Mybatis源码-XXXmapper.xml中的select|insert|update|delete标签解析过程
前提:上次讲过一篇《Mybatis源码-XXXmapper.xml中的resultMap标签解析过程》,现在就在上篇文章基础上讲一讲Mybatis是如何解析XXXmapper.xml文件中的select|insert|update|delete标签的,由于这几种标签的方式是一致的,下面我将以update标签为例,介绍一下update标签的解析过程。
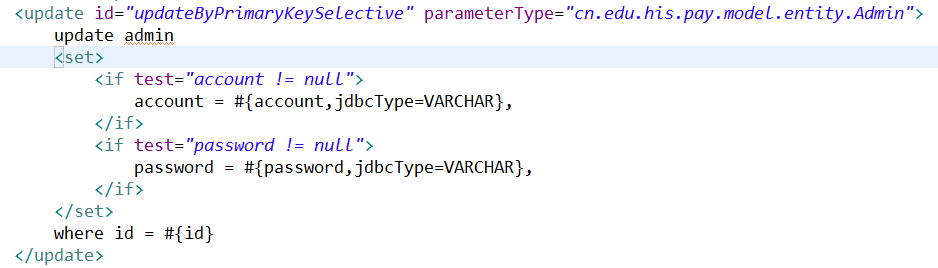
在这里还是先贴一下需要解析的updateByPrimaryKeySelective方法:
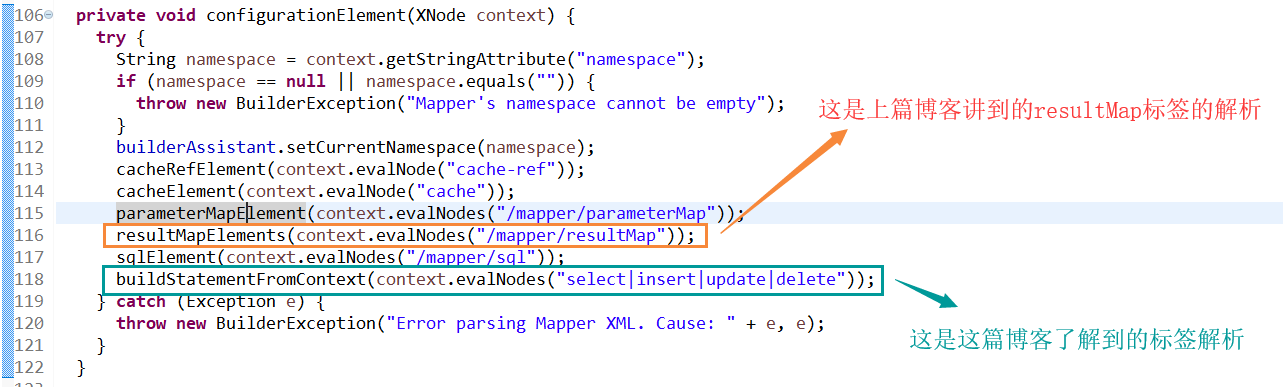
1. 首先进入select|insert|update|delete解析入口:XMLMapperBuilder#configurationElement。
2. XMLStatementBuilder#parseStatementNode是负责解析单前的select|insert|update|delete节点,主要就是拿到节点属性去XMLLanguageDriver#createSqlSource中解析节点的子节点属性,解析完拿到SqlSource对象,将SqlSource注册到大管家中。
public void parseStatementNode() { // 拿到当前update标签的id属性:updateByPrimaryKeySelective String id = context.getStringAttribute("id"); // 标签上配置的数据源databaseId String databaseId = context.getStringAttribute("databaseId"); // requiredDatabaseId为当前默认的数据源id,只有这二个id相等后才能正确的去解析该标签 if (!databaseIdMatchesCurrent(id, databaseId, this.requiredDatabaseId)) { return; } // 标签上配置的parameterType属性:cn.edu.his.pay.model.entity.Admin String parameterType = context.getStringAttribute("parameterType"); // 反射拿到该类的反射Clas对象 Class<?> parameterTypeClass = resolveClass(parameterType); String resultType = context.getStringAttribute("resultType"); // 拿到nodeName就是对应的是什么标签,如update,insert等等,sqlCommandType非常重要,其实就是确定是那一类操作 String nodeName = context.getNode().getNodeName(); SqlCommandType sqlCommandType = SqlCommandType.valueOf(nodeName.toUpperCase(Locale.ENGLISH)); // 显然现在是解析update标签而不是Select,false boolean isSelect = sqlCommandType == SqlCommandType.SELECT; // *** 重点-这里会进一步展开来看 SqlSource sqlSource = langDriver.createSqlSource(configuration, context, parameterTypeClass); String resultSets = context.getStringAttribute("resultSets"); String keyProperty = context.getStringAttribute("keyProperty"); String keyColumn = context.getStringAttribute("keyColumn"); // 在insert语句中我们可以在Insert标签下定义一个<selectKey>标签用于生成主键id,同样也可以自己生成 KeyGenerator keyGenerator; String keyStatementId = id + SelectKeyGenerator.SELECT_KEY_SUFFIX; keyStatementId = builderAssistant.applyCurrentNamespace(keyStatementId, true); if (configuration.hasKeyGenerator(keyStatementId)) { keyGenerator = configuration.getKeyGenerator(keyStatementId); } else { keyGenerator = context.getBooleanAttribute("useGeneratedKeys", configuration.isUseGeneratedKeys() && SqlCommandType.INSERT.equals(sqlCommandType)) ? Jdbc3KeyGenerator.INSTANCE : NoKeyGenerator.INSTANCE; } // 将解析后的SqlSource封装到大管家中 builderAssistant.addMappedStatement(id, sqlSource, statementType, sqlCommandType, fetchSize, timeout, parameterMap, parameterTypeClass, resultMap, resultTypeClass, resultSetTypeEnum, flushCache, useCache, resultOrdered, keyGenerator, keyProperty, keyColumn, databaseId, langDriver, resultSets); }
3. 上图代码中介绍了SqlSource的重要性,现在就更加深入的SqlSource是怎么产生的,这个时候就来到了XMLScriptBuilder#parseScriptNode方法,即就是解析当前的update标签的重点,可以看出如下的context就是当前需要解析的update类型的节点。
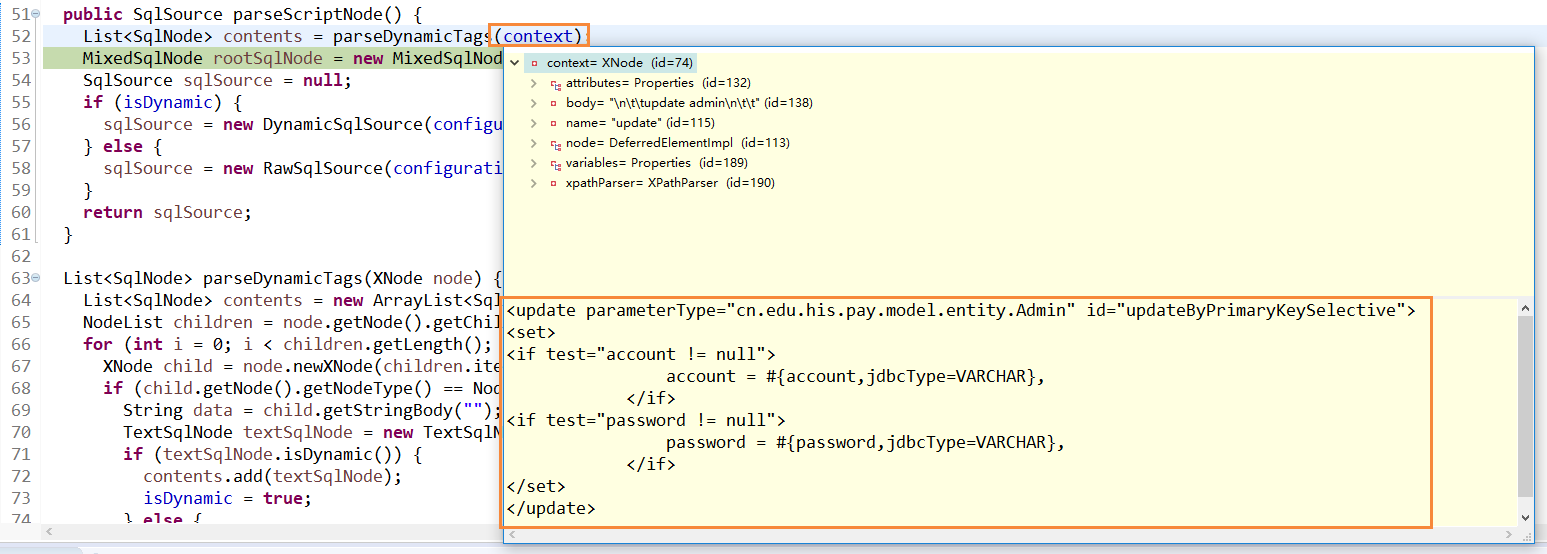
接着拿到update节点的信息调用XMLScriptBuilder#parseDynamicTags来解析这个节点,解析的时候主要就是判断当前节点下的属性类型,哪些是TEXT_NODE(文本节点),哪些是ELEMENT_NODE(元素节点)。当为文本节点是就直接往contents(负责封装节点信息)集合中加入一个StaticTextSqlNode。否则继续解析元素节点,并调用对于元素节点的处理类递归的去解析。
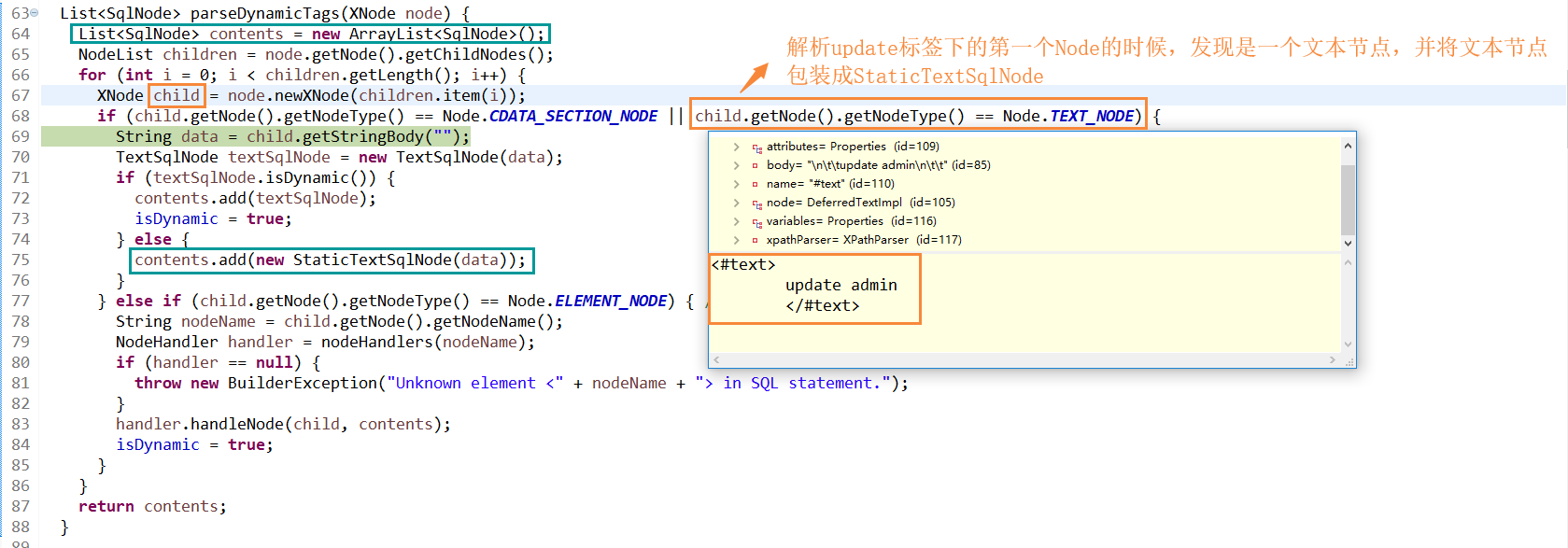
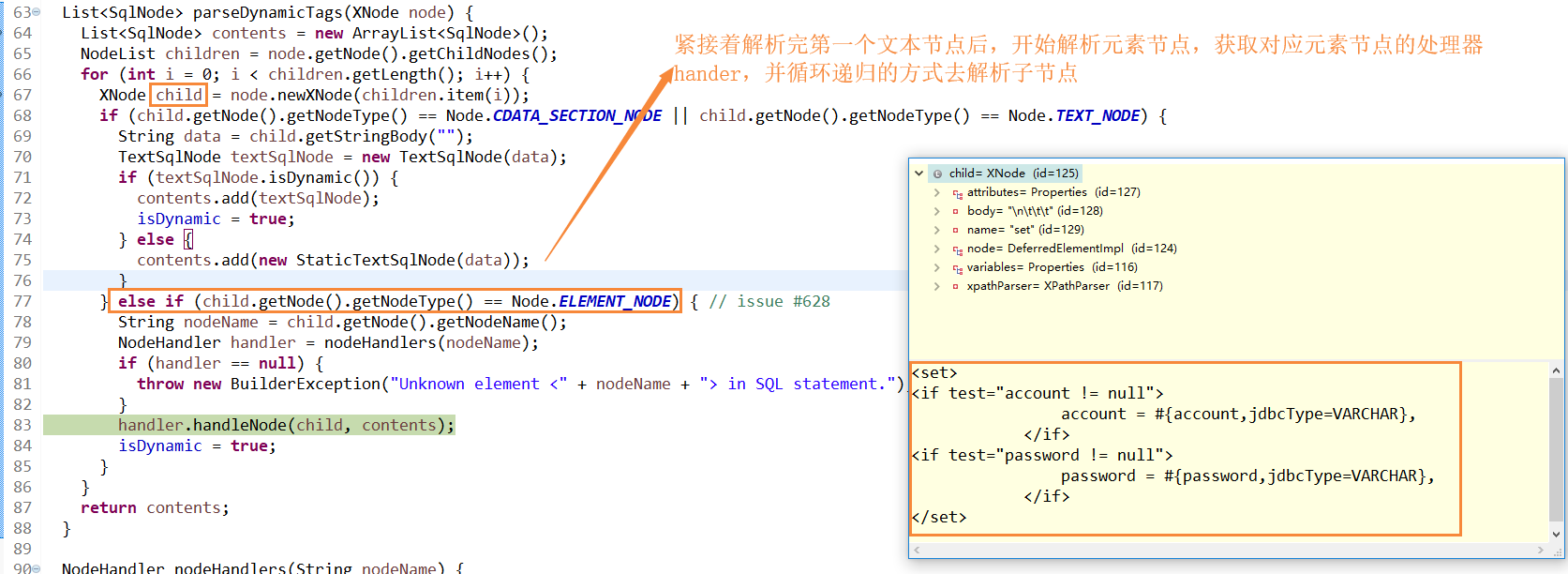
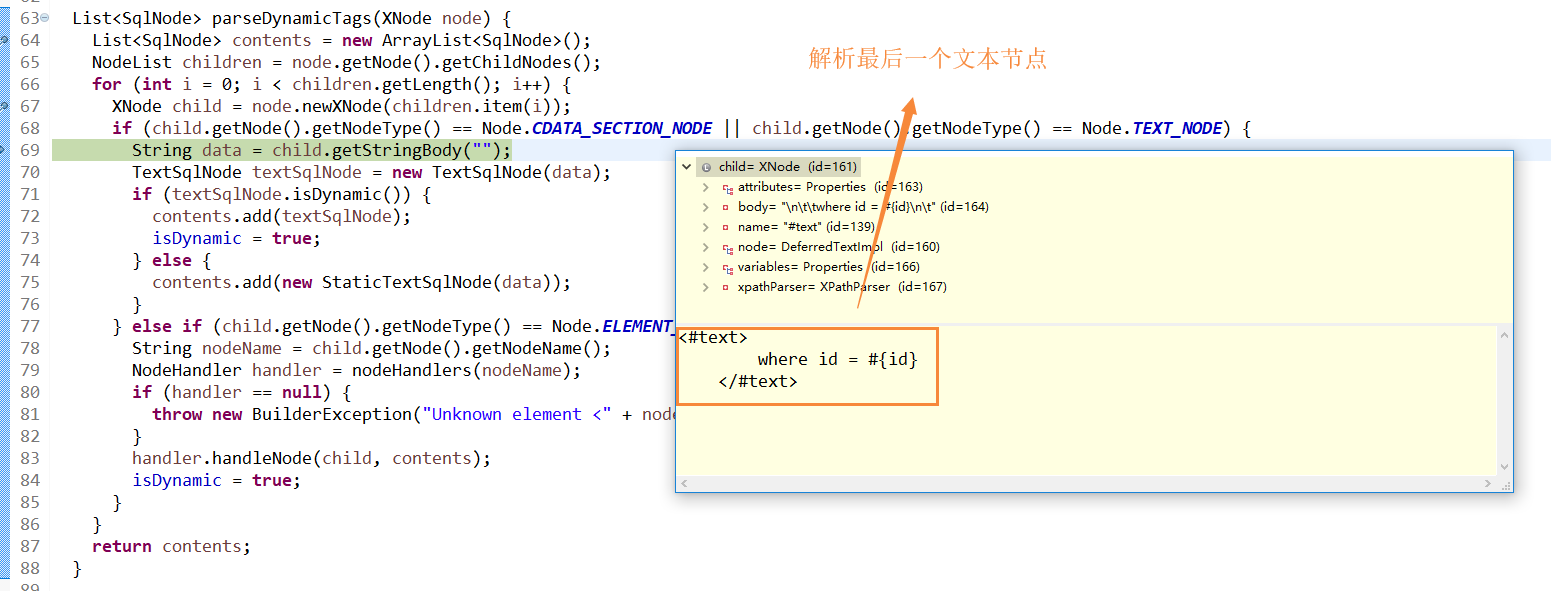
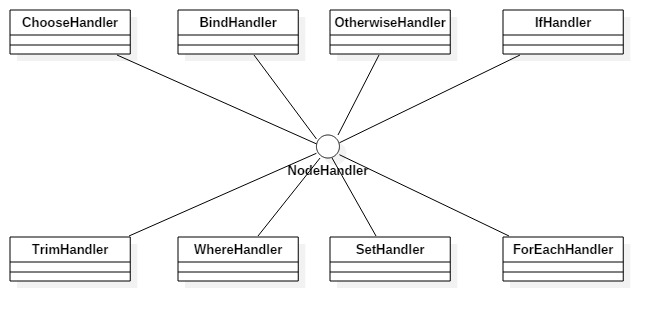
4. 这里就不再贴出set元素节点的效果图了,就是通过子节点的循环,拿到子节点信息,判断是什么类型的子节点后通过对应的子节点处理器进行解析,解析的方法就是通过反复递归调用parseDynamicTags方法来完成的,如下是Mybatis的节点处理器类图。
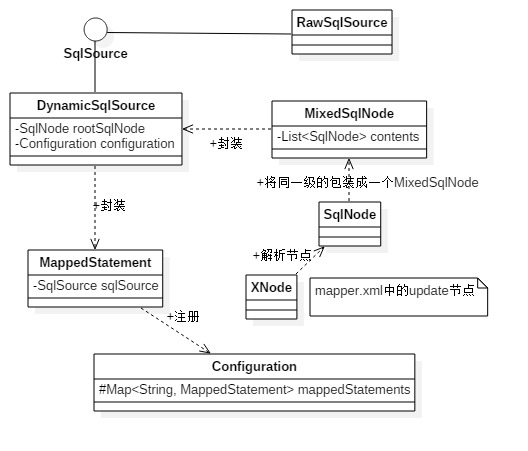
5. 通过所有的解析过后会得到一个最外层的SqlNode集合contents,并将contents包装到MixedSqlNode对象中个,如下是整个MixedSqlNode结构图。
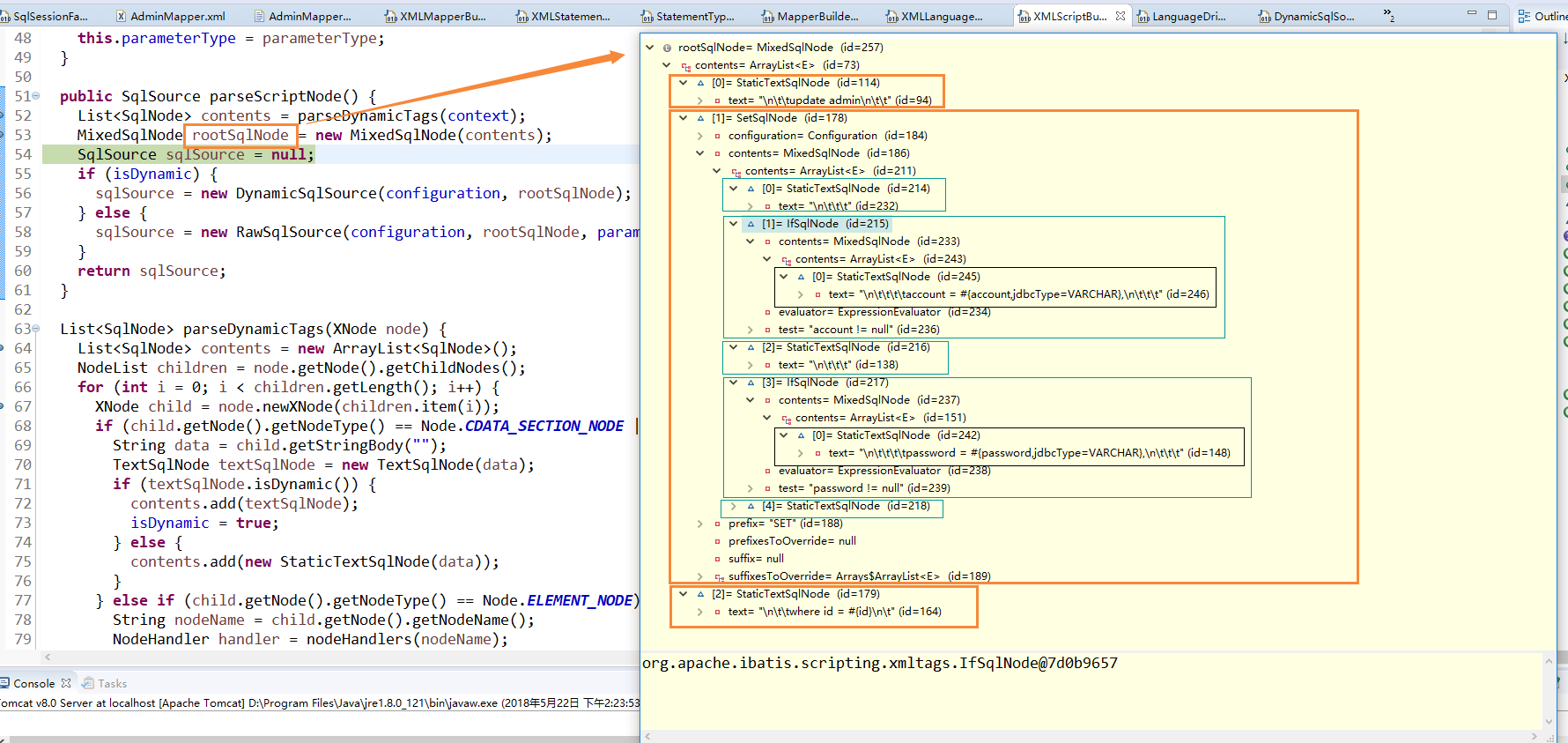
通过如上结构图发现,就一个简单的update标签,通过配置文件的解析后,会得到一个三个等级的封装,对应XXXmapper.xml中的update标签如下:
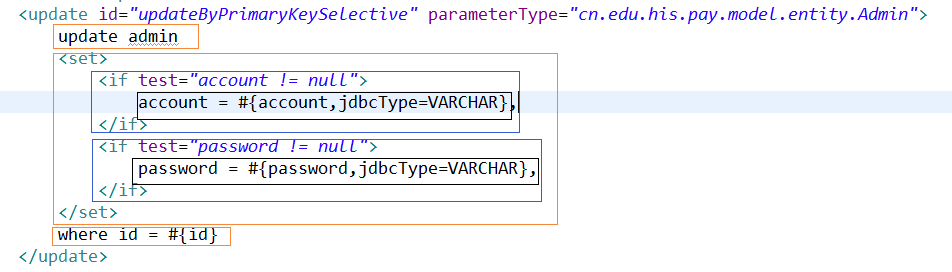
6. 最后附上包装的整体类图关系