前言
- 安装搜索引擎过程中,我遇到了很多坑!发出来让各位绕道而行,后面都是用ES关键字来代替Elasticsearch,后面的搭建和使用都是在centos 6.8环境下,本人使用的ES是5.5.0的版本,JDK使用1.8版本。
一、ES集群搭建
1.linux添加单独用户,因为ES不能使用root用户启动,会报错!
java.lang.RuntimeException: can not run elasticsearch as root at org.elasticsearch.bootstrap.Bootstrap.initializeNatives(Bootstrap.java:106) ~[elasticsearch-5.5.1.jar:5.5.1] at org.elasticsearch.bootstrap.Bootstrap.setup(Bootstrap.java:194) ~[elasticsearch-5.5.1.jar:5.5.1]
groupadd search #创建用户 useradd search-g search #设置密码 passwd search #创建es安装目录,并且用户授权 mkdir /opt/elasticsearch cd /opt chown -R search:search elasticsearch
2. 切换到search用户,然后去官网下载es安装包,解压到/opt/elasticsearch目录解压。
3. 启动ES
cd elasticsearch/bin ./elasticsearch
4.你可能遇到如下问题:
#这个是linux内核不支持 syscall filter,centos 7以上据说没这个问题,但是不影响使用 unable to install syscall filter: java.lang.UnsupportedOperationException: seccomp unavailable: CONFIG_SECCOMP not compiled into kernel, CONFIG_SECCOMP and CONFIG_SECCOMP_FILTER are needed #通过配置后面第[4]个好像就没有报错了
#linux max file配置过低 [1]: max file descriptors [4096] for elasticsearch process is too low, increase to at least [65536] #通过配置 /etc/security/limits.conf 解决 * soft nofile 65536 * hard nofile 65536 * soft nproc 2048 * hard nproc 4096
#使用最大线程数过低 [2]: max number of threads [1024] for user [search] is too low, increase to at least [2048] #通过配置/etc/security/limits.d/90-nproc.conf 解决 * soft nproc 2048
#虚拟内存配置太低 [3]: max virtual memory areas vm.max_map_count [65530] is too low, increase to at least [262144] #通过配置 /etc/sysctl.conf 追加一行如下解决 vm.max_map_count=655360
#system call filters安装失败 [4]: system call filters failed to install; check the logs and fix your configuration or disable system call filters at your own risk #解决办法通过配置 /opt/elasticsearch/config/elasticsearch.yml参数解决 bootstrap.memory_lock: false bootstrap.system_call_filter: false
5. ES启动JVM配置,在config/jvm.options调整了一下jvm参数
-Xms8g -Xmx8g
6. 我的master的ES启动配置参数,集群服务器的115这个节点也是和一下配置类似,只是IP不一样
cluster.name: onesearch node.name: master-node1 path.logs: /home/search/logs bootstrap.memory_lock: false bootstrap.system_call_filter: false network.host: 10.1.1.114 network.bind_host: 10.1.1.114 network.publish_host: 10.1.1.114 http.port: 9200 http.cors.enabled: true http.cors.allow-origin: "*" node.master: true node.data: true #我配置了两个节点 discovery.zen.ping.unicast.hosts: ["10.1.1.114","10.1.1.115"]
7. OK,现在启动master节点,您会看到日志就代表启动成功了
[2017-08-11T15:25:24,405][INFO ][o.e.n.Node ] [ZikeeFb] started
8. 然后在启动另外一个master节点的时候,您会看到日志里面提示另外一个节点已经连接,因为ES是自动发现节点的。
二、为ES安装head和ik分词器插件
- head插件是一个很试用的插件,界面简介,即使您不使用http rest方式访问也会对您后面的开发有很大的帮助
- ik中文分词器这个比较有名,好像paoding已经消失在历史长河中了,不多说。
1. 安装head插件,在使用ES 5.5的时候,我在网上搜了一些文档,但是都过时了,5.5安装head插件还不如说是自己单独安装了一个node 然后跑了一个node程序去通过http接口访问es接口。网上文档都是一律的把插件解压到ES的plugins目录里面,然而,我并没有跑起来,或许是我自己的问题。下面介绍单独跑node来部署head程序吧
#安装node,安装目录你自己随意定了 wget https://nodejs.org/dist/v6.11.2/node-v6.11.2-linux-x64.tar.xz #配置nodejs环境变量 编辑 /etc/profile ,我直接使用的root安装,这个所谓,主要安装node相关工具需要一些权限 export PATH=/root/node-v6.11.2-linux-x64/bin:$PATH #安装git,这里注意下,如果是自动安装git 1.7的话 clone会报403错,我是自己手动下载安装了1.9 yum -y install git #clone head插件源码 git clone git clone git://github.com/mobz/elasticsearch-head.git #进入head插件目录执行 npm install grunt --save npm install #这个慢得一批 #安装grunt cli npm install -g grunt-cli #编辑Gruntfile.js里面的hostname connect: { server: { options: { port: 9100, base: '.', hostname: '0.0.0.0', ##这里,这里 keepalive: true } } } #编辑_site/app.js ,找到下面这一行,加行后面一截,如果IP不一样,你自己修改,我是和master部署到同一个节点的 this.base_uri = this.config.base_uri || this.prefs.get("app-base_uri") || "http://localhost:9200"; ## <-注意这里,自己加 #启动head程序 grunt server -d #然后访问 http://IP:9100/ 即可看到简洁的界面
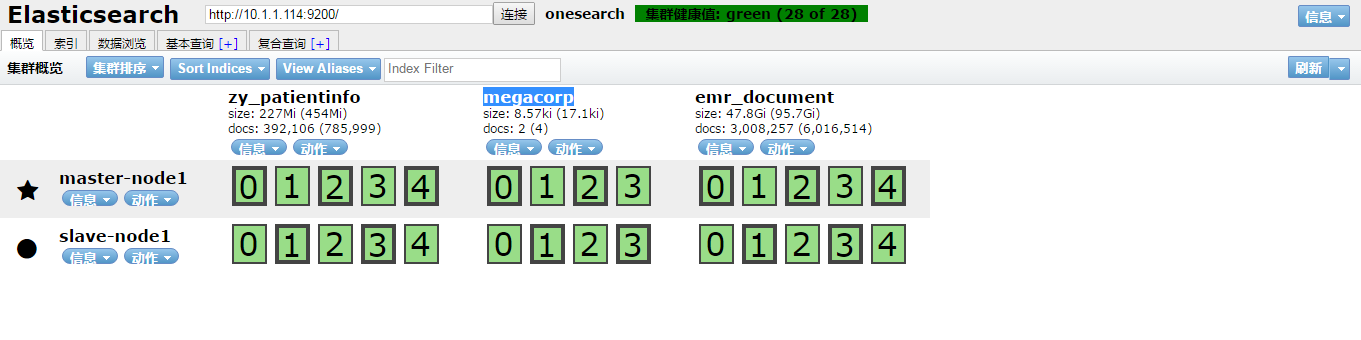
head程序(我不叫插件,因为我单独部署的)界面如下:
2. ik分词器插件安装,顺便说一句,使用yml配置方式来配置分词器已经在5.5不适用,启动会报错
#传说用的./elasticsearch-plugin install 方式来安装插件,我也没安装成功 #ik的github上提供了 ./bin/elasticsearch-plugin install https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v5.5.1/elasticsearch-analysis-ik-5.5.1.zip 我没试,因为我用的另外一种方式安装成功了 #下载https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v5.5.2/elasticsearch-analysis-ik-5.5.2.zip #在/opt/elasticsearch/plugins/下 创建ik目录 mkdir ik #然后把 elasticsearch-analysis-ik-5.5.2.zip 解压到ik目录,重启ES即可
- 测试分词器standard是es自带的,基本上就是一个字一个字的
#!!注意 下面连接里面的 megacorp 是我通过head程序手动创建了一个索引 #浏览器访问http://10.1.1.114:9200/megacorp/_analyze?analyzer=standard&pretty=true&text=我是卡尔码农 #得到一下访问结果 { "tokens" : [ { "token" : "我", "start_offset" : 0, "end_offset" : 1, "type" : "<IDEOGRAPHIC>", "position" : 0 }, { "token" : "是", "start_offset" : 1, "end_offset" : 2, "type" : "<IDEOGRAPHIC>", "position" : 1 }, { "token" : "卡", "start_offset" : 2, "end_offset" : 3, "type" : "<IDEOGRAPHIC>", "position" : 2 }, { "token" : "尔", "start_offset" : 3, "end_offset" : 4, "type" : "<IDEOGRAPHIC>", "position" : 3 }, { "token" : "码", "start_offset" : 4, "end_offset" : 5, "type" : "<IDEOGRAPHIC>", "position" : 4 }, { "token" : "农", "start_offset" : 5, "end_offset" : 6, "type" : "<IDEOGRAPHIC>", "position" : 5 } ] }
#浏览器请求http://10.1.1.114:9200/megacorp/_analyze?analyzer=ik_smart&pretty=true&text=我是卡尔码农 #其中analyzer=ik_smart可以换成analyzer=ik_max_word 是ik提供两种分词方式 #得到返回结果 { "tokens" : [ { "token" : "我", "start_offset" : 0, "end_offset" : 1, "type" : "CN_CHAR", "position" : 0 }, { "token" : "是", "start_offset" : 1, "end_offset" : 2, "type" : "CN_CHAR", "position" : 1 }, { "token" : "卡尔", "start_offset" : 2, "end_offset" : 4, "type" : "CN_WORD", "position" : 2 }, { "token" : "码", "start_offset" : 4, "end_offset" : 5, "type" : "CN_CHAR", "position" : 3 }, { "token" : "农", "start_offset" : 5, "end_offset" : 6, "type" : "CN_CHAR", "position" : 4 } ] }
还是有一点效果,其实搜索引擎分词很有讲究,现在我所了解的医疗行业的分词已经有公司通过机器学习病例样生成好用的字典给ik来使用,虽然上面"卡尔"被认为在一起,但是“码农”很明显也应该合并一下,这个我们都可以通过配置ik的字典来解决这个问题,当前不讨论这个问题了。
最后
当初有接触过lucene、后来接触compass、再后来接触TB的终搜、solrj包括现在的ES,搜索引擎在各行业中都发挥这重要作用,后面我会提到ES在我们单位的使用实战情况。感谢您的关注!

