在上篇《 hive(01)、基于hadoop集群的数据仓库Hive搭建实践 》一文中我们搭建了分布式的数据仓库Hive服务,本文主要是在上文的基础上结合Hadoop分布式文件系统,将结构化的数据文件映射为一张数据库表,将sql语句转换为MapReduce任务进行运行的具体实践。
一、环境准备
1.hadoop集群环境
2.完整的Hive服务环境(连接了远程元数据库服务)
注:hadoop集群或者hive服务没有搭建,请从参考前面的文章
二、实践准备
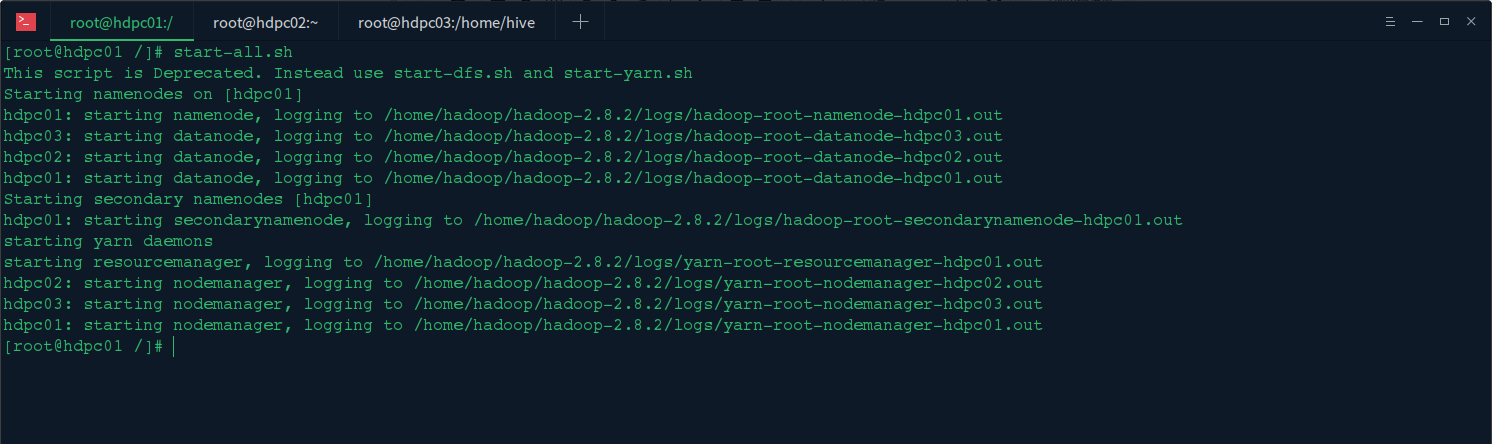
1.启动hadoop集群
启动hadoop三台机器,然后在主节点机器上启动hadoop集群:start-all.sh
2.启动hiveserver服务
在hive机器上启动hiveserver服务:hive --service hiveserver2 或者hive --service hiveserver2 &
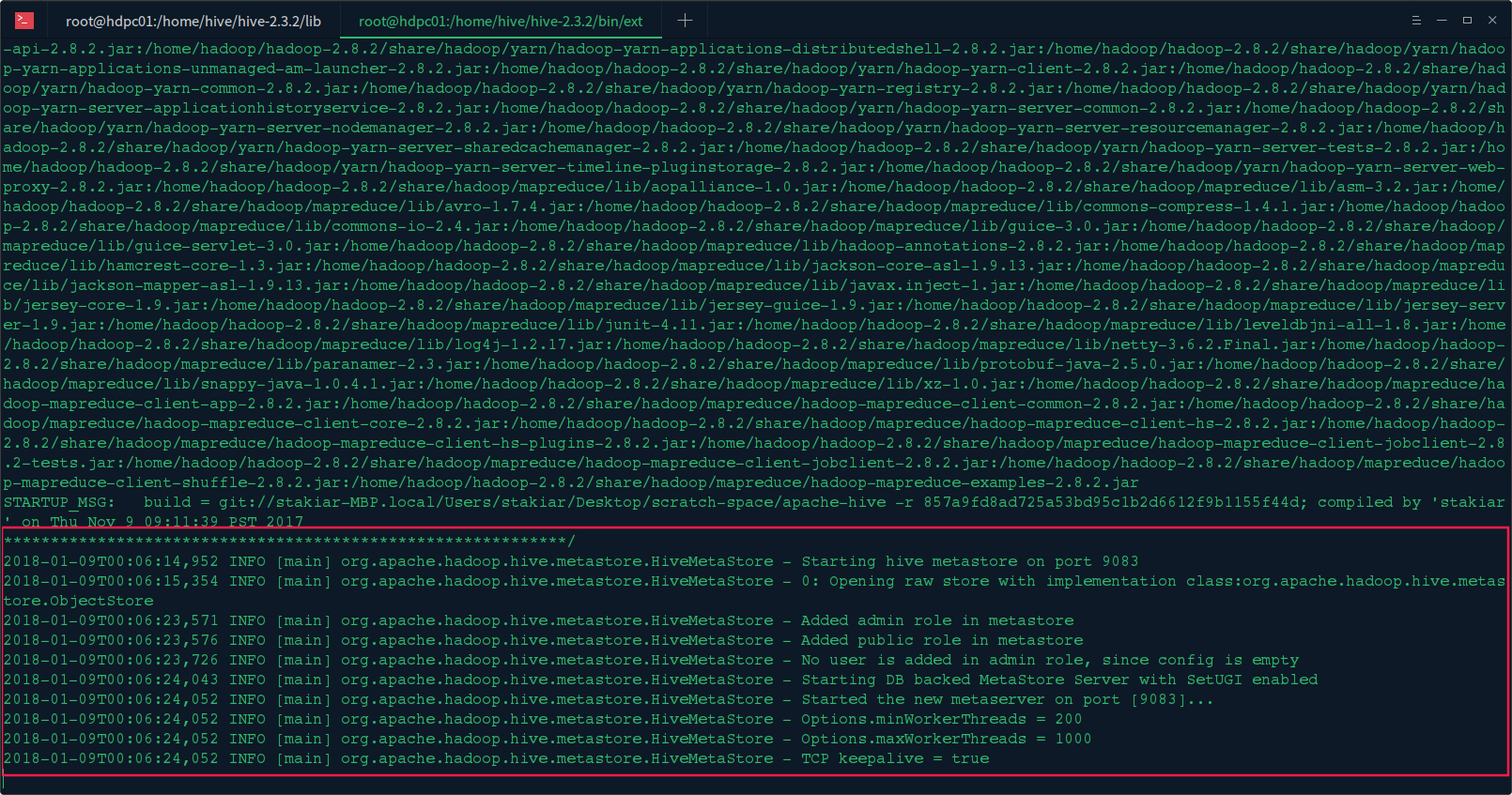
3.启动Hive服务
在hive机器上启动Hive Metastore服务:hive --service metastore或者hive --service metastore &

看到如下信息,说明启动完成:
4.验证启动
在终端输入jps -ml查看:

可以看到hadoop集群个hive服务启动都正常
三、实践过程
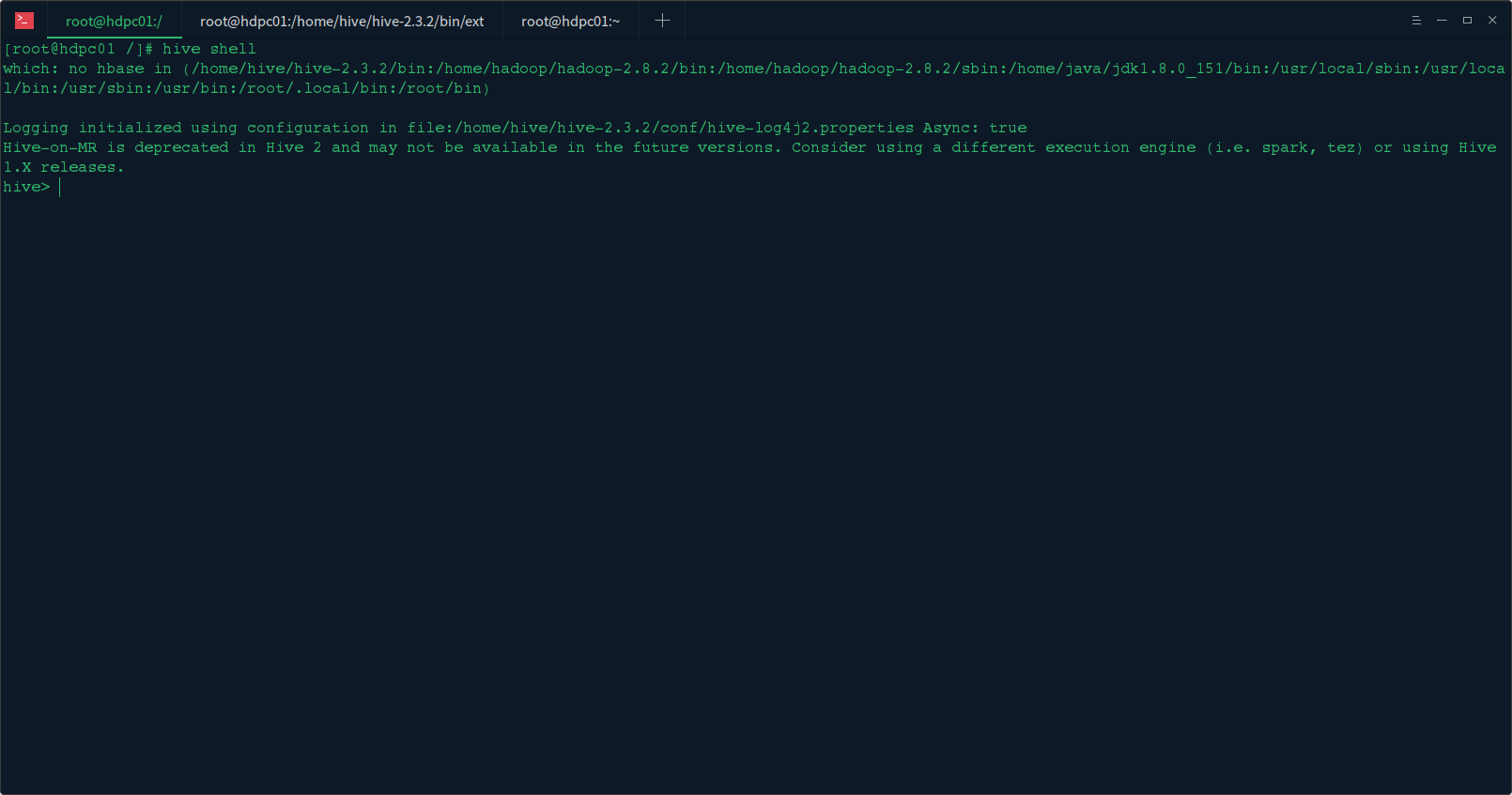
1.启动hive客户端
在hive机器上启动hiveserver服务:hive 或者hive shell
2.基本操作
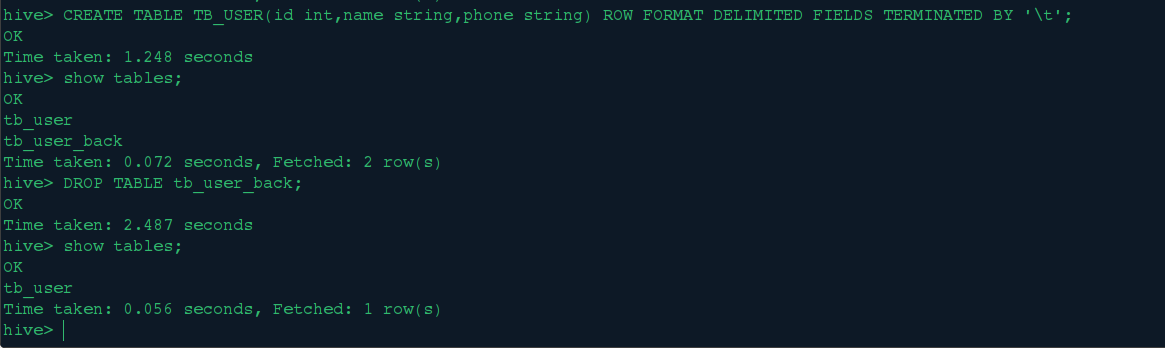
<1>.创建表
在hive控制台输入脚本:
CREATE TABLE TB_USER(id int,name string,phone string)
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t';

<2>.正则匹配查找表
在hive控制台输入:show tables '*user*';

<3>.查看表结构
在hive终端输入:desc 表名

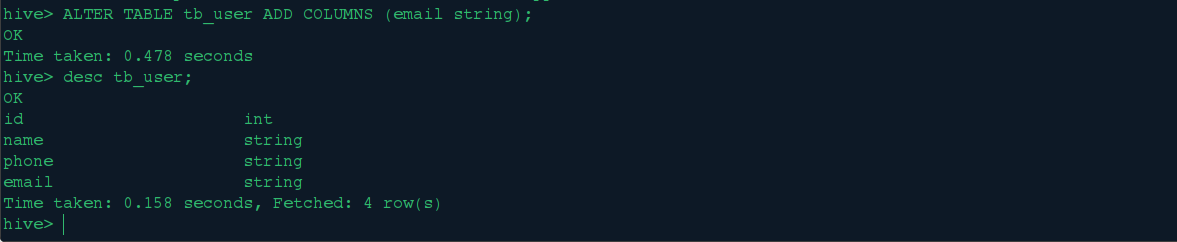
<4>.增删表字段
我们给tb_user表先增加一个email字段: ALTER TABLE tb_user ADD COLUMNS (email string);
<5>.表重命名
我们将tb_user重新命名成tb_user_back表:ALTER TABLE tb_user RENAME TO tb_user_back;

<6>.删除表
首先创建一个tb_user表,然后删除tb_user_back表:DROP TABLE tb_user_back;
<7>.插入数据
Hive插入数据有以下几种方式:
1>.从本地文件系统中导入数据到Hive表;
首先我们从本地文件系统中导入数据到Hive的tb_user表中:
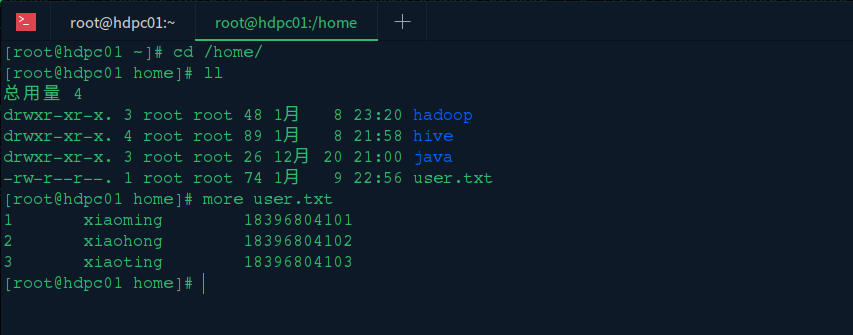
我们在hive机器的home目录下创建user.txt文件,内容如下
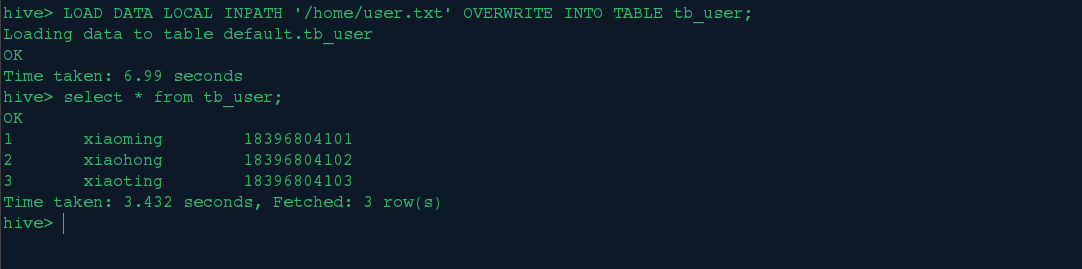
然后在hive终端执行:
LOAD DATA LOCAL INPATH '/home/user.txt' OVERWRITE INTO TABLE tb_user;
在HDFS中查看刚刚导入的数据:

2>.从HDFS上导入数据到Hive表;
创建表tb_user_hdfs,然后从hdfs上导入user.txt的数据
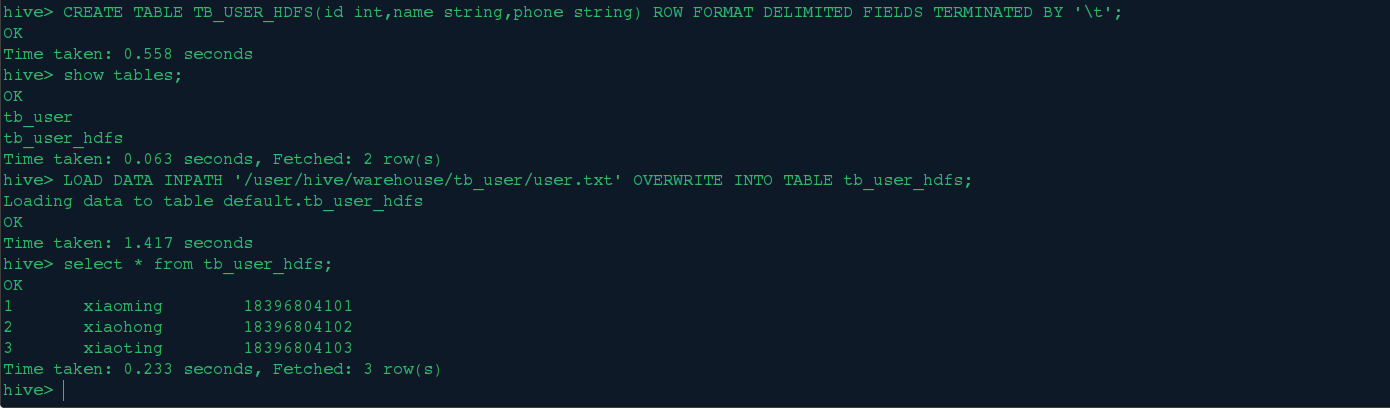
在HDFS中查看刚刚导入的数据:

3>.从别的表中查询出相应的数据并导入到Hive表中;
创建表tb_user_end_tab,然后从tb_user表查询导入数据
CREATE TABLE TB_USER_END_TAB(id int,name string,phone string)
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t';
INSERT OVERWRITE TABLE tb_user_end_tab SELECT * FROM tb_user;
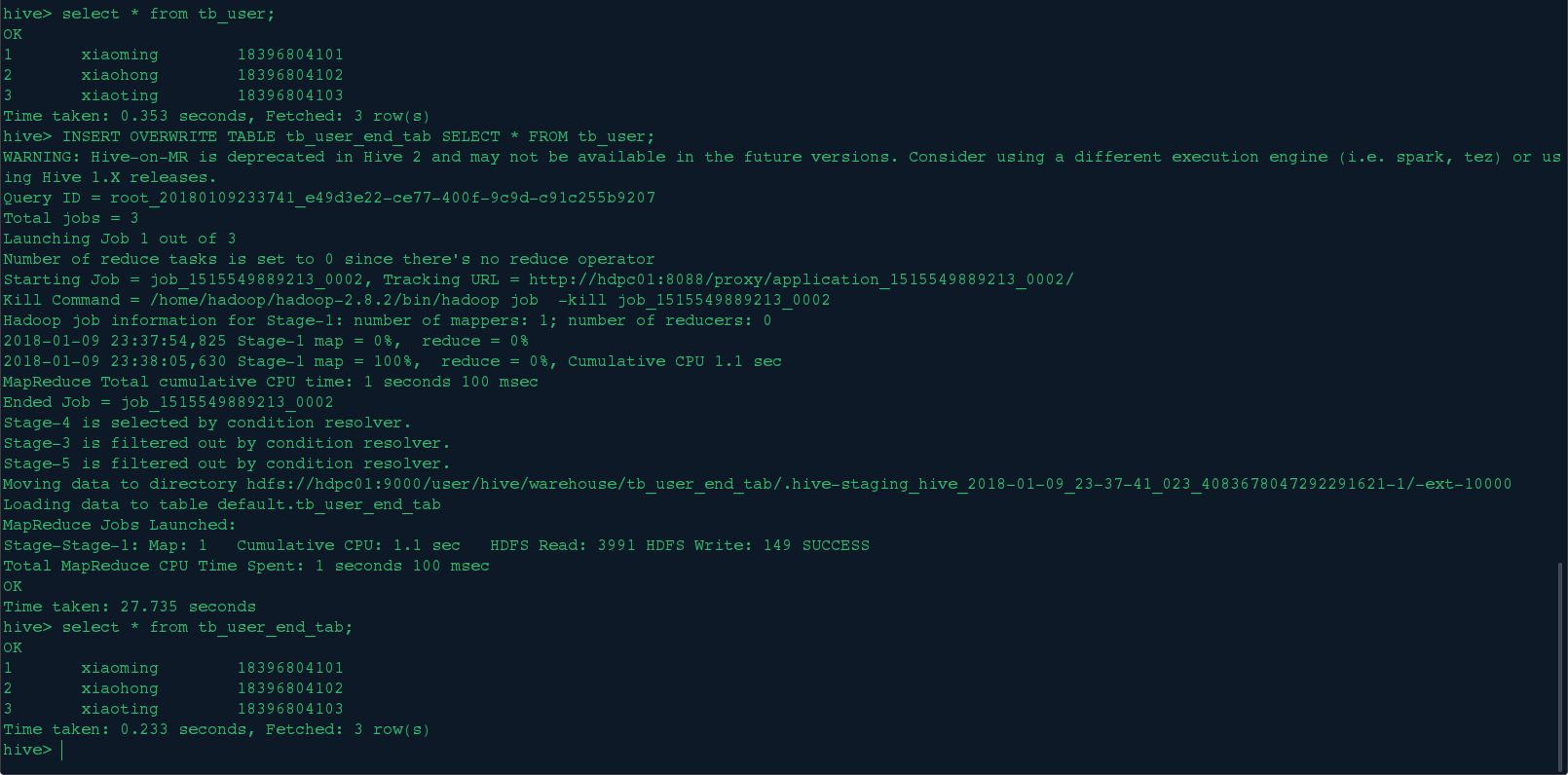
4>.在创建表的时候通过从别的表中查询出相应的记录并插入到所创建的表中;
新建 tb_user_new_tab表并从tb_user表中导入数据
CREATE TABLE tb_user_new_tab AS SELECT * FROM tb_user;
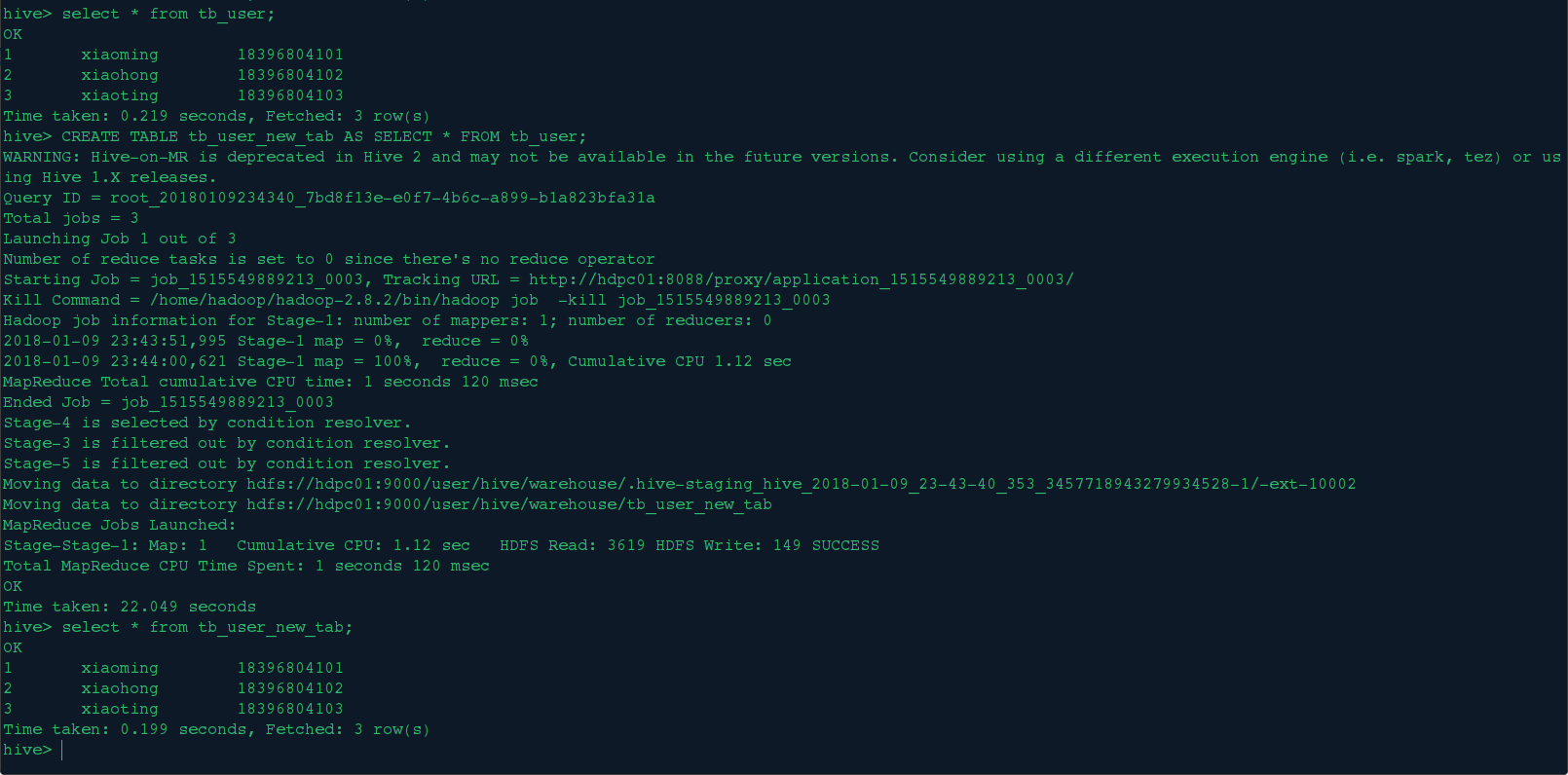
CREATE TABLE tb_user_new_tab LIKE tb_user;这是只克隆表结构不导数据
<8>.导出数据
1>.通过Hive导出到本地文件系统
INSERT OVERWRITE LOCAL DIRECTORY '/home/user' SELECT * FROM tb_user;
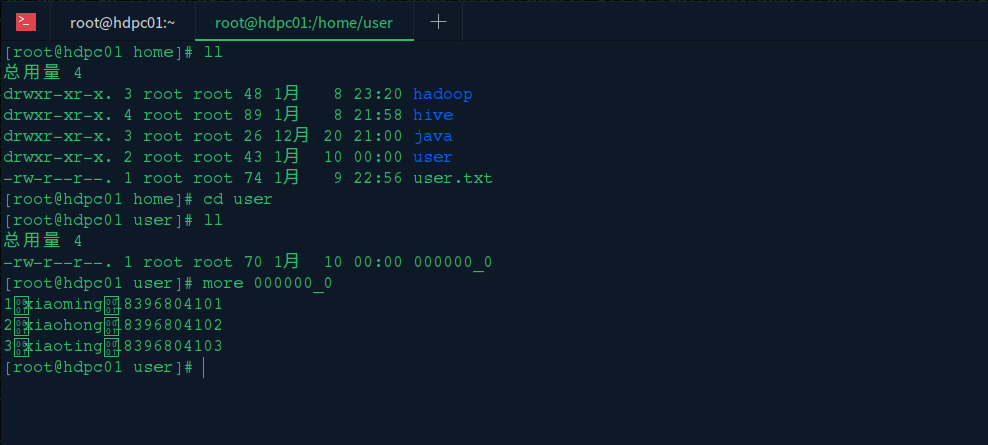
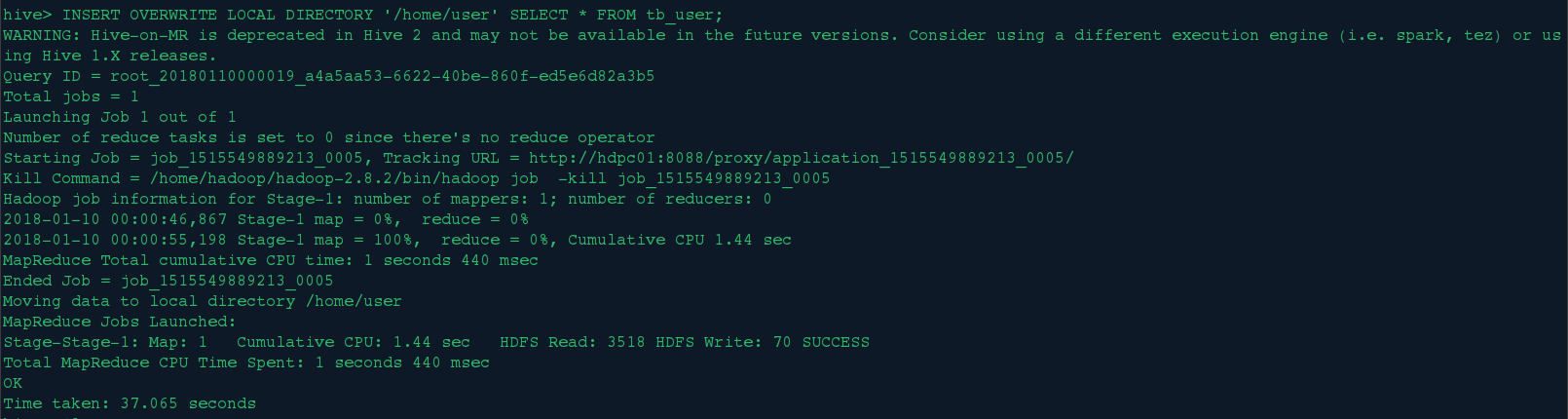 查看导出的数据:
查看导出的数据:
2>.从hdfs中导出数据
参见《hadoop(02)、使用JAVA API对HDFS进行基本操作》中hdfs下载文件的操作
3.查询操作
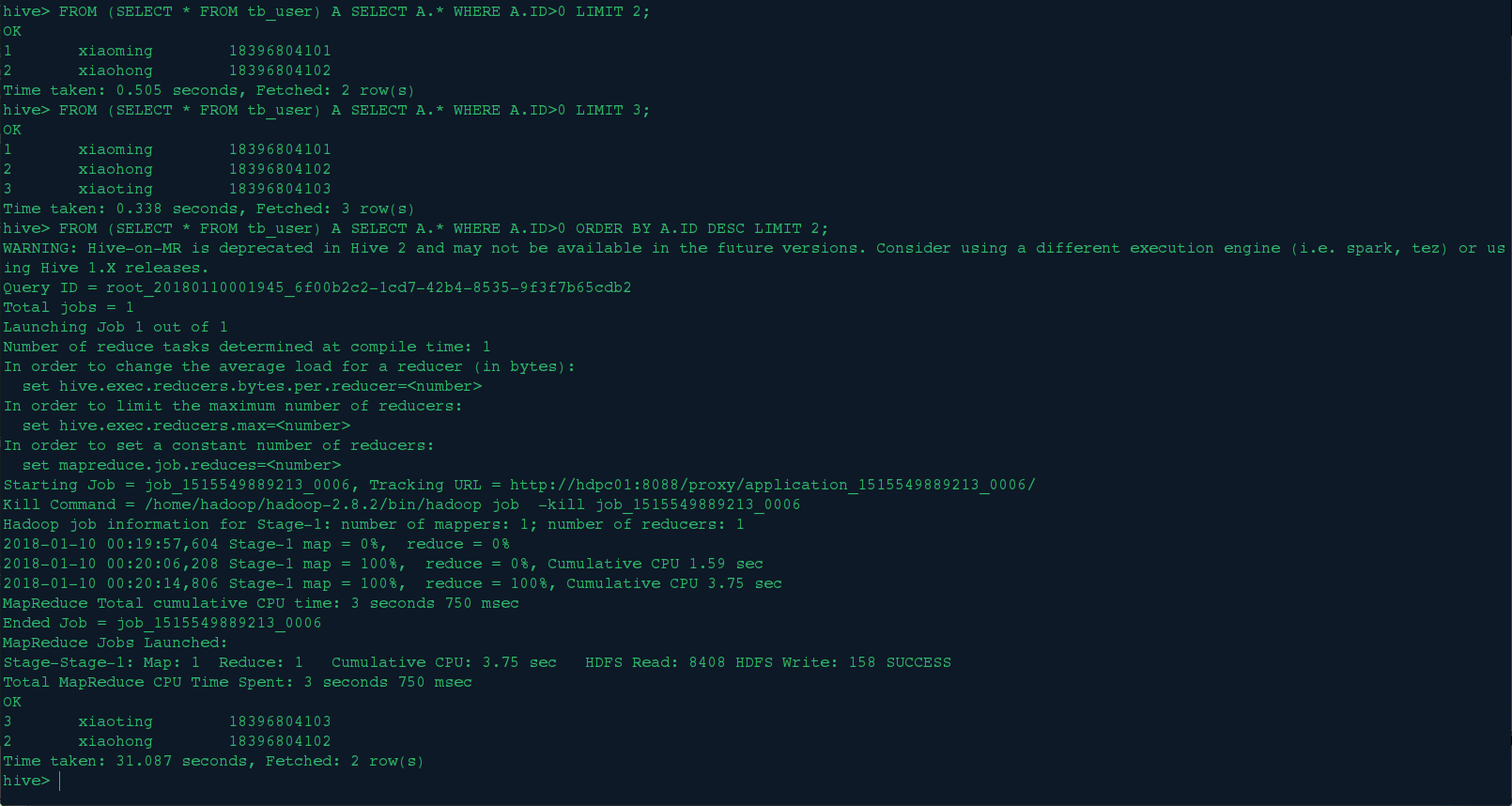
<1>.普通的条件、排序查询
FROM (SELECT * FROM tb_user) A SELECT A.* WHERE A.ID>0 LIMIT 2;
FROM (SELECT * FROM tb_user) A SELECT A.* WHERE A.ID>0 LIMIT 3;
FROM (SELECT * FROM tb_user) A SELECT A.* WHERE A.ID>0 ORDER BY A.ID DESC LIMIT 2;
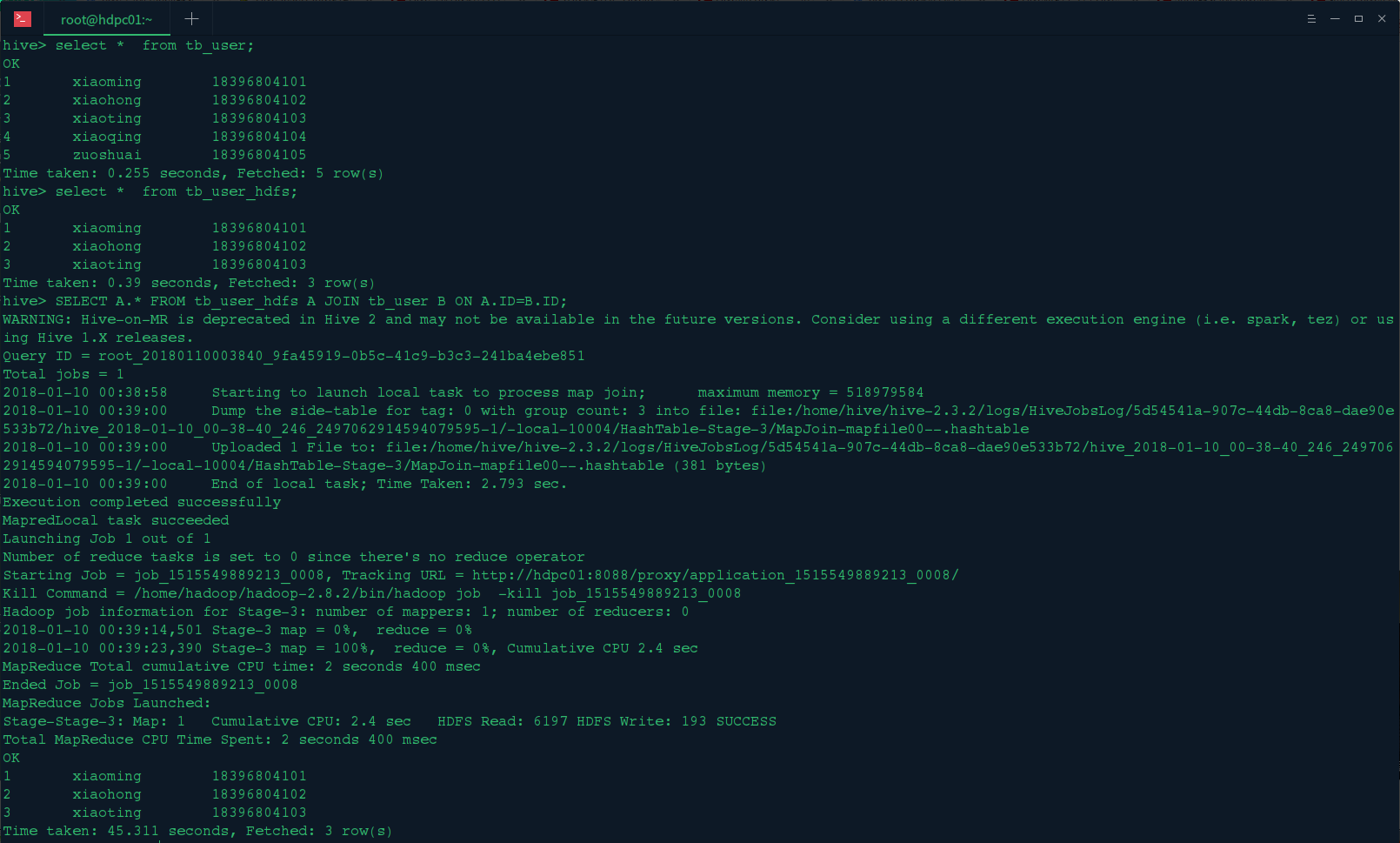
<2>.连接查询
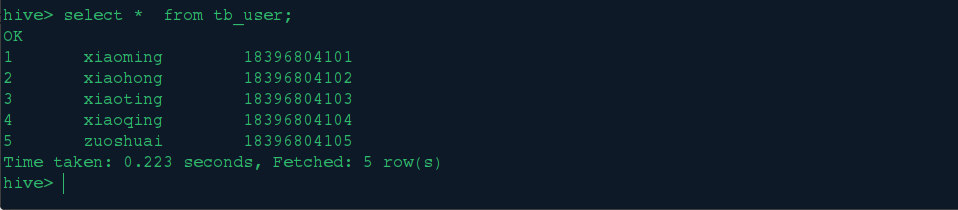
为了测试我们给tb_user表加入多几条数据:
SELECT A.* FROM tb_user_hdfs A JOIN tb_user B ON A.ID=B.ID;
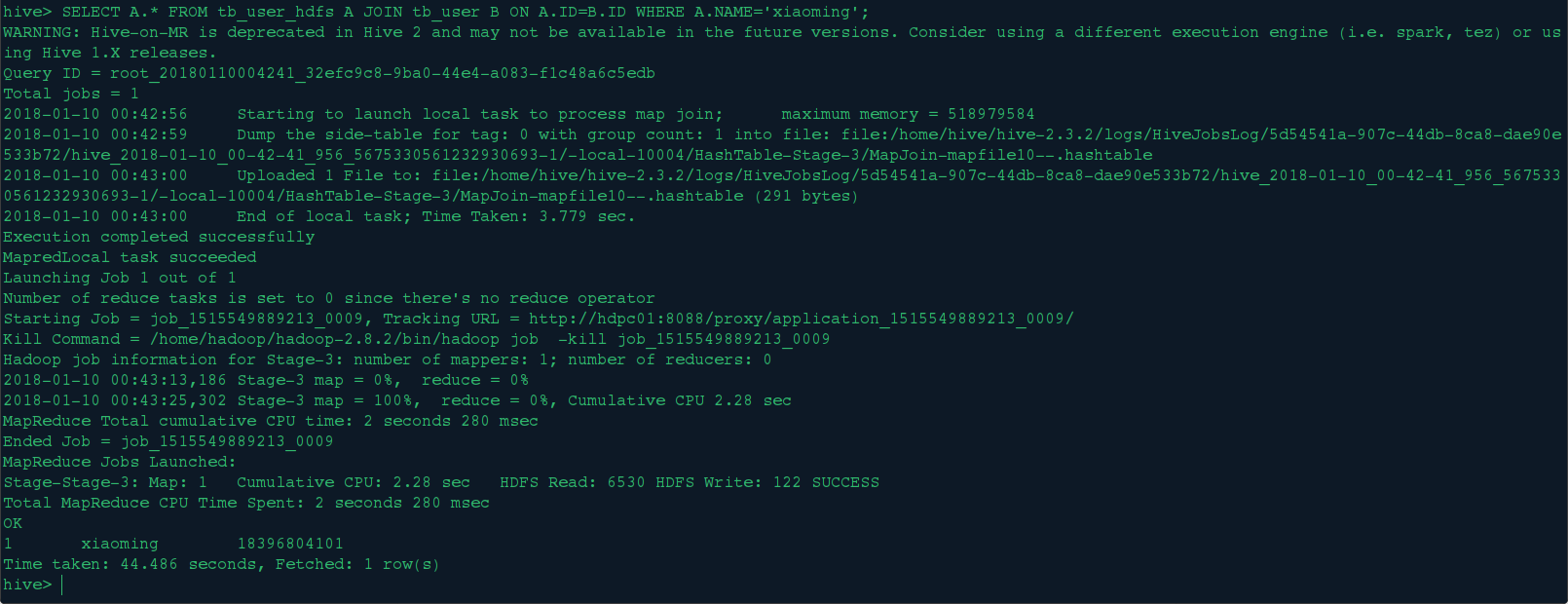
SELECT A.* FROM tb_user_hdfs A JOIN tb_user B ON A.ID=B.ID WHERE A.NAME='xiaoming';
<3>.聚合查询
SELECT COUNT(DISTINCT ID) FROM tb_user;
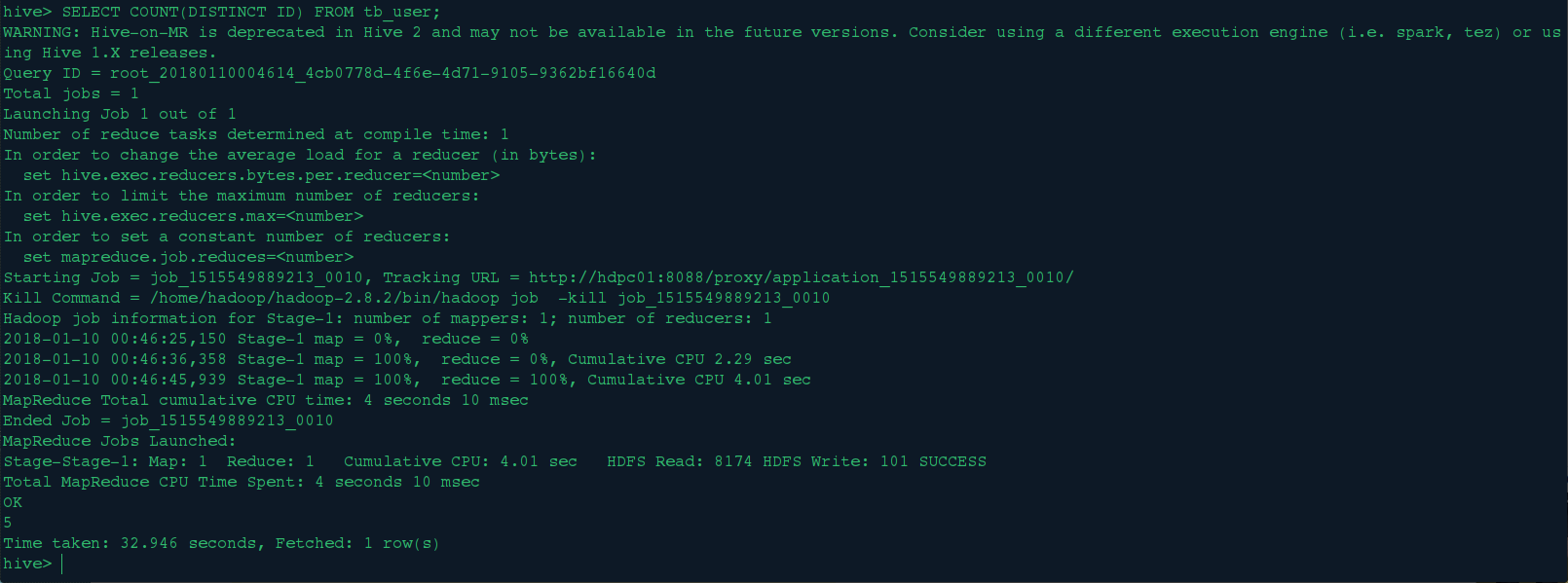
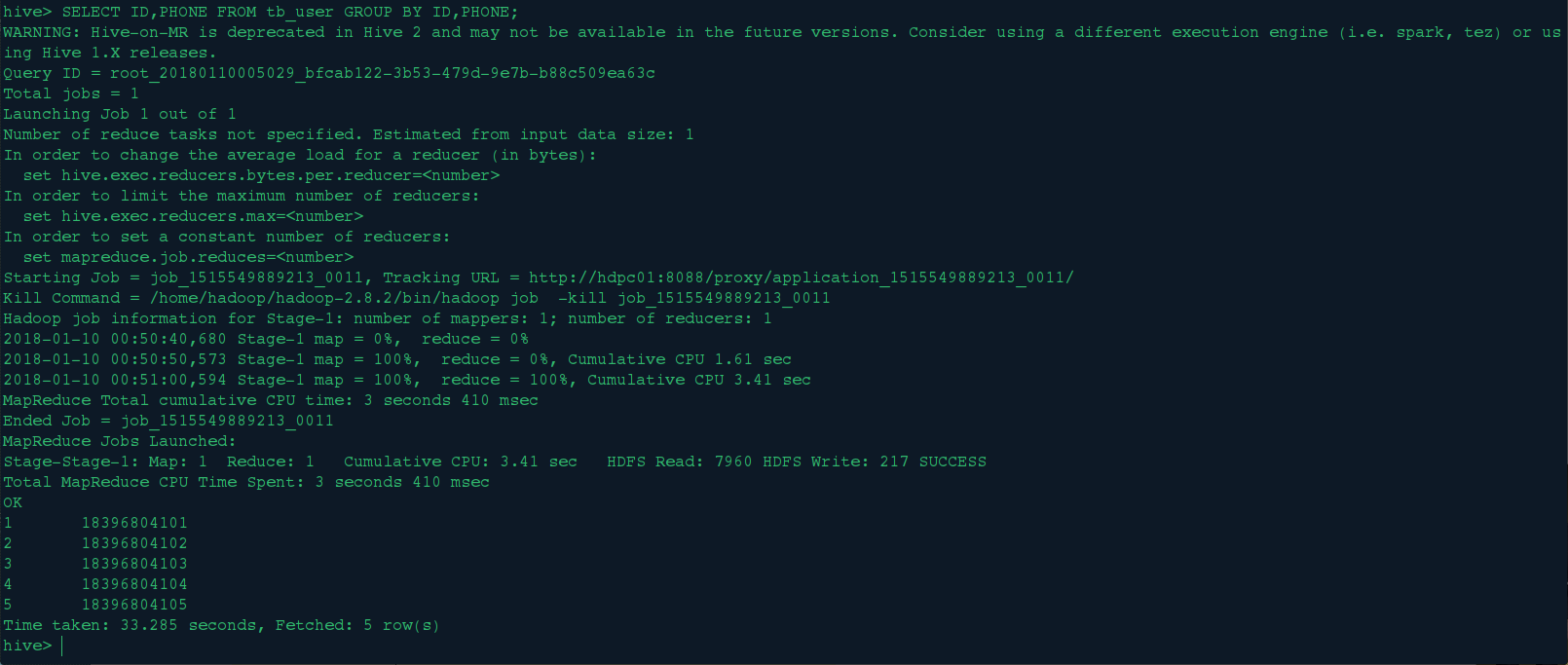
<4>.分组查询
SELECT ID,PHONE FROM tb_user GROUP BY ID,PHONE;
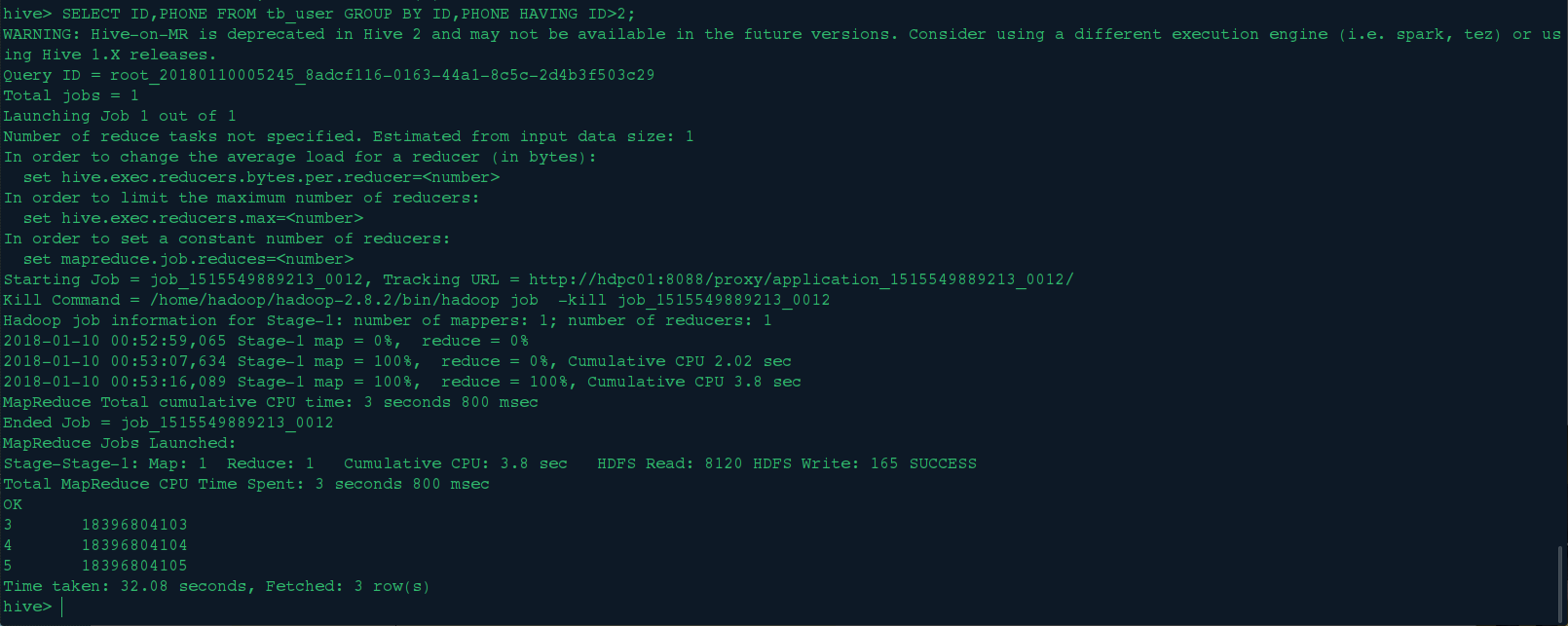
SELECT ID,PHONE FROM tb_user GROUP BY ID,PHONE HAVING ID>2;
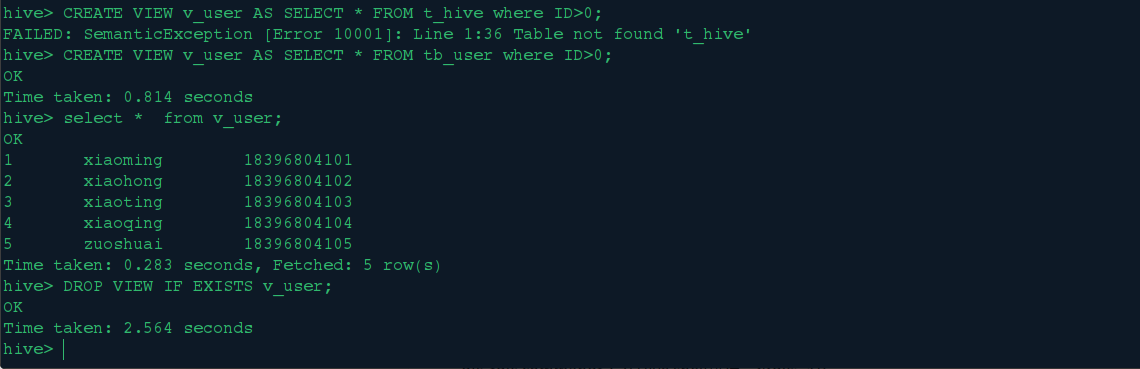
4.视图操作
hive也有对视图的操作,下面我们进行视图的创建和删除
四、Hive终端下交互命令
quit,exit: 退出hive终端
reset: 重置配置为默认值
set <key>=<value> : 修改特定变量的值
set : 输出用户覆盖的hive配置变量
set -v : 输出所有Hadoop和Hive的配置变量
add FILE[S] *, add JAR[S] *, add ARCHIVE[S] * : 添加 一个或多个 file, jar, archives到分布式缓存
list FILE[S], list JAR[S], list ARCHIVE[S] : 输出已经添加到分布式缓存的资源
list FILE[S] *, list JAR[S] *,list ARCHIVE[S] * : 检查给定的资源是否添加到分布式缓存
delete FILE[S] *,delete JAR[S] *,delete ARCHIVE[S] * : 从分布式缓存删除指定的资源
! <command> : 从Hive shell执行一个shell命令
dfs <dfs command> : 从Hive shell执行一个dfs命令
<query string> : 执行一个Hive 查询,然后输出结果到标准输出
source FILE <filepath>: 在CLI里执行一个hive脚本文件
五、总结
本文中是对hive的一些基本操作和常用的操作的实践,在实际开发中是应用比较多的,在实践中好多地
方尝试了好几遍,遇到了很多问题,通过查询网上的资料都解决了 ,在此记录帮助和我一样在学习hive
的同学,同时文中有不足的地方也请大家通过留言提出来,共同学习。

