概述
raft有和多种语言实现,其中在go语言中,etcd的实现是公认的典范,本文就是从源码级别探索etcd的raft是如何实现的,这样可以让我们一步一步了解raft论文是如何实现为一个工程的。
注:不清楚raft是什么的可以先去看我的另一篇文章https://my.oschina.net/fileoptions/blog/883497
例子
etcd将raft单独抽象、实现为一个模块,同时也为raft模块提供了一个基本例子,在etcd源码中,它就是contrib/raftexample,进到该目录下,我们可以首先看README,里面已经有非常详细的例子使用方法了,我这里就再赘述一次。
首先,我们在build之后,在目录下会产生一个raftexample的可执行文件,此时可以使用如下命令启动一个raft实例(single-member cluster):
raftexample --id 1 --cluster http://127.0.0.1:12379 --port 12380
上面这条命令意思是,启动了一个raft实例的kv存储引擎,id选项用于执行本raft实例的id,cluster选项执行集群的成员地址信息,port选项指定kv存储引擎的服务端口。
启动成功之后,此时我们可以向存储引擎存储一个值:
curl -L http://127.0.0.1:12380/my-key -XPUT -d hello
然后我们将其取出来验证一下:
curl -L http://127.0.0.1:12380/my-key
如果我们想启动一个本地集群,那么首先我们先安装goreman(自己google了解吧),然后直接在目录下执行:
goreman start
goreman会使用Procfile文件定义的信息启动一个集群版本的raft和kv存储,配置如下:
raftexample1: ./raftexample --id 1 --cluster http://127.0.0.1:12379,http://127.0.0.1:22379,http://127.0.0.1:32379 --port 12380 raftexample2: ./raftexample --id 2 --cluster http://127.0.0.1:12379,http://127.0.0.1:22379,http://127.0.0.1:32379 --port 22380 raftexample3: ./raftexample --id 3 --cluster http://127.0.0.1:12379,http://127.0.0.1:22379,http://127.0.0.1:32379 --port 32380
此时,我们可以随机向集群中的三个成员中的任意一个发送存储指令,raft会保证存储值的一致性,同样我们也可以随机从任何一个成员中读取。
例子中还包括了raft容错测试和集群成员变更测试,本文不再赘述。
raftexample入口main代码如下:
func main() { // 解析集群地址,包括自己 cluster := flag.String("cluster", "http://127.0.0.1:9021", "comma separated cluster peers") // 本节点的id id := flag.Int("id", 1, "node ID") // 应用端口 kvport := flag.Int("port", 9121, "key-value server port") // 是否是加入一个已存在的集群 join := flag.Bool("join", false, "join an existing cluster") flag.Parse() // 用于提议的channel proposeC := make(chan string) defer close(proposeC) // 用于配置变更的channel confChangeC := make(chan raftpb.ConfChange) defer close(confChangeC) // raft provides a commit stream for the proposals from the http api var kvs *kvstore // 应用提供的获取snapshot的函数(获取应用状态机的快照) getSnapshot := func() ([]byte, error) { return kvs.getSnapshot() } // 创建raft实例,RaftNode是根据应用自身进行定义的数据结构 commitC, errorC, snapshotterReady := newRaftNode(*id, strings.Split(*cluster, ","), *join, getSnapshot, proposeC, confChangeC) // 创建kvstore kvs = newKVStore(<-snapshotterReady, proposeC, commitC, errorC) // 启动http服务,用于处理存储请求 serveHttpKVAPI(kvs, *kvport, confChangeC, errorC) }
kv存储引擎
上面代码中,首先定义了一个kv存储kvstore,其具体实现如下:
// a key-value store backed by raft type kvstore struct { proposeC chan<- string // channel for proposing updates mu sync.RWMutex // 读写锁,用于在产生快照的时候禁止写 kvStore map[string]string // current committed key-value pairs snapshotter *snap.Snapshotter // 用于存取raft产生的snapshot } type kv struct { Key string Val string } func newKVStore(snapshotter *snap.Snapshotter, proposeC chan<- string, commitC <-chan *string, errorC <-chan error) *kvstore { s := &kvstore{proposeC: proposeC, kvStore: make(map[string]string), snapshotter: snapshotter} // replay log into key-value map s.readCommits(commitC, errorC) // read commits from raft into kvStore map until error // 启动goroutine监听commit channel go s.readCommits(commitC, errorC) return s } // 查找 func (s *kvstore) Lookup(key string) (string, bool) { // 上锁 s.mu.RLock() v, ok := s.kvStore[key] s.mu.RUnlock() return v, ok } // 提议一个kv值 func (s *kvstore) Propose(k string, v string) { var buf bytes.Buffer // 将kv序列化 if err := gob.NewEncoder(&buf).Encode(kv{k, v}); err != nil { log.Fatal(err) } // 进行提议 s.proposeC <- buf.String() } // 读一个raft commit上来的值,它会在一个单独的goroutine一直运行 func (s *kvstore) readCommits(commitC <-chan *string, errorC <-chan error) { // 遍历commit channel for data := range commitC { // data如果为nil就表示要加载snapshot if data == nil { // done replaying log; new data incoming OR signaled to load snapshot // 加载snapshot snapshot, err := s.snapshotter.Load() // 如果没有snapshot就返回 if err == snap.ErrNoSnapshot { return } // 如果是其他错误,就抛出异常 if err != nil && err != snap.ErrNoSnapshot { log.Panic(err) } // 打印出snapshot的一些元信息 log.Printf("loading snapshot at term %d and index %d", snapshot.Metadata.Term, snapshot.Metadata.Index) // 从snapshot上恢复kv if err := s.recoverFromSnapshot(snapshot.Data); err != nil { log.Panic(err) } continue } var dataKv kv dec := gob.NewDecoder(bytes.NewBufferString(*data)) // 解码commit上来的数据到dataKv中 if err := dec.Decode(&dataKv); err != nil { log.Fatalf("raftexample: could not decode message (%v)", err) } // 将kv值存储kv引擎 s.mu.Lock() s.kvStore[dataKv.Key] = dataKv.Val s.mu.Unlock() } // 如果error channel有错误 if err, ok := <-errorC; ok { log.Fatal(err) } } // 获取应用状态机的快照 func (s *kvstore) getSnapshot() ([]byte, error) { // 产生snapshaot的时候必须加上读写锁 s.mu.Lock() defer s.mu.Unlock() // 将kv序列化为Json return json.Marshal(s.kvStore) } // 从snapshot中恢复kv存储(恢复应用状态机) func (s *kvstore) recoverFromSnapshot(snapshot []byte) error { var store map[string]string // 对snapshot反序列化 if err := json.Unmarshal(snapshot, &store); err != nil { return err } s.mu.Lock() s.kvStore = store s.mu.Unlock() return nil }
上面的代码比较简单,和一般的kv存储相比而言,唯一的不同就是,现在的kv存在多个副本(抗容灾能力),多个副本使用raft协议保证一致性,其大致原理如下:
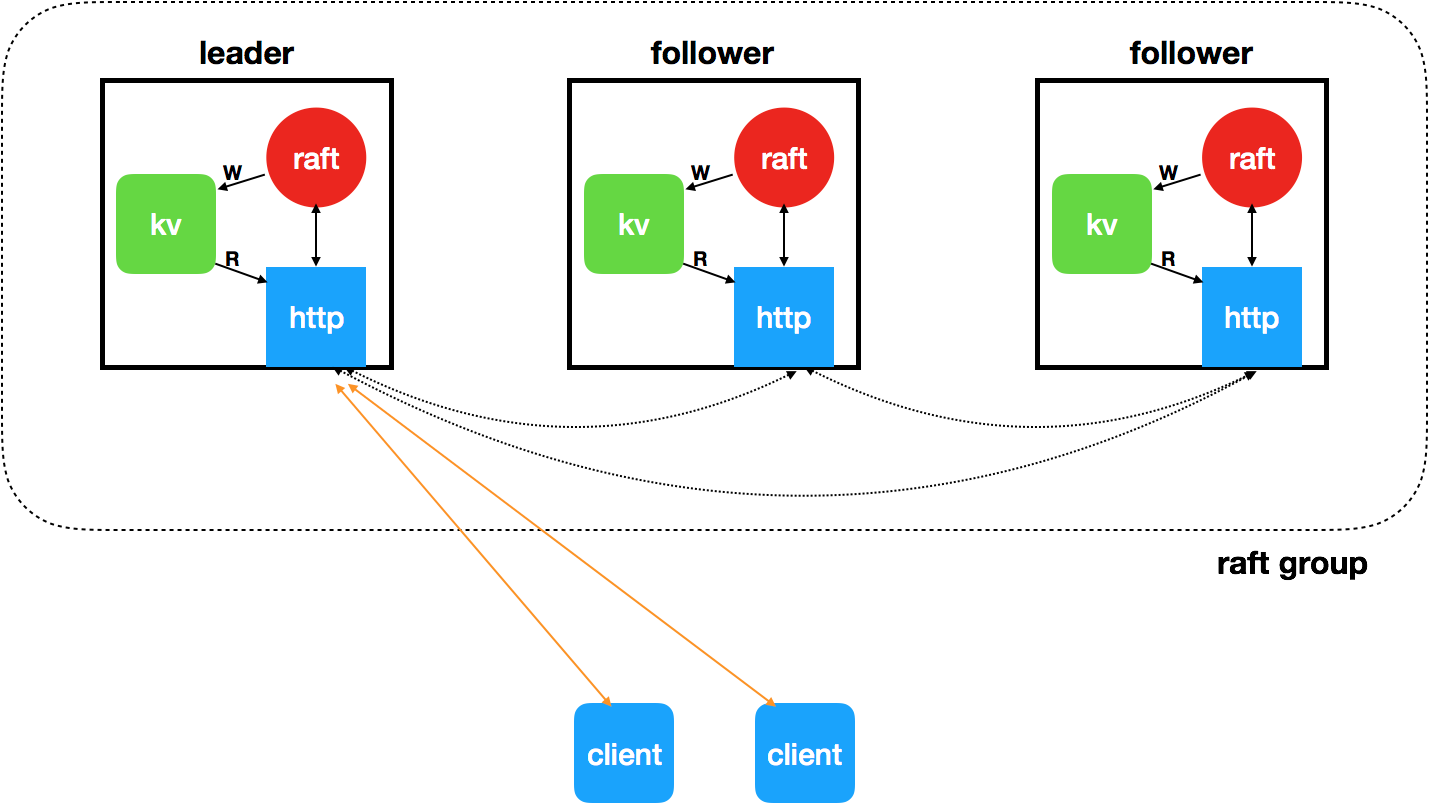
由于raft的实现比较复杂,如果将所有细节都写在同一片文章中会显得非常臃肿,因此我打算将其细分为一下几篇文章,以后周末只要有时间就至少写一篇(这件事情拖了很久了,草稿箱里还存了一大堆)。
本系列文章
1、etcd raft模块分析--kv存储引擎
2、etcd raft模块分析--raft snapshot
3、etcd raft模块分析--raft wal日志
4、etcd raft模块分析--raft node
5、etcd raft模块分析--raft 协议
6、etcd raft模块分析--raft transport
7、etcd raft模块分析--raft storage
8、etcd raft模块分析--raft progress

