HashMap也是我们使用非常多的Collection,它是基于哈希表的 Map 接口的实现,以key-value的形式存在。
HashMap是基于哈希表的Map接口的非同步实现。此实现提供所有可选的映射操作,并允许使用null值和null键。此类不保证映射的顺序,特别是它不保证该顺序恒久不变。
本文使用的是JDK1.7的HashMap源码,因为JDK1.8的HashMap改变还很多,以后再去单一分析。
HashMap内部结构
查看HashMap源代码,可以发现其继承自AbstractMap, 并实现了Map, Cloneable, Serializable接口~
public class HashMap<K,V> extends AbstractMap<K,V> implements Map<K,V>, Cloneable, Serializable
HashMap包含一个数组对象table[],
/** * The table, resized as necessary. Length MUST Always be a power of two. */ transient Entry<K,V>[] table = (Entry<K,V>[]) EMPTY_TABLE;
数组中包含的元素为Entry对象,Entry是HashMap中定义的静态内部类,内容如下:
static class Entry<K,V> implements Map.Entry<K,V> { final K key; V value; Entry<K,V> next; int hash; /** * Creates new entry. */ Entry(int h, K k, V v, Entry<K,V> n) { value = v; next = n; key = k; hash = h; } public final K getKey() { return key; } public final V getValue() { return value; } public final V setValue(V newValue) { V oldValue = value; value = newValue; return oldValue; } public final boolean equals(Object o) { if (!(o instanceof Map.Entry)) return false; Map.Entry e = (Map.Entry)o; Object k1 = getKey(); Object k2 = e.getKey(); if (k1 == k2 || (k1 != null && k1.equals(k2))) { Object v1 = getValue(); Object v2 = e.getValue(); if (v1 == v2 || (v1 != null && v1.equals(v2))) return true; } return false; } public final int hashCode() { return Objects.hashCode(getKey()) ^ Objects.hashCode(getValue()); } public final String toString() { return getKey() + "=" + getValue(); } /** * This method is invoked whenever the value in an entry is * overwritten by an invocation of put(k,v) for a key k that's already * in the HashMap. */ void recordAccess(HashMap<K,V> m) { } /** * This method is invoked whenever the entry is * removed from the table. */ void recordRemoval(HashMap<K,V> m) { } }
从Entry的类内容可以看出,其主要包含四个部分,
static class Entry<K,V> implements Map.Entry<K,V> { final K key; V value; Entry<K,V> next; int hash;
key -- 键
Value -- 值
next -- 下一个Entry对象
hash -- hash值
从上述的描述可以看出,HashMap的内部结构基本上是通过 “数组” + “链表”来实现~ 如下图所示:
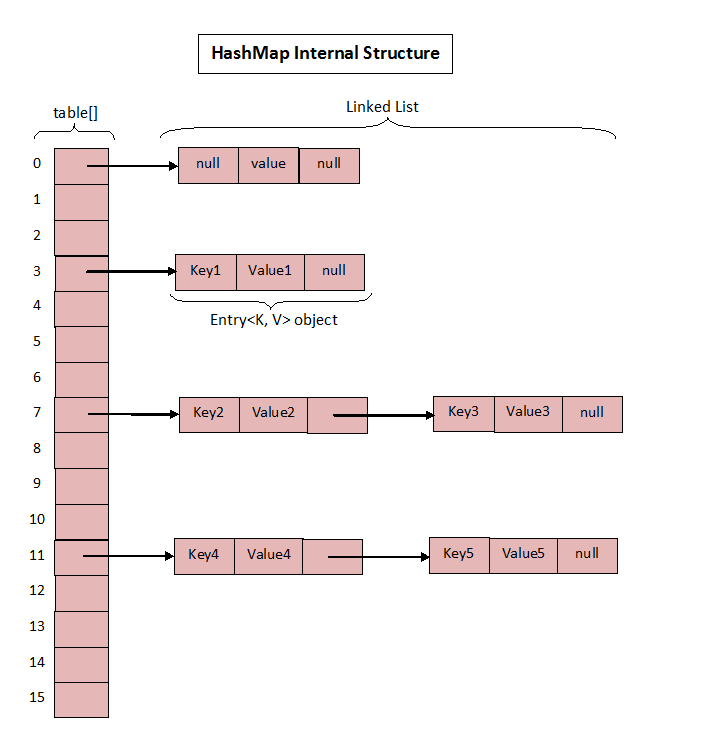
HashMap默认的大小为16
/** * The default initial capacity - MUST be a power of two. */ static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // aka 16
接下来,使用一个简单示例来感受一下HashMap的数组+链表的结构存储。
如下是一个以名字为键,年龄为值的HashMap示例~
import java.util.HashMap; import java.util.Map; public class MapExample { public static void main(String[] args) { Map<String, Integer> nameAgeMap = new HashMap<>(); nameAgeMap.put("Eric", 20); nameAgeMap.put("John", 21); nameAgeMap.put("LiLei", 19); nameAgeMap.put("Wang", 28); nameAgeMap.put("Zhang", 24); System.out.println(nameAgeMap); } }
在输出结果之前,Debug一下nameAgeMap中的内容,如下图所示:
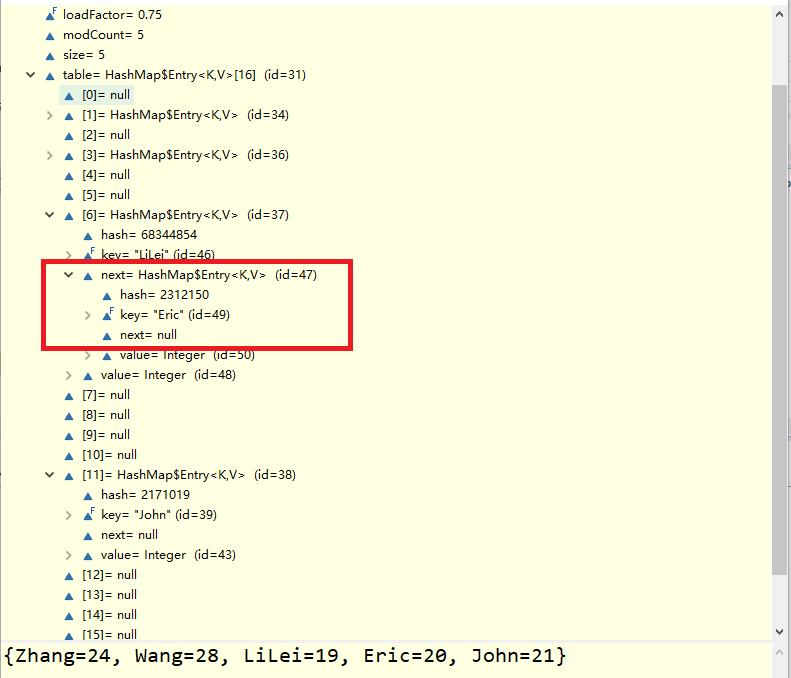
从上述的示例中可以看出,不同的Key根据hash映射到数组(table[])的不同部分上去。
HashMap通过如下方式选择元素存放在哪一个table[]元素中去:
int hash = hash(key); int i = indexFor(hash, table.length);
其中,
/** * Retrieve object hash code and applies a supplemental hash function to the * result hash, which defends against poor quality hash functions. This is * critical because HashMap uses power-of-two length hash tables, that * otherwise encounter collisions for hashCodes that do not differ * in lower bits. Note: Null keys always map to hash 0, thus index 0. */ final int hash(Object k) { int h = hashSeed; if (0 != h && k instanceof String) { return sun.misc.Hashing.stringHash32((String) k); } h ^= k.hashCode(); // This function ensures that hashCodes that differ only by // constant multiples at each bit position have a bounded // number of collisions (approximately 8 at default load factor). h ^= (h >>> 20) ^ (h >>> 12); return h ^ (h >>> 7) ^ (h >>> 4); }
- indexFor(hash, table.length)的内容为
/** * Returns index for hash code h. */ static int indexFor(int h, int length) { // assert Integer.bitCount(length) == 1 : "length must be a non-zero power of 2"; return h & (length-1); }
如果不同元素计算出来的hash值是一样的,HashMap使用链表的方式来解决。
就像上述示例中,
table[6]存放了key为“LiLei”的Entry,并且这个Entry的next对象为key为“Eric”的Entry。
对HashMap的数据结构有了大致了解之后,就可以来看看,HashMap的主要方法实现是怎么样的~
方法put的实现
源代码
/** * Associates the specified value with the specified key in this map. * If the map previously contained a mapping for the key, the old * value is replaced. * * @param key key with which the specified value is to be associated * @param value value to be associated with the specified key * @return the previous value associated with <tt>key</tt>, or * <tt>null</tt> if there was no mapping for <tt>key</tt>. * (A <tt>null</tt> return can also indicate that the map * previously associated <tt>null</tt> with <tt>key</tt>.) */ public V put(K key, V value) { if (table == EMPTY_TABLE) { inflateTable(threshold); } if (key == null) return putForNullKey(value); int hash = hash(key); int i = indexFor(hash, table.length); for (Entry<K,V> e = table[i]; e != null; e = e.next) { Object k; if (e.hash == hash && ((k = e.key) == key || key.equals(k))) { V oldValue = e.value; e.value = value; e.recordAccess(this); return oldValue; } } modCount++; addEntry(hash, key, value, i); return null; }
put方法步骤
put方法主要包含的部分如下图所示:

从源码可以看出,HashMap是支持键为null值的
使用代码来验证一下:
import java.util.HashMap; import java.util.Map; public class Test { public static void main(String[] args) { Map<String, Integer> nameAgeMap = new HashMap<>(); nameAgeMap.put("One", 1); nameAgeMap.put("Two", 2); nameAgeMap.put("Three", 3); nameAgeMap.put(null, 4); for (Map.Entry<String, Integer> entry : nameAgeMap.entrySet()) { System.out.println(entry.getKey() + ' ' + entry.getValue()); } } }
输出:
null 4 Three 3 One 1 Two 2
addEntry方法
/** * Adds a new entry with the specified key, value and hash code to * the specified bucket. It is the responsibility of this * method to resize the table if appropriate. * * Subclass overrides this to alter the behavior of put method. */ void addEntry(int hash, K key, V value, int bucketIndex) { if ((size >= threshold) && (null != table[bucketIndex])) { resize(2 * table.length); hash = (null != key) ? hash(key) : 0; bucketIndex = indexFor(hash, table.length); } createEntry(hash, key, value, bucketIndex); }
- 如果元素越来越多,达到阈值(threshold),则需要将table大小乘2,并重新hash
- 如果未到达阈值,则添加元素到相应的table[bucketIndex]中
createEntry方法
/** * Like addEntry except that this version is used when creating entries * as part of Map construction or "pseudo-construction" (cloning, * deserialization). This version needn't worry about resizing the table. * * Subclass overrides this to alter the behavior of HashMap(Map), * clone, and readObject. */ void createEntry(int hash, K key, V value, int bucketIndex) { Entry<K,V> e = table[bucketIndex]; table[bucketIndex] = new Entry<>(hash, key, value, e); size++; }
从上述可以看出,table[bucketIndex]中的Entry永远是存放最新的元素的~
方法get的实现
源代码
/** * Returns the value to which the specified key is mapped, * or {@code null} if this map contains no mapping for the key. * * <p>More formally, if this map contains a mapping from a key * {@code k} to a value {@code v} such that {@code (key==null ? k==null : * key.equals(k))}, then this method returns {@code v}; otherwise * it returns {@code null}. (There can be at most one such mapping.) * * <p>A return value of {@code null} does not <i>necessarily</i> * indicate that the map contains no mapping for the key; it's also * possible that the map explicitly maps the key to {@code null}. * The {@link #containsKey containsKey} operation may be used to * distinguish these two cases. * * @see #put(Object, Object) */ public V get(Object key) { if (key == null) return getForNullKey(); Entry<K,V> entry = getEntry(key); return null == entry ? null : entry.getValue(); }
从上述源码可以看出,HashMap的在实现上考虑了key为null值或者不为null值。
三个步骤==>
- 如果key为null值,则调用getForNullKey方法
- 如果key不为null值,则调用 getEntry(key)来获取Entry
- 如果获取的Entry为null,则返回null;不为null则返回entry.getValue()
getForNullKey方法
/** * Offloaded version of get() to look up null keys. Null keys map * to index 0. This null case is split out into separate methods * for the sake of performance in the two most commonly used * operations (get and put), but incorporated with conditionals in * others. */ private V getForNullKey() { if (size == 0) { return null; } for (Entry<K,V> e = table[0]; e != null; e = e.next) { if (e.key == null) return e.value; } return null; }
如果Map中没有元素,则返回null,否则从table[0]中查找~
getEntry(Object key)方法
/** * Returns the entry associated with the specified key in the * HashMap. Returns null if the HashMap contains no mapping * for the key. */ final Entry<K,V> getEntry(Object key) { if (size == 0) { return null; } int hash = (key == null) ? 0 : hash(key); for (Entry<K,V> e = table[indexFor(hash, table.length)]; e != null; e = e.next) { Object k; if (e.hash == hash && ((k = e.key) == key || (key != null && key.equals(k)))) return e; } return null; }
- 如果size为0,也就是HashMap中没有元素,则返回null
- 如果HashMap中有元素,则先计算出key值对应的数组元素table[bucketIndex], 然后通过遍历链表获取元素
方法clear的实现
源代码
/** * Removes all of the mappings from this map. * The map will be empty after this call returns. */ public void clear() { modCount++; Arrays.fill(table, null); size = 0; }
HashMap中clear方法的实现包含了如下几个部分
- 修改次数加1
- 数组table的元素设置成null,调用Arrays.fill方法实现
- HashMap中元素的个数size设置成0
Arrays.fill方法如下:
/** * Assigns the specified Object reference to each element of the specified * array of Objects. * * @param a the array to be filled * @param val the value to be stored in all elements of the array * @throws ArrayStoreException if the specified value is not of a * runtime type that can be stored in the specified array */ public static void fill(Object[] a, Object val) { for (int i = 0, len = a.length; i < len; i++) a[i] = val; }
方法containsKey和containsValue的实现
containsKey的实现
/** * Returns <tt>true</tt> if this map contains a mapping for the * specified key. * * @param key The key whose presence in this map is to be tested * @return <tt>true</tt> if this map contains a mapping for the specified * key. */ public boolean containsKey(Object key) { return getEntry(key) != null; } /** * Returns the entry associated with the specified key in the * HashMap. Returns null if the HashMap contains no mapping * for the key. */ final Entry<K,V> getEntry(Object key) { if (size == 0) { return null; } int hash = (key == null) ? 0 : hash(key); for (Entry<K,V> e = table[indexFor(hash, table.length)]; e != null; e = e.next) { Object k; if (e.hash == hash && ((k = e.key) == key || (key != null && key.equals(k)))) return e; } return null; }
getEntry(key)方法说明如下:
- 如果size为0,也就是HashMap中没有元素,则返回null
- 如果HashMap中有元素,则先计算出key值对应的数组元素table[bucketIndex], 然后通过遍历链表获取元素
containsValue的实现
/** * Returns <tt>true</tt> if this map maps one or more keys to the * specified value. * * @param value value whose presence in this map is to be tested * @return <tt>true</tt> if this map maps one or more keys to the * specified value */ public boolean containsValue(Object value) { if (value == null) return containsNullValue(); Entry[] tab = table; for (int i = 0; i < tab.length ; i++) for (Entry e = tab[i] ; e != null ; e = e.next) if (value.equals(e.value)) return true; return false; } /** * Special-case code for containsValue with null argument */ private boolean containsNullValue() { Entry[] tab = table; for (int i = 0; i < tab.length ; i++) for (Entry e = tab[i] ; e != null ; e = e.next) if (e.value == null) return true; return false; }
无论value的值是否为null值,都是采用双重循环来实现~
方法resize的实现
源代码
/** * Rehashes the contents of this map into a new array with a * larger capacity. This method is called automatically when the * number of keys in this map reaches its threshold. * * If current capacity is MAXIMUM_CAPACITY, this method does not * resize the map, but sets threshold to Integer.MAX_VALUE. * This has the effect of preventing future calls. * * @param newCapacity the new capacity, MUST be a power of two; * must be greater than current capacity unless current * capacity is MAXIMUM_CAPACITY (in which case value * is irrelevant). */ void resize(int newCapacity) { Entry[] oldTable = table; int oldCapacity = oldTable.length; if (oldCapacity == MAXIMUM_CAPACITY) { threshold = Integer.MAX_VALUE; return; } Entry[] newTable = new Entry[newCapacity]; transfer(newTable, initHashSeedAsNeeded(newCapacity)); table = newTable; threshold = (int)Math.min(newCapacity * loadFactor, MAXIMUM_CAPACITY + 1); }
就想上面提到过的,如果HashMap中添加元素超过了阈值,则需要扩容,并重新分配元素到新的数组( table[] )中去~
如transfer方法如下所示,其作用就是将所有的元素从当前table数组中,转移到新的table数组中
transfer方法
/** * Transfers all entries from current table to newTable. */ void transfer(Entry[] newTable, boolean rehash) { int newCapacity = newTable.length; for (Entry<K,V> e : table) { while(null != e) { Entry<K,V> next = e.next; if (rehash) { e.hash = null == e.key ? 0 : hash(e.key); } int i = indexFor(e.hash, newCapacity); e.next = newTable[i]; newTable[i] = e; e = next; } } }
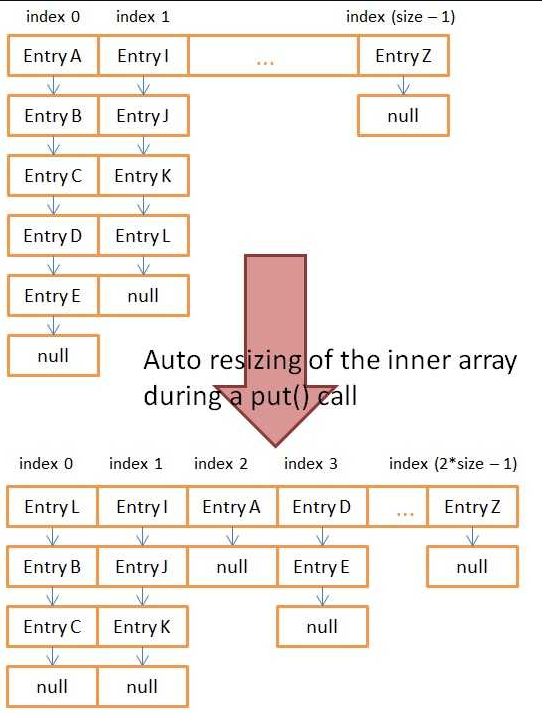
resize方法在添加单个元素的时候,需要考虑,同样在添加多个元素的时候更要考虑~
putAll方法
/** * Copies all of the mappings from the specified map to this map. * These mappings will replace any mappings that this map had for * any of the keys currently in the specified map. * * @param m mappings to be stored in this map * @throws NullPointerException if the specified map is null */ public void putAll(Map<? extends K, ? extends V> m) { int numKeysToBeAdded = m.size(); if (numKeysToBeAdded == 0) return; if (table == EMPTY_TABLE) { inflateTable((int) Math.max(numKeysToBeAdded * loadFactor, threshold)); } /* * Expand the map if the map if the number of mappings to be added * is greater than or equal to threshold. This is conservative; the * obvious condition is (m.size() + size) >= threshold, but this * condition could result in a map with twice the appropriate capacity, * if the keys to be added overlap with the keys already in this map. * By using the conservative calculation, we subject ourself * to at most one extra resize. */ if (numKeysToBeAdded > threshold) { int targetCapacity = (int)(numKeysToBeAdded / loadFactor + 1); if (targetCapacity > MAXIMUM_CAPACITY) targetCapacity = MAXIMUM_CAPACITY; int newCapacity = table.length; while (newCapacity < targetCapacity) newCapacity <<= 1; if (newCapacity > table.length) resize(newCapacity); } for (Map.Entry<? extends K, ? extends V> e : m.entrySet()) put(e.getKey(), e.getValue()); }
putAll方法就是确定好足够的大小之后,循环调用put方法来实现的~
方法remove的实现
源代码
/** * Removes the mapping for the specified key from this map if present. * * @param key key whose mapping is to be removed from the map * @return the previous value associated with <tt>key</tt>, or * <tt>null</tt> if there was no mapping for <tt>key</tt>. * (A <tt>null</tt> return can also indicate that the map * previously associated <tt>null</tt> with <tt>key</tt>.) */ public V remove(Object key) { Entry<K,V> e = removeEntryForKey(key); return (e == null ? null : e.value); }
remove方法其实就是调用了removeEntryForKey方法~
removeEntryForKey如下:
方法removeEntryForKey
/** * Removes and returns the entry associated with the specified key * in the HashMap. Returns null if the HashMap contains no mapping * for this key. */ final Entry<K,V> removeEntryForKey(Object key) { if (size == 0) { return null; } int hash = (key == null) ? 0 : hash(key); int i = indexFor(hash, table.length); Entry<K,V> prev = table[i]; Entry<K,V> e = prev; while (e != null) { Entry<K,V> next = e.next; Object k; if (e.hash == hash && ((k = e.key) == key || (key != null && key.equals(k)))) { modCount++; size--; if (prev == e) table[i] = next; else prev.next = next; e.recordRemoval(this); return e; } prev = e; e = next; } return e; }
removeEntryForKey其实就是链表的删除的实现,其包含如下几个部分:
- 如果没有元素,则返回null值
- 然后根据key计算hash值,并确定到哪一个table[bucketIndex]中删除
- 循环遍历元素,删除符合条件的Entry节点即可,比较好理解
方法indexFor的实现
源代码
/** * Returns index for hash code h. */ static int indexFor(int h, int length) { // assert Integer.bitCount(length) == 1 : "length must be a non-zero power of 2"; return h & (length-1); }
indexFor方法在HashMap中用于定位数组位置table[bucketIndex]~
int i = indexFor(hash, table.length);
在HashMap中,table的长度定义推荐使用2的N次方~
h & (length - 1) 等价与 h % length,但他们是等价(效果)不等效(效率)的,位运算结果与取模一致,但效率更高;
这样做的好处还有:
当数组长度为2的n次幂的时候,不同的key算得得index相同的几率较小,那么数据在数组上分布就比较均匀,也就是说碰撞的几率小,相对的,查询的时候就不用遍历某个位置上的链表,这样查询效率也就较高了。 参考【http://www.iteye.com/topic/539465】
modCount是干嘛的
源代码
/** * The number of times this HashMap has been structurally modified * Structural modifications are those that change the number of mappings in * the HashMap or otherwise modify its internal structure (e.g., * rehash). This field is used to make iterators on Collection-views of * the HashMap fail-fast. (See ConcurrentModificationException). */ transient int modCount;
modCount记录的HashMap结构变化的次数,在迭代器初始化过程中会将这个值赋给迭代器的 expectedModCount,在迭代过程中,判断 modCount 跟 expectedModCount 是否相等,如果不相等就表示已经有其他线程修改了 Map,那么将抛出ConcurrentModificationException,这就是所谓fail-fast策略。
可以查看HashMap中的抽象类HashIterator:
private abstract class HashIterator<E> implements Iterator<E> { Entry<K,V> next; // next entry to return int expectedModCount; // For fast-fail int index; // current slot Entry<K,V> current; // current entry HashIterator() { expectedModCount = modCount; if (size > 0) { // advance to first entry Entry[] t = table; while (index < t.length && (next = t[index++]) == null) ; } }
- remove改变抛ConcurrentModificationException异常
final Entry<K,V> nextEntry() { if (modCount != expectedModCount) throw new ConcurrentModificationException(); Entry<K,V> e = next; if (e == null) throw new NoSuchElementException(); if ((next = e.next) == null) { Entry[] t = table; while (index < t.length && (next = t[index++]) == null) ; } current = e; return e; } public void remove() { if (current == null) throw new IllegalStateException(); if (modCount != expectedModCount) throw new ConcurrentModificationException(); Object k = current.key; current = null; HashMap.this.removeEntryForKey(k); expectedModCount = modCount; }
Fail-Fast简单示例
import java.util.HashMap; import java.util.Map; public class Test { public static void main(String[] args) { Map<String, Integer> nameAgeMap = new HashMap<>(); nameAgeMap.put("One", 1); nameAgeMap.put("Two", 2); nameAgeMap.put("Three", 3); nameAgeMap.put(null, 4); nameAgeMap.put("five", null); for (Map.Entry<String, Integer> entry : nameAgeMap.entrySet()) { if(null == entry.getKey()) { nameAgeMap.remove(null); } System.out.println(entry.getKey() + ' ' + entry.getValue()); } } }
运行结果:
null 4 Exception in thread "main" java.util.ConcurrentModificationException at java.util.HashMap$HashIterator.nextEntry(Unknown Source) at java.util.HashMap$EntryIterator.next(Unknown Source) at java.util.HashMap$EntryIterator.next(Unknown Source) at Test.main(Test.java:16)
这里就不对HashMap中的方法一一列举了~
JDK 1.8 HashMap调整
HashMap在JDK1.8中,相比JDK 1.7做了较多的改动。
HashMap的数据结构(数组+链表+红黑树),桶中的结构可能是链表,也可能是红黑树,红黑树的引入是为了提高效率

如put方法~
/** * Associates the specified value with the specified key in this map. * If the map previously contained a mapping for the key, the old * value is replaced. * * @param key key with which the specified value is to be associated * @param value value to be associated with the specified key * @return the previous value associated with <tt>key</tt>, or * <tt>null</tt> if there was no mapping for <tt>key</tt>. * (A <tt>null</tt> return can also indicate that the map * previously associated <tt>null</tt> with <tt>key</tt>.) */ public V put(K key, V value) { return putVal(hash(key), key, value, false, true); }
putVal方法
/** * Implements Map.put and related methods * * @param hash hash for key * @param key the key * @param value the value to put * @param onlyIfAbsent if true, don't change existing value * @param evict if false, the table is in creation mode. * @return previous value, or null if none */ final V putVal(int hash, K key, V value, boolean onlyIfAbsent, boolean evict) { Node<K,V>[] tab; Node<K,V> p; int n, i; if ((tab = table) == null || (n = tab.length) == 0) n = (tab = resize()).length; if ((p = tab[i = (n - 1) & hash]) == null) tab[i] = newNode(hash, key, value, null); else { Node<K,V> e; K k; if (p.hash == hash && ((k = p.key) == key || (key != null && key.equals(k)))) e = p; else if (p instanceof TreeNode) e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value); else { for (int binCount = 0; ; ++binCount) { if ((e = p.next) == null) { p.next = newNode(hash, key, value, null); if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st treeifyBin(tab, hash); break; } if (e.hash == hash && ((k = e.key) == key || (key != null && key.equals(k)))) break; p = e; } } if (e != null) { // existing mapping for key V oldValue = e.value; if (!onlyIfAbsent || oldValue == null) e.value = value; afterNodeAccess(e); return oldValue; } } ++modCount; if (++size > threshold) resize(); afterNodeInsertion(evict); return null; }
其中, treeifyBin(tab, hash)部分就是红黑树的相关处理部分~
参考
http://coding-geek.com/how-does-a-hashmap-work-in-java/
http://javaconceptoftheday.com/how-hashmap-works-internally-in-java/

