写在前面:该篇宕机问题的排查难度远比上一篇(记一次解决线上OOM的心路历程)大的太多,上一篇中内存泄漏的问题是有迹可循的,本次的宕机在业务日志上没有任何征兆,另外本文有许多值得深挖的点,希望读者能找到自己感兴趣的点进行深挖,并将心得体会留言在评论区,让大家共同进步。
现象:zabbix告警生产环境应用shutdown,通过堡垒机登入生产环境,查看应用容器进程,并发现没有该业务应用的相应进程,第一感觉进程在某些条件下被系统杀死了,然后查看容器日志,发现均没异常可寻。
问题:
1、为何会没有应用进程及异常的日志输出?如果真的是系统杀死了应用进程,是什么条件触发了它?
2、测试环境、UAT环境为何从未有这样的情况,差别在哪?
排查:
首先去查看生产环境系统资源情况及相应容器的配置,查得该台生产机器的总内存是8G:

接着查看该应用所在容器环境的变量设置:
#!/bin/sh # chkconfig: 345 88 14 # description: Tomcat Daemon set -m #Change to your Jdk directory SCRIPT_HOME=/home/appadmin/scripts/glink export JAVA_HOME=/Data/software/jdk1.8.0_65 #Change to your Tomcat directory CATALINA_HOME=/Data/software/tomcat-glink export JAVA_OPTS="-server -Xms512m -Xmx4G -XX:PermSize=128M -XX:MaxNewSize=512m -XX:MaxPermSize=256m -Djava.awt.headless=true -XX:+PrintGCDetails -XX:+PrintGCApplicationStoppedTime -XX:+PrintGCApplicationConcurrentTime -XX:+PrintGCTimeStamps -Xloggc:$CATALINA_HOME/logs/gc.log -Djava.awt.headless=true -Denv=prod -Dproject=GLINK -Dprofile=Production_us -Dallow.push=true -Dsave.directory=/Data/diamond/glink/config -Dcat.app.name=GLINK_PROD -Duser.timezone=GMT+08" # Determine and execute action based on command line parameter #-Ddiamond.conf.path=/Data/diamond/glink/diamond.properties echo "Starting Best Glink Tomcat..." DATE=`date "+%Y-%m-%d %H:%M:%S"` echo "$DATE : user $USER starts tomcat." >> $SCRIPT_HOME/start.log sh $CATALINA_HOME/bin/startup.sh
此处可以看到这里为java设置的最大内存为4G,接着我们又查看了部署在本台机器上的另一个应用环境的设置,结果和该应用一样,设置的内存大小为4G,我们继续查看了该机器上的其他java应用,发现另外还部署了一个本地queue(activitymq),且设置的最大占用内存为1G,此时似乎已经可以猜测,由于机器的总内存不够,当应用在申请新的内存时,由于环境变量设置的缘故并没有去触发GC,而是直接申请内存,系统方发现总内存已经不够用,于是直接将该应用进程杀死。

为了验证上面的说法,我们查找系统的相关日志:
less /var/log/messages
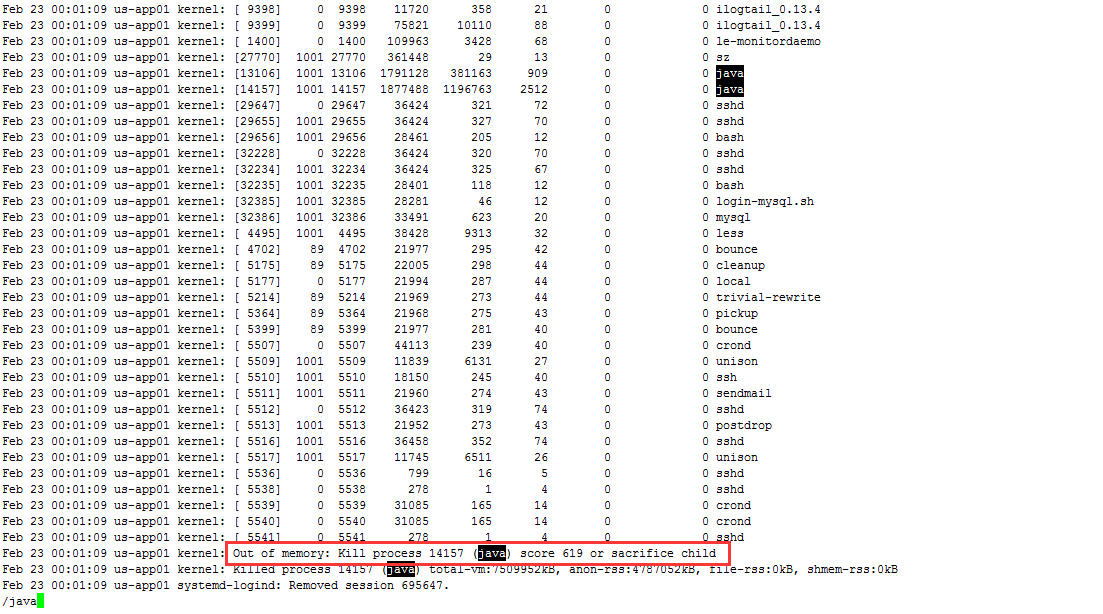
清晰地看到:Feb 23 00:01:09 us-app01 kernel: Out of memory: Kill process 14157 (java) score 619 or sacrifice child,此处说明的确是系统杀死了应用进程,根据这里的系统日志查询资料得知,系统会为每一块新分配的内存添加跟踪记录至low memory,当low memory的内存耗尽同时有需要新分配内存时,内核便会触发Kill process,此处为什么系统选择了kill该应用进程,我的猜想是一该应用进程属于用户进程,它的结束并不会影响系统的正常运行,二是由于该应用最大可用内存设置的不合理性,需要新分配内存来存储对象就发生在其中。由于当时的进程已经被系统杀死,我们无法得知当时具体内存的使用及分配情况,作为参考依据我们选择查看相同环境下的另一台机器的内存情况:
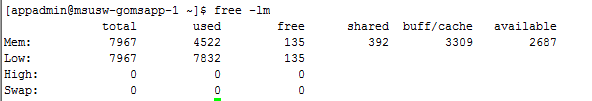
此处可以看出系统的总内存为7967m,low memory的总内存也为7967,(64位的系统,系统总内存与low memory相同),当前low memory已经使用7832(low memory = used + buff/cache)。
种种迹象表明:由于该应用及部署在同一台机器上的另一个应用,其环境中最大可用内存设置的不合理(系统总内存8G,这两个应用的最大可用内存设置为4G,同时机器上还有一个本地queue)性,导致其内部在申请内存时由于系统的low memory被耗尽,触使系统杀死了该应用进程。
临时解决:
减少应用环境中的设置的最大可用内存,重启应用。
继续解决:
应用重启后的一段时间(几天后),我们查看应用使用的内存情况:
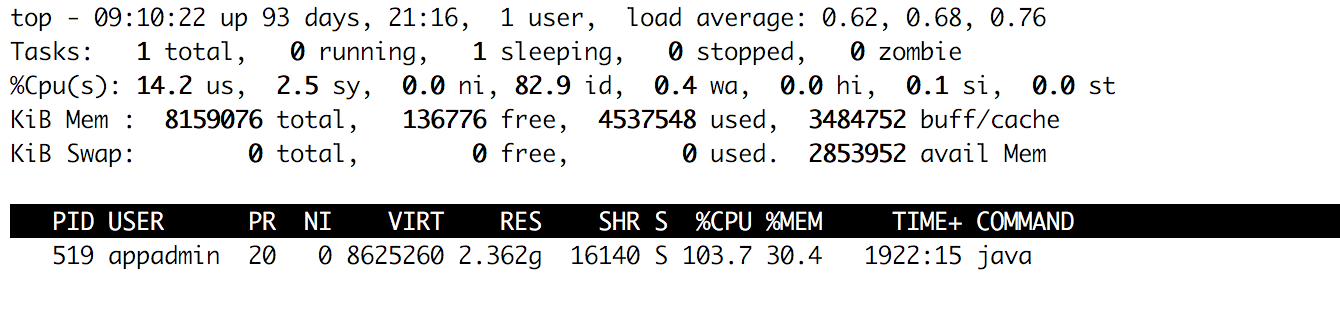
我们想到该应用满足的业务量很小并没有那种数据量特别大的场景,为何系统会使用掉这么多的内存呢,于是我们决定对该应用从代码角度上进行一些可行的调优。
首先使用jmp dump出内存快照,并导入jprofiler,借助jprofiler进行分析:
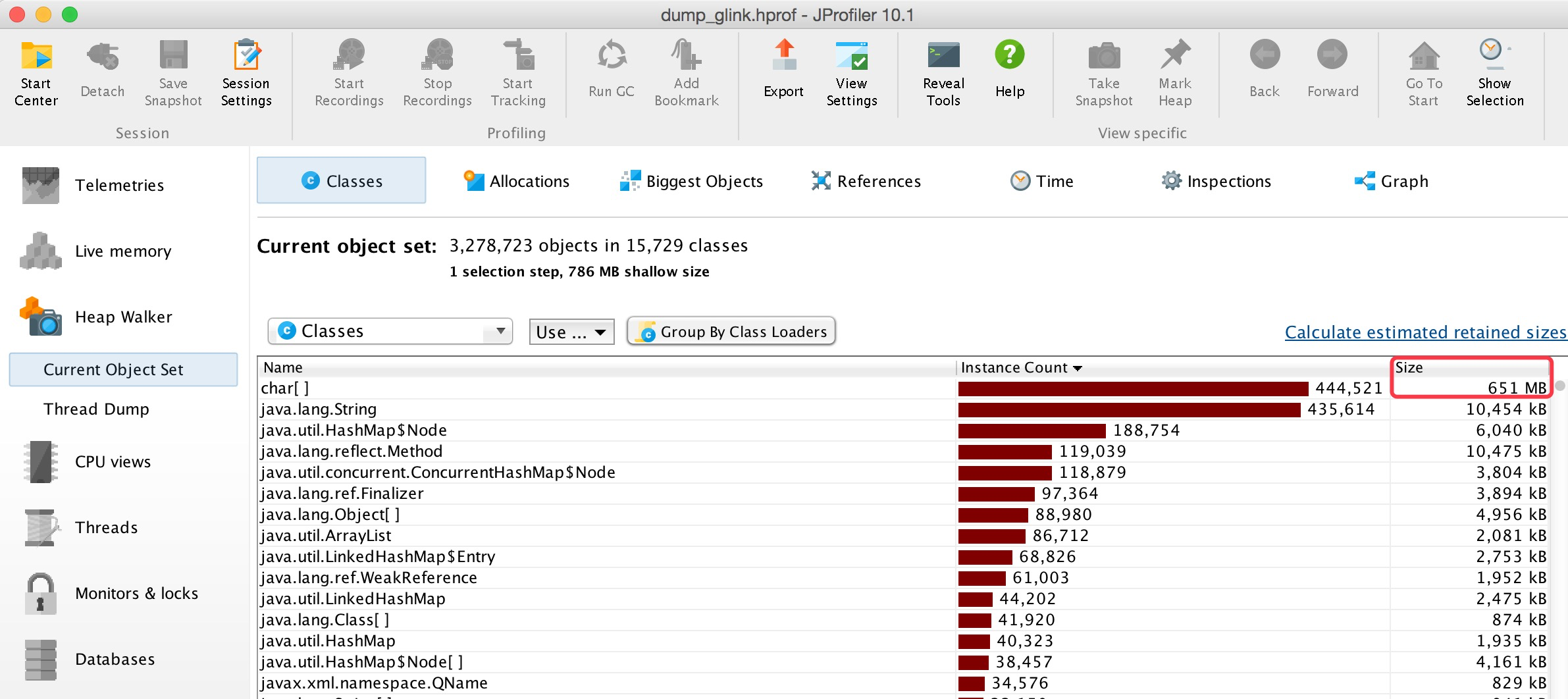
从上图我们可以看到char[]占用了651m的内存,String占用的是10m左右,显然这里对char类型的使用或者处理是有问题的,我们进一步查看到底是什么地方使用了char[],又有哪些大的char[]实例,以及其中都存了怎样的数据:
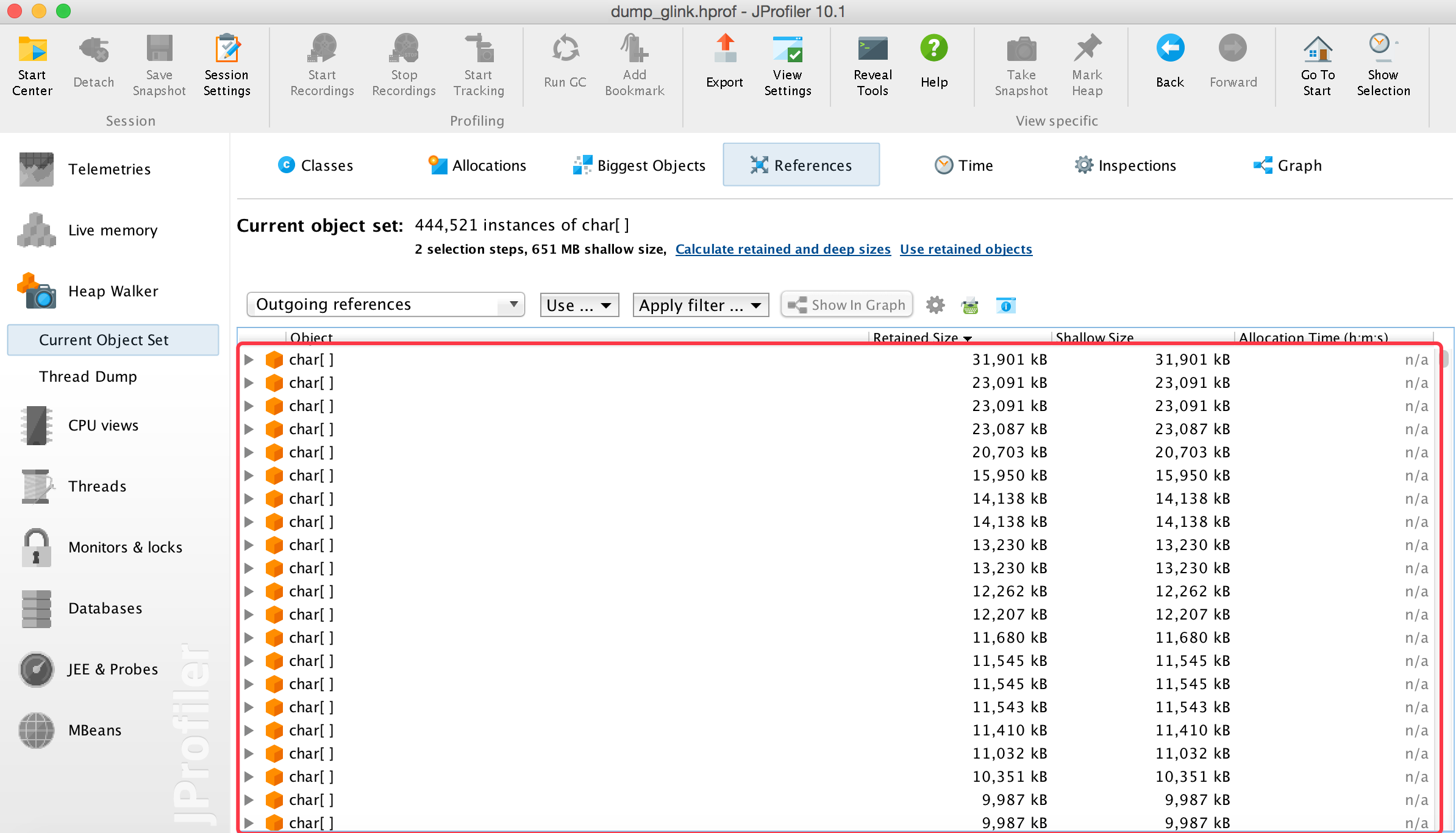
这里我们看到有将近20个char[]实例的大小都超过了10m,其中最大的已然有30m,我们再查看这里都存了哪些数据:
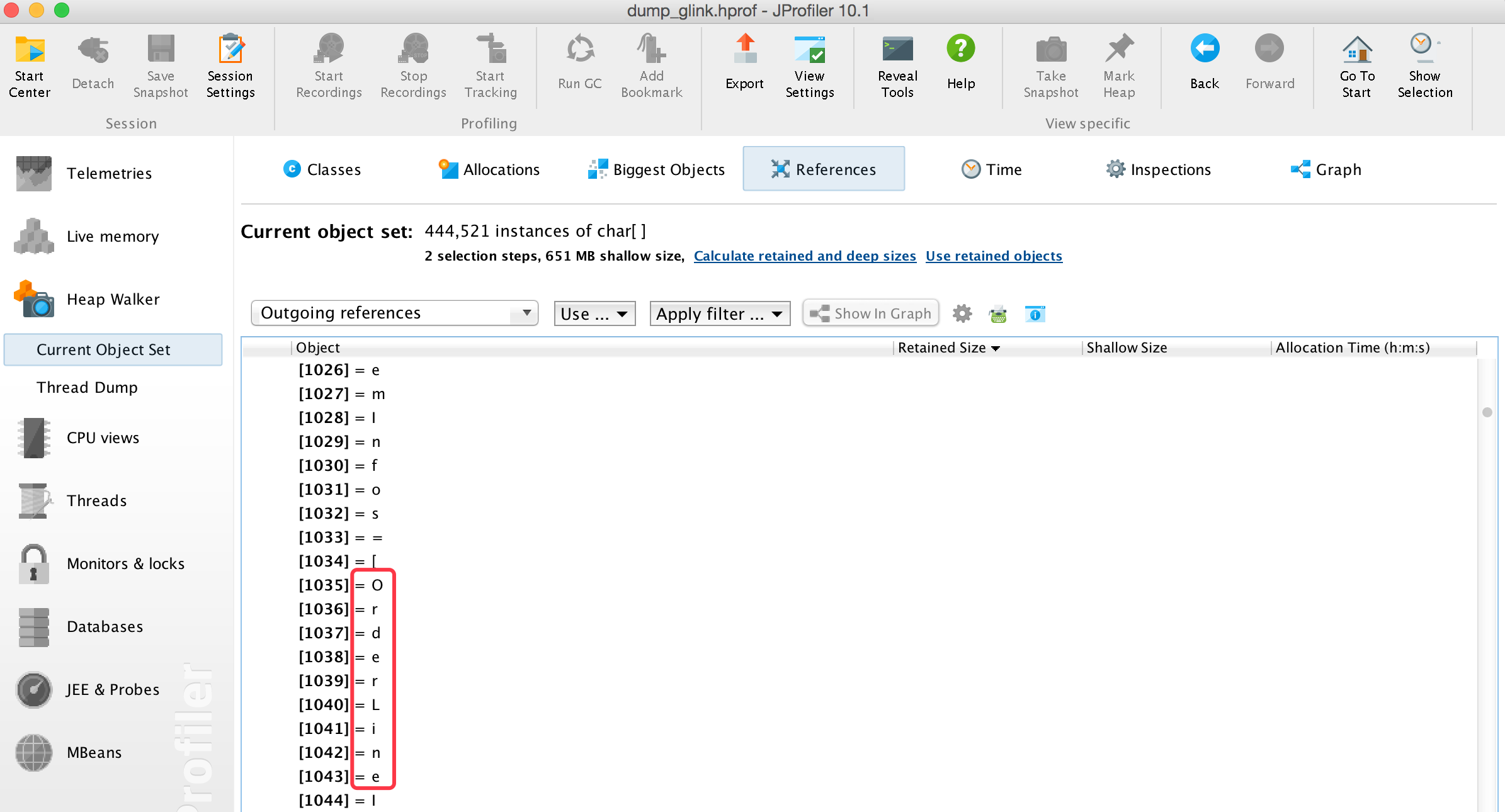
此处可以看到其中有一些业务数据的记录,另外其内存数据中还有部分公司内部任务中心的一些任务信息(此处就不截图出来了),于是我们隐隐感觉到是不是任务平台做了什么事情,比如收集日志什么的,我们继续查看其引用情况:
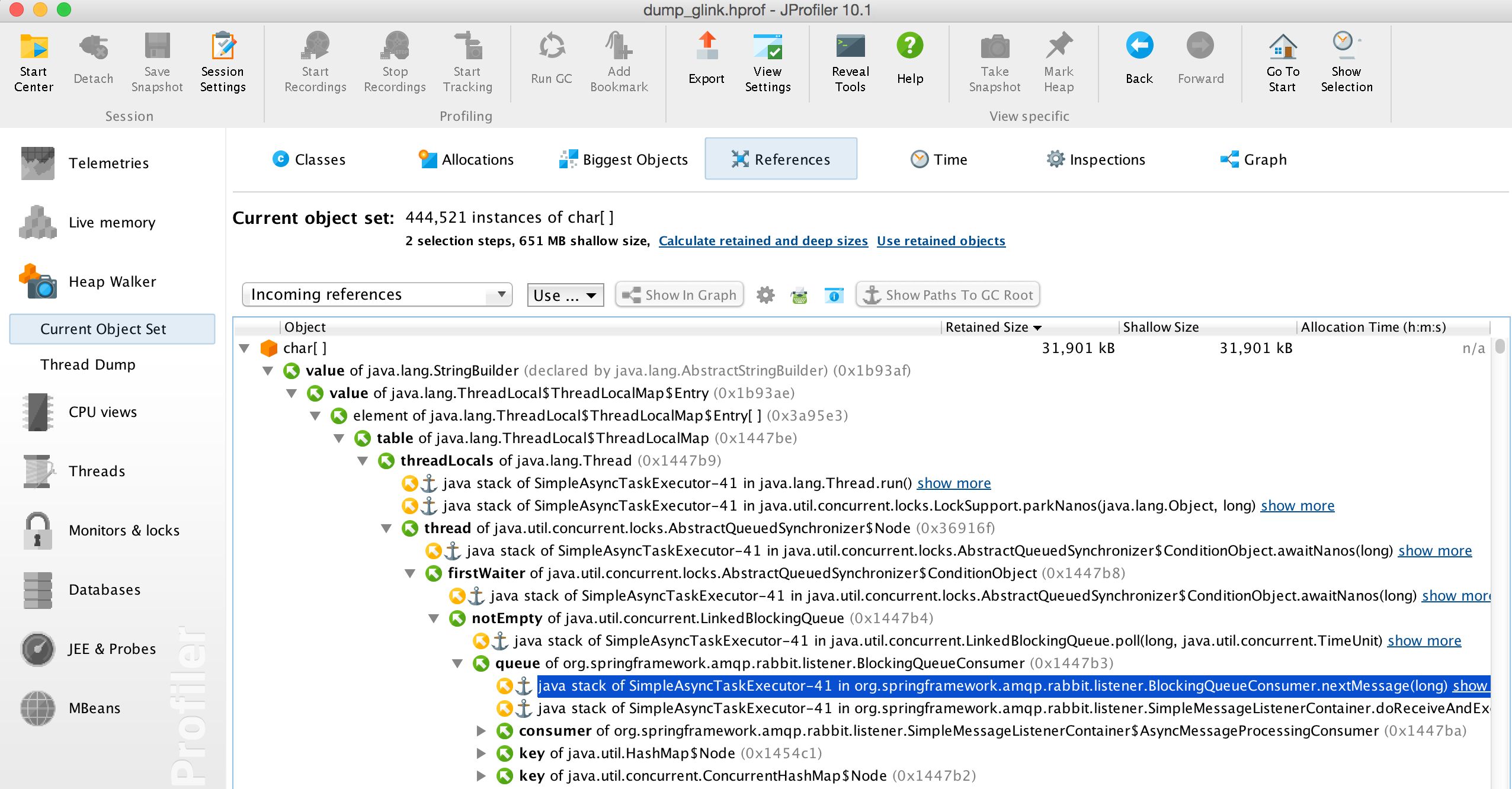
看到此处的rabbit基本可以断定了就是任务中心client的引用,项目中其他地方并没有用到rabbit,于是我们找到任务中心的维护人员进行询问,他们的答案是不会去收集应用的日志的(我们心里的答案也是这,又不是日志平台的client,任务中心团队不会做这么傻的事),然而我们在char[]中的确看到的都是任务平台的信息这是怎么回事?于是我们查看任务平台客户端的源码及对外的api,看看能有什么线索,最终锁定了一个问题,任务平台客户端使用了线程池,并且默认的线程池中线程最多为100(这个是有些坑,简单说明,任务中心是通过queue实现的,服务端发送任务消息,client收到后消费)。
我们再看到截图中的线程,隐隐也是任务中心client的线程池中的线程,于是我们进一步查找到底哪里才会使用char[],并且会有业务数据,查看全局代码后我们发现对于应用中任务消息的处理器并没有直接使用char[],组内一位同学提醒是不是使用log4j打日志处理不当的原因,想一想就目前现状而言,这种说法说的通,于是我们在每一个任务处理器中查看日志上有没有大对象的输出,果然找到了一些(订单、库存等....)。
private List<AmazonOrderInfo> getAmazonOrderNotInLocal(CustomerSalesChannelVO channel) { List<AmazonOrderInfo> amazonOrderInfoList = new ArrayList<>(); try { Date nowTime = new Date(); Date toTime = new Date(nowTime.getTime() - 121000); Date fromTime = new Date(nowTime.getTime() - 720000); amazonOrderInfoList = amazonOrderService.getAmazonOrderInfoNotInLocal(channel, fromTime, toTime); BizLogger.info("get amazon new order when amazon inventory feedback, result : " + amazonOrderInfoList); } catch (Exception e) { BizLogger.syserror("getAmazonOrderNotInLocal error,", e); } return amazonOrderInfoList; } //获取本地amazon创建失败的平台订单暂用的库存量 private List<AmazonOrderItemVO> getAmazonErrorOrderInLocal(String customerCode) { AmazonOrderSO so = new AmazonOrderSO(); so.setCustomerCode(customerCode); so.setStatus(AmazonOrderStatus.ERROR); List<AmazonOrderItemVO> amazonOrderItemVOList = amazonOrderService.getAmazonOrderItemVOList(so); BizLogger.info("get amazon error order item in local when amazon inventory feedback, result : " + amazonOrderItemVOList); return amazonOrderService.getAmazonOrderItemVOList(so); }
if (CollectionUtils.isNotEmpty(inventoryAgeVOList)) { BizLogger.info("send inventoryAge message." + inventoryAgeVOList); sendInventoryAgeSyncMessage(asnVO.getCustomerCode(), inventoryAgeVOList); }
于是我们查阅相关资料了解到log4j会将当前线程中被打印的最长记录的大小进行缓存,至此该问题已经说得通了。
由于任务中心的客户端启用了默认最大线程数为100的线程池,这些线程用来消费服务端发送过来的任务消息,该业务应用中配置很多关于库存、订单的相应任务,在这些具体任务消息的处理器中存在一定的大对象日志输出。由于线程是用线程池维护,每次执行完并不会被销毁掉,因此会存在大量的缓存区域。
这样也就能回答我们最初设想的第二个问题:测试环境、UAT环境为何从未有这样的情况,差别在哪?差别有四个地方:
- 系统环境的内存大小及虚机版本。
- 订单数据或是库存数据量的差异。
- 测试环境和UAT环境我们并不会配置很多的job,更多的是测试完就结束。
- 应用重启的频率不同,测试环境较为频繁。
最终处理方案:
(1)将任务中心客户端消费任务消息的线程池的最大线程数按照应用的实际情况改为10。
(2)去除对大对象的日志输出。
同时将任务中心客户端对于默认线程池的最大线程数设置的不合理性进行反馈,避免同样的事情发生在其他项目组。
总结:
1、当low memory被耗尽时,系统会kill掉不会影响自身稳定运行的用户进程。
2、应用上线程池的最大线程数的设置需要根据机器环境及应用本身进行合理设置,尤其要注意依赖消息实现的三方工具包中的线程次设置,避免被其引用的对象使用过量的缓存等。
3、在组内会议中明确,任务处理器中不允许有大对象的日志输出。

