测试工具选择
由于TinyDBCluster是基于JdbcDriver层实现的分库分表方案,因此工具就只能选用支持自定义Driver的工具了,而MyCat由于是在通信层做的适配因此对工具不挑,这一点确实更方便一点,但是为了公平PK,因此就选择了Idea/DataGrip、NetBeans、DataVisualizer 3种工具来测试,Idea和DataGrip是同源工具基本相同,因此测试得时候用DataGrip了。选择3种工具也是考虑到不同的工具其内部实现细节还是有区别的,如果三种都可以比较好的支持,那说明普适性就基本没有问题了。


测试目的及测试用例设计
TinyDbRouter是在JDBCDriver层的实现方案,优点是各种数据库都可以支持确定就是只能支持Java系列的应用;MyCat是代理实现的方式,因此对于什么开发语言来说都可以非常好的匹配,但是对不同的数据库的支持上就相对困难一些,毕竟每种方案都有其固有的优点和缺点。
不论什么样的分库分表解决方案,都是期望提供一个对用户透明的解决方案,这里的用户不仅是开发人员,也针对实施和运维人员,毕竟当需要排查一个问题的时候,如果没有好的工具的支持,这不啻是一种灾难。 因此,此次测试就直接通过工具来验证分库分表解决方案是否OK,如果能支持工具那么对于编程自然也问题不大。利用这些工具,我们只需要导入分库分表驱动,就能直观的进行增删改查以及修改数据结构的操作,管理分库分表的工作也将变的简单,这对于前期开发和后期运维都是非常有意义的。
其实我们使用数据库,主要使用的就是,表、视图、索引、元数据等等,因此此次测试得范围也限定在这些范畴,另外由于我们使用了分库分表,也希望与为分库分表的时候做一下对比,以便检视性能提升的情况,由于条件限制,10个分片数据都在一个物理数据库上,这会导致由于资源冲突而没有达到线性增长的目的,但是由于TinyDbCluster和MyCat使用的都是一样样的10个分片,因此对于对比结果并没有太大的影响。
测试目的
1.客观、公正地评估其易用性:主要通过数据库工具来验证TinyDBCluster和MyCat支持哪些sql,以及与工具的兼容性。
2.性能:通过工具,我们可以清晰的看到使用TinyDBCluster和MyCat以后性能是否有提升、提升多少。
测试环境
1.测试工具
Idea/DataGrip、NetBeans、DataVisualizer
2.数据环境
数据库:单台mysql数据库中分biz_0、biz_1、biz_2...biz_9 共十个库。
分库表:t_org和t_user。分片键均是org_id。t_org数据总量200万。
TinyDbCluster和mycat均采用取余算法分片。 200万数据均匀分配到十个库中。
测试过程
1 功能性验证
1.1 sql执行器
1.1.1 元数据命令
| 分类 | 功能点 | 预想结果 | 实测结果 |
| Dbvisualizer | Netbeans | idea |
| show命令 | show variables | 能显示所有分库的并集 | 通过 | 通过 | 通过 |
| | show databases | 包含默认数据库的所有库的并集以及tinydbcluster | 通过 | 通过 | 通过 |
| | show tables | 包含分库分表的表以及分分库分表的表 | 通过 | 通过 | 通过 |
| | show columns from t_org | 包含所有字段,字段类型正确 | 通过 | 通过 | 通过 |
| | show processlist | 显示所有库show processlist的并集 | 通过 | 通过 | 通过 |
| use命令 | 加上use以后再执行show tables。比如use biz_1,biz_1库和biz_0库不一样。看看是不是显示biz_1库的table | 显示biz_1库的所有库。 | 通过 | 通过 | 通过 |
1.1.2 DDL语句
| 功能点 | 预想结果 | 实测结果 |
| Dbvisualizer | Netbeans | idea |
| create table | 所有分库都能创建表t_org | 通过 | 通过 | 通过 |
| alter table | 所有分库的t_org表的注释都改过来 | 通过 | 通过 | 通过 |
| 新增字段 | 所有分库的t_org表都增加该字段 | 通过 | 通过 | 通过 |
| 修改字段 | 所有分库t_org表字段都会修改过来 | 通过 | 通过 | 通过 |
| 删除字段 | 所有分库t_org表字段都被删除 | 通过 | 通过 | 通过 |
| 新增索引 | 所有分库t_org表都会新建索引 | 通过 | 通过 | 通过 |
| 删除索引 | 所有分库t_org表的该索引都会被删除 | 通过 | 通过 | 通过 |
| 新增视图 | 只会在默认库biz_0新增视图 | 通过 | 通过 | 通过 |
| 删除视图 | 该视图在biz_0中删除,并且不会报错 | 通过 | 通过 | 通过 |
1.1.3 增删改查
分库的表t_org的增删改查。
1.1.3.1 基本的增删改查
| 分类 | 功能点 | 预想结果 | 实测结果 |
| insert | 普通insert语句 insert多条数据 | 能插入到不同的分片 | 通过 |
| | insert不加字段名 | 能插入成功 | 通过 |
| delete | delete from t_org where org_id=123 | 看日志,路由到了biz_3这个库中,并且能删除成功 | 通过 |
| | in:delete from t_org where org_id in(109,983,1039,10002,30001) | 看日志,能路由到相应分片中,并且都能删除成功 | 通过 |
| | between:delete from t_org where org_id between 300002 and 300004 | 看日志,能路由到相应分片中,并且都能删除成功 | 通过 |
| | truncate t_org | 所有分片中的t_org被清空 | 通过 |
| update | =:update t_org set org_name='aaa' where org_id=125 | 看日志,能路由到相应分片中,而不是所有分片都执行。并且能更新数据 | 通过 |
| | in:update t_org set org_name='eee' where org_id in(104,985,1034,10009,10001) | 看日志,能路由到in中对应分片中,而不是所有分片都执行。并且能更新数据 | 通过 |
| | between:update t_org set org_name='fff' where org_id BETWEEN 123 and 132 | 看日志,能路由到between对应分片中。并且能更新数据。 | 通过 |
| | 非分片键:update t_org set org_name='fff' where org_name='bbb' | 看日志。所有分片都执行。并且更新成功。 | 通过 |
| select | select * from t_org where org_id=12532 | 看日志,被路由到biz_2分片中。结果正确 | 通过 |
| | select org_id,org_name from t_org where org_id=12532 | 同上。 | 通过 |
| | in: select * from t_org where org_id in (123,456,789) | 看日志,能路由到相关分片。并且结果正确 | 通过 |
| | between:select * from t_org where org_id between 123 and 456 | 看日志。能路由到相关分片。并且结果正确 | 通过 |
| | select * from t_org | 所有分片都执行。最后结果正确 | 通过 |
1.1.3.2 group by语句
| 功能点 | 预想结果 | 实测结果 |
| select org_detail,count(org_detail) from t_org group by org_detail | 返回结果正确,并且快速返回 | 通过 |
| select org_detail from t_org group by org_detail desc | 返回结果正确,并且快速返回 | 通过 |
| 常规函数,比如concat:select * from t_org where org_name like concat('%,',org_id,',%') | 返回结果正确,并且快速返回 | 通过 |
| max函数 | | 通过 |
| min函数 | | 通过 |
| avg函数 | | 通过 |
| sum函数 | | 通过 |
1.1.3.3 分页查询
| 功能点 | 预想结果 | 实测结果 |
| select * from t_org order by org_id desc limit 0,100 | 从第1条数据开始往后100条,有序排列 | 通过 |
| select * from t_org order by org_id desc limit 100 | 从第1条数据开始往后100条,有序排列 | 通过 |
| select * from t_org order by org_id desc limit 1,100 | 从第2条数据开始往后100条,有序排列 | 通过 |
| 连续执行多次 select * from t_org order by org_id limit 0,100; select * from t_org order by org_id limit 1,50; select * from t_org order by org_id limit 52,100; select * from t_org order by org_id limit 1,50 | 多次执行多条语句结果都没问题 | 通过 |
其他sql
| 功能点 | 预想结果 | 实测结果 |
| 表备份:create table t_user_bk (select * from t_user); | 在默认数据库biz_0,创建t_user_bk表,并且会将biz_0中的表复制到t_user_bk中。 | 通过 |
带null的数据group by、order by
| 功能点 | 预想结果 | 实测结果 |
| group by字段数据带null:select org_detail,count(*) from t_org group by org_detail desc。也就是org_detail中数据有null | 不会报错,且结果正确。最终null的数据也在分组中 | 通过 |
| group by 函数中数据带null。 select count(org_detail)... | | 通过 |
| order by字段数据带null。 select org_detail,sum(bbb),count(aaa) from biz_0.t_org order by org_detail desc | | 通过 |
| 不带group by的函数。select org_detail,sum(bbb),count(aaa) from t_org order by org_detail desc | | 通过 |
| is null放到where字句中 | | 通过 |
| update语句中is null放到where字句中 | | 通过 |
| update t_org set abc=null where org_id=134 | | 通过 |
| delete语句中is null放到where字句中 | | 通过 |
| insert语句中加入字段值为null | | 通过 |
1.2 工具图形界面
1.2.1 表结构
| 分类 | 功能 | 预测结果 | 实测结果 |
| Netbeans | idea |
| 数据库基本信息 | 展开左侧数据库列表 | 包含原生库中的所有catalog。 是否会比原生的多出一个dbcluster的专属catalog(tinydbcluster)。 | 通过 | 通过 |
| table | 建表 | | 通过 | 通过 |
| | 修改表 | | 通过 | 通过 |
| | 删除表 | | 通过 | 通过 |
| | 新增字段 | | 通过 | 通过 |
| | 修改字段 | | | 通过 |
| | 删除字段 | | 通过 | 通过 |
| index | 新增索引 | | 通过 | 通过 |
| | 删除索引 | | 通过 | 通过 |
| view | 新增视图 | | 通过 | 通过 |
| | 点开视图,能看到数据 | | 通过 | 通过 |
| | 删除视图 | | 通过 | 通过 |
1.2.2 数据
1.2.2.1 使用工具查看数据,并且修改、删除、新增操作
| 分类 | 功能 | 预测结果 | 实测结果 |
| Netbeans | idea |
| insert | 新增一条数据,分片键有值 | 数据能插入到算法对应分片中 | 通过 | 通过 |
| | 新增多条数据,分片键有值 | 数据能插入到不同库中 | 通过 | 通过 |
| update | 直接编辑数据,修改分分片键的值,保存 | 能保存成功。 | 通过 | 通过 |
| | 直接编辑数据,修改多条数据(对应多个分片) | 都能保存成功。查看日志,只对应到一个分片 | 通过 | 通过 |
| delete | 直接在工具上删除某条数据 | 能删除成功 | 通过 | 通过 |
| | 直接在工具上删除多条数据(不同分片) | 均能删除成功 | 通过 | 通过 |
| select | 点开后能看到所有数据 | | 通过 | 通过 |
| | 点击某个字段进行排序 | | 通过 | 通过 |
2 性能测试,并且与原生数据库、mycat进行对比。
事先准备好原生数据库以及mycat环境
原生数据库
新建单表t_org,数据量200万,与之前分库分表的数据一致。
mycat:安装mycat,修改配置文件schema.xml,将t_org,t_user均分到10个库(biz_0...biz_9)中,同样采用取余算法(mod-long);将sqlMaxList改成了1000000。(因为mycat在对sql语句都做了limit限制,性能测试时应排除此干扰)。
<mycat:schema xmlns:mycat="http://io.mycat/"> <schema name="TESTDB" checkSQLschema="true" sqlMaxLimit="10000000"> ... </mycat:schema>
-
工具中执行命令。
show命令。dbcluster都能执行通过,而mycat对个别语句不支持。但显示的结果会略有不同,请看说明
| 功能点 | 是否支持 | 说明 |
| tinydbcluster | mycat |
| show variables | 支持 | 支持 | |
| show databases | 支持 | 支持 | dbcluster显示所有库名,而mycat只显示TESTDB(虚拟schema) |
| show tables | 支持 | 支持 | dbcluster会显示所有库中表的并集,而mycat则会显示默认数据库的所有表,以及mycat配置的虚拟表 |
| show columns from t_org | 支持 | 支持 | |
| show columns from t_user_bk(非分库分表的表) | 支持 | 不支持 | mycat错误信息:[3D000][1046] No dataNode found ,please check tables defined in schema:TESTDB |
| show processlist | 支持 | 支持 | |
| 加上use以后再执行show tables。比如执行 use biz_1;show tables; use tinydbcluster;show tables; use biz_1;show tables; 看看biz_0,biz_1只显示自己库中table,而tinydbcluster库包含所有库中的table | 支持 | 不支持 | MYCAT只支持USE TESTDB,TESTDB为虚拟schema |
DDL语句比较
dbcluster和mycat支持对分库table的创建修改删除、对字段的新增修改删除
dbcluster的优势是除了以上功能之外还支持对非分库table的DDL语句,支持对索引和视图的DDL语句、支持use语句切换不同的数据库(包括原生数据库和原生的biz_0-biz_9)。
它的好处就是无需频繁切换数据源,就能访问到原生数据源的数据。
| 分类 | 功能点 | 是否支持 | 说明 |
| tinydbcluster | mycat |
| ddl table | create table | 支持 | 支持 | |
| | alter table :比如加注释 | 支持 | 支持 | |
| | drop table | 支持 | 支持 | |
| | 非分库分表的表执行create table、alter table、drop table | 支持 | 不支持 | mycat报[42000][1064] op table not in schema---- |
| ddl 字段 | alter table 修改字段 | 支持 | 支持 | |
| | alter table 新增字段 | 支持 | 支持 | |
| | alter table drop字段 | 支持 | 支持 | |
| ddl index | ALTER TABLE `t_org` ADD INDEX `abc`(`org_name`) COMMENT 'aaa'; | 支持 | 不支持 | mycat [42000][1064] op table not in schema---- |
| | drop index | 支持 | 不支持 | mycat [42000][1064] op table not in schema---- |
| ddl view | create view。 create view abcd as select * from t_org | 支持 | 不支持 | mycat [42000][1064] op table not in schema---- |
| | drop view drop view abcd | 支持 | 不支持 | mycat [42000][1064] op table not in schema---- |
| | create view 带schema。 create view biz_1.abcd as select * from t_org; drop view biz_1.abcd | 支持 | 不支持 | mycat [42000][1064] op table not in schema---- |
| use语句 | select * from t_org where org_id in (1,2,3) 语句。会显示所有包含库中该表记录集的总和(1、2、3 3条数据)。执行use biz_0。再执行该语句。(biz_0为其中一个原生数据库的库名)。然后执行select * from t_org where org_id in (1,2,3)语句。其结果集和select * from biz_0.t_org where org_id in (1,2,3)一样。 执行use tinydbcluster。再执行select * from t_org where org_id in (1,2,3)语句。其结果又变回了1、2、3 三条数据。 | 支持 | 不支持 | [42000][1049] Unknown database 'biz_0' |
基本增删改查语句
mycat对分库table的insert、update、delete、select均不支持,而这些,dbcluster都是支持的。
进过多次执行,dbcluster和mycat执行时间相近。
| 大项 | 分类 | 功能点 | 是否支持 | 执行时间 | 说明 |
| tinydbcluster | mycat | 原生 | tinydbcluster | mycat |
| insert | insert非分库分表 | insert语句 | 支持 | 不支持 | | | | |
| | insert分库分表 | 普通insert语句 | 支持 | 支持 | | | | |
| | | insert into abc(id,name) select * from abc_bk(id,name) | 不支持 | 不支持 | | | | mycat [42000][1064] TODO:insert into .... select .... not supported! |
| | | insert不加字段 | 支持 | 不支持 | | | | mycat [42000][1064] partition table, insert must provide ColumnList |
| | select非分库分表 | 常规单表select语句 | 支持 | 不支持 | | | | mycat [42000][1064] can't find table define in schema T_USER_BK schema:TESTDB Details |
| select | select分库分表 | select * from t_org where org_id=12532 | 支持 | 支持 | 1s 800ms-3s | 150-180ms | 170-190ms | |
| | | select org_id,org_name from t_org where org_id=12532 | 支持 | 支持 | 1s 800ms-3s | 150-180ms | 150-180ms | |
| | | in: select * from t_org where org_id in (123,454,780) | 支持 | 支持 | 1s 300ms-1s 800ms | 170-210ms | 180-200ms | |
| | | between:select * from t_org where org_id BETWEEN 10000 and 20000 | 支持 | 支持 | 1s 300ms-1s 600ms | 360-400ms | 360-420ms | 取前十万条的执行时间,不包括fetch时间 |
| | | select * from t_org | 支持 | 支持 | 400-600ms | 2s 500ms-3s 200ms | 6s-12s | mycat执行很慢 |
| | | 常规函数,比如concat:select concat('%',org_id,'%') from t_org | 支持 | 支持 | 50-100ms | 800ms-1s | 3s-4s | mycat执行很慢 |
| | | select * from t_org order by org_id desc | 支持 | 支持 | 5-6s | 3.5-5s | 8-9s | mycat执行很慢 |
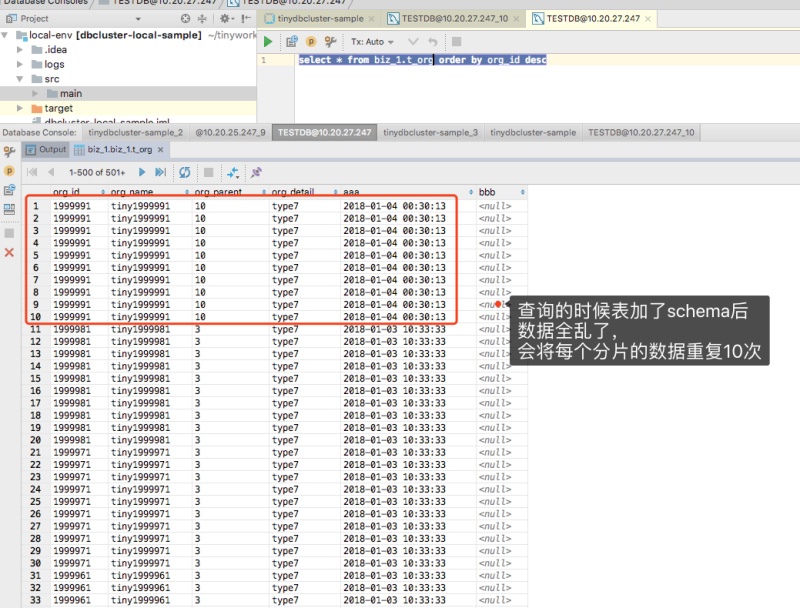
| | | 表前加schema/catalog:select * from biz_1.t_org order by org_id desc | 支持 | 不支持 | 600-800ms | 600-800ms | 7-8s | mycat执行很慢,而且所有结果不正确,请看截图 |
| | | 不带group by的函数。select org_detail,sum(bbb),count(aaa) from t_org order by org_detail desc | 支持 | 支持 | 1s - 1s 600ms | 300-600ms | 350-500ms | |
| | | 表前加schema | | | | | | |
| | | 非分片键:select * from t_org where org_name='tiny129' | 支持 | 支持 | 1s 400ms-2s | 350-500ms | 350-500ms | |
| update | update分库分表 | update t_org set name='aaa' where org_id=124 | 支持 | 支持 | | | | |
| | | update t_org set org_name='eee' where org_id in(104,985,1034,10009,10001) | 支持 | 支持 | 1s 500ms-2s | 100-200ms | 100-200ms | |
| | | update t_org set org_name='fff' where org_id BETWEEN 123 and 132 | 支持 | 支持 | 1s 500ms-2s | 600-700ms | 600-700ms | |
| | | update t_org set org_name='fff' where org_name='bbb' | 支持 | 支持 | 1s 500ms-2s | 600-700ms | 600-700ms | |
| | | update is null条件 | 支持 | 支持 | | | | |
| | | update set abc=null | 支持 | 支持 | | | | |
| delete | delete分库分表 | delete from t_org where org_id=123 | 支持 | 支持 | 1s 500ms-2s | 150-200ms | 150-200ms | |
| | | delete from t_org where org_id in (5001,5002,5003) | 支持 | 支持 | 1s 500ms-2s | 250-450ms | 200-400ms | |
| | | delete from t_org where org_id between 5010 and 5025 | 支持 | 支持 | 1s 500ms-2s | 650-700ms | 650-750ms | |
| | | truncate语句 | 支持 | 支持 | | | | |
group by
| 功能点 | 是否支持 | 执行时间 | 说明 |
| tinydbcluster | mycat | 原生 | tinydbcluster | mycat |
| select org_detail from t_org group by org_detail desc | 支持 | 支持 | 5-6s | 3s 100ms-3s 300ms | 3s 100ms-3s 300ms | |
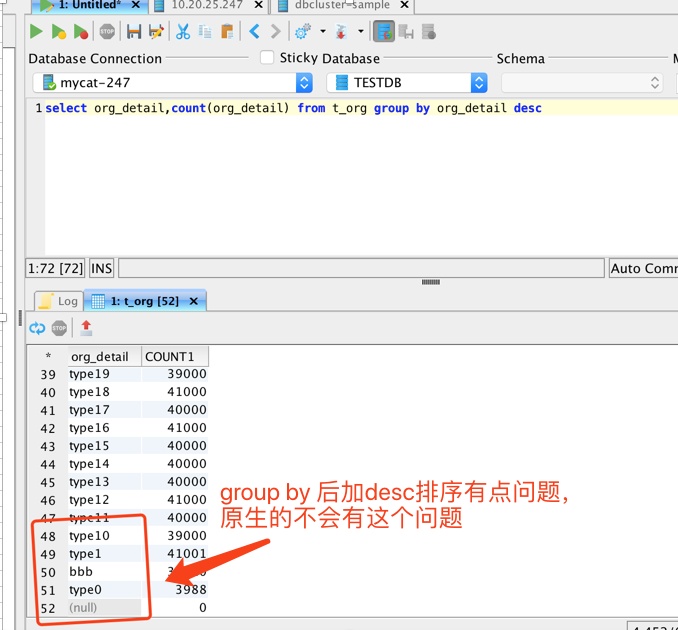
| select org_detail,count(org_detail) from t_org group by org_detail | 支持 | 支持 | 13-14s | 4-5s | 4-5s | mycat排序不正确,应该是不支持group by …desc 请看截图 |
| select org_detail,count(org_detail) from t_org group by org_detail desc | 支持 | 不支持 | 13-14s | 4-5s | 4-5s | |
| select org_detail,max(org_id),min(org_id),sum(org_id),avg(org_id) from t_org group by org_detail | 支持 | 支持 | 16-17s | 4s 500ms-5s | 4s 500ms-5s | |
| having:select org_detail,avg(org_id) from t_org group by org_detail having avg(org_id)>1000000 | 不支持 | 不支持 | | | | dbcluster没对having做特殊处理;mycat数据也不正确 |
| 非分片键和分片键做联合查询:select * from t_org where org_id=1234 and org_name='tiny1234' | 支持 | 支持 | 1s 300ms -2s | 140-160ms | 140-150ms | |
分页查询
| 功能点 | 是否支持 | 执行时间 | 说明 |
| tinydbcluster | mycat | 原生 | tinydbcluster | mycat |
| select * from t_org order by org_id desc limit 0,100 | 支持 | 支持 | 1s 300ms-1s 700ms | 300-600ms | 300-600ms | |
| select * from t_org order by org_id desc limit 100 | 支持 | 支持 | 1s 300ms-1s 700ms | 300-600ms | 300-600ms | |
| select * from t_org order by org_id desc limit 1,100 | 支持 | 支持 | 1s 300ms-1s 700ms | 300-600ms | 300-600ms | |
| select * from t_org order by org_id desc limit 1000000,1000 | 支持 | 支持 | 4-5s | 14-15s | 2s 600ms-3s | |
其他sql
| 功能点 | 是否支持 | 执行时间 | 说明 |
| tinydbcluster | mycat | 原生 | tinydbcluster | mycat |
| 非分片键:select * from t_org where org_name='tiny129' | 支持 | 支持 | 1s 400ms-2s | 350-500ms | 350-500ms | |
| 表备份:create table t_user_bk (select * from t_user); | 支持 | 不支持 | | | | |
附:
mycat测试过程中的一些问题
小结
功能性
TinyDbCluster:绝大多数sql语句都能支持,支持的sql语句比mycat更广。包括修改表结构、数据的增删改查。不仅支持分库分表的表管理,还支持对分库分表以外的表(默认数据源的表)进行管理。
mycat:不支持非分库分表的表的增删改查以及DDL语句,不支持use语句,不支持视图、索引,不支持不加字段名的insert语句。不支持查询除TESTDB(虚拟schema)以外的表。
性能
性能上dbcluster和mycat在大多数的情况下相差无几,但相对于原生数据源快很多,如果真的分在不同的物理机上,性能上会有更大的提升。
综上,mycat和dbcluster都是比较优秀的数据库分库分表方案,都解决了数据库在大数据量下的性能瓶颈。
总结
实际验证下来,Mycat确实比我预先估计的强悍许多,为Mycat点赞;当然TinyDbRouter也证明了自己的实力。

