欢迎点击「算法与编程之美」↑关注我们!
本文首发于微信公众号:"算法与编程之美",欢迎关注,及时了解更多此系列博客。
本系列博客我们将为大家介绍JavaWeb 大家可能遇到的各种烦人的中文乱码问题。虽然您可能已经知道了在某些情况下如何解决中文乱码的问题,但是您不一定知道为什么会产生中文乱码?很多时候了解问题产生的原因远比问题解决方案重要。我们将带领大家从Tomcat源码的角度为大家带来深入的分析,帮助您彻底的理解这些乱码产生的深层次原因。
1 问题描述
有两个 JSP 文件,第一个名为 input.jsp,内容非常简单,里面有一个form 表单,表单里面有一个名为 content 的输入框和一个按钮,表单提交给result.jsp处理。
<%@ page contentType="text/html;charset=UTF-8"language="java"%> <html> <head> <title>Title</title> </head> <body> <form action="result.jsp" method="post"> <input type="text"name="content"/> <input type="submit"value="send"/> </form> </body> </html>
第二个文件叫 result.jsp,接受 input.jsp 表单里面输入框的内容,显示在页面上。
<%@ page contentType="text/html;charset=UTF-8"language="java"%> <html> <head> <title>Title</title> </head> <body> <% String content =request.getParameter("content"); %> <p><%=content%></p> </body> </html>
上面的两个 JSP 文件,相信对大家都不会有问题,编写完成后开始部署运行,当我们访问http://localhost:8080/input.jsp,表单中输入“你好”,点击 submit 后,结果让我们很吃惊,我们竟然看到了一串我们人类并不能理解的字符“ä½ å¥½”。
2 源码分析
为什么会出现上面的中文乱码情况呢?相信这也是大家刚开始做 JavaWeb 开发的时候遇到的最多的问题之一。可能现在的您已经知道了如何解决上面的中文乱码问题,但是如果面试官问您,为什么会出现这种中文乱码?您能回答出来吗?
result.jsp 中只有一行代码,那么显然问题就是出现在这儿。
request.getParameter("content")这行代码到底发生了什么?
让我们一点点的来看一看。
2.1RequestFacade分析
首先我们需要搞明白的一个问题是这个 request 变量是什么类型?然后才能定位到它的 getParameter()方法里面去。难道不是吗?
有些同学说这不是很简单吗,request 变量的类型就是 ServletRequest。
请大家思考这种说法对吗?这句话说了相当于白说,原因很简单,因为 ServletRequest 是一个接口,接口里面并没有实现代码,所以你还是找不到 getParameter()方法的代码。
如何获得 request 对象的真实类型?
接下来给大家介绍的就是一个非常重要的技能,我们可以通过断点调试的方法来获得。
在该行代码上加上断点,然后执行调试。当代码运行到该断点时,将鼠标放在request 上,就会出现下图: 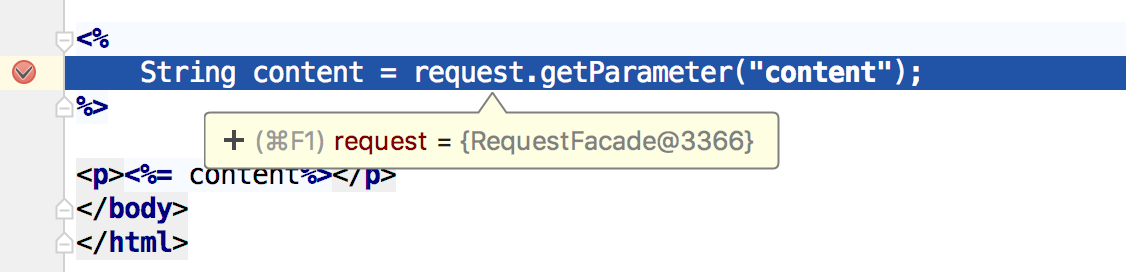
相信大家现在应该能够确认 request 对象的真实类型是什么了,那就是 RequestFacade,所以我们需要看的代码是 RequestFacade 类的 getParameter()方法,如下所示:
RequestFacade @Override public String getParameter(String name) { if (request == null) { throw new IllegalStateException( sm.getString("requestFacade.nullRequest")); } if (Globals.IS_SECURITY_ENABLED){ return AccessController.doPrivileged( new GetParameterPrivilegedAction(name)); } else { return request.getParameter(name); } }
注意,此时的 request对象和刚开始遇到的那个 request 不是同一个类型。
此处的 request 类型为org.apache.catalina.connector.Request, 因此我们接下来将分析这个 request 下的 getParameter()方法。
2.2 connector.Request 分析
org.apache.catalina.connector.Request @Override public String getParameter(String name) { if (!parametersParsed) { parseParameters(); } return coyoteRequest.getParameters().getParameter(name); }
从上面的代码我们可以看到是先解析参数,解析成功后直接从 parameters 属性中直接获得name 值。
parseParameters()方法中代码较多,我们只贴出和我们问题相关的代码。
String enc = getCharacterEncoding(); boolean useBodyEncodingForURI = connector.getUseBodyEncodingForURI(); if (enc != null) { parameters.setEncoding(enc); if (useBodyEncodingForURI) { parameters.setQueryStringEncoding(enc); } } else { parameters.setEncoding (org.apache.coyote.Constants.DEFAULT_CHARACTER_ENCODING); if (useBodyEncodingForURI) { parameters.setQueryStringEncoding (org.apache.coyote.Constants.DEFAULT_CHARACTER_ENCODING); } }
和我们相关的代码实际上就这些,两个步骤:
首先获得 enc 变量的值,如果不为空的话,就设置编码为 enc, 这里我们看到它同时也设置了 queryString的编码格式。
如果为空的话,直接将编码格式设置为一个常量,而这个常量的值为:
public final class Constants { public static final String DEFAULT_CHARACTER_ENCODING="ISO-8859-1"; }
其实现在到这儿,貌似问题已经迎刃而解了,但是我们还有一个非常关键的问题:
这个 enc 变量的值到底是什么呢?
2.3 enc 是什么
首先我们来看看:
@Override public String getCharacterEncoding() { String result = coyoteRequest.getCharacterEncoding(); if (result == null) { Context context = getContext(); if (context != null) { result = context.getRequestCharacterEncoding(); } } return result; }
从以上代码,我们可以看到,检查了两个地方的编码,一个是 coyoteRequest 对象,另外一个是 context 中。
(1)coyoteRequest 中发生了什么
public String getCharacterEncoding() { if (charEncoding != null) { return charEncoding; } charEncoding = getCharsetFromContentType(getContentType()); return charEncoding; } public String getContentType() { contentType(); if ((contentTypeMB == null) || contentTypeMB.isNull()) { return null; } return contentTypeMB.toString(); } public MessageBytes contentType() { if (contentTypeMB == null) { contentTypeMB = headers.getValue("content-type"); } return contentTypeMB; } private static String getCharsetFromContentType(String contentType) { if (contentType == null) { return (null); } int start = contentType.indexOf("charset="); if (start < 0) { return (null); } String encoding =contentType.substring(start + 8); int end = encoding.indexOf(';'); if (end >= 0) { encoding = encoding.substring(0, end); } encoding = encoding.trim(); if ((encoding.length() > 2) &&(encoding.startsWith("\"")) && (encoding.endsWith("\""))) { encoding = encoding.substring(1, encoding.length() - 1); } return (encoding.trim()); }
从上面四段代码我们可以看到,它做的工作实际上是从 HTTP 头部的 content-type 中去检查有没有设置charset,如果有的话,则设置 enc 为该编码。
(2)context 中发生了什么
StandardContext @Override public String getRequestCharacterEncoding() { return requestEncoding; }
context指的是当前网站的上下文容器,那么这个requestEncoding 属性又是什么时候设置的呢?
在 Servlet 4.0中,我们可以直接设置属性request-character-encoding的值,注意该属性仅在4.0中起作用。
<web-app xmlns="http://xmlns.jcp.org/xml/ns/javaee" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://xmlns.jcp.org/xml/ns/javaee http://xmlns.jcp.org/xml/ns/javaee/web-app_4_0.xsd" version="4.0"> <request-character-encoding>UTF-8</request-character-encoding> </web-app>
2.4 编码设置流程总结
整个的流程我们已经分析完了,最后我们来总结一下,Tomcat在处理 request.getParameter()到底发生了什么。下面两张图将解释一切。
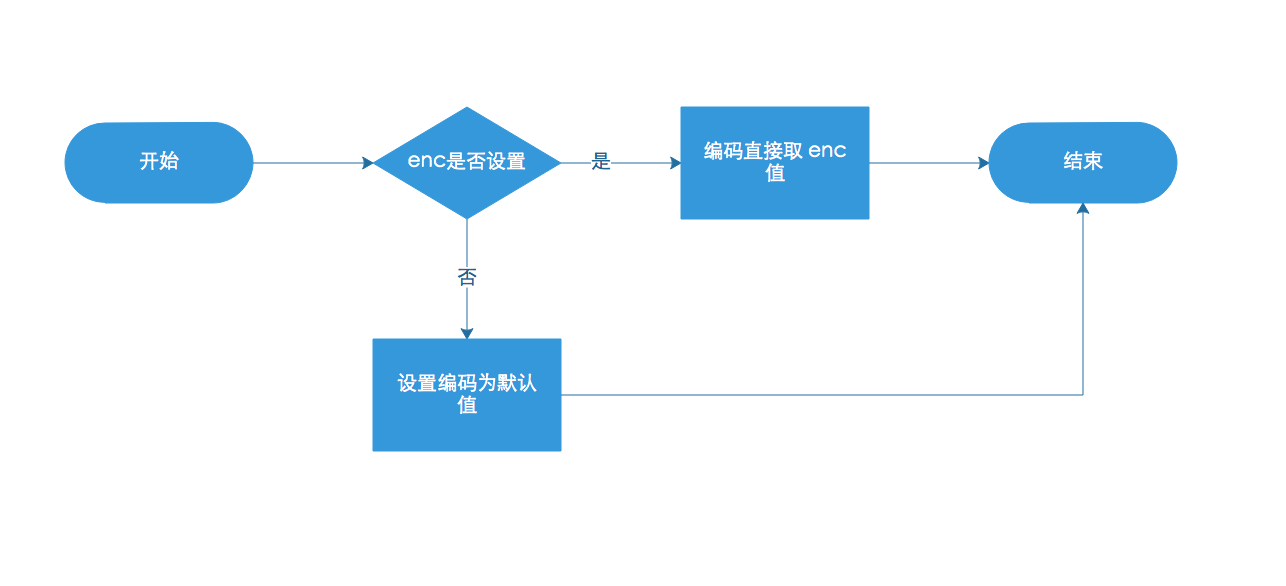

首先判断 enc 变量是否设置,如果未设置,则将其设置为默认值 ISO-8859-1。
enc 变量的设置流程如下:
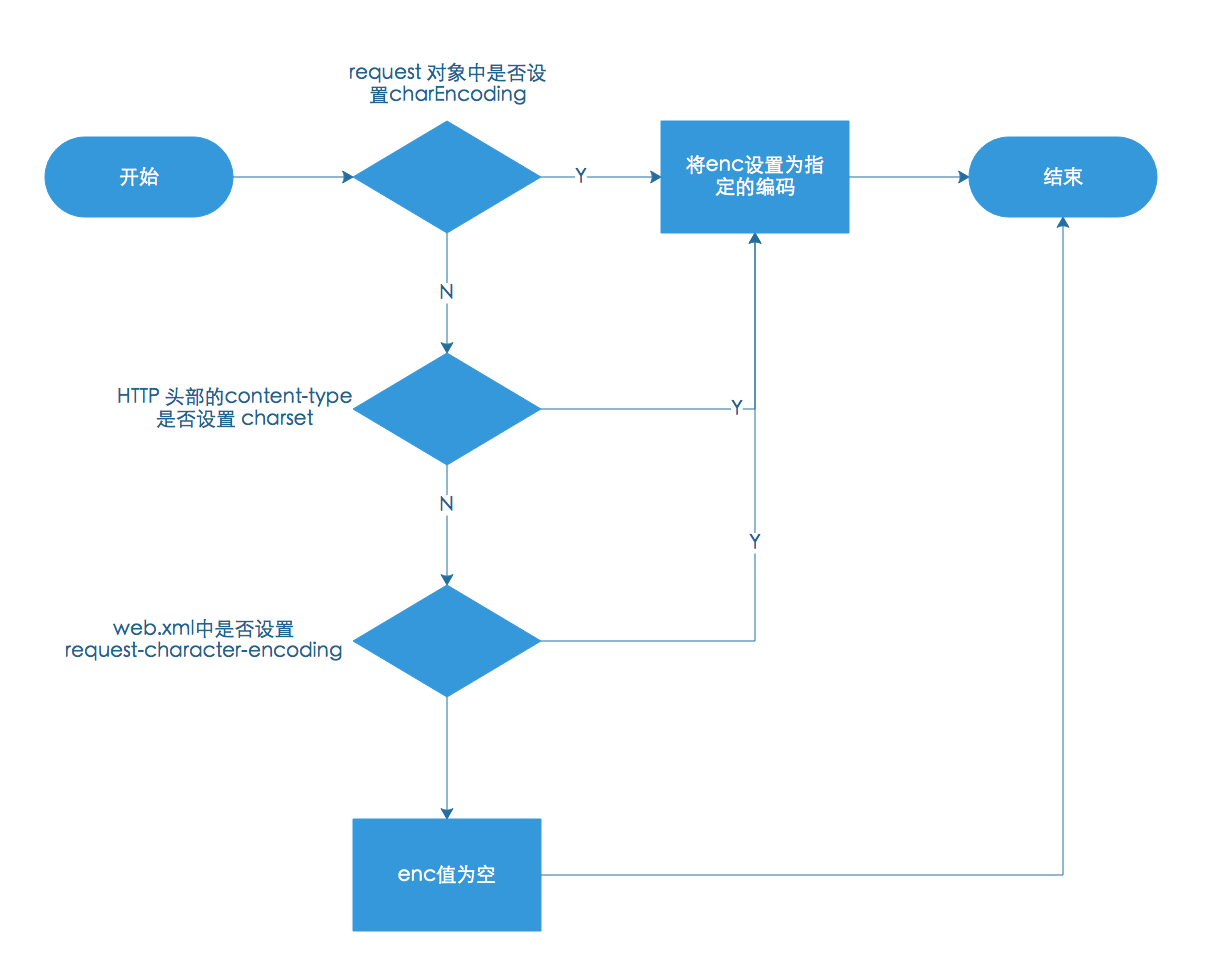
第一步判断 request 对象是否设置了 charEncoding,相信这也是大家平时在解决乱码问题中最常见的一种方式,即:
request.setCharacterEncoding("utf-8");
如果未设置则进行第二步,检查 HTTP 头部的 content-type 属性是否设置了 charset 值。熟悉 HTTP 协议的同学相信都应该知道:
Content-type:text/html;charset=utf-8
如果未设置则进行第三步,检查 context 容器中是否设置了requestEncoding 属性。所谓 context 容器指的是web.xml 中是否设置了 request-character-encoding 属性,这个属性仅在 Servlet4.0中起作用。
2.5 乱码产生原因
上面分析了这么多,貌似我们还没有解释为什么会出现乱码?

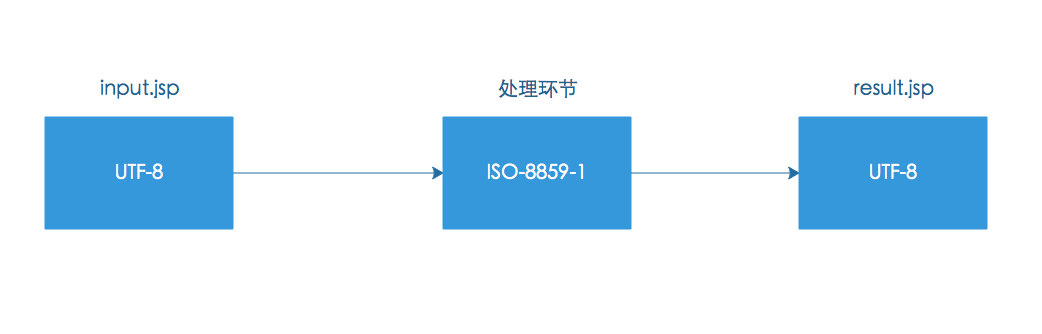
我们知道 input.jsp 和 result.jsp 的页面编码都是 UTF-8,在默认情况下,处理环节中的编码为:ISO-8859-1,从上图我们发现一左一右的编码都是 UTF-8,而中间的是ISO-8859-1,因此前后编码不一致,自然会出现乱码。
如何解决乱码?
通过§2.4我们可以发现,解决乱码我们有两种途径:
第一种方式是让 input.jsp 和 result.jsp 全部设置为:ISO-8859-1编码,这样三个环节的编码都变成了ISO-8859-1。
第二种方式是通过各种途径让中间的处理环节的编码变为 UTF-8。
有哪些途径呢?这些途径就是§2.4中如何设置 enc 变量的几种方式。
3 总结
本文从 Tomcat 源码的角度深入分析了在FORM表单中如果直接提交中文,而默认不做任何编码的设置,那么在结果页中将会出现中文乱码。最后总结了中文乱码出现的本质原因在于一头一尾和中间环节的编码不一致导致的。并给出了解决中文乱码的几种途径。如果你从源码的角度了解了为什么会出现乱码,以后遇到任何乱码的问题,在你面前将不再是问题。
欲知后事如何,请持续关注“算法与编程之美”微信公众号,及时了解更多精彩文章。


