Redis Cluster 故障发现和恢复总结
声明:本文转载自https://my.oschina.net/u/3777515/blog/1631888,转载目的在于传递更多信息,仅供学习交流之用。如有侵权行为,请联系我,我会及时删除。
1、故障发现
- 通过ping/pong消息实现故障发现:不需要Sentinel
- 跟Sentinel一样,有主观下线和客观下线
2、主观下线
定义:某个节点认为另一个节点不可用,“偏见”
主观下线流程:
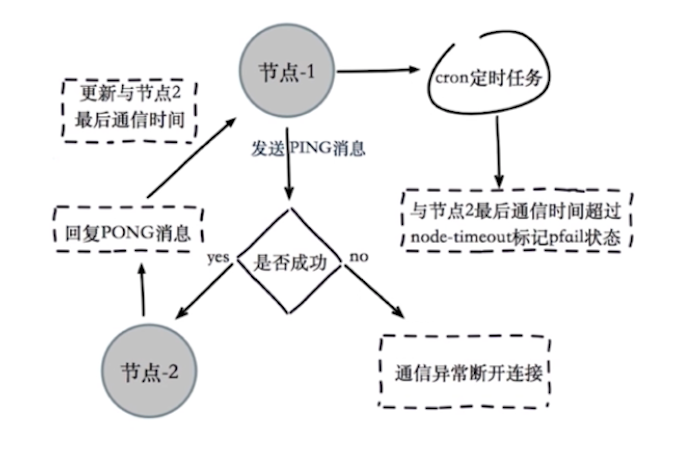
3、客观下线
定义:当半数以上持有槽的主节点都标记某节点主观下线
客观下线流程:
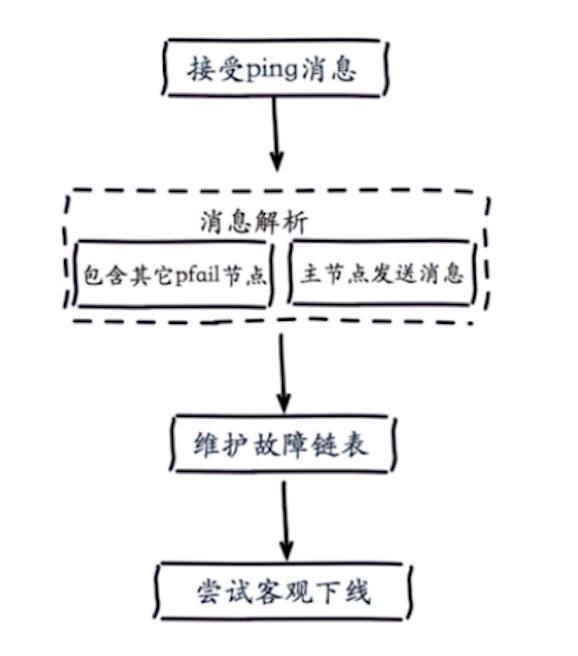
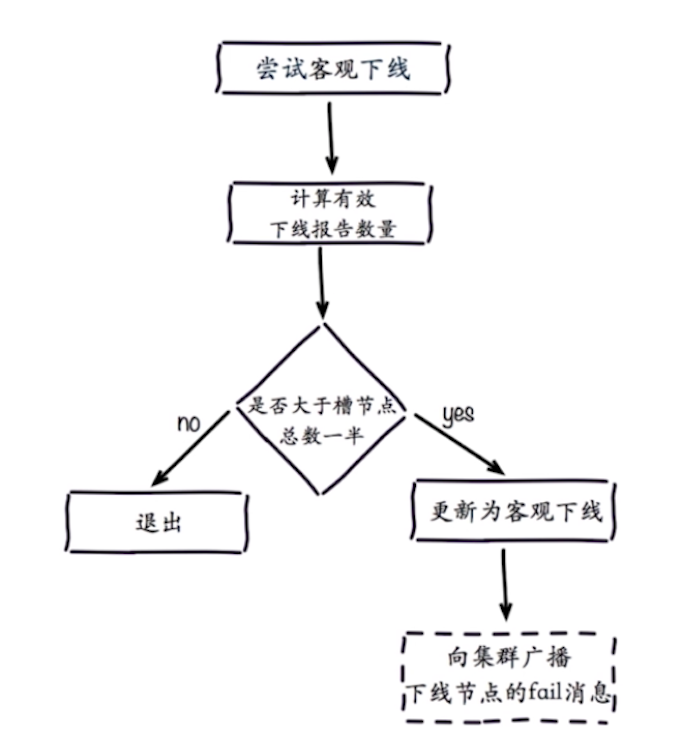
4、尝试客观下线
- 通知集群内所有节点标记故障节点为客观下线
- 通过故障节点的从节点触发故障转移流程
5、故障恢复
(1)资格检查
- 每个从节点检查与故障主节点的断线时间
- 超过 cluster-node-timeout * cluster-slave-validity-factor 取消资格。
- cluster-slave-validity-factor : 默认是10
(2)准备选举时间
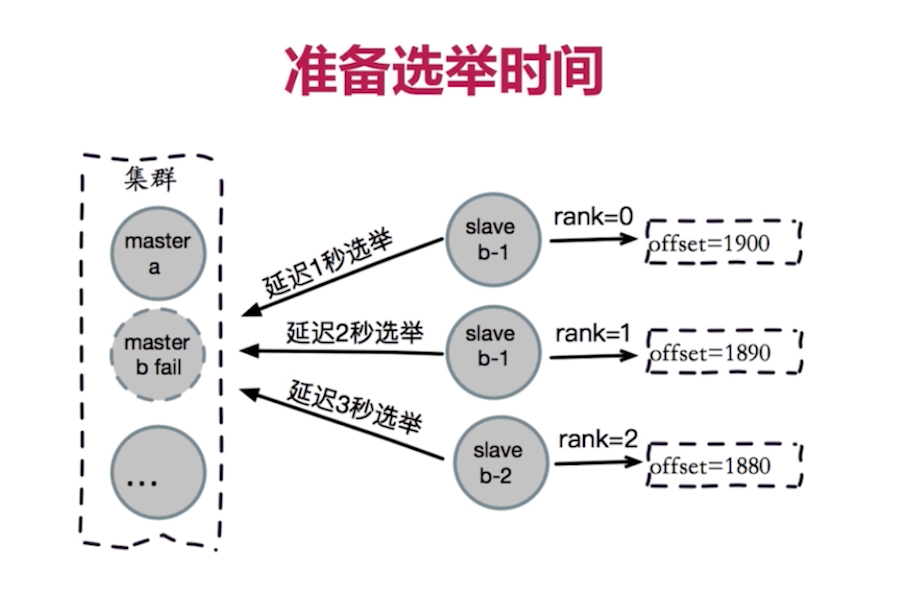
(3)选举投票
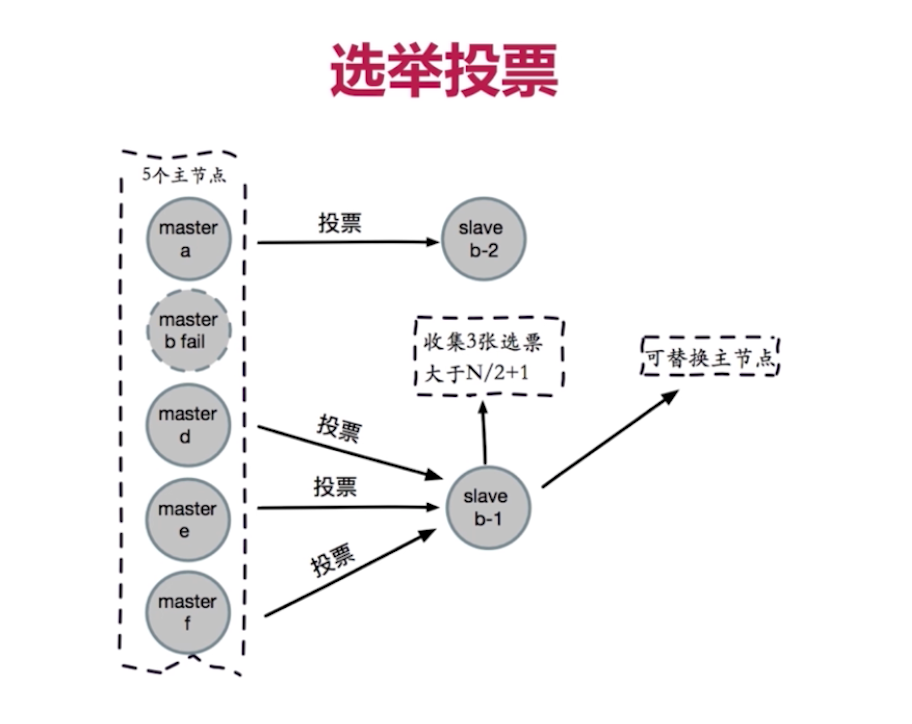
(4)替换主节点
- 当前从节点取消复制变为主节点(slaveof no one)
- 执行clusterDelSlot撤销故障主节点负责的槽,并执行clusterAddSlot把这些槽分配给自己。
- 向集群广播自己的pong消息,表明已经替换了故障从节点
6、故障演练
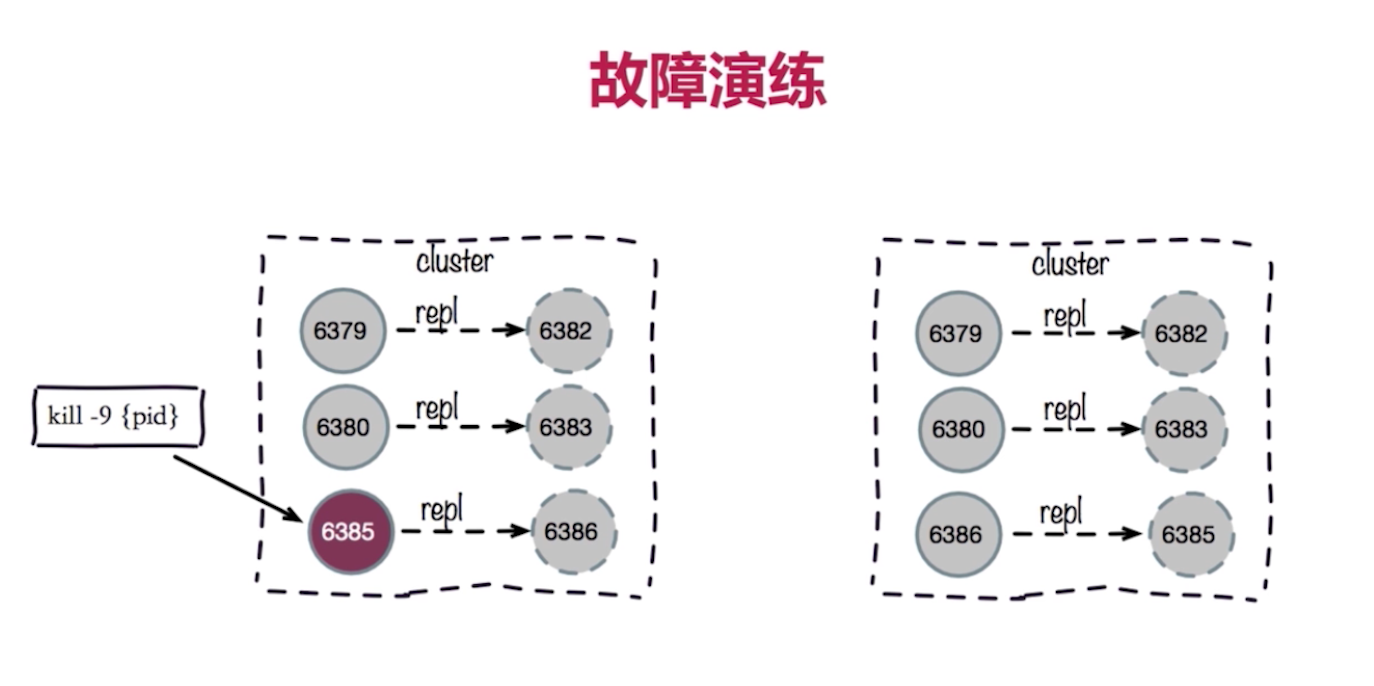
7、具体步骤
- 执行kill -9 节点模拟拖机
- 观察客户端故障恢复时间
- 观察各个节点的日志

抱拳了,老铁!
本文发表于2018年03月08日 22:44
(c)注:本文转载自https://my.oschina.net/u/3777515/blog/1631888,转载目的在于传递更多信息,并不代表本网赞同其观点和对其真实性负责。如有侵权行为,请联系我们,我们会及时删除.
阅读 4593 讨论 0 喜欢 0
