在上文 hue(01)、Hue4.1的编译安装启动 中,我们完整的进行了Hue的源码下载编译安装,Hue的web控制台与Hdfs、Hive、Hbase等集成才能展现它的魅力。本文我们在Hue中集成hadoop的hdfs和yarn服务,然后使用Hue操作和监控hadoop集群。
一、环境准备
1.hadoop集群(hadoop2.8.2)
2.hue4.1服务
二、集成配置
注意:以下1-4同样需要在其他的hadoop集群的节点上操作
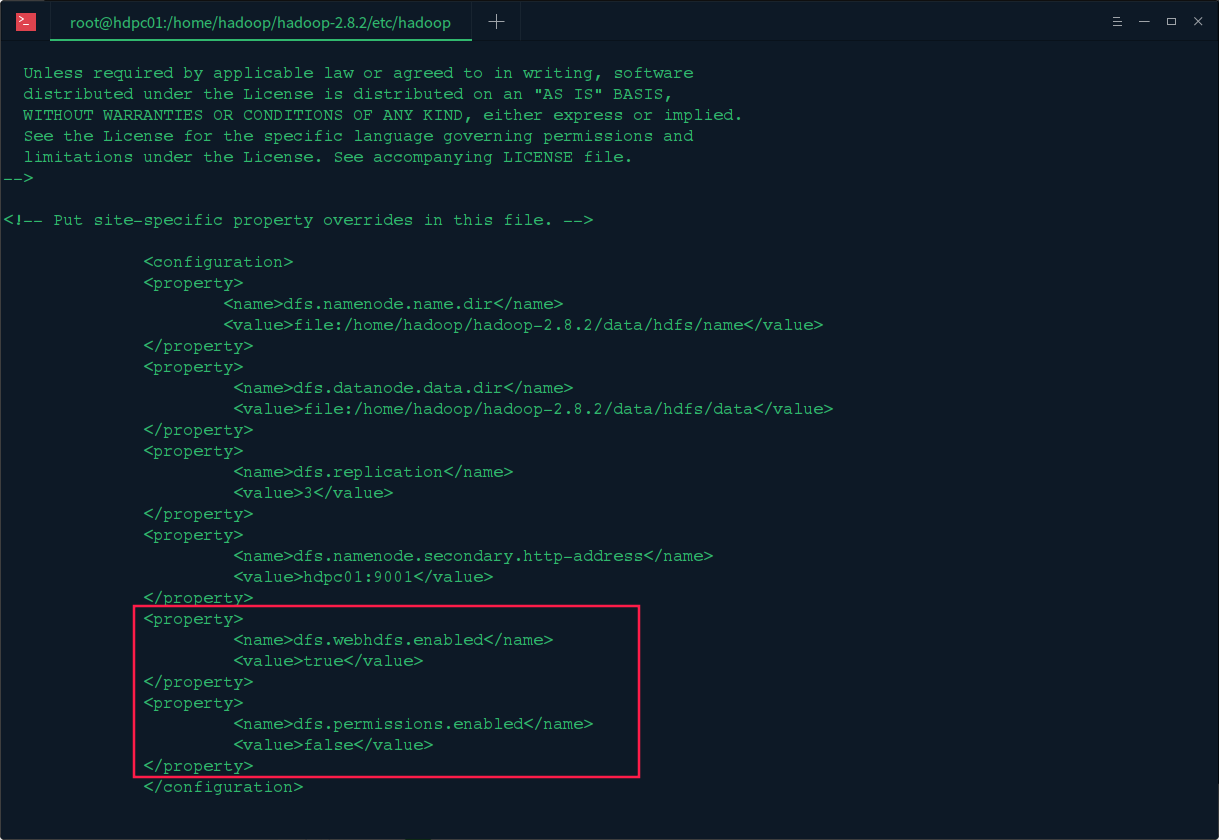
1.修改hadoopde的hdfs-site.xml文件
修改hadoop的/etc/hadoop/目录下的hdfs-site.xml文件,在文件中加入以下配置:
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
<property>
<name>dfs.permissions.enabled</name>
<value>false</value>
</property>
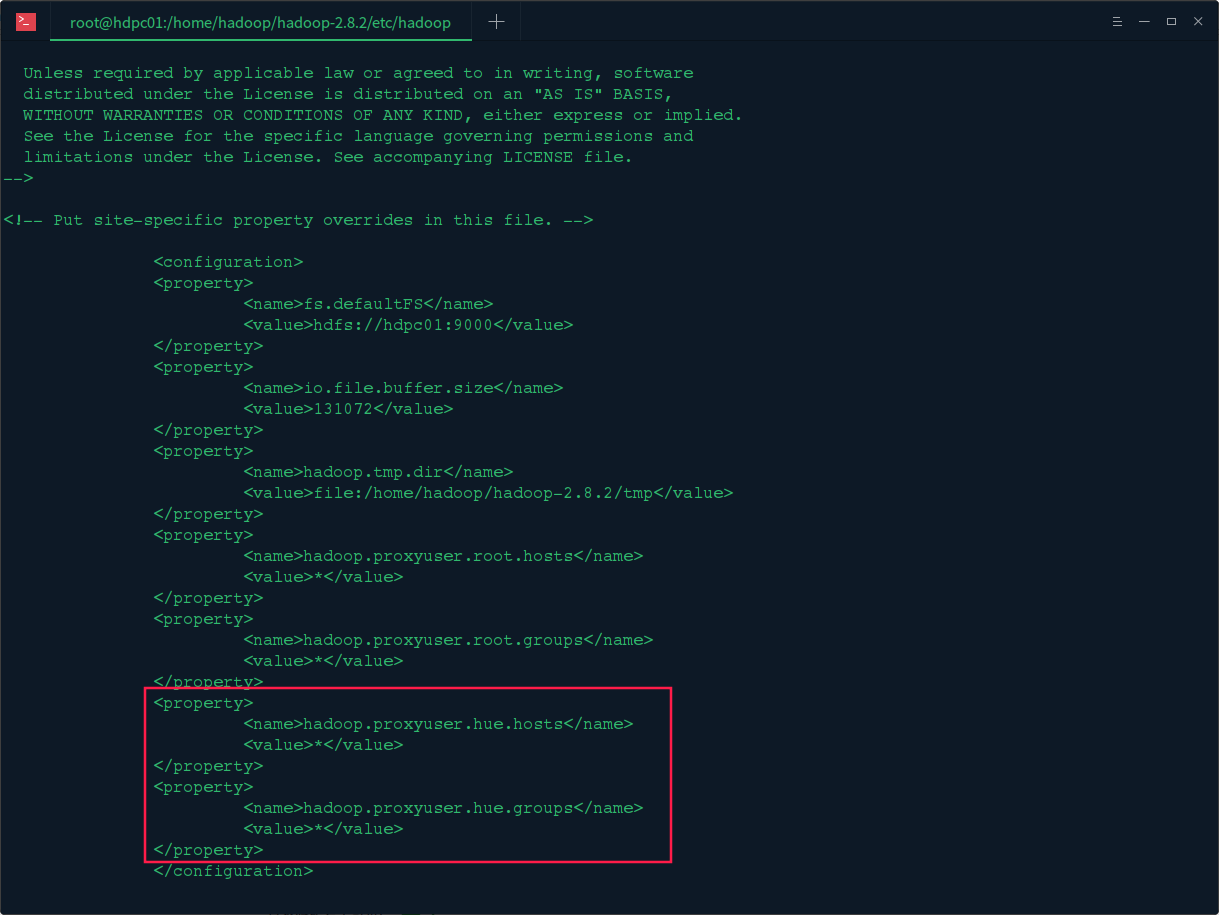
2.修改hadoopde的core-site.xml文件
修改hadoop的/etc/hadoop/目录下的core-site.xml文件,在文件中加入以下配置 :
<property>
<name>hadoop.proxyuser.hue.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.hue.groups</name>
<value>*</value>
</property>
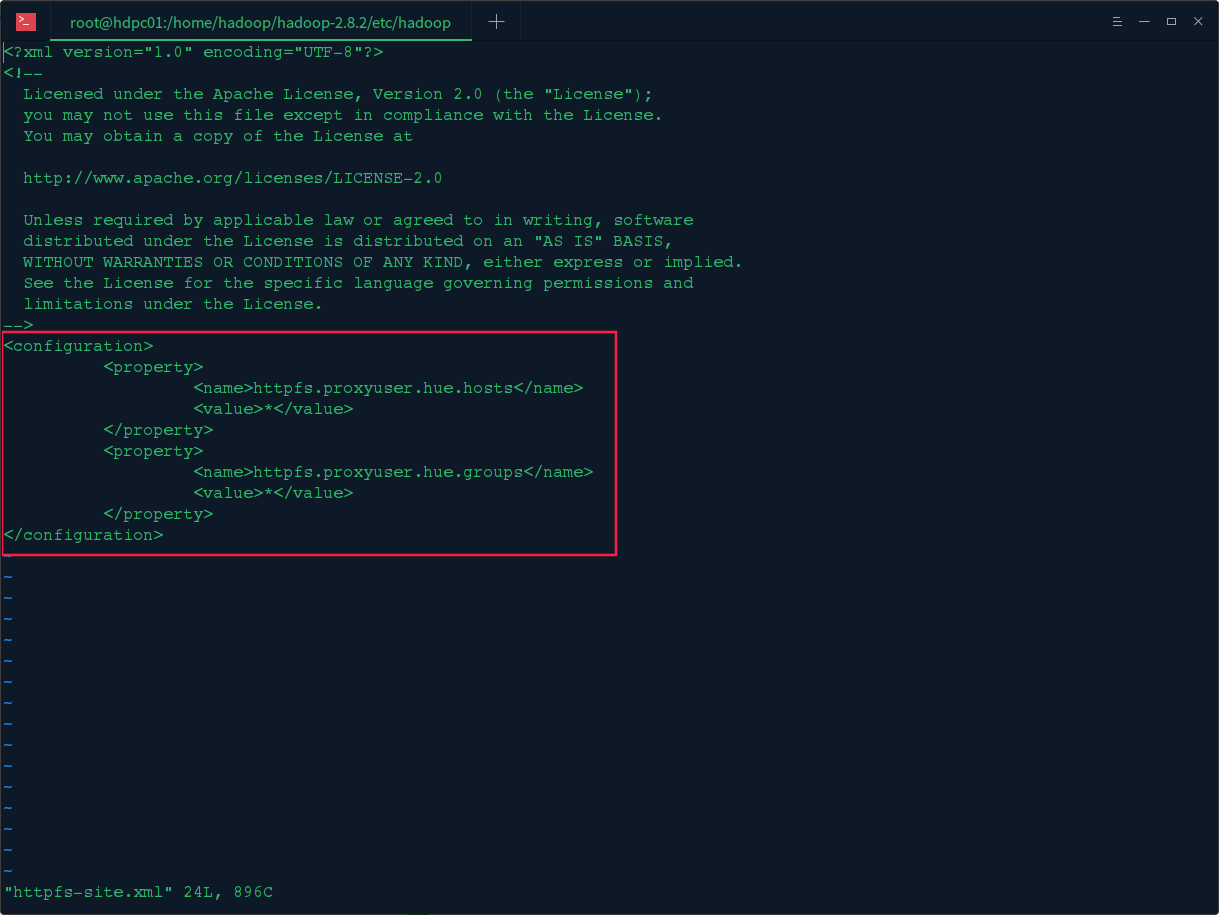
3.修改hadoopde的httpfs-site.xml文件
修改hadoop的/etc/hadoop/目录下的httpfs-site.xml文件,在文件中加入以下配置 :
<property>
<name>httpfs.proxyuser.hue.hosts</name>
<value>*</value>
</property>
<property>
<name>httpfs.proxyuser.hue.groups</name>
<value>*</value>
</property>
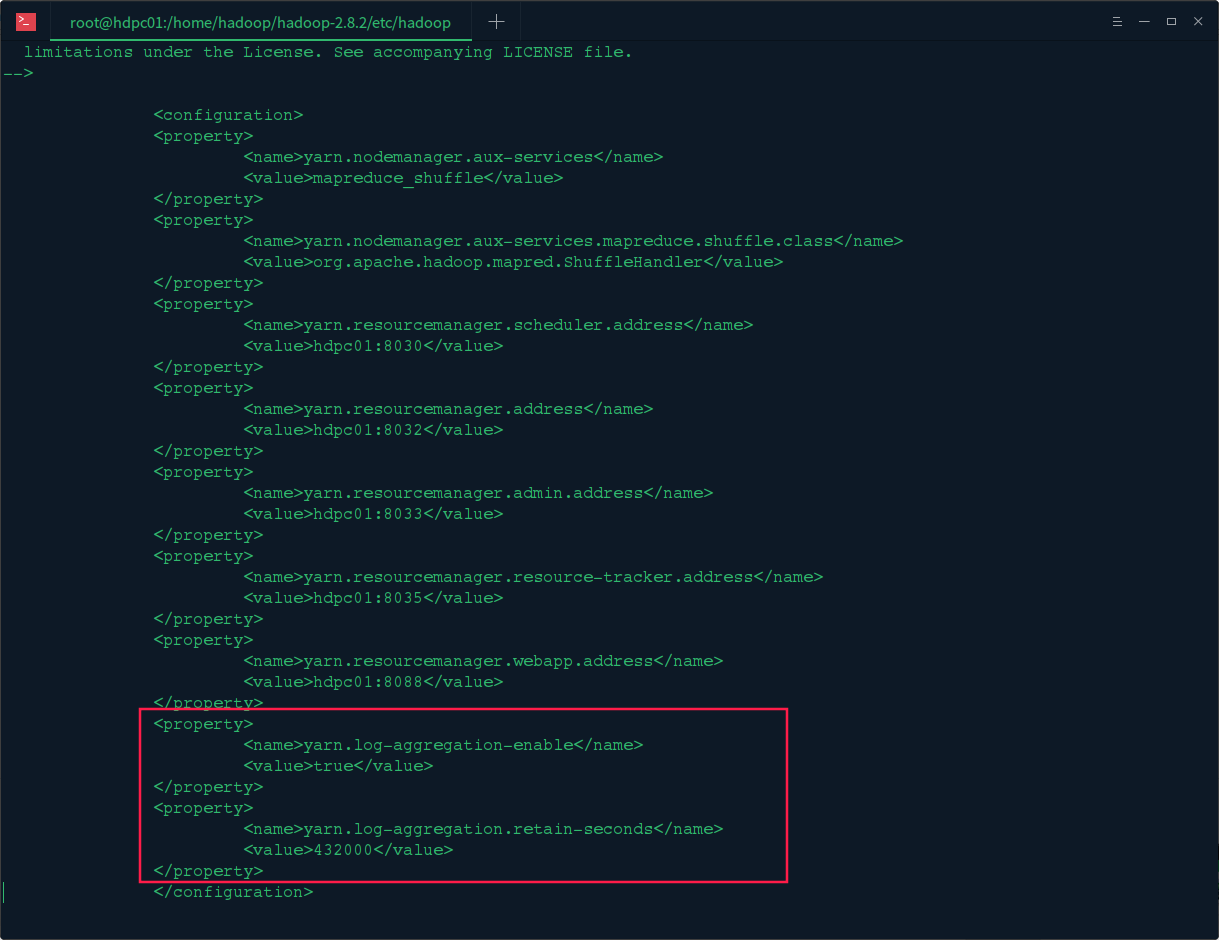
4.修改hadoopde的yarn-site.xml文件
修改hadoop的/etc/hadoop/目录下的yarn-site.xml文件,在文件中加入以下配置 :
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>432000</value>
</property>
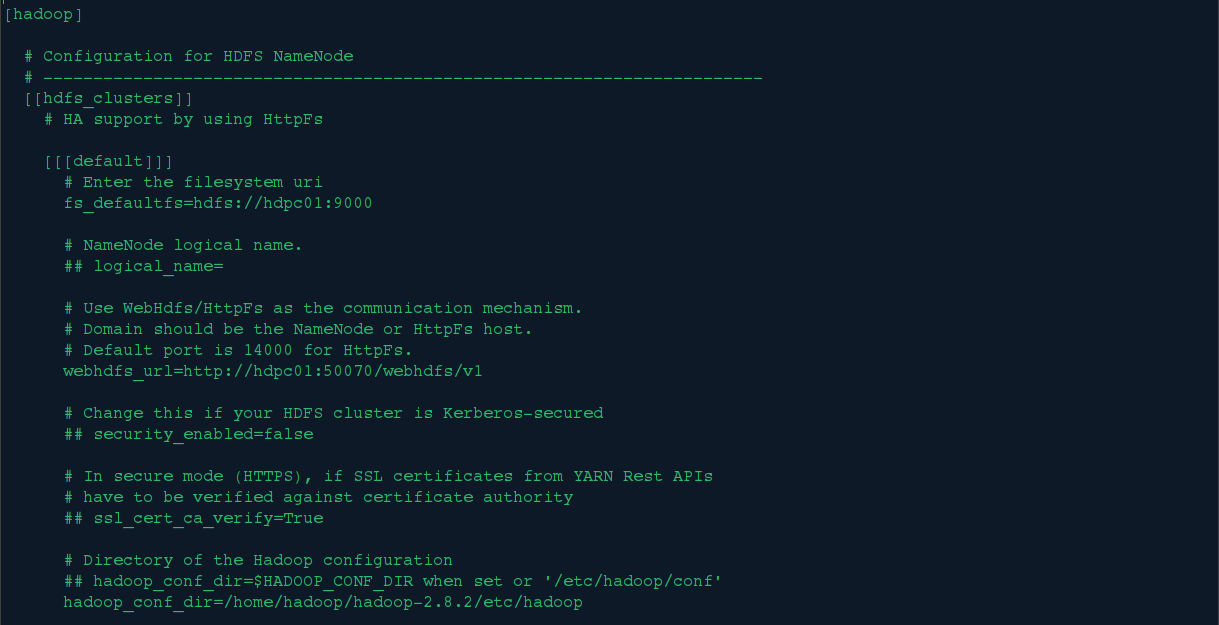
5.修改hue的pseudo-distributed.ini文件集成hdfs
修改hue的/desktop/conf/目录下的pseudo-distributed.ini文件,对hadoop集群的hdfs配置如下:
fs_defaultfs=hdfs://hdpc01:9000
webhdfs_url=http://hdpc01:50070/webhdfs/v1
hadoop_conf_dir=/home/hadoop/hadoop-2.8.2/etc/hadoop
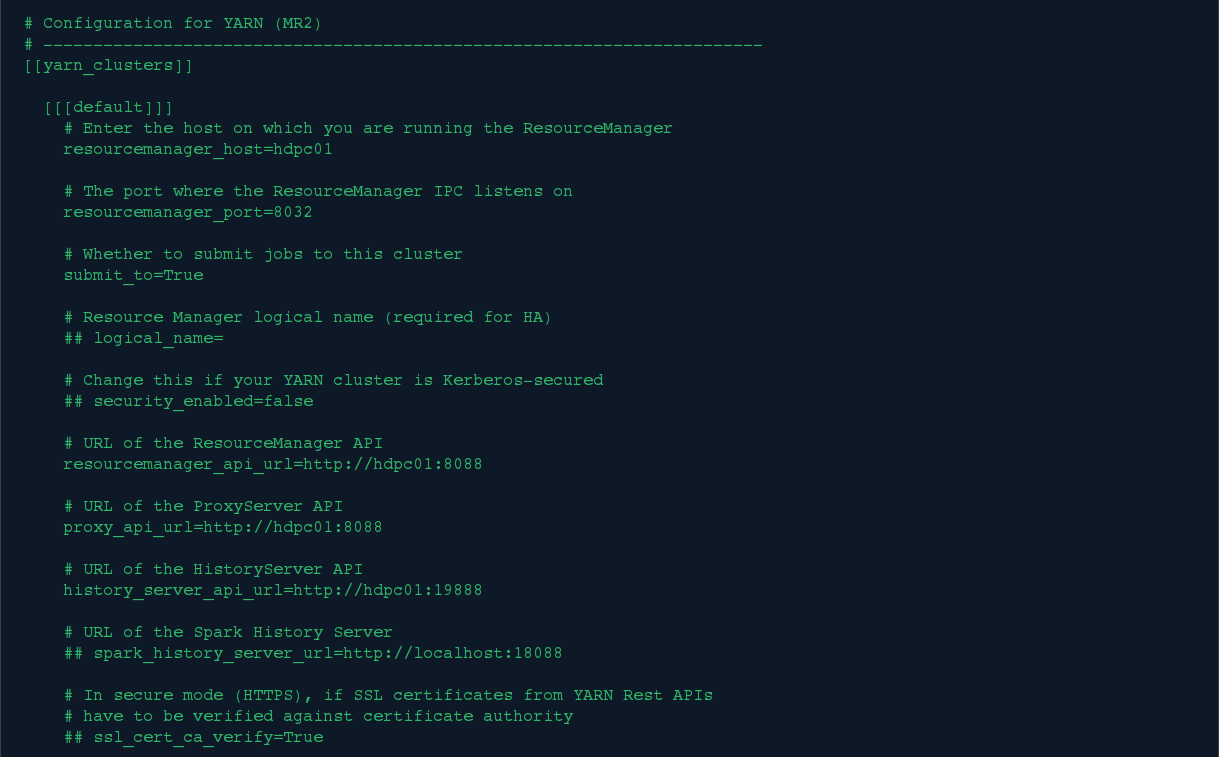
6.修改hue的pseudo-distributed.ini文件集成yarn
修改hue的/desktop/conf/目录下的pseudo-distributed.ini文件,对hadoop集群的yarn配置如下:
resourcemanager_host=hdpc01
resourcemanager_port=8032
submit_to=True
resourcemanager_api_url=http://hdpc01:8088
proxy_api_url=http://hdpc01:8088
history_server_api_url=http://hdpc01:19888
三、集成准备
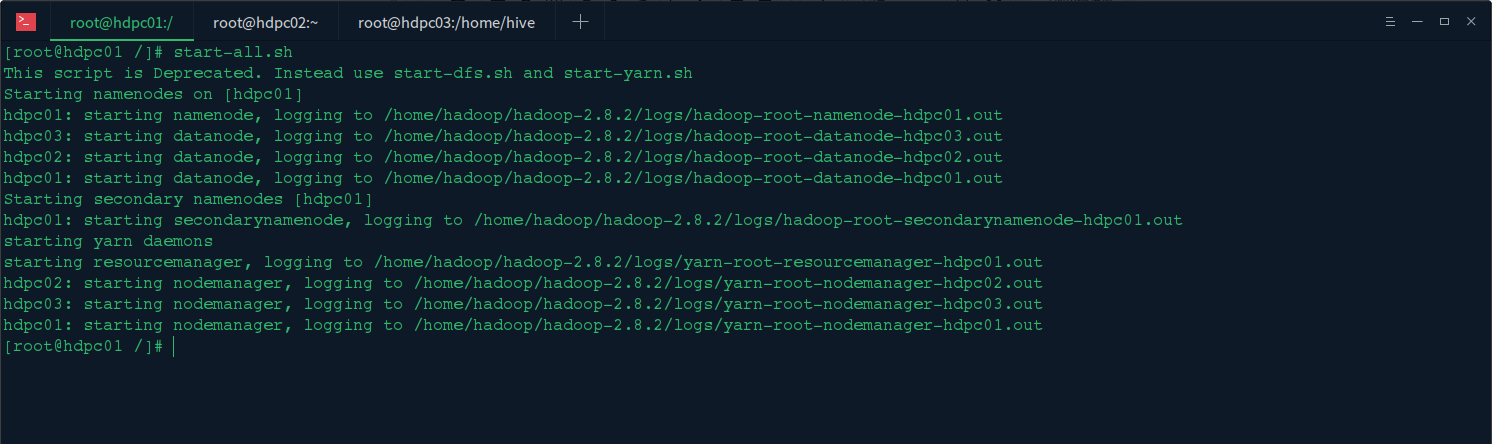
1.启动hadoop集群
在主节点上启动hadoop集群start-all.sh
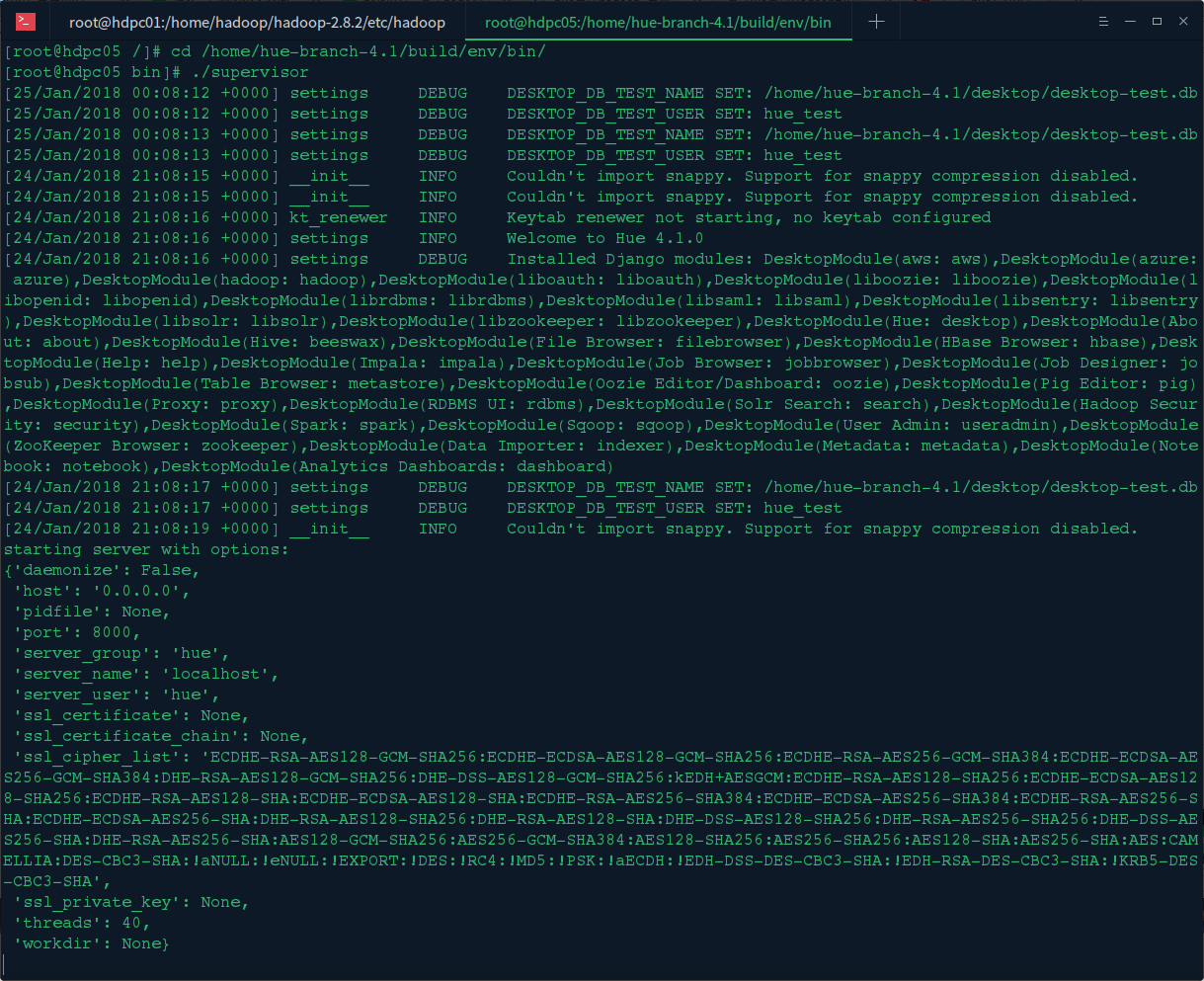
2.启动Hue服务
在hue的/bulid/env/bin/目录下 ./supervisor 启动hue服务
3.服务启动验证
验证hadoop集群启动
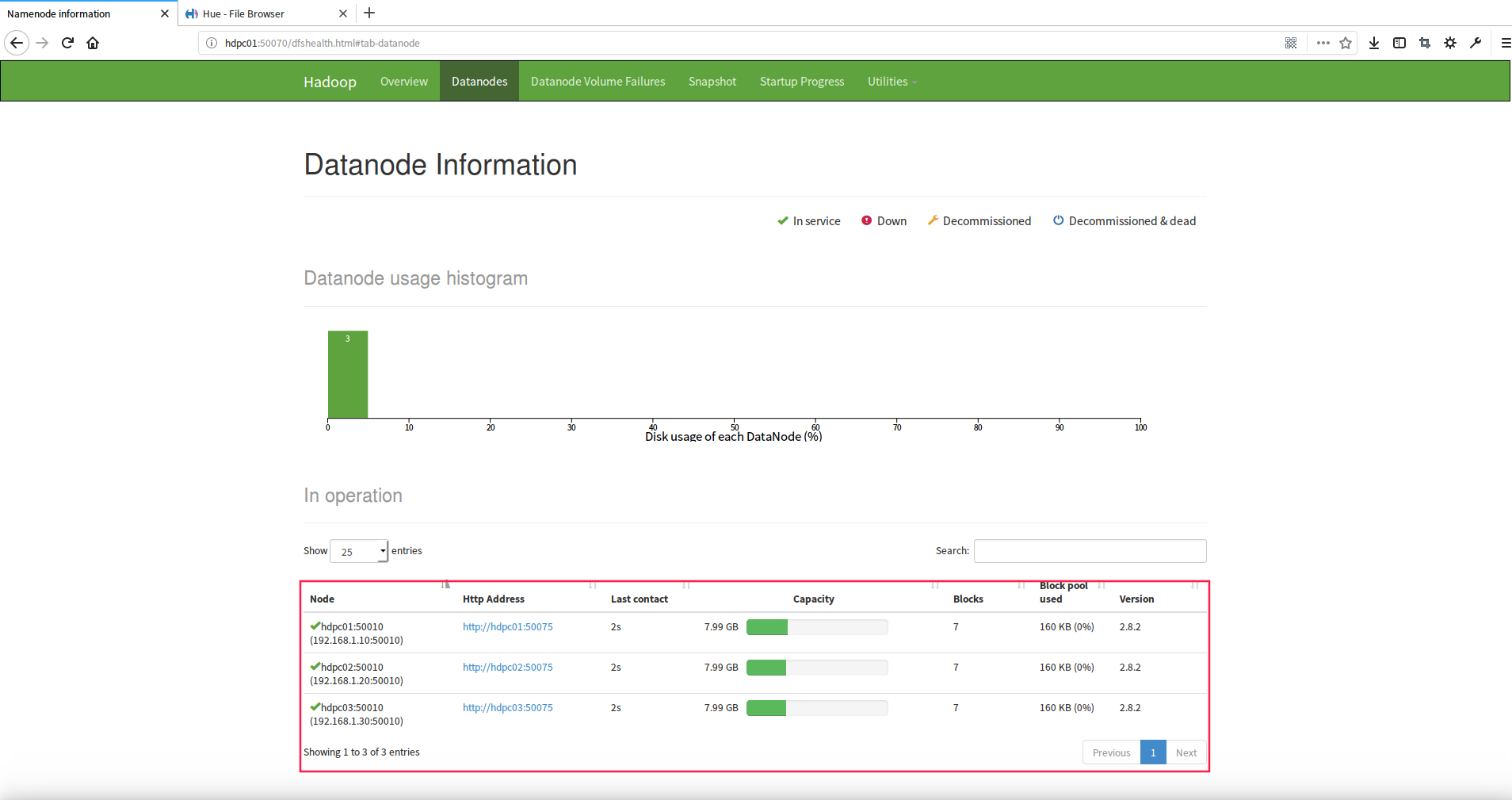
验证hue服务启动

四、集成使用
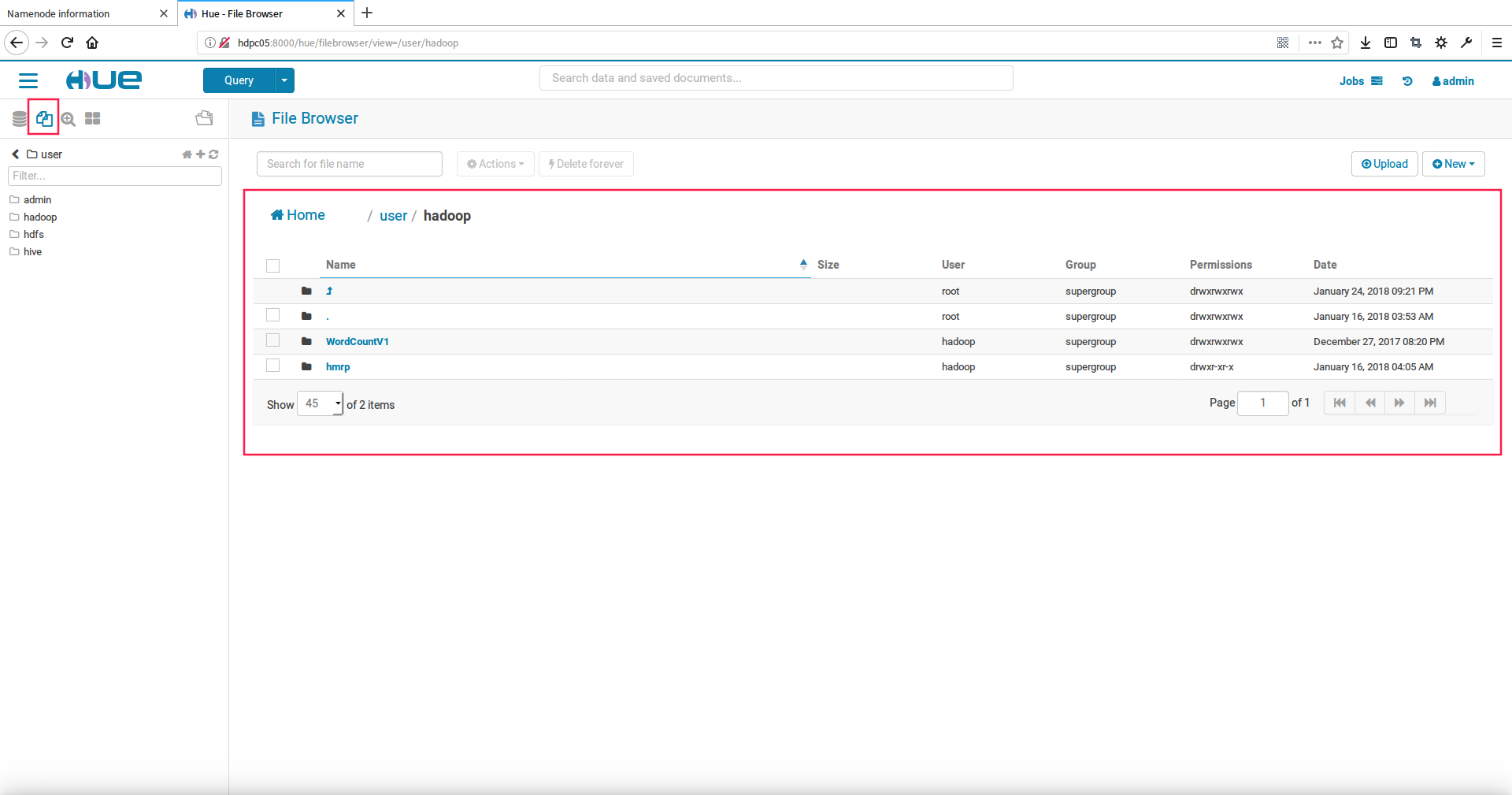
1.使用hue查看hdfs文件
点击hdfs图标,可以Open in Browser查看详细的文件列表信息,如下图:
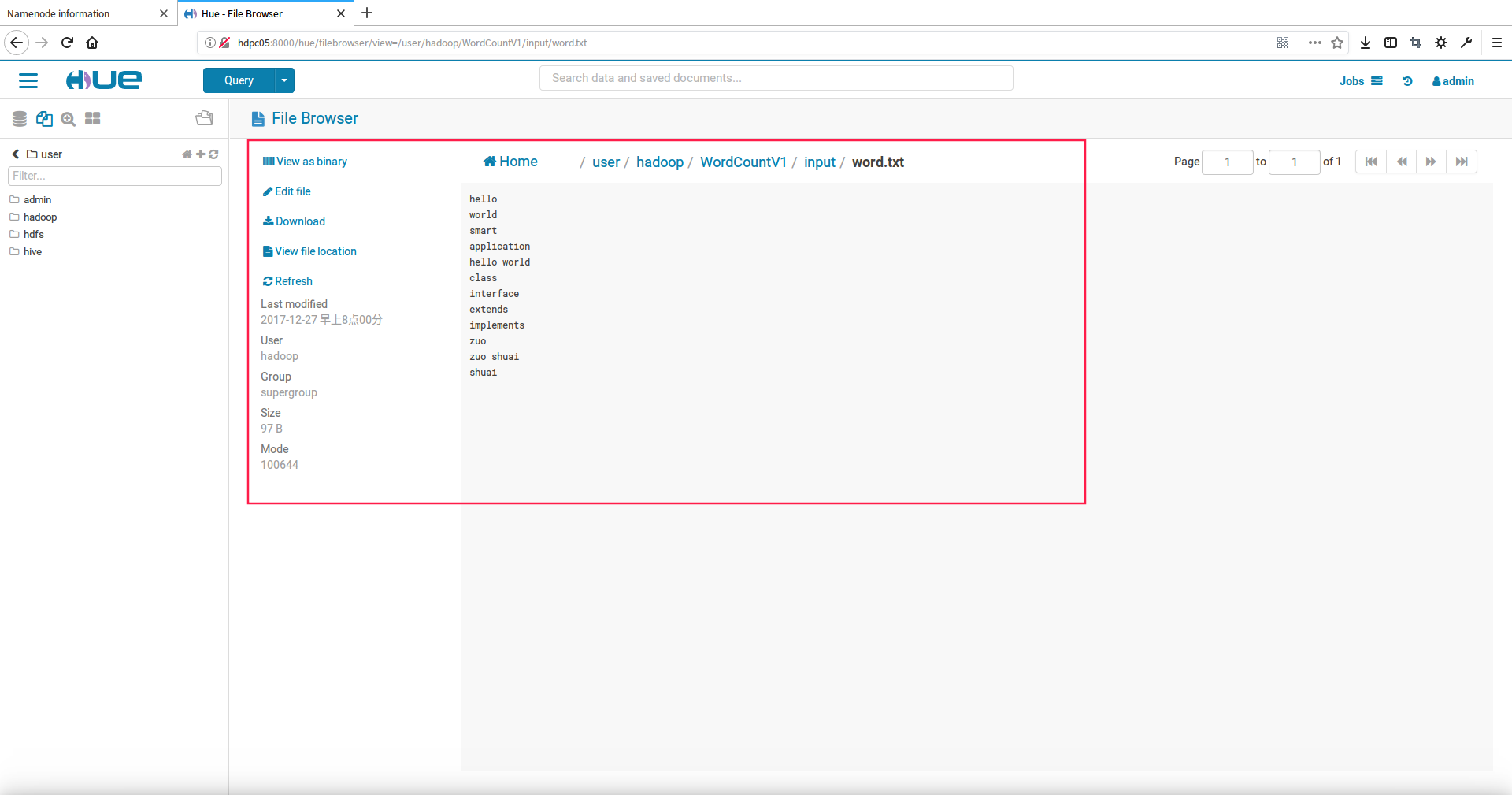
2.查看单个文件详细的信息
在文件列表中点击文件可以查看这个文件详细的信息,如下图:
3.使用hue上传文件到hdfs中
我们这里上传bsck.txt文件到hdfs目录下,如下步骤:
首先,切换到hdfs目录下,点击upload上传文件按钮
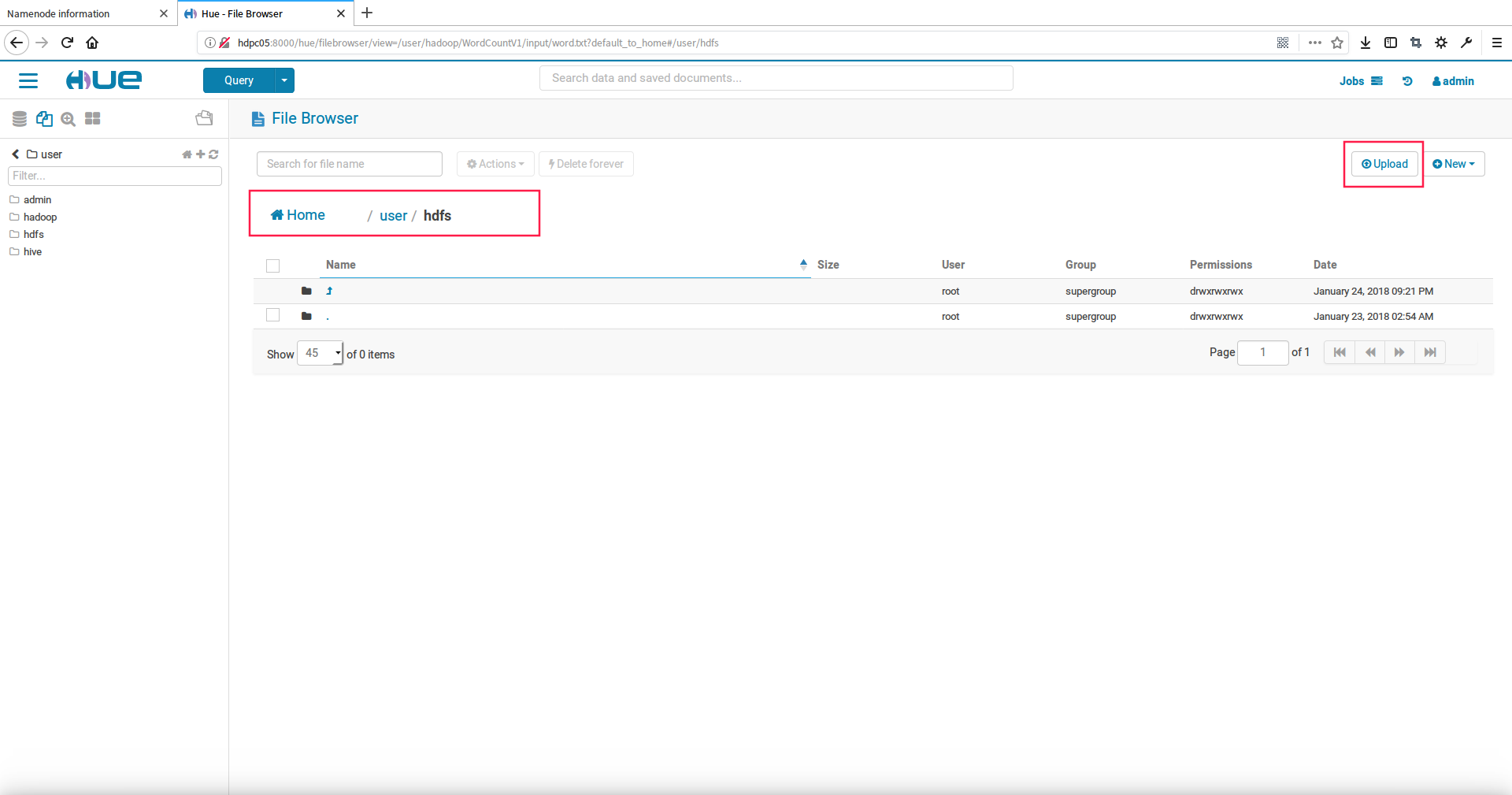
然后,选择上传的back.txt文件到hdfs中即可看到
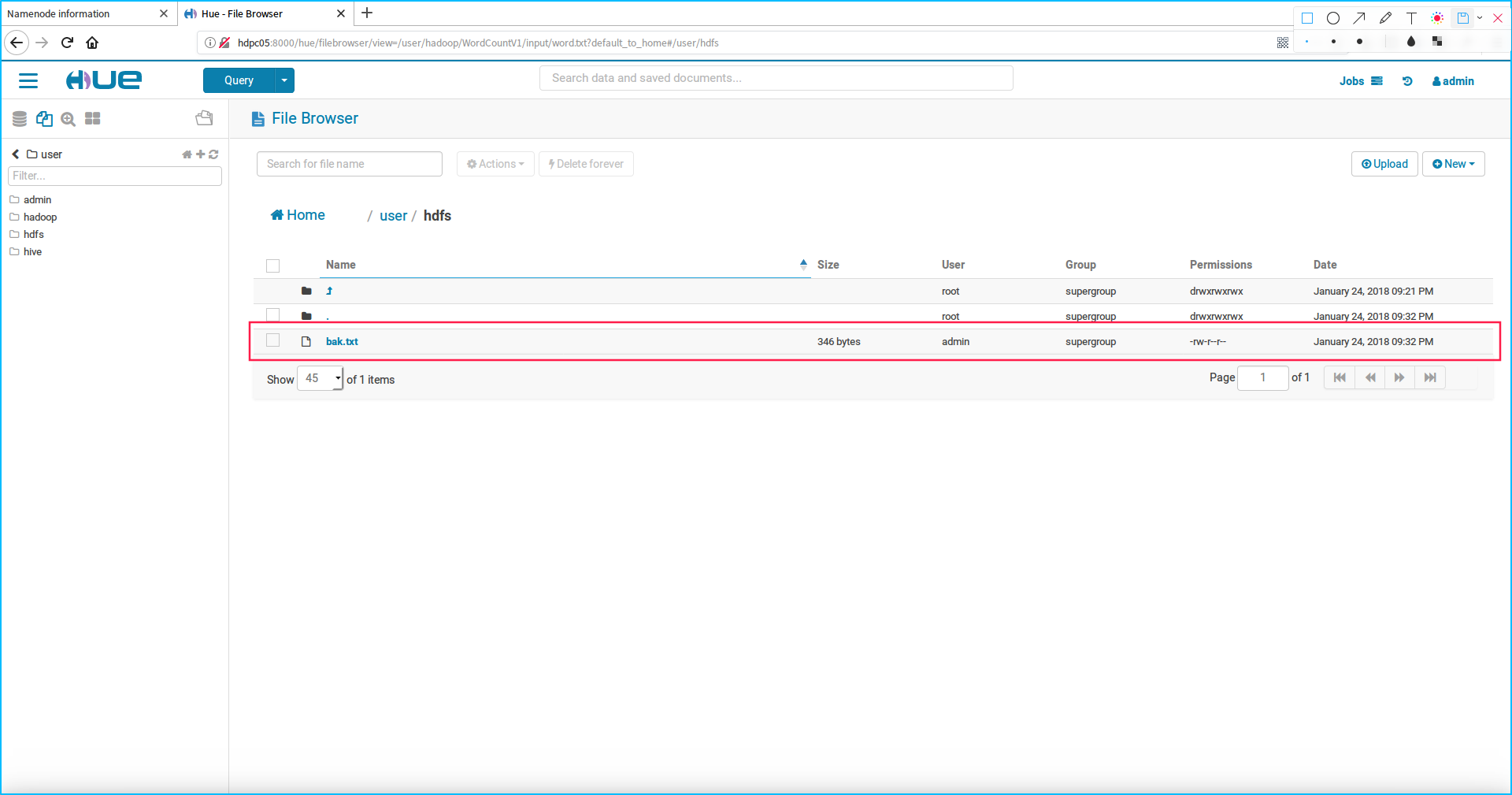
4.从hdfs上删除文件
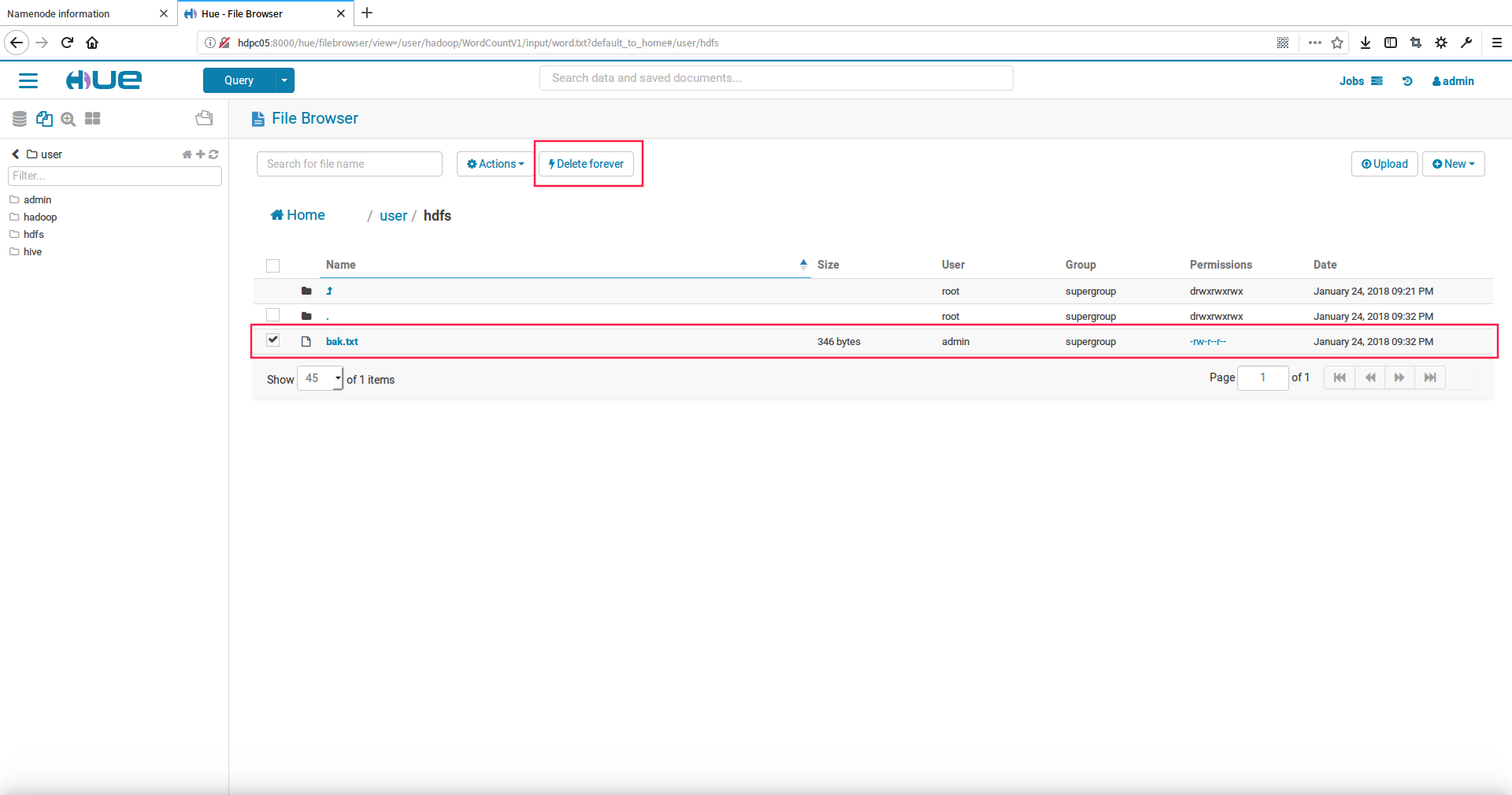
我们删除刚刚上传到hdfs目录下的back.txt文件,先选中文件然后点击Delete forever按钮即可删除
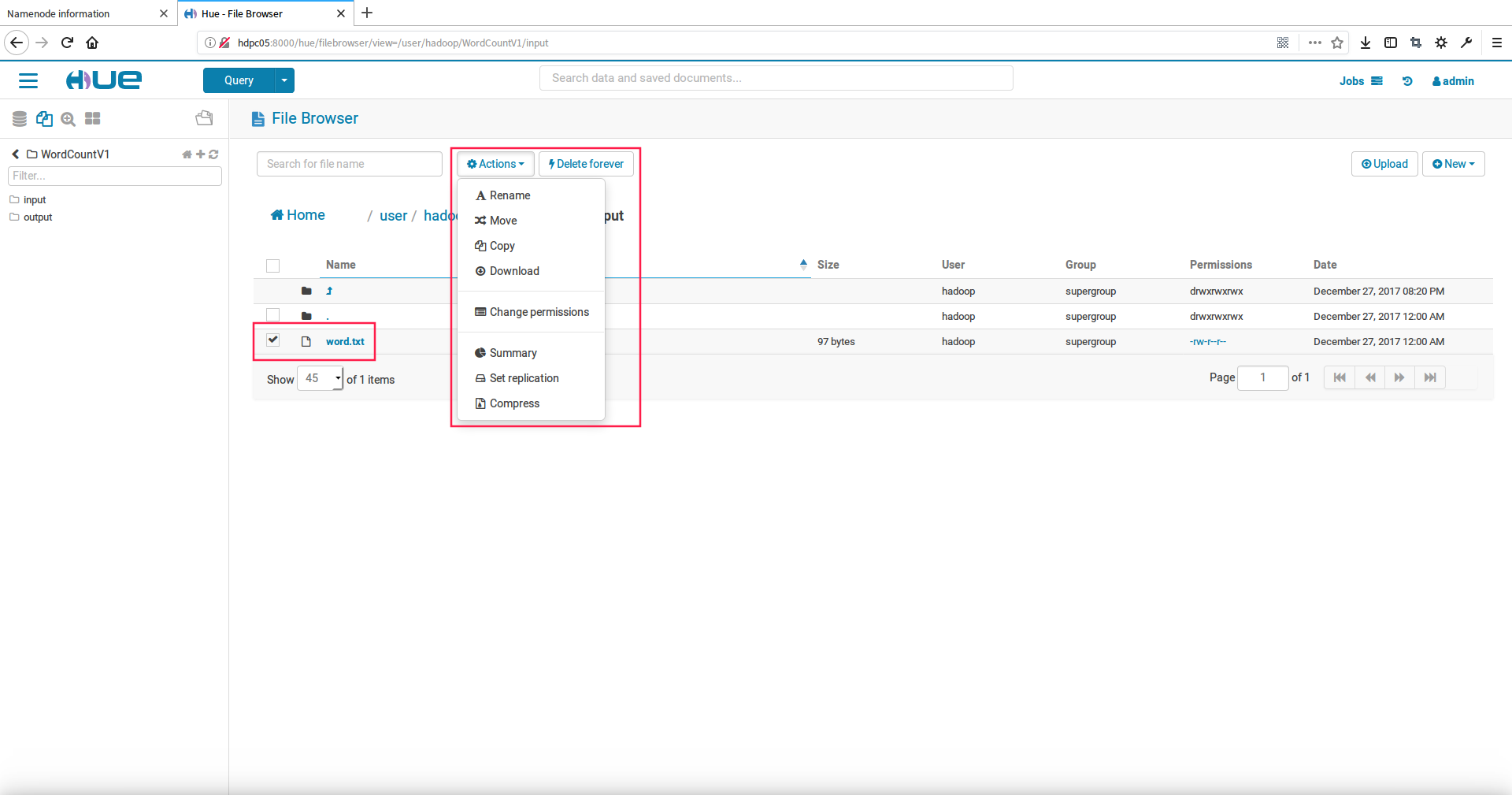
5.hue中对hdfs文件的更多操作
我们选中文件点击Actions,可以看到下拉框中对文件的更多其他操作项,有下载、拷贝、移动、重命
名、修改权限等等
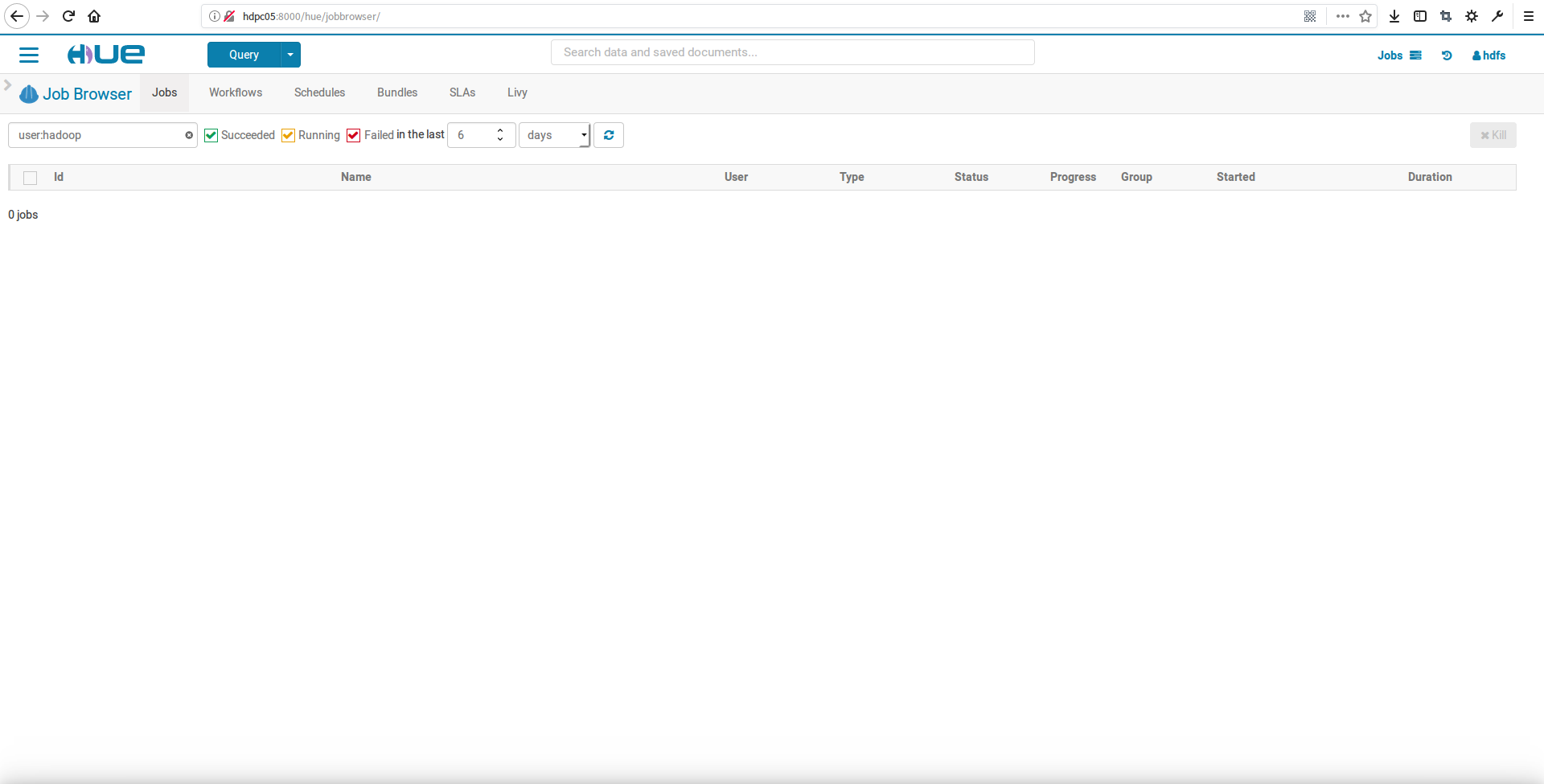
6.hue中查看MapReduce执行的Job
我们点击Jobs打开作业浏览面板,在这里可以看到执行中、执行完成、执行失败的作业信息,如下:
五、问题总结
1.关于hue集成hdfs的问题
在hue集成完成hadoop后,使用hue查看hdfs的时候,hue的控制面板总是提示如下错误:

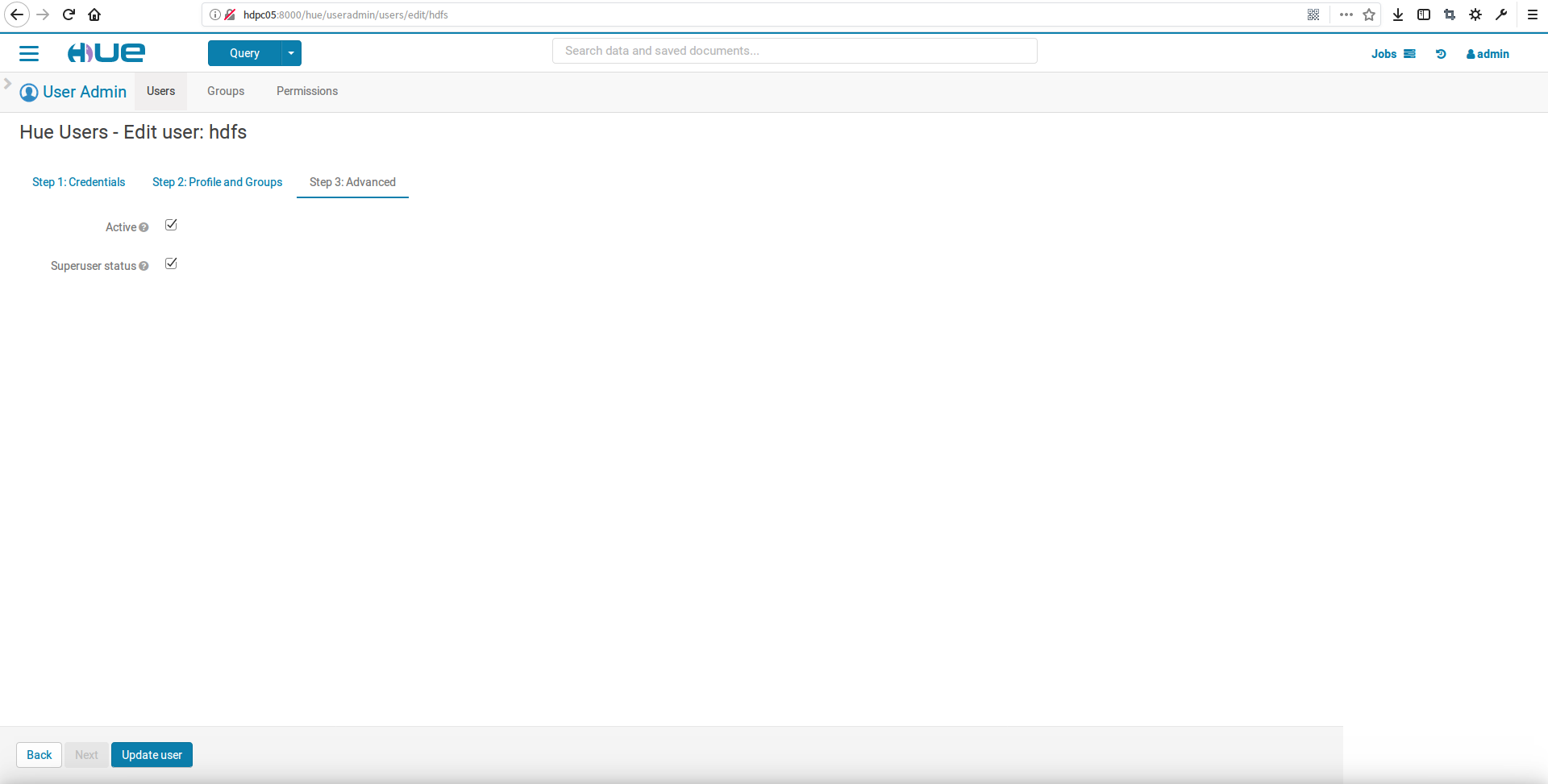
解决办法:在hue中创建用户hdfs,并且设置未超级用户即可解决
2.关于进入hue提示连接10000端口服务异常

该问题是我们没有连接hive服务提示的异常,解决办法就是集成hive即可,详细见下篇博文
六、最后总结
通过文本在hue中集成hadoop集群(hdfs和yarn),并且在集成完成后进行了简单的使用,我们以后
可以有更好的方式操作hdfs和查看作业执行情况了,后面我们还将继续集成hive和mysql服务,文中有
不对的地方欢迎大家指出来

