以自行去了解内部类的序列化问题,此处不再展开,因为它偏离了本节的主题。
8. 方法引用
8.1. 访问静态方法
现在我们知道,若接口是函数式接口,它的实现类实例可以使用 lambda 表达式,比起匿名类实例, lambda 表达式更加的简洁和可读性更好。然而, Java 设计者们并不满足于此,他们觉得,在某些情况, lambda 表达式可以被替代,有新的表达方式可以让代码变得更加简洁和可读性更好。有些时候, lambda 表达式的方法体仅仅是使用了一条语句,调用了一个方法就结束了。在这样的场景下,我们可以使用方法引用( method references )代替 lambda 表达式,让你代码变得更少。
在前面,我们定义了会员实体类,所有应用会员存储在集合 List<Person> roster 对象中。现在,我们假设会员存储在数组中,并且根据他们的生日进行正向排序,即生日从早到晚,从小到大。在 Java 领域,说一个时间早,指的是该时间距离 1970 年 1 月 1 日 0 点 0 分 0 秒比较近。相反地,说一个时间晚,指的是该时间距离 1970 年 1 月 1 日 0 点 0 分 0 秒比较远。比如,2016 年和 2017 年相比, 2016 比较早,比较小, 2017 比较晚,比较大。可见,若是按照时间进行正向排序,时间早,时间小,排在前面,时间晚,时间大,排在后面。若是按照会员生日进行正向排序,等同按照会员的年龄从小到大进行排序。首先,我么需要把 List<T> 类型的 roster 转化为数组类型的 rosterAsArray 。
Person[] rosterAsArray = roster.toArray(new Person[roster.size()]);
<T> T[] toArray(T[] a) :该方法返回一个数组,数组元素包含了 List<T> 中的所有元素,数组中的元素顺序和 List<T> 中的元素顺序保持一致。该方法声明了类型参数(泛型参数) T ,代表数组元素的类型。请注意,返回值类型 T[] 和参数类型 T[] 是同一种类型,这就说明,参数指定的类型等同了返回值的类型。在本例,我们的参数指定为 new Person[roster.size()] ,它的类型是一个元素类型为 Person 的数组,这就代表返回值类型也是元素类型为 Person 的数组。该方法的参数是 T[] a ,若是 a 的大小能够装得下 List<T> 中的所有元素,该方法的返回值就是 a 。否则,该方法会创建一个新的数组,其类型和 a 保持一致,大小和 List<T> 元素个数保持一致,返回值就是新创建的数组。在本例,该方法的参数 new Person[roster.size()] ,它的大小刚好是 List<T> 元素的个数,能够装得下 List<T> 中的所有元素,所以,该方法返回值就是数组 new Person[roster.size()] ,无需创建新的数组。该方法的参数是 T[] a ,若是 a 的大小超过 List<T> 中元素的元素个数,剩余的空间会被设置成 null 。
该方法是基于数组的对象和基于 Collection 的对象( List 是 Collection 的子类)的桥梁,提供了把基于 Collection 的对象转化为基于数组的对象的通道。并且,该方法可以通过指定参数的类型,精确地控制返回值的类型,而不是简单地返回一个元素类型是 Object 类型的数组。参数类型是数组 T[] ,创建数组时,通过指定数组的大小( List<T> 的元素个数有多少,就指定数组的大小有多大),可以有效的避免空间的浪费。
想要对 Person[] rosterAsArray 中的元素根据他们的生日进行正向排序,我们需要定义一个生日比较器( Comparator )。
package cn.lambda.test; import java.util.Comparator; class PersonAgeComparator implements Comparator<Person> { public int compare(Person a, Person b) { return a.getBirthday().compareTo(b.getBirthday()); } }
会员的生日字段的类型是 LocalDate ,该类有个方法 public int compareTo(ChronoLocalDate other) , LocalDate 是 ChronoLocalDate 的子类。该方法比较两个日期,调用该方法的当前对象代表一个日期(当前日期),该方法参数代表另一个日期。既然是计较,就涉及到排序,该方法的排序是正向排序,即时间从小到大,或者说从早到晚。该方法返回值是 int ,若当前日期小于另一个日期,返回负数,大于另一个日期,返回正数,相等,返回 0 。
Comparator<T> 是一个函数式接口,类型参数 T 代表待比较对象的类型。我们自定义的比较器 PersonAgeComparator 需要实现该接口,该接口的唯一一个抽象方法, “ int compare(T o1, T o2); ”,该方法比较参数指定的两个对象。若第一个对象 o1 大于或等于或小于第二个对象 o2 ,该方法分别返回正整数、 0 、负整数。这样的返回值规则和类 LocalDate 的方法 compareTo 完全一致,所以,在编写类 PersonAgeComparator 的方法 compare 的具体逻辑中,我们调用了类 LocalDate 的方法 compareTo ,实现按照会员的生日从小到大的排序的逻辑。
有了生日比较器,我们就可以对数组Person[] rosterAsArray 进行排序了。
Arrays.sort(rosterAsArray, new PersonAgeComparator());
public static <T> void sort(T[] a, Comparator<? super T> c) :该方法根据指定的比较器 c,对数组 a 进行排序。对于本例而言,就是根据生日比较器(年龄从小到大),对会员进行排序。当然,我们需要保证数组中的元素都是都是可以彼此进行比较的。比如,本例中的数组元素是 Person 类型的会员,具体的逻辑是对会员的生日进行比较,所以数组不能出现生日 birthday 是 null 的会员。其次,该方法能保证每次的排序结果都是一样的。这句话是针对排序是相等的元素而言的。比如数组有两个会员 p1 、 p2 ,他们的生日都是同一天,那么排序时,若是 p1 被排在第二位, p2 被排在第三位,以后进行排序,都是这样的顺序,不会有时候成了p1 被排在第三位, p2 被排在第二位。该方法的这一特征有句专业的表达,“ This sort is guaranteed to be stable.” ,译成中文“排序能够保证是稳定的”。
为了能够对数组 Person[] rosterAsArray进行排序,根据数组元素会员的生日从早到晚,年龄从小到大进行排序,我们定义了独立类(比较器) PersonAgeComparator 去实现接口 Comparator<T> ,接着创建独立类的实例,作为方法 sort 的第二个参数。请注意 sort 方法的第二个参数类型 Comparator<T> ,它是一个函数式接口,所以我们完全可以使用 lambda 表达式来代替上述的步骤。
Arrays.sort(rosterAsArray, (a, b) -> a.getBirthday().compareTo(b.getBirthday()));
Lambda 表达式的方法体有一条语句,我们把这条语句写在会员实体类 Person 的静态方法 compareByAge 中,该方法定义如下:
public static int compareByAge(Person a, Person b) { return a.birthday.compareTo(b.birthday); }
实体类 Person 经改造之后,多了一个方法 compareAge ,现在是这样子的:
package cn.lambda.test; import java.time.LocalDate; import java.util.List; public class Person { // 性别枚举 public enum Sex { MALE, FEMALE } private String name; // 姓名 private LocalDate birthday; // 生日 private Sex gender; // 性别 private String emailAddress; // 邮件地址 private int age; // 年龄 public void printPerson() { // 打印会员的个人信息 } public static int compareByAge(Person a, Person b) { return a.birthday.compareTo(b.birthday); } // getter setter methods }
这样一来, lambda 表达式可以写成这样:
Arrays.sort(rosterAsArray, (a, b) -> Person.compareByAge(a, b));
你仔细观察这个 lambda 表达式,发现它的方法体就是调用了一个方法,因此,我们可以使用方法引用代替 lambda 表达式。
Arrays.sort(rosterAsArray, Person::compareByAge);
相信你立马发现,方法引用让代码更少了,可读性更好了。方法引用的语法简单极了,在本例中,它的语法形式是“类名::静态方法名”,若是把它转为 lambda 表达式,它表达两层含义:
1.lambda 表达式的方法参数就是 compareAge 的方法参数,即“ (Person a, Person b) ” 。
2.lambda 表达式的方法体就是调用了方法 compareAge ,即 “ Person.compareByAge(a, b) ”。
方法引用有四种类型,这是其中一种,称之为访问静态方法( compareAge 是静态方法),语法形式是“ ContainingClass::staticMethodName ”,即“类名::静态方法”。
8.2. 访问特定对象的实例方法
实体类 Person 的方法 compareAge 若是非静态的方法,而是特定对象的实例方法,我们该如何对数组 Person[] rosterAsArray进行排序呢?
Person personInLambda = new Person(); Arrays.sort(rosterAsArray, (a, b) -> { return personInLambda.compareByAge(a, b); });
因为现在,方法 compareByAge 是实例方法,必须使用 Person 类型的实例来调用它,所以我们需要创建 Person 类型的实例 personInLambda 。现在的 lambda 表达式,它的方法体依旧只是调用了一个方法,因此,我们可以使用方法引用代替 lambda 表达式。
Person personInLambda = new Person(); Arrays.sort(rosterAsArray, personInLambda::compareByAge);
这种方法引用称之为访问特定对象的实例方法,语法形式是“ containingObject::instanceMethodName ”,即“对象::实例方法”。若是把它转为 lambda 表达式,它表达两层含义:
1.lambda 表达式的方法参数就是 compareAge 的方法参数,即“ (Person a, Person b) ” 。
2.lambda 表达式的方法体就是调用了方法 compareAge ,即 “ personInLambda.compareByAge(a, b) ”
8.3. 访问特定类型的随机对象的实例方法
String 类有这样一个非常实用的实例方法 “ public int compareToIgnoreCase(String str) ”,以调用该方法的当前对象作为作为一个字符串(下文称之为 this 字符串),方法参数作为另一个字符串(下文称之为 another 字符串),忽略这两个字符串的大小写,按照字典序,对它们进行比较。何为字典序?每个字符串( strings )都是由 0 至多个字符( character )组成的,每个字符都有 Unicode 值,多个字符组成了字符序列( character sequence )。 this 字符串是一个字符序列, another 字符串也是字符序列,这两个字符序列按照字典序进行比较。
如果两个字符串是不同的,从某个索引开始,字符是不一样的,这个索引称之为有效索引( valid index )。比如说,字符串“ lambdaexpression ”和“ lambdatest ”,这两个字符串是不同的,索引 0 到索引5 ,字符相同,第 6 个索引,字符串“ lambda ”是字符 “ e ”,字符串“ lambdatest ”是字符“ t ”,字符不一样,所以索引 6 称之为有效索引。当然还有其他的索引,这两个字符串的字符也是不同的,此处我们取这些索引中的最小值,使用 K 标记该索引。此时,方法 compareToIgnoreCase 的返回值是:
this.charAt(k) - anotherString.charAt(k)
this 代表 this 字符串,anotherString 代表 another 字符串,方法“ public char charAt(int index) ”返回指定索引 index 的字符。两个字符进行求差,实际是两个字符的 Unicode 值进行求差,字符会自动转化为对应的 Unicode 值,再进行运算。可见,如果this 字符串位于索引 K 的字符的 Unicode 值比较小,方法 compareToIgnoreCase 的返回值是负整数,表示 this 字符串比较小,排在 another 字符串的前面。如果this 字符串位于索引 K 的字符的 Unicode 值比较大,方法 compareToIgnoreCase 的返回值是正整数,表示 this 字符串比较大,排在 another 字符串的后面。如果this 字符串位于索引 K 的字符的 Unicode 值和 another 字符串位于索引 K 的字符的 Unicode 值相等,方法 compareToIgnoreCase 的返回值是 0 ,表示 this 字符串和 another 字符串相等。
有时候,两个字符串是不同的,但是不存在索引,它们字符是不同的。比如字符串“ lambda ”和“ lambdaexpression ”,显然,这两个字符串是不同的,长度不同,但是直到第一个字符串的索引结束,也不存在和第二个字符串不同的字符。此时,方法 compareToIgnoreCase 的返回值是:
this.length()-anotherString.length()
可见,在这场场景下,方法 compareToIgnoreCase 的返回值是由两个字符串的长度计算的,不再是由某个索引的字符的 Unicode 值计算的。当然,计算结果依然是负整数、正整数、 0 ,依旧代表 this 字符串“比较小,排在 another 字符串的前面”、“比较大,排在 another 字符串的后面”、“和 another 字符串相等”。
需要注意的是,方法 compareToIgnoreCase 计算两个字符串的某个索引的字符的 Unicode 值时,是忽略大小的,两个字符串会在一开始就被格式化成全部小写。比如 this 字符串位于索引 K 的字符是“ a ”,another 字符串位于索引 K 的字符是“ A ”,方法 compareToIgnoreCase 计算时,这两个字符的 Unicode 值相等。如果你想让两个字符串的字符大小写敏感,使用 String 类的另一个方法“ public int compareTo(String anotherString) ”。
String[] stringArray = { "Barbara", "James", "Mary", "John", "Patricia", "Robert", "Michael", "Linda" }; Arrays.sort(stringArray, (a, b) -> a.compareToIgnoreCase(b));
我们定义了元素类型是 String 的数组 stringArray ,对数组中的字符串进行字典序排序,使用的是 String 类的实例方法 compareToIgnoreCase 。前面已经提过,类 Arrays 方法 sort 的第二个参数类型是函数式接口 Comparator<? super T> ,该接口的抽象方法 compare 的返回值规则和 String 类的方法 compareToIgnoreCase 完全一致。抽象方法 compare 的返回值规则是,若第一个对象 o1 大于或等于或小于第二个对象 o2 ,该方法分别返回正整数、 0 、负整数。方法 compareToIgnoreCase 的返回规则是,若 this 字符串大于或等于或小于 another 字符串,该方法分别返回正整数、 0 、负整数。所以,在给抽象方法 compare 做实现时,可以调用 String 类的方法 compareToIgnoreCase ,实现对数组中的字符串进行字典序排序,且为正向排序。
lambda 表达式,有两个参数,在本例中,我们把这两个参数取名为 a 、 b ,代表数组中的两个字符串。从语法上讲,这两个名字是随机取的,称之为随机名字( arbitrary names ),我们完全可以为它们取其他的名字。当 java 运行时, lambda 表达式两个参数变量,也就是 String 类型的对象引用,会指向两个字符串对象。这两个对象称之为特定类型的随机对象( Arbitrary Object of a Particular Type )。方法 compareToIgnoreCase 是实例方法,使用的 lambda 表达式的第一个参数调用该方法,这称之为访问特定类型的随机对象的实例方法。
我们注意到,该 lambda 表达式的逻辑同样是调用一个方法就结束了。因此,我们可以使用方法引用代替 lambda 表达式。
String[] stringArray = { "Barbara", "James", "Mary", "John", "Patricia", "Robert", "Michael", "Linda" }; Arrays.sort(stringArray, String::compareToIgnoreCase);
方法 compareToIgnoreCase 是实例方法,必须是 String 类型的实例才可以调用它,但观察这个方法引用“ String::compareToIgnoreCase ”,我们看不出有任何 String 类型的实例调用该方法。请注意,若是方法引用的方法是实例方法,但看不出有实例调用它,说明若是使用 lambda 表达式,是 lambda 表达式的第一个方法参数调用了它。所以,这种形式的方法引用,“ String::compareToIgnoreCase ”,称之为访问特定类型的随机对象的实例方法。语法形式是,“ ContainingType::methodName ”,即“特定类型的随机对象::实例方法”。若是把它转为 lambda 表达式,它表达两层含义:
1.lambda 表达式的方法参数,第一个参数是作为当前对象,调用了方法 compareToIgnoreCase ,其他参数即是方法 compareToIgnoreCase 的参数,即“ (String a, String b) ”。
2.lambda表达式的方法体就是调用了方法 compareToIgnoreCase ,即“ a.compareToIgnoreCase(b) ”。
8.4. 访问构造函数
现在我们有这样的需求,把一个集合(源集合)的元素复制到另一个集合(目标集合)。
public static <T, S extends Collection<T>, D extends Collection<T>> D transferElements( S sourceCollection, Supplier<D> collectionFactory) { D result = collectionFactory.get(); for (T t : sourceCollection) { result.add(t); } return result; }
该方法 transferElements 声明了三个类型参数,第一个类型参数是 T ,代表任意类型。第二个类型参数是 S ,它的类型是 Collection<T> 或是 Collection<T> 的子类型。第三个类型参数是 D ,它的类型和第二个类型参数 S 一样。该方法返回值是类型 D ,代表新的集合,即目标集合,里面存放的元素是从老集合,即源集合复制而来。该方法有两个参数,第一个参数 S sourceCollection 代表源集合,第二个参数 Supplier<D> collectionFactory 代表集合工厂,可以从集合工厂获取一个目标集合。
Supplier<T> 是一个标准函数式接口,代表供应结果的供应商。类型参数 T 代表结果的类型。该接口抽象方法“ T get(); ”,不接受参数,返回一个类型为 T 的结果。
方法 transferElements 首先从集合工厂获取一个结果,在本例中,该结果就是目标集合。接着遍历源集合,把源集合的每一个元素复制到目标集合,最后,把目标集合返回。
接下面调用方法 transferElements ,实现需求。
List<Person> roster = ... Set<Person> rosterSetLambda = transferElements(roster, () -> new HashSet<Person>());
源集合是元素类型是 Person 的 List 集合,目标集合是元素类型是 Person 的 HashSet 集合,实现了把 List 集合中的元素复制到 HashSet 集合。仔细观察这个 lambda 表达式,它的方法体仅仅是调用了构造方法,创建了一个实例,所以,我们可以使用方法引用代替 lambda 表达式。
Set<Person> rosterSetLambda = transferElements(roster, HashSet<Person>::new);
这种形式的方法引用称之为访问构造函数,语法形式是“ ClassName::new ”,即“类名::new ”。此时,相信你心中会有一个疑问,类 HashSet<E> 有好几个构造函数,方法引用“ HashSet<Person>::new ”调用的哪一个构造函数?这和目标类型有关。方法 transferElements 的第二个参数的目标类型是函数式接口 Supplier<D> collectionFactory ,该函数式接口的抽象方法不接受参数,所以,方法引用“ HashSet<Person>::new ”调用的就是无参的构造函数。
public static <T, R> R constructor(T t, Function<T, R> mapper) { return mapper.apply(t); }
该方法的功能是根据输入,获得一个输出。声明了两个类型参数 T 、 R ,均代表任意类型,返回值的类型是 R 。该方法有两个参数,第一个参数是 T t 代表一个输入,第二参数 Function<T, R> mapper 是标准函数式接口类型,前面已经提过,该接口代表根据输入,获得一个输出。下面我们调用该方法。
constructor(2, t -> new Person());
输入的是一个整数数值 2 ,输出的一个 Person 实例。仔细观察这个 lambda 表达式,它的方法体仅仅是调用了构造方法,而且是无参构造函数,创建了一个实例,所以,我们可以使用方法引用代替 lambda 表达式。
constructor(2, Person::new);
此时,方法引用“ Person::new ”调用的是类 Person 的哪个构造函数?答案是带有一个 int 或 Integer 类型的参数的构造函数会被调用。比如,类 Person 有如下的构造函数会被调用。
public Person(int age) { this.age = age; }
为什么呢?这和目标类型有关。方法 constructor 的第二个参数类型是 Function<T, R> mapper ,它的抽象方法“ R apply(T t); ”接受一个类型为 T 的参数,在本例中,接收一个类型为 Integer 的参数。所以,方法引用“ Person::new ”调用的是带有一个 int 或 Integer 类型的参数的构造函数。若是把访问构造函数的方法引用转为 lambda 表达式,它表达两层含义:
1.lambda 表达式的方法参数就是构造函数 Person(int age) 的方法参数,即“ (int age) ” 。
2.lambda 表达式的方法体就是调用了构造函数 ,即 “ new Person(age) ”。构造函数的参数是由目标类型决定的,目标类型一定是函数式接口类型,接口的抽象方法的参数和构造函数的参数保持一致。
至此,有关 lambda 的知识就讲完了。 Java 设计者们以匿名类为出发点,设计了 lambda 表达式,进而设计出方法引用。目的是让程序的代码变得更少,可读性更好。
更多技术交流,敬请关注微信公众号,扫一扫下方二维码即可关注:


