前言
(本段瞎扯淡,可略)距离上一篇博客已经过去一个多月了,如果说没写博客的原因,大概是因为懒了吧。本篇还是关于tio的内容,不过由应用转为源码分析,原作者的博客总是短小精悍,我的博客风格又臭又长,建议先码后看或者直接不看。瞎扯些,为什么要去看tio-http端的代码呢,我相信大部分程序员多少都有被问到过 get 和post的区别的经历,好像之前对于http的理解也只能到这里了。一般开发也就会用httpClient即可,会请求,会调用接口。我相信大部分公司也不会闲着没事让你写一套http server的。当然借着书本(HTTP权威指南)上的内容和tio-http的源码,让我对http的了解更加深入一些,所以博客内容仅限于本人自己的理解,有错误之处还请指正。
什么是HTTP?
相信web开发者对于这四个字母在熟悉不过了,不管是什么语言的,都少不了这个东西。没错,他就是超文本传输协议,就是一种协议。还没有接触tio的时候,我以为tio就是WebSocket,后来才发现,他只是通讯框架,而HTTP,WebSocket,FTP等都是协议。举个很简单的例子,tio可以有client-server通讯,很简单的demo就可以实现。但是tio server端如何接收浏览器的请求呢?能解析吗?我的答案是能接收,但是响应的内容恐怕浏览器识别不了。所以,就需要实现HTTP协议,只要实现了它,那么不管是HttpClient还是浏览器,都能够正常请求基于tio的服务端并且获得响应了。
怎么实现HTTP?
既然HTTP是一种协议,那么他就有一些规定,所以没什么好说的,按照规定走就完事了。那说起来容易,那接下来我们就详细看看它的规定吧。
构建HTTP请求
我拿百度举例,访问百度首页,F12查看一下请求详情,我们在截图中能看到RequestHeaders,ResponseHeader还有General中的内容,其实之前我还被浏览器误导了,以为server端接收的报文就是这样的格式,后来想想,它就是一个对于开发人员看起来便捷的UI。呵呵,我真傻。。。
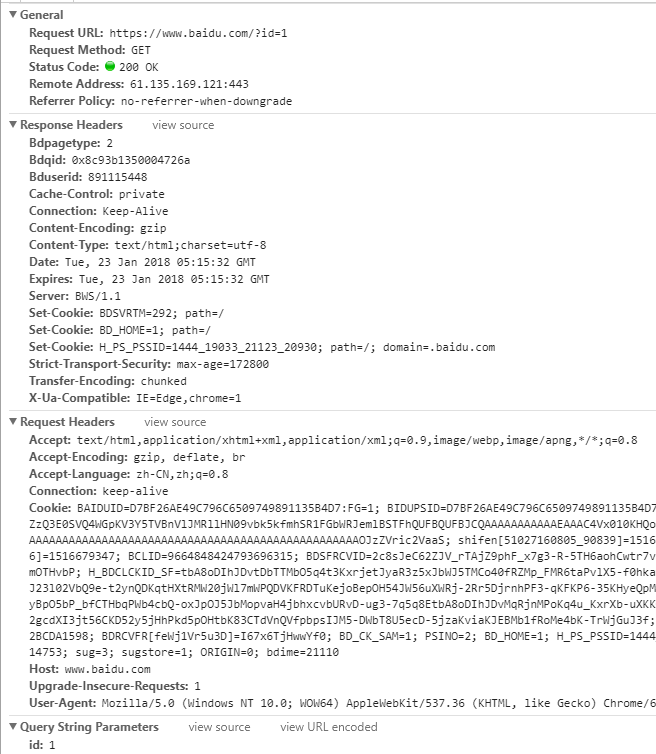
那么,真正的报文长什么样呢?我也不知道,接下来我们从源码中探寻吧。
HttpRequestDecoder
这个类是解析请求报文的核心类。其中方法 decode 返回 一个HttpRequest 对象,HttpRequest对象包含如下字段:
private RequestLine requestLine = null; private Map<String,Object[]> params = new HashMap<>(); private List<Cookie> cookies = null; private Map<String,Cookie> cookieMap = null; private int contentLength; private String bodyString; private HttpConst.RequestBodyFormat bodyFormat; private String charset = HttpConst.CHARSET_NAME; private Boolean isAjax = null; private Boolean isSupportGzip = null; private HttpSession httpSession; private Node remote = null; private ChannelContext channelContext; private HttpConfig httpConfig; private String domain = null; private String host = null; private String clientIp = null; private long createTime = SystemTimer.currentTimeMillis(); private boolean closed = false;
看其中的字段,相信大家也能看个差不多。比如包含请求内容,参数,cookie等信息。所以,decode的方法的任务就是将 ByteBuffer 转化为程序可操控的HttpRequest对象。核心代码如下:
/** * position < limit * 循环读取每行的内容进行解析 * */ while(buffer.hasRemaining()){ String line; try{ //读取每一行的内容(详见下文) line = ByteBufferUtils.readLine(buffer,null,MAX_LENGTH_OF_HEADERLINE); }catch (LengthOverflowException e){ throw new AioDecodeException(e); } int newPosition = buffer.position(); //如果头部信息超过 20480 字节,异常 if (newPosition - initPosition > MAX_LENGTH_OF_HEADER){ throw new AioDecodeException("max http header length " + MAX_LENGTH_OF_HEADER); } //没有内容,返回null if (line == null){ return null; } headerString.append(line).append("\r\n"); //line为空,头部信息解析结束 if("".equals(line)){ //从 Content-Length:167 读取请求体的长度 String contentLengthStr = headers.get(HttpConst.RequestHeaderKey.Content_Length); if(StringUtils.isBlank(contentLengthStr)){ contentLength = 0; }else{ contentLength = Integer.parseInt(contentLengthStr); } //头部信息长度 int headerLength = (buffer.position() - initPosition); //头部和体部的总字节长度 int allNeedLength = headerLength + contentLength; if(readableLength >= allNeedLength){ step = step.body; break; }else{ channelContext.setPacketNeededLength(allNeedLength); return null; } }else{ if(step == Step.firstline){ //解析第一行(详见下文) firstLine = parseRequestLine(line); step = Step.header; }else if(step == Step.header){ //解析头部(详见下文) KeyValue keyValue = HttpParseUtils.parseHeaderLine(line); headers.put(keyValue.getKey(),keyValue.getValue()); } continue; } }
首先一个while 循环,依次按行读取,为什么这么做呢?因为报文内容每一段是以 CRLF 结尾也就是 "\r\n".所以看到 ByteBufferUtils.readLine方法不难理解。
//开始位置 int startPosition = buffer.position(); //结束位置 int endPosition = lineEnd(buffer, maxlength.intValue()); //返回开始位置到结束位置的字节数组 byte[] bs = new byte[endPosition - startPosition]; //转换为字符串返回 return new String(bs, charset);
其中lineEnd方法,就是通过CRLF标识来返回结束的位置(endPosition)
//CR if (b == 13) { canEnd = true; //LF } else if (b == 10) { if (canEnd) { int endPosition = buffer.position(); return endPosition - 2; } } else { canEnd = false; } }
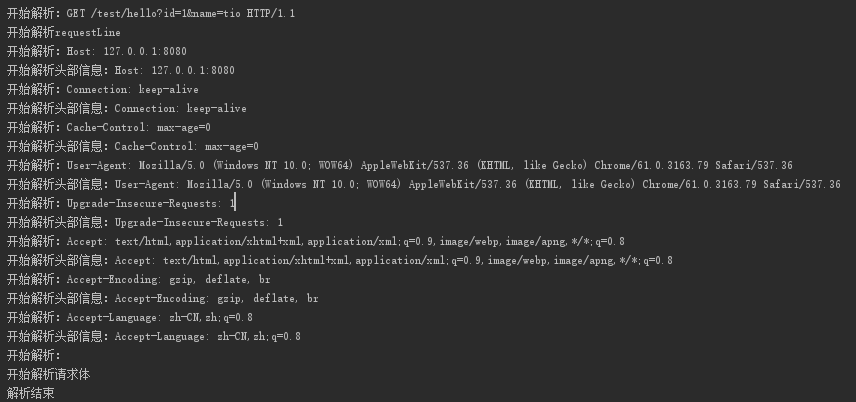
可能到这里大家有些云里雾里的,没关系。我专门打印了一下ByteBuffer的内容。比如,我们访问 http://127.0.0.1:8080/test/hello?id=1&name=tio,我们来看看服务器接收到的内容是什么:
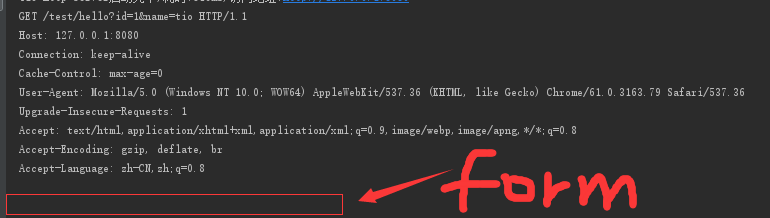
看到上图是不是很清晰了呢,首先第一行的 GET /test/hello?id=1&name=tio HTTP/1.1 让服务器知道,HTTP的方法是什么,请求的路径以及参数,还有协议版本信息。那么剩下的几行就是请求头的部分。大家注意中间有一个空行。空行下用红框框住的部分就是form表单的内容了(截图中是空的,因为是GET请求)。
接下来继续分析源码。
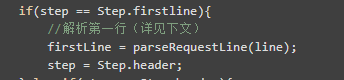
解析第一行的时候,执行parseRequestLine方法,然后将解析步骤置为header。parseRequestLine做了什么呢,就是把 GET /test/hello?id=1&name=tio HTTP/1.1 解析成一个 RequestLine 对象,方便后续使用。解析过程就是一些字符串的处理了(代码有剪切,详细代码可去查看源码)。
/** * 解析第一行 GET /test/hello?id=1&name=tio HTTP/1.1 * */ public static RequestLine parseRequestLine(String line) throws AioDecodeException{ //GET /test/hello HTTP/1.1 int index1 = line.indexOf(' '); //得到请求方法 GET String _method = StringUtils.upperCase(line.substring(0,index1)); //转化为枚举的Method Method method = Method.from(_method); //截取路径 /test/hello int index2 = line.indexOf(' ',index1 + 1); // /test/hello String pathAndQueryStr = line.substring(index1 + 1,index2); //是否带有?参数 int indexOfQuestionMark = pathAndQueryStr.indexOf("?"); //URL上是否带参数,例如 ?user=123456 if(indexOfQuestionMark != -1){ queryStr = StringUtils.substring(pathAndQueryStr,indexOfQuestionMark + 1); path = StringUtils.substring(pathAndQueryStr,0,indexOfQuestionMark); }else{ path = pathAndQueryStr; queryStr = ""; } //HTTP/1.1 String protocolVersion = line.substring(index2 + 1); String[] pv = StringUtils.split(protocolVersion,"/"); //HTTP String protocol = pv[0]; //1.1 String version = pv[1]; return requestLine; }
接下来是头部内容:
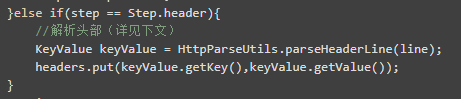
每一行其实可以理解为键值对。比如: Connection:keey-alive,解析之后转化为 KeyValue 对象。
最后,解析body,参数等信息。然后封装到HttpRequest中。
解析流程
总结
写的马马虎虎,终归自己去体验才能明白其中的原理。本篇源代码地址:https://gitee.com/tywo45/t-io/blob/master/src/zoo/http/common/src/main/java/org/tio/http/common/HttpRequestDecoder.java

